
ED-GAN:基于改进生成对抗网络的法律文本生成模型
2019-05-10 02:16:10康云云彭敦陆
小型微型计算机系统 2019年5期
康云云,彭敦陆,陈 章,刘 丛
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
当前“互联网+法律”的模式有效缓解了法律服务行业中人力资源不足的问题,让人们足不出户就可方便享受到法律咨询服务.研究出适用于法律文书的自动文本生成技术,在减轻法律工作者文书工作上具有重要的现实意义.例如,在作为司法领域最为重要的法律文本——法律判决书中,案情描述是其重要组成部分,是否可以采用自动或半自动化方式生成呢?比如,让用户根据提示填写案件要素.在收集完案件要素后,按要求自动生成与案情要素对应的案情描述文本,并将其置入法律判决书的相应部分.
文本自动生成是自然语言处理NLP(Nature Language Process)领域的主要研究方向,而深度学习算法在自然语言处理领域也越来越被重视.例如,采用循环神经网络(RNNs)生成时间预测序列[1].但由于RNN易出现梯度消失或梯度爆炸的问题,所以实际应用中,难以处理文本序列中的长期依赖关系[2].文献[3]提出的长短期记忆网络单元(LSTMs)就是为了解决文本序列中的长期依赖问题.近年来,研究者们,还针对序列到序列的生成如机器翻译提出了编码-解码(Encoder-Decoder)框架[4],文献[5]提出了基于LSTMs网络的Encoder-Decoder模型进一步提高了序列到序列的生成效果.然而这些网络在训练时需要对隐变量做推断,参数的更新都直接来自样本,参数训练很繁琐.起初用于图像生成的GAN也应用到了文本生成中[6],GAN由生成器G和辨别器D构成,生成器G需拟合相应生成,辨别器是具有分类作用的函数,可以采用机器学习的SVM算法[7],更可以采用深度学习分类算法.GAN的特点是不断训练辨别器D来提高鉴别真实数据和生成数据的能力,生成器G不断训练提高迷惑D的能力.G的参数更新不是直接来自数据样本,而是使用来自D的反向传播,很好的解决了参数训练繁琐的问题.针对需要解决的问题:1) 文本序列生成中的长期依赖关系; 2) 参数训练繁琐.在前人研究成果的基础上,本文对GAN网络做出改进并应用于法律文本的自动生成,生成器为基于LSTMs的Encoder-Decoder模型,判别器采用基于CNN的二分类模型.
2 相关工作
深度生成模型已经受到越来越多的关注,它对大量未标注的数据表现出灵活的学习能力.由Geoffrey Hinton提出的深度信念网络(DBN)通过训练神经元间的权重,让整个神经网络按照最大概率来生成训练数据[8].这种方法建立在先验分布的基础上,因此生成效果较好但是存在棘手的概率近似计算问题.
Ian Goodfellow于2014年针对生成模型提出了新的训练模型,对抗式生成模型(GANs),它启发自博弈论中的二人零和博弈,GAN模型中的两位博弈方分别由生成式模型(generative model)和判别式模型(discriminative model)充当,它跳过了极大似然估计中棘手的计算难题.文献[6]将GAN应用到了文本生成上,提出了TextGAN模型,使得文本生成效果的评测任务转到了判别器上,通过对抗自动进行参数优化,直至生成文本与真实文本无法分辨.
另一方面,前人们在生成结构式序列方面也做了大量研究.文献[9]第一次提出了序列到序列(sequence to sequence)生成模型,其输入是一个序列(比如一个英文句子),输出也是一个序列(比如该英文句子所对应的法文翻译).编码-解码框架就是对这个实际问题的很适用的模型.这种结构最重要的特征在于输入序列和输出序列的长度是可变的.编码(Encoder) 部分就是一个RNNCell 结构.每个时间步长(timestep)向Encoder中输入一个词向量直到一个句子的最后一个词,然后输出描述整个句子的语义向量.然而RNN在长序列任务上易出现信息损失问题,LSTM对解决长序列依赖问题非常有效.文献[10]提出将每行古诗关键词和前面已经生成的序列输入到生成模型中经过编码解码可以使得生成古诗的效果优化.
在前人工作的基础上,本文将GAN网络用于法律案情描述的生成.GAN的生成器采用基于LSTM网络的Encoder-Decoder模型,输入为案情要素文本;辨别器是基于CNN的二分类模型,计算生成器生成的案情描述和真实的案情描述的相似度.
论文余下部分的结构为:第3节,问题描述以及文中领域专业名词及字母的解释;第4节,介绍将案情要素输入到生成器的编码(Encoder)的过程和生成案情描述的解码(Decoder)过程.第5节描述CNN网络作为辨别器模型原理;第6节介绍论文的数据集及实验分析;第7节,论文总结.
3 问题描述
根据法律案情要素生成对应的案情描述文本,将案情要素S,输入到模型进行学习,输出为生成的对应案情描述文本Y.本节主要介绍对原始法律文本进行预处理,包括对案件要素和案情描述文本的分词及向量化,以适合所提算法的计算要求,表1给出了下文相关名词术语以及参数的解释.
3.1 名词解释
法律案情要素:表明案件的一个或多个要素信息:何事、何时、何地、何情、何故、何物、何人.
例如,离婚案件中描述原被告双方何时以及如何认识的一条案情要素:2006年经朋友介绍认识.
何时认识:2006年.
如何认识:朋友介绍.
法律案情描述:包含了法律案情要素的七大要素内容,对案件进行详细的叙述.
例如,与上文的案情要素“2006年经朋友介绍认识”对应的案情描述为:原、被告于2006年经朋友介绍认识.
表1 字母参数及其含义
Table 1 Meaning of Alphabetic parameters

名 称含 义S案情要素SiS的第i个词t时间步EOS案情要素结束标识符r={r1:rSi}将案情要素输入编码层得到的隐藏层向量h=[h0:hT]输入生成的前文序列和编码得到的案情要素语义向量到解码层得到的隐藏层向量{y1,y2,…,ySi}解码得到的输出序列C案情描述词典{ptO1,ptO2,…,ptOV}时刻t关于案情描述的词典中C中每个字符的概率值,V为C中词数ωc解码LSTM从隐藏层到输出序列的权重
3.2 文本分词及向量化
法律文本数据中实体之间的关系比较明显,因此在对数据做分词、向量化等操作时,保留实体间的关系显得很重要.这里的实体包括时间,地点等词.本文采用条件随机场(CRF)分词,CRF把分词当作字的词位分类问题.通常定义字的词位信息:词首,常用B表示;词中,常用M表示;词尾,常用E表示;单字词,常用S表示.词位标注后,将B和E之间的字,以及S单字构成分词.
例句:婚后育有一个女儿.
CRF标注后:婚/B 后/E 育/S 有/S 一/B 女/B 儿/B.
分词结果:婚后/育/有/一个/女儿.
分词结束后,使用word2vec向量化词语,将分得的词和其向量组合得到法律案情描述的词典C.
4 基于编码——解码框架的生成器模型
本节详细介绍基于LSTMs的编码-解码(Encoder-Decoder)框架的生成模型G.模型的目的是学习生成器在样本数据(真实案情描述文书)上的分布函数pg,真实案情描述文书的分布函数为pdata.首先向Encoder阶段的LSTM(命名为EnLSTM)中输入案情要素S,其中包含了一个或多个词,编码后得到固定维数的隐藏层向量.然后,将这个隐藏层向量输入到Decoder阶段的LSTM(命名为DeLSTM)中,并结合t-1时刻的输出生成时刻t的隐藏层向量,最后解码得到生成序列y即对应的案情描述文本,映射过程表示为G(S,θ),θ为LSTMs的参数.生成模型结构如图1所示,说明了由案情要素“1992年、自由恋爱”生成对应得案情描述“原被告于1992年自由恋爱”的原理.下面,详细的介绍了生成器的编码(Encoder)过程以及解码(Decoder)过程.
4.1 Encoder
如图1所示,虚线左边部分是编码(Encoder)过程.案情要素S中第i个词记为si,案情要素词序列S={s1,s2,…,st},定义为EnSen.然后,顺序输入到EnLSTM中,每个时间步t输入一个词向量.当前时刻t的隐藏层向量rt是由t-1时刻的隐藏层向量rt-1和当前时刻的输入st决定的.LSTM有通过精心设计的称作为“门”的结构,具有去除或者增加信息到隐藏状态的能力[3].LSTM包含了三种门结构,分别为遗忘门,输入门以及输出门.首先,遗忘门层决定丢弃一些信息:
ft=σ(Wf·[rt-1,st]+bf
(1)

图1 生成器模型结构图Fig.1 Builder model structure
其中Wf是决定忘记信息的权重,bf为偏置值.

it=σ(Wi·[rt-1,st]+bi)
(2)
(3)
Wi,WC分别为sigmoid 层,tanh层选择信息的权重,bi,bC为偏置值.在上面的计算基础上,更新的状态信息,即:
(4)
最后,通过输出门决定输出信息,进而得到输出信息的向量表示,如公式(5)和公式(6):
ot=σ(Wo·[rt-1,St]+bo)
(5)
rt=ot·tanh(Ct)
(6)
Wo是决定输出信息的权重,bo是偏置值.
经过以上编码得到一个隐藏层向量序列r={r1:rt}.当输入到结束标志(EOS)时,生成最后的语义向量rc.rc作为初始向量输入到解码阶段.
4.2 Decoder
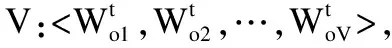
(7)
其中ωc是解码LSTM从隐藏层到输出序列的权重矩阵,这些概率值可进一步通过一个Argmax函数得到输出序列{y1,y2,…,yt},定义为DeSen,θ是生成模型中LSTMs的参数.这个过程根据给定的语义向量rc和之前已经生成的输出序列y1,y2,…,yt-1预测下一个输出的单词yt,即:
yt=argmaxP(yt|y1,y2,…,yt-1,rc,ht)
(8)
式(8)可简写成:
yt=g(yt-1,ht,rc)
(9)
其中,ht是DeLSTM的隐藏层向量,yt-1是上一时间刻的输出,作为这一时刻的输入,g是一个非线性的多层感知机,产生词典C中各词语属于yt的概率.基于Encoder-Decoder框架的生成器模型伪代码如算法1所示.
算法1.基于LSTMs的encoder-decoder框架的序列生成
Encoder:
输入:案情要素词序列EnSen:{S1,…,St}.
输出:rc
BEGIN:
1.fort in 1: len (EnSen)
2.ft=σ(Wf·[rt-1,st]+bf);//忘记门选择丢弃一些信息
3.it=σ(Wi·[rt-1,st]+bi);//sigmoid 层称“输入门层”决定什么值我们将要更新

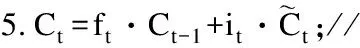
6.ot=σ(Wo·[rt-1,st]+bo);//输出门决定输出信息
7.rt=ot·tanh(Ct);//输出信息的向量表示
8.rc=q(r1:rt);
9.rc=q(r1:ri)=ri;//将最后的隐藏层作为输入的关键词序列的语义向量
10.end for
END
Decoder:
输入:rc,前面生成的输出词向量序列DeSen:{y1,y2,…,yt-1}
输出:解码生成的词向量序列DeSen:{y1,y2,…,yt}
BEGIN:
11.fort in 1: len (DeSen)
18.
19.yt=argmaxP(yt|y1,y2,…,yt-1,rc,ht)=g(yt-1,rc,ht);//g是一个非线性的多层感知机,产生词典C中各个词语属于yt的概率
20.end for
END
5 基于CNN网络的辨别器模型
GAN网络的优势是不需要设计专门的算法来评估生成的文本效果.GAN网络的判别器D是一个二分类器,其输入为G生成的案情描述及样本案情描述,经过D输出值为一个0到1之间的数,用于表示输入文本数据为真实的案情描述的概率.由于CNN在文本分类中的高效性,这里采用了CNN网络作为辨别器,结构如图2所示.
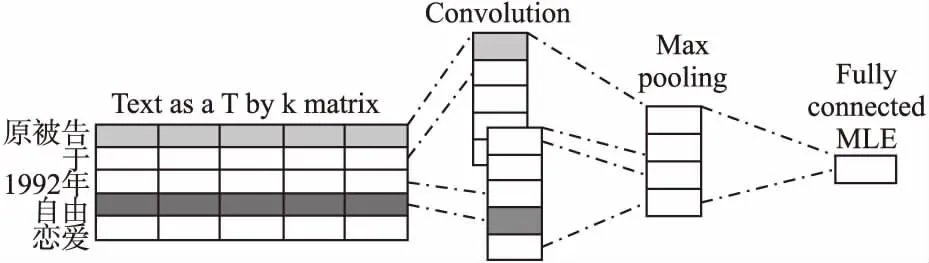
图2 辨别器模型结构图Fig.2 Discriminative model
D的输入序列ξ1=y1⊕y2⊕…⊕yT,即生成模型生成的案情描述,xt∈Rk是k维的向量,⊕是将输入序列向量转化为矩阵的运算,得到ξ1:T∈RT×k.D采取了窗口大小为l个词的卷积核v∈Rl×k(卷积核是由输入样本案情描述转化的矩阵向量训练得到),通过和输入的文本矩阵卷积运算得到特征映射:
cj=δ(v⊗ξj:j+l-1+b)
(10)
⊗是卷积核和文本矩阵数乘运算,b是偏置量,δ是非线性激活运算,可以采用不同大小的卷积核进行文本特征抽取,对特征矩阵进行最大池化后得到:
(11)
再经过基于sigmode函数的全连接层输出得到输入文本来自真实文本的概率.基于CNN的辨别器D(x,φ),x是真实样本数据,φ是参数.D输出一个标量,这个标量表示x来自于真实已有的案情描述pdata的概率.训练D最大化其正确区分真实案情描述和生成的案情描述的能力,同时训练生成器G以最小化log (1-D(G(S))),S代表案情要素词序列.G的训练是关于值函数V(G,D)的极小化极大的二人博弈问题:
minGmaxDV(D,G)=
Ex~pdata(x)[logDx]+ES~pS(s)[log(1-D(G(S)))]
(12)
在训练生成器G和辨别器D过程中,固定一方,更新另一方的网络权重,交替迭代,伪代码如算法2.在这个过程中,双方都极力优化自己的网络:生成器不断优化自身生成逼真
文本的能力,辨别器不断提高区分生成的文本与真实文本的能力,从而形成竞争对抗,直到双方达到一个动态的平衡.此时生成模型G恢复了训练数据的分布(造出了和真实数据一模一样的样本)即有:
pg=pdata
(13)
算法2.生成对抗网络的小批量随机梯度下降训练
判别器训练步数k,为一个超参数,本实验设置k=2,考虑到消耗和训练速度;交替迭代训练 次达到收敛状态:
Pg=Pdata
BEGIN:
1. for i in 1: N
for j in 1: k
2. 输入:含有m条案情要素关键词序列{S(1),…,S(m)}
3. 输入:由真实的文本生成模型Pdata生成的m段对应的案情描
述文本序列
{x(1),…,x(m)}
4. 根据下式,通过随机梯度上升更新训练生成器模型
5.end for
6.输入:含有m条案情要素关键词的序列{S(1),…,S(m)}

别器模型
8.end for
END
6 实验分析
6.1 数据来源
实验部分的数据集采集于2016年某省离婚案件的法律文书[注]China Judgements Online.http://wenshu.court.gov.cn,2016.共25000份案情描述文本以及其对应的案件要素表,内容包含:当事人信息、开庭判决总过程(以时间为序)、复核事实、证据陈述和判决结果.实验前对数据集进行了分词、去除噪声和去重复数据等预处理.
6.2 算法有效性分析
生成器G和辨别器D共享一组参数,采用随机梯度下降法交替更新这组参数,达到“对抗”训练的效果.在训练的内部循环中完成最优化D从计算方面来讲是过于高难度的,在有限的数据集上做这件事会导致过拟合.相反,我们在k步优化D和1步优化G交替进行.只要G改变的足够慢,D的结果就能维持其最近的最优解.超参k的选取影响参数趋于收敛所花费的时间,以及参数趋于平衡后G生成文本的效果.
本节设计实验1探究了在法律文本数据集上G对训练趋于收敛所需的时间以及收敛后生成器生成文本效果的影响;实验2比较了本文所提模型与传统模型在不同规模数据集下的文本生成效果;实验3人为设定四种指标:法律性,流利性,连贯性,意义性来分析生成法律案情描述文本的质量,进而分析论文模型算法的有效性.
实验1.比较k取值对于生成器G的收敛效果的影响.
实验采用每训练k次D,训练一次G的策略.为分析整个模型生成文本效果,采用综合收敛值与收敛速度来反映k对G收敛效果的影响.评价G收敛效果一种比较好的方法是从生成的文本取样,表示为q,再让充分了解真实文本数据特征的专业人员来评价G生成的文本正确性.假设专业人员学习了准确的真实文本数据分布模型,表示为phuman(x).要使生成的文本与真实文本难以区分,就要最小化负对数似然值:
-Ex~qlogphuman(x)
(14)
为了模拟真实世界的结构序列即真实的案情描述文本,实验中使用一种语言模型来捕捉真实文本中的词与词之间的依赖关系.这里,随机初始化一个LSTM网络作为真实模型(命名为oracle,记为Goracle),用于生成真实案情描述文本数据分布p(xt|x1,…,xt-1).采用这一模型生成了10000份文本序列作为G的训练集,以此评估G生成文本的效果[11].在实验数据集下,通过oracle模型评估G,得出评估函数:
(15)
实验中,从G生成的文本中采样10000份,在不同的k值对采样的每个文本计算其NLLoracle的平均值,k依次取1,2,3,5.图3描述了本文所提模型ED-GAN在不同k值实验下评估函数结果.
分析图3得出,k=1时,D过拟合,k=5,收敛速度快,但生成效果不好.k=2,3时,收敛值和收敛速度得到平衡.

图3 损失平均值Fig.3 Average of NLLoracle
实验2.利用BLEU评分算法,来比较所提模型和传统模型在不同规模数据集下的文本生成效果.
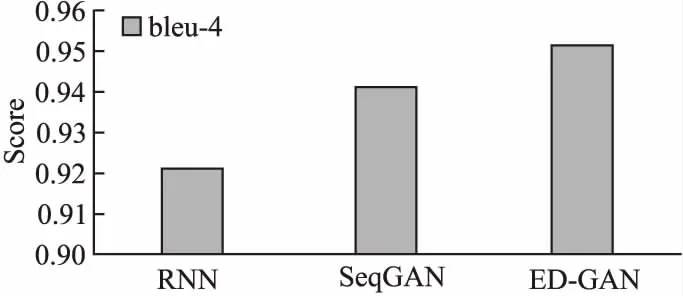
图4 BLEU评分值 Fig.4 Score of BLEU
在生成文本效果差距很小的情况下,k=3时,模型训练的时间效率较高,因此实验2设置k=3并采用BLEU评分算法计算了生成的案情描述文本与真实的案情描述文本之间的相似度,进而评估模型生成文本的效果.实验2将论文模型ED-GAN和前人提出的RNN(LSTM)序列模型和seqGAN序列生成模型作对比,三种计算模型的BLEU得分如图4所示.
从图4的柱状图可以得到模型ED-GAN生成的案情描述文本与传统算法生成的案情描述文本相比有更高的BLEU得分,因此ED-GAN算法在案情描述生成上有更好的效果.
实验3.比较ED-GAN和传统模型的文本生成效果.
实验为专业评价人设置了4个评价指标:法律专业性,流利性,连贯性和意义性,每个指标的分值为1到5,分值越高代表生成的案情描述文本相应指标的效果越好.表2给出了这4个指标的具体解释.
表2 4个评价指标及其解释
Table 2 Meaning of four evaluation indexes

法律性文章满足法律判决书的格式,相关术语满足法律性表达流利性文章读起来顺口流利连贯性文章前后衔接正确,具有逻辑性,不矛盾意义性文章能让人读懂其要表达的意思,相关概念意思清楚
实验仍然将论文模型ED-GAN与RNN(LSTM)型和SeqGAN模型对比,每种模型会分别生成20篇15字符的案情描述和20篇25个字符的案情描述.有四位专业人员分别针对四个指标对各种模型生成的文本进行评分,模型最终得分为四个指标得分的平均值,结果如表3.
表3 4指标及其平均分值
Table 3 Score of four indexes
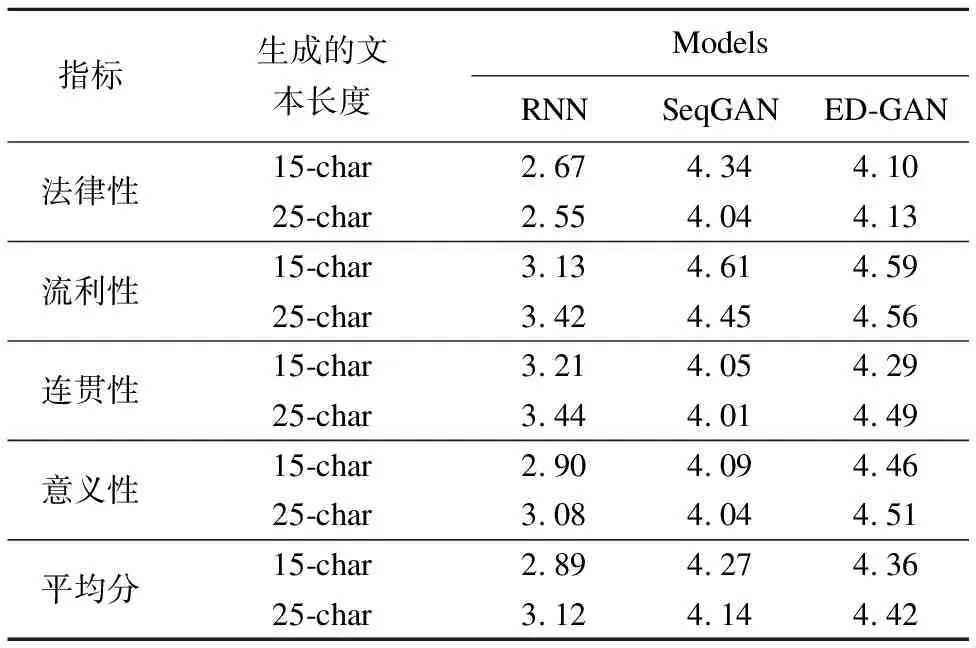
指标生成的文本长度ModelsRNNSeqGANED-GAN法律性15-char2.674.344.1025-char2.554.044.13流利性15-char3.134.614.5925-char3.424.454.56连贯性15-char3.214.054.2925-char3.444.014.49意义性15-char2.904.094.4625-char3.084.044.51平均分15-char2.894.274.3625-char3.124.144.42
从实验结果数据可见,本论文所提出的模型ED-GAN相比较其他模型在4个评价指标上的得分都有提高,对提高生成更准确,更贴合真实案情文本的案情描述具有重要的意义,相对传统地模型算法,特别在较长的案情描述文本生成上的效果更加准确.
7 总 结
法律文本的自动生成可缓解法律服务行业中的人员不足现状,根据用户给出的案情要素自动生成案情描述文本,可以减少法律服务人员的文书工作,提高民众对法律服务的获取效率.本文结合Encoder-Decoder框架对GAN做了改进,构建了适用于法律文本自动生成的深度学习网络模型——ED-GAN,并将模型应用于法律案情描述的生成中.实验结果表明,ED-GAN模型在生成案情描述文本时具有较好的生成效果.在生成案情描述文本的基础上,可以针对案情描述文本匹配相应的法律判决,对于案件预测具有重要意义.
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中国外汇(2019年19期)2019-11-26 00:57:32
青少年科技博览(中学版)(2019年12期)2019-04-10 10:59:26
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
小猕猴智力画刊(2015年7期)2015-08-15 08:48:04
