
基于知识库的问答系统
2019-04-22 12:03:10毛麾
现代计算机 2019年8期
毛麾
(四川大学计算机学院,成都 610065)
0 引言
随着互联网信息时代的到来,人们可以通过互联网获取海量的信息和知识,人们获取信息和知识的方式也越来越丰富。但是,从互联网中海量的数据中快速准确地获得用户所需的知识仍然是一个困难的问题。在这样的背景下,基于自然语言的问答系统开始发展起来。
问答系统(Question Answering System,QA)是信息检索系统的一种高级型式,它能用准确、简洁的自然语言回答用户用自然语言提出的问题。问答系统是目前人工智能和自然语言处理领域中一个倍受关注并具有广泛发展前景的研究方向。为了解决信息检索中的各种问题,本文提出了一种基于知识库的问答系统的构建方法,主要使用了命名实体识别、实体链接等技术来通过知识库获取问题的答案。
1 相关工作
早期的研究主要基于规模较小的专用知识库进行,使用的方法以语义解析为主。但这种方法往往需要大量人工标注的数据来训练模型,代价较大。目前主流的研究方法主要分为基于语义分析的方法和基于信息检索的方法两大类。语义解析(Semantic Parsing)[1-2]的方法侧重于将自然语言形式的问句转换为逻辑表达式,如lambda表达式和依存组合语义树,然后从知识库中寻找答案。信息抽取(Information Extraction)[3-4]的方法主要通过在知识库中查询该实体,可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案。随着深度学习在自然语言处理领域的发展,基于分布式词表示(Distributed Embedding)的方法[5-8]开始成为主流,该方法首先利用命名实体识别技术找出问题中的实体词,然后利用实体链接(Entity Linking)技术找到实体词在知识库中对应的实体,通过在知识库中检索实体的属性,可以得到问题的候选答案,最后通过计算问题和答案的相似性来为候选答案排序来得到最符合问题的答案。
从问题本身的语言形式的角度来说,研究界最普遍关注的依然还是单关系(Single Relation)的事实型问题(Factoid Questions)。虽然单关系的事实型问题目前被研究的最为广泛,但由于问答系统本身具有的开放性,使得这仍然是一个十分具有挑战性的难题。
命名实体识别(Named Entity Recognition,NER)是自然语言处理的一项基本任务(Natural Language Process,NLP),主要目的是找出文本中的一些实体并识别出它们的类型,例如文本中的人名、地名和机构名。
传统基于统计学习的NER方法[9]严重依赖特征工程和专家知识,如条件随机场(Conditional Random Field,CRF)。基于深度学习的NER[10-11]、特征工程和专家知识不再是必不可少的,NER的识别率也得到了显著提高。Cicero Nogueira dos Santos[12]等人提出了利用来CharWNN来进一步提高NER的准确率,该方法在传统的词嵌入(Word Embedding)的基础上利用字嵌入(Character-level Embedding)来增强词向量的表达能力。Jason P.C.Chiu和Eric Nichols[13]使用了双向LSTM(Bidirectional LSTM,BiLSTM),较单向 LSTM 在 NER中取得了更好的效果。Guillaume Lample[14]使用了LSTM-CRF的结构,通过利用CRF作为网络的最后一层,很好地改善了网络输出的结果。总的来说,命名实体识别现阶段的方法还是以在BiLSTM-CRF模型的基础上改进为主。
2 系统架构
本节主要介绍基于知识库的问答系统的整体框架和流程。如图1所示,对于一个问题Q(例如:红楼梦作者是谁?),系统首先通过命名实体识别技术可以检测出问题中的实体词“红楼梦”,然后以“红楼梦”作为关键词在知识库中查找,可以得到“红楼梦”对应的实体(红楼梦〈书〉、红楼梦〈电视剧〉等)。通过实体链接找到确定问题Q中实体词“红楼梦”表示的实体是“红楼梦〈书〉”。确定问题Q中“红楼梦”对应的实体之后,利用知识库查找出实体相关的信息(如图中作者、主要任务、别名)生成候选答案。最后通过计算问题Q与候选答案的语义相似性来对答案排序,选择相似度最高的答案作为问题Q的最终答案。
3 关键技术
(1)实体识别
本文实体识别主要使用了字特征和词特征来改进BiLSTM-CRF模型,结构如图2所示,模型输入的是拼接后的词向量和字向量,通过双向LSTM处理过后输入到CRF层,CRF层计算最后的标注序列。

图1 问答系统流程图
(2)实体链接
实体链接的关键是将知识库中的实体表示为一个可计算的向量,本文提出了Entity Embedding算法来解决这个问题。Entity Embedding算法的流程如图3。
①利用主题模型对知识库中实体的上下文信息进行处理,得到对应的主题词。
②通过在查找表中进行查找,将主题词替换为对应的嵌入式表达,即词向量。
③将所有的词向量线性求和,得到Entity Embedding。
Entity Embedding算法最大的作用就是将知识库中的一个实体表示为一个向量,为计算相似度和其他后续处理带来了巨大的便利。在计算出实体的Entity Embedding后,可以用文本表示方法将问题也表示为一个同维度的向量,这样就可以用计算相似度的方法来将实体词连接到正确的实体。
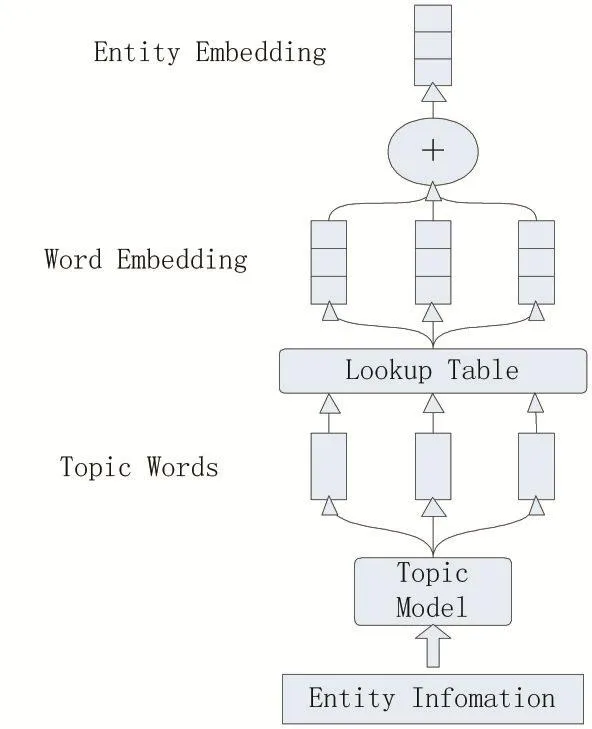
图3 Entity Embedding算法流程图
4 实验及结果分析
为了测试系统在公开数据集的表现,本文在NLPCC ICCPOL 2016 KBQA数据集上进行了实验。NLPCC数据集提供了一个包含14609个问题对的训练集和包含9870个问题对的测试集。为了证明本问答系统的有效性,我们将结果与文献[15]进行了对比,具体结果如表所示。
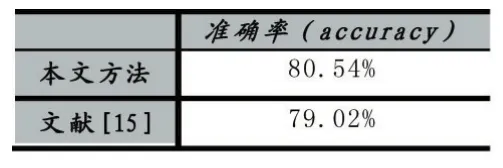
表1 NLPCC数据集实验结果
从表1可以看出,基于知识库构建的问答系统在NLPCC数据集上也取得了优异的效果,这充分说明了本文所提出的方法的可行性和有效性。
为了验证命名实体识别的有效性,我们从人民日报语料中随机选择了80%的数据来训练模型,将另外20%的数据用来测试。实验的评估指标选择的是准确率(P)、召回率(R)和 F1值,我们主要对人名(PER)、地名(GEO)、机构名(ORG)这三类实体进行了评测,结果见表2。为了进一步说明本文提出的命名实体识别模型的有效性,我们用相同的数据训练了一个BiLSTMCRF模型作为对比,BiLSTM-CRF模型的训练采用了与本文模型完全相同的方法。

表2 命名实体识别实验结果
从表2数据可以看出,本文方法相比于BiLSTMCRF模型在准确率、召回率和F1值这三个指标上都取得了提升。
5 结语
本文提出了一种基于知识库的问答系统的构建方法,并且通过实验证明了其可行性和有效性。不同于一般的搜索系统,问答系统希望从语义层面来分析用户的需求,为了理解用户的真实意图需要使用自然语言的方法来对问题进行处理。本文主要使用了命名实体识别来提取问题中的实体词,然后将实体词链接到知识库中的实体,通过将问题和实体表示为向量,利用计算向量的距离表示语义相似度。本文的不足之处在于主要考虑的是单关系的事实型问题,没有考虑更复杂的问题,在后续研究当中将做进一步探索。
猜你喜欢
红楼梦学刊(2020年4期)2020-11-20 05:52:38
海峡姐妹(2020年7期)2020-08-13 07:49:32
红楼梦学刊(2020年3期)2020-02-06 06:16:54
中国外汇(2019年18期)2019-11-25 01:41:54
制造技术与机床(2019年6期)2019-06-25 10:17:46
海峡姐妹(2018年5期)2018-05-14 07:37:10
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
中国交通信息化(2016年9期)2016-06-06 07:42:23
