
基于客户-服务器双端去重的Web预取新方法
2019-04-19 05:18姚瑶
计算机技术与发展 2019年4期
姚 瑶
(郑州工程技术学院 信息工程学院,河南 郑州 450044)
0 引 言
随着网络用户和服务内容的爆炸式增长,用户对网络服务质量的要求越来越高,尤其是用户访问延迟正面临着严峻的考验。为了解决上述问题,学者们虽然采取了较为有效的方法,比如基于时间局部性原理的Web缓存机制[1]、基于空间局部性原理的Web预取机制[2],以及基于地域性的CDN系统,但是对网络延迟的影响仍然受限于内存、命中率和带宽等因素。
Web预取技术试图在用户提出请求之前主动提取资源,在一定程度上提高了命中率,降低了访问延迟。最近客户端访问历史常被用来预测在不久最可能被访问的资源。但是存在投机性,有时还会额外增加带宽。因此,该方法需要谨慎使用。也正是因为潜在的带宽受限而使得Web预取技术在商业领域的应用不是很好。Mozilla Firefox浏览器和Google搜索引擎相继采用Web预取技术减少延迟。
利用数据去重技术分析数据的冗余度,从而适当减少网络数据传输量,由此释放被占用的带宽资源[3]。该技术可以利用数据对象之间的信息冗余,获得远高于传统压缩方法及增量备份方法的空间利用率。数据去重技术早期应用在存储系统和备份系统中,目前是云存储应用中一种重要的存储优化技术[4-7]。基于存储系统内在的数据相似性和数据重复访问的特点,数据去重技术还被应用于内存性能优化和延长SSD使用寿命等方面。随着人们不断利用其数据缩减优势来改进和优化现有存储和网络系统的不足,数据去重技术的应用将会越来越广泛。文献[8]提出基于网页正文结构和特征串的相似网页去重算法,虽然取得了较高的去重率,但是应用于预取系统时导致延迟较高,并且降低了预测准确率。在云计算环境下,文献[9]提出了一种基于流水线的数据读取模型,但是随着冗余率增加,系统速度降低,影响了预取性能。文献[10]在客户端实现重复数据删除技术,通过对文件进行分块和在备份过程中去除重复数据块,减少了客户端与服务期间需要传输的数据量,使得文件备份的速度获得较大提高,也降低了网络带宽要求,显著提高了网络备份系统的性能,但却没有考虑预取。
Web预取技术受限于带宽,而数据去重技术由于减少转移数据的体积从而释放部分占用带宽。所以,将预取技术与数据去重技术结合起来在减少网络延迟方面有重大意义。文中首先改进了Web预取系统,其次通过移植数据去重模块实现了预取系统的双端去重,最后通过实验所提方法进行验证。
1 基于数据去重的Web预取系统
对传统的Web预取系统框架进行改进,引入了客户端重复数据去重模块(CDM)和代理服务器端重复数据去重模块(SDM),实现了双端数据去重。
1.1 Web预取系统架构
1.1.1 代理服务器端
改进后的代理服务器端增加了响应重组模块、SDM模块和响应拦截模块等,如图1所示。
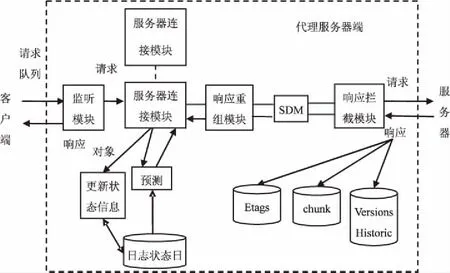
图1 改进的代理服务器端体系结构
服务器连接模块:主要负责直接连接客户端和服务器端,尤其是在处理响应的时候,该模块第一时间接收最原始HTTP响应消息报头,并传递给客户端。然后把从服务器端接收的所有资源数据原封不动地传递给客户端。文中所提方法对HTTP响应消息报头做了进一步的改进。报头信息不仅仅包括现有保证连接的附加标题信息,而且涉及修改了标题值。例如,需要修改Content-Length。此外,由于该系统需要对消息实体做拆分处理,所以需要第一时间从服务器端接收完整的消息实体。当该过程终止时,再把修正过的实体内数据回传给客户端。
响应拦截模块:由于改变了代理服务器端HTTP响应报文的处理方式,故新设一个响应拦截模块,拦截来自服务器端的最原始的HTTP响应报文,存储在临时缓冲区内并做预处理,判断传输方式是标准数据还是分块方式。该模块的具体工作:第一,检查是否存在ETag(被请求变量实体的值),如果存在取出其值;第二,检查Content-Length和Transfer-Encoding字段,如果是前者存在并有效,则HTTP服务器响应的报文必须和消息内容的传输长度完全一致。对于动态的内容或者在发送数据前不能判定长度的情况下,可以使用分块的方法传送编码。该模块检索客户端缓存关联资源的自定义报头的、以数组形式存储的资源标识符。然后把装有存储的响应头、实体消息数据和资源标识符数组的缓冲区传送给代理服务器数据去重模块SDM。
SDM模块:对响应拦截模块转交过来的消息实体的数据执行拆分。分两个步骤完成:块划分和数据去重。该模块存储的主要字段是ETag、Chunk和Versions Historic。ETag存储唯一ETag资源标识符,由资源版本号索引。Chunk存储块元信息,SDM模块处理的所有资源版本号的所有块,由块哈希索引。Versions Historic存储了所有资源版本号的Chunk的链接队列,由资源版本号索引。
SDM模块首先检查ETag的状态,如果是新资源,则生成一个新的资源标识符存储于ETag中,使用分块算法为资源分块,生成块链表,存储在Versions Historic中。如果ETag已经存在,意味着该资源先前已经被SDM处理过,不需要重新分块,仅检索Versions Historic中存储的资源版本号的块链表。接下来,SDM执行数据去重算法,使用两个缓冲区分别存储元数据和非冗余数据。SDM模块遍历块链表,试图找到一个匹配的散列块内的客户端参考源。如果不匹配,SDM模块在已经被处理过的当前资源版本块中再做一次查找(例如:自冗余数据案例)。如果找到一个匹配成功的冗余块,SDM模块添加块的元信息到对应缓冲区。对于非冗余块,实体消息数据需要添加到非冗余缓冲区。SDM模块建立了元数据和非冗余内容的最终组合,通知重组响应模块数据拆分过程已经完成。
响应重组模块:准备和发送回传的响应报文。响应报头信息进行重组,更新/创建Content-Length附加上新的实体消息数据长度;添加两个新的报头信息X-vrs(资源版本号标识符)和X-mtd(元数据长度)。响应重组模块通过附加非冗余内容块到元数据块之后重组新的实体内容数据块(entity content data block),最终重组后的回传响应报文包含报头和消息实体内容。
组合过的响应报文被多功能的服务器连接模块拦截,背负式(piggybacks the hintlist)报头信息并丢弃未改变的实体消息块,最终重组过的HTTP响应报文传递给客户。
预测引擎模块:主要任务是在每一次资源被请求的时候预测即将可能访问的页面。该模块依据预测算法将产生一系列最近被访问频率最高的资源的URL,并将结果放入决策数据库中。
1.1.2 客户端
改进后的客户端引入了Resource Versions数据文件模块、CDM模块,体系结构如图2所示。
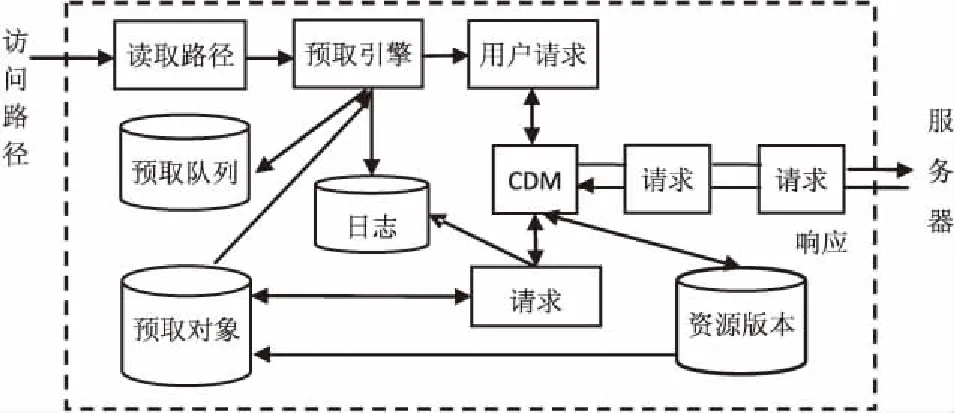
图2 改进的客户端体系结构
Resource Versions数据文件:客户端新增的模块,用来存储重组的消息实体数据,由资源标识符索引。实质上担任了客户端浏览器的角色。数据存储文件中的资源信息与Fetched Objects中的信息是同步的,存储的是资源关联而不是具体的消息实体。资源版本号(Resource Versions)由客户端数据去重模块CDM保存。
CDM模块:拦截客户端UserRequests或者是Prefetch Requests模块发送的HTTP请求报文。具体工作:查询Resource Versions数据存储文件,获得客户端缓存中的所有资源的资源标识符。CDM通知Communications Interceptor(通信拦截)模块对报文做继续处理。CDM分配一个缓冲区,采用块划分算法重组来自服务器的原始资源。CDM检查元数据,每一chunk由一个元组引用,复制Resource Versions数据存储中的消息实体数据到重组缓冲区。当数组和chunk之间不匹配时,CDM复制非冗余数据块,维持原chunk的顺序。通过这种方法,原资源版本被重组。CDM在Resource Version数据存储中存储最新的资源版本号,如果发现相同资源较早的版本出现,则替换出去,保证客户端总能保证资源最新的版本。
预取管理模块(Prefetch Manager Block):预取引擎位于客户端则会有较好的预取效果。故在客户端添加预取管理模块。通过读取记录模块的访问队列,检查预取对象池(Fetched Objects),确认资源是否已经预取过。若没有预取过,则把请求发送给服务器,预取管理模块创建多个User Request线程并等待一个新的请求。当从服务器接收到响应资源时,预取管理模块检查其URL是否在预取队列中,若在则移除URL并插入到预取对象池。预取模块同时检查请求队列是否为空,若为空,当一个新用户请求入队时直接被送至服务器。当一个新的客户端请求入队时,预取管理模块暗示删除已经预取过的资源并清空Hint List数据存储。
User Requests模块接收来自预取管理模块的请求,再传递给Request模块。为了避免后来资源的预取,当从服务器接收到一个响应资源时,User Requests把响应报头的hint插入到预取队列(Prefetch List)数据存储中,把资源的URL插入到预取对象池中。
1.2 数据去重模块基本原理
文中采用的数据去重系统来源于dedupHTTP系统。其中,CDM和SDM分别工作在客户端和代理服务器端。双端数据去重系统架构如图3所示。
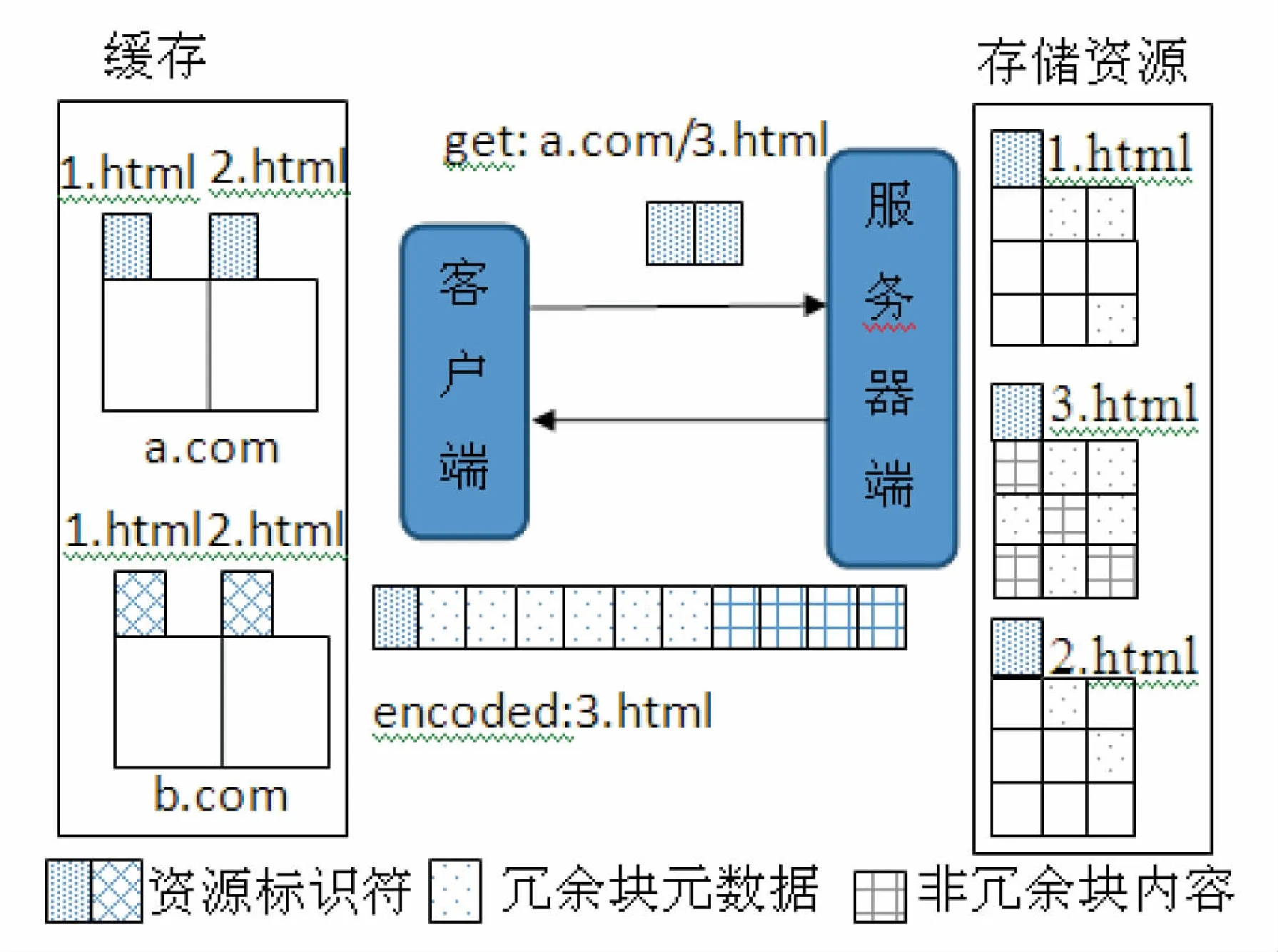
图3 双端数据去重架构
具体工作流程如下:
当SDM接收到一个给定的资源请求,检索由CDM发送的参考源标识符的一个自定义的请求报头。然后SDM从服务器中取出该资源。接收过充分响应的报头和数据后,SDM给资源分配一个新的标识符。将资源数据划分为块,块的元信息存储在数据存储文件中。在这个数据存储库中SDM保证了块的哈希索引的元信息资源的所有版本的所有块。
SDM遍历资源所有块。对每个资源块,将在参考源具有相同散列块。如果有一块没有匹配的参考源,SDM会在当前响应资源块中搜索。因此,冗余检测不仅在资源在CDM的高速缓存执行,而且在资源被送交CDM时也执行。SDM组合最终响应资源发给CDM。响应由元数据段开始。元数据的大小(字节)存储在一个自定义HTTP响应报头中。元数据的内容从响应的资源标识符开始。在每个参考源中包含了四元组,每个元组包含的信息是CDM能够在缓存中找到每一个冗余块的必需信息。具体包含的字段是当前响应的偏移量Offset,资源标识符Resource identifier,资源内部的偏移量InOffset和块的长度。
数组按照在原始响应中相应块的顺序排列。在元数据块的结尾,附加上非冗余数据内容,仍然保持原响应中的顺序。由于对该元组和非冗余数据的顺序维护,CDM仅需数组的第一偏移量就可知道如何在非冗余数据附加上冗余数据。
当CDM收到响应后,为所有的数据重建原有的资源,包括从本地缓存资源中复制块引用信息和复制接收到响应的非冗余数据内容。CDM并不存储任何一块元信息,也不需要发送或存储哈希。
通信拦截模块:负责对CDM和请求端信息做语法处理。当Communications Interceptor接收到CDM的通知时,该模块为信息添加自定义报头“X-vrs”,即客户端参考源的X-vrs报头就包含了资源标识符。Communications Interceptor把报头信息附加在HTTP请求报头上,给Requests模块,最后传给服务器。
当从代理服务器端接收到HTTP响应报文,Communications Interceptor模块对报头进行语法分析,分别从X-vrs和X-mtd报头提取资源标识符和元数据的长度。为了进一步处理拆分数据,分别进入三个不同的缓冲区,一个缓冲区存放报头信息,一个存放元数据,一个存放非冗余数据。最后又将所有数据传给CDM。
1.3 基于滑动窗口的数据块划分
基于滑动窗口的数据块划分方法主要依据块的内容划分,该方法的查重率高、分块更为合理有效[11-12]。SDM模块采用LBFS算法将服务器响应给客户端的每一个资源版本号划分为索引数据chunk。
第一步:当客户端发出一个请求时,服务器将资源划分为若干索引chunk。判断出该资源的哪些部分客户端已经存在,哪些部分是新的、需要发送的。
令ci为第i个资源流的字节,k为Karp-Rabin块的长度,b为进制的基数。Karp-Rabin块[13]的哈希如下:
H(ci…ci+k)=ci×bk-1+ci+1×bk-2+…+
ck-1×b+ck
其中,b是一个常数。
函数的应激性允许计算下一个字节的哈希,如下:
H(ci+1…ci+1+k)={[H(ci…ci+k)-ci×bk]+
ck+1}×b
第二步:选择代表资源的哈希。为了节省内存空间,选择合适的哈希作为较大数据块的边界。选择窗口机制,能够提供更好的冗余检测。分别确定最小和最大的chunk尺寸,对比期望chunk大小,基于文中方法的内容可能会造成过大的chunk或者过小的chunk。
块哈希表的查找复杂度是O(p/k),其中p是参考源中块的数量,k是一个常数。最坏情况下,参考源中不存在块信息。SDM的哈希查找算法的复杂度是O(n*m*p),其中n是当前处理的块数量,m是参考源的数量。当m相当小,例如最终用户并且缓存中只剩下很少的资源数量,大文件小容量块,将得到n*p≫m,可见算法复杂度的决定性影响因子是块的大小。
2 实验与结果分析
2.1 实验参数
系统的评价标准分别是字节节省率和延迟。前者是指每次请求所节省的字节传输作为冗余块的总和,即没有从代理发送客户端而是从客户机获得引用资源的数据块的字节数的总和。后者指对于一个给定资源,从客户端GET请求直到客户端响应该资源的时间间隔。
客户端机器配置:Intel Pentium 4,2.16 GHz,4 GB内存,操作系统Linux Mint 14-32b。服务器配置:Intel Pentium 4,3.20 GHz,6 GB内存,操作系统Linux Mint 14-32b。实验运行在带宽为54 MB/s的局域网。限制带宽下测试,模拟蓝牙有效带宽2.1 Mb/s。
工作负载中应用的各种测试是通过下载一个典型的新闻网站(www.dn.pt)3个层次的深度的文件。实验中,请求所有的工作文件,相当于客户机-服务器之间传输约20 MB的文件。具体地,最大的字节数为214 595,最小字节数为298,平均字节数29 672,总大小为19.8 MB。
客户端请求自动使用Wget实用程序。为了模拟一个真正的用户发起Web导航,引入用户请求允许预取操作之间的空闲时间,使用了Wget开关“-w10”和“randomwait”,主要为了引入一个5、15秒请求之间的随机延迟。
2.2 实验结果分析
实验一:重点分析当执行数据去重时,冗余检测效率对块大小的依赖情况。预取(PF)和数据去重(DDP)同时执行(PFON-DDPON),块的平均尺寸依次设置为32、64、128、256、512、1 024和2 048个字节。一般情况下,设置最小块的大小等于平均块尺寸的1/4,块的最大尺寸等于平均块大小的2倍。实验结果参见图4和图5。
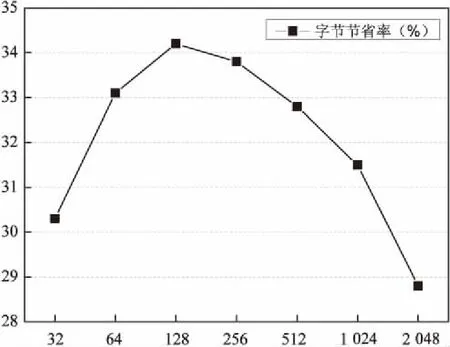
图4 PFON_DDPON相对于PFON_DDPOFF 字节节省率(带宽54 Mbs)
图4显示了PFON_DDPON时刻相对于PFON_DDPOFF时刻的字节节省率。结果表明,最好的冗余检测获得的块大小为128字节,节省了34.2%的字节数量。
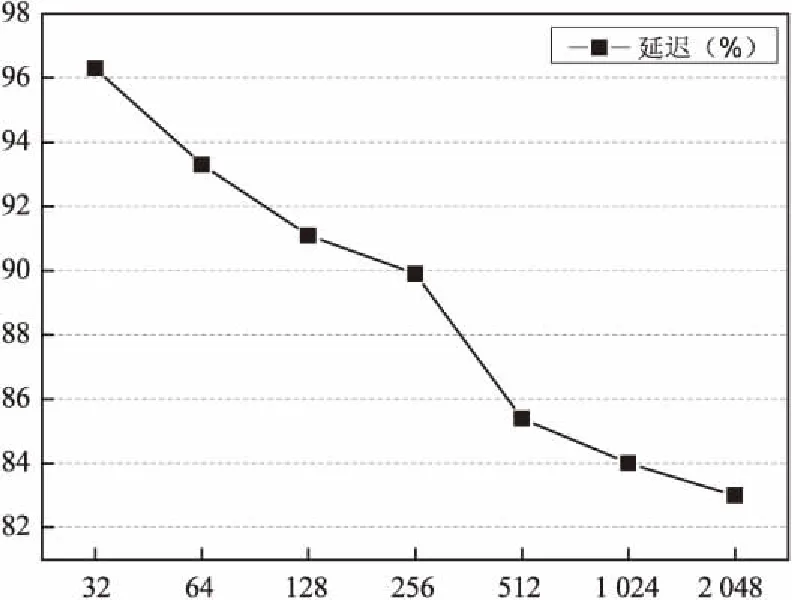
图5 相对于标准HTTP传输情况 (PFON_DDPON,带宽54 Mbs)
图5显示延迟时间和块大小成反比关系。原因是随着块尺寸的增加,块的数量减少,那么数据去重的计算开销也要增加。因此数据去重算法执行时间也要兼顾。
为了获得更高的字节节省率,设置块大小为128字节。具体实验对比了PFOFF_DDPOFF和PFOFF_DDPON,PFON_DDPOFF和PFON_DDPON。带宽设置为54 Mbs,在字节节省率方面,PFOFF_DDPON方法比PFOFF_DDPOFF方法节省了34.1%,PFON_DDPON方法比PFON_DDPOFF方法节省了34.2%。结果表明,引入数据去重技术可以节省34%的字节传输。
实验二:使用该系统传输每种资源的延迟时间与标准HTTP传输时延迟的比值对比如图6所示。对比标准HTTP传输,仅有去重时能够减少大约8%的延迟,有预取时减少的延迟更明显,分别减少14.7%和8.9%。差别的原因在于数据去重算法存在一定的计算开销。综合考虑可见,当使用预取和数据去重时,数据去重保证了一定的字节节省率,但是以适度增加的等待时间为代价,保证了系统的整体性能。
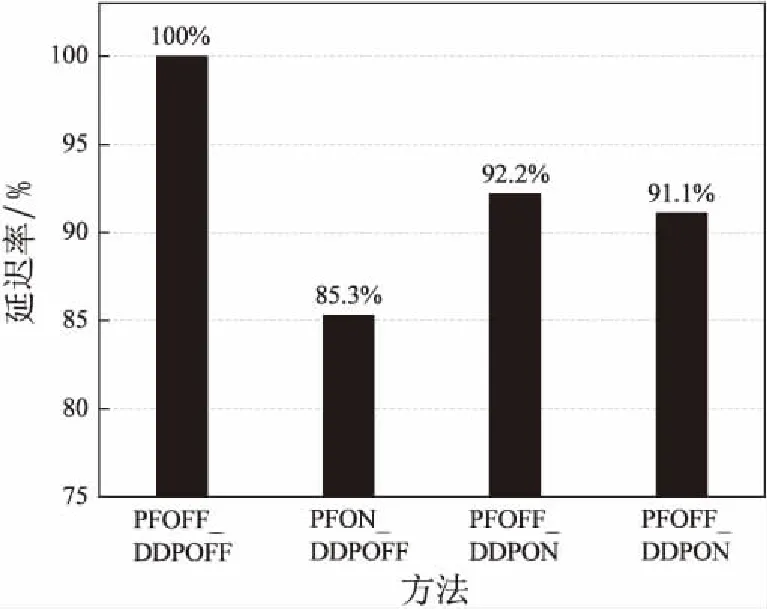
图6 相对于标准HTTP传输延迟情况
实验三:评估在可达到的冗余值中对不同带宽的影响效果。分别在LAN条件(54 Mbs)和蓝牙条件(2.1 Mbs)下进行PFON_DDPON操作的比较测试,如表1所示。

表1 不同带宽下相对于HTTP标准传输 的延迟 %
结果表明,带宽对字节节省率基本无影响。在蓝牙情况下每个资源的延迟时间减少的幅度是LAN情况下减少的一半,分别为4.4%和8.9%。由于预取频度依赖于用户请求之间的空闲时间,增加的延迟意味着请求需要更长的时间完成,因此可以减少空闲时间,从而减少预取请求启动的机会。
3 结束语
提出一种基于客户-服务器端双端去重的Web预取系统的设计方法,旨在提高网络访问效率,改善用户预期的延迟。实验结果表明,该系统一方面相对于正常传输的字节数传输量显著减少,节约了大约34%;另一方面可以实现减少大约8%的用户预期的延迟,即使因为网络的客观条件影响实际效果,也能够保证降低4%的延迟。未来将进一步研究如何更准确地判定数据去重阶段的相似块以及如何降低数据去重算法的时间开销。
猜你喜欢
台湾农业探索(2020年5期)2020-12-28
数码世界(2020年11期)2020-11-23
台湾农业探索(2020年4期)2020-10-29
计算机系统应用(2020年8期)2020-03-22
台湾农业探索(2019年5期)2019-09-10
新闻爱好者(2018年11期)2018-12-05
网络空间安全(2016年11期)2017-02-13
软件导刊(2016年11期)2016-12-22
同舟共进(2016年5期)2016-05-04
软件导刊(2015年6期)2015-06-24
