
电厂金属锅炉等离子点火装置故障预测模型研究
2019-04-15 05:45冯珑
世界有色金属 2019年2期
冯 珑
(浙江浙能兰溪发电有限责任公司,浙江 兰溪 321100)
随着工业经济的快速发展,工业企业电力需求迅猛增量,2018年中国的火力发电总量达到了49794.7亿千瓦时(同比增长6%),约为全国发电总量的73.23%,火力发电厂的大型锅炉通常采用等离子点火系统,其日常维护、调试都是亟需关注的重要课题。
等离子点火系统属于高电压大电流点火方式,实现了无油点火,其结构包括等离子点火枪、等离子煤粉燃烧器、控制系统、整流电源系统、冷却水系统、载体风系统、冷炉制粉系统、一次风在线监测系统、图像火检系统、检测元件等[1]。
等离子点火系统是整个系统的核心,它的不稳定性直接影响锅炉点火的优劣。张海等人以湖北华电襄阳发电有限公司#1机组等离子体点火改造为研究对象,介绍了非接触式300 kW等离子体点火系统的组成[2]。王兆虎等人[3,4]在2×600MW超临界抽凝供热发电机组上采用一种基于双主站网络控制的新型双层等离子点火系统,且分析该双主站结构的网络拓扑模式在特定环境下的优势。保立虎[5]采用分析了交流等离子点火燃烧器在660 MW直流锅炉上的应用情况,介绍了交流等离子点火燃烧器的工作原理,并对煤粉质量分数、一次风量、二次配风方式对锅炉启动时的点火过程和火焰稳定性进行分析。
陈海民[6]综合分析等离子点火技术在某电厂机组调试期间的应用情况,并统计分析了等离子点火技术在此期间所产生的经济效益和社会效益。
等离子点火系统中阴极、阳极是发生器的主要部件,且为导电元件,直接影响等离子的稳定性。采用日常维护历史数据对等离子点火系统进行分析,并对原来重点出现的故障前兆信息进行预测。
1 机器学习的故障预测模型
在火力电力生产企业,统计等离子点火系统的历史数据,将历史数据中影响故障现象的影响因子进行统计,但是往往有些故障现象的产生是因为某些或者某个偶发性的自变量作用下而发生的,不仅工作量大,而且存在预测的难度。传统的方法即建立简单的映射关系,而此简单的映射关系并不能很好的预测故障。根据机器学习的基本原理,建立故障预测模型。
定义1:在企业现有的影响等离子点火系统的影响因子,设为影响因子数据集X={xi},xi为第i个影响因子,且需要被预测的故障现象为Y={yi},xi,yi均为数量。
定义2:假设已知故障现象模型预测的定义损失函数LL,模型预测的等离子点火系统故障为,搭建模型的目标就是使得损失函数达到最小值。
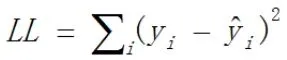
根据企业历史数据分析,影响故障发生的影响因子(原始特征)为部分所知,即X={xi}。
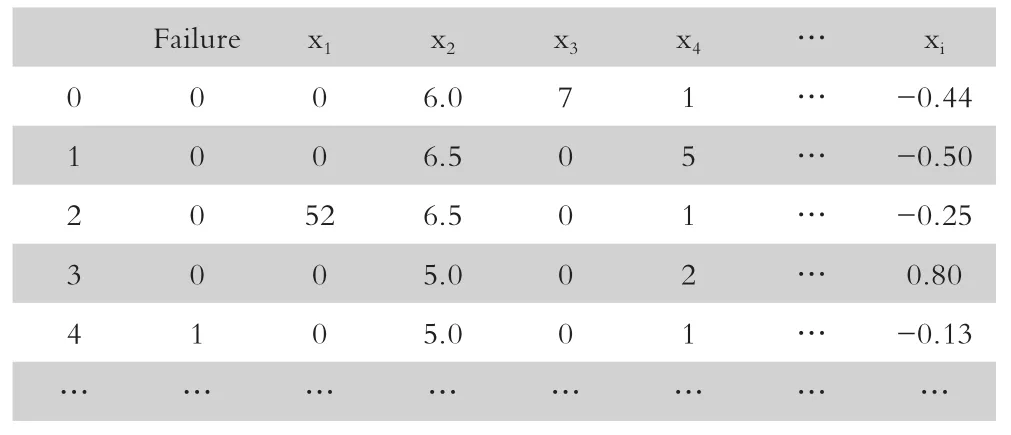
表1 根据企业建立已有的分类特征
例如,某一时间段xj作为一个分类特征,即其对故障发生起到较为必然的关系,这类分类特征即为周期性(时间周期)的分类特征,需要在模型中考虑的。
2 优化目标以及评估模型
由于目前火力发电厂历史数据有限,且并不清楚是否穷举各类分类特征,以及等离子点火系统可能出现的故障类型,故预测模型采用无监督学习(Unsupervised Learning),采用K-均值算法建立特征聚类,最小化所有数据点与其关联的聚类中心之间的距离和。
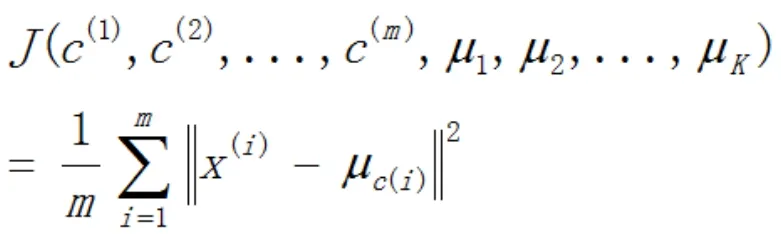
其中:
µc(i)为x(i)最近的聚类中心点,优化目标即寻找最优组合c(1),c(2),...,c(m)和µ1,µ2,...,µK。
K-均值具体算法(伪代码):

针对等离子电源柜已有的分类特征X={xi}包括额定输入电压(V)、额定输入电流(A)、电子电路额定供电电压(V)、冷却风机电源额定电压(V)、冷却风机电源额定电流(A)、冷却风机额定流量(m3/h)、额定直流输出电压(V)等,建立其数据区间,例如200A系列ABB DCS500型。

表2 等离子电源柜已有的分类特征
根据等离子柜的启动和调试特点以及采集部分其它数据进行强化,比如人为的误操作等因素,以及综合考虑非正常环境下的调试影响因子(室内温度、湿度、其它设备出现的问题的干涉、故障码等数据)。
在火电厂等离子点火系统调试过程中,也增加人为的不确定因素,例如在检查隔离变压器一、二次电缆及等离子电源柜、切换柜相应一次回路接线及对应关系正确,交流电缆相序正确,直流电缆极性正确。数据的记录需要更为规范和标准化,记录尽量全的数据变化,最优情况下能够采用部分灵敏度高的传感器进行实时监控和数据采集。例如,用1000KV摇表检查隔离变压器、等离子电源柜、切换柜一次回路绝缘特性。回路绝缘特性中绝缘数据的变化,都是至关重要。
采用基于机器学习的预测模型,可以较好的完成数据量大、数据不全、数据缺省等情况下的“数据淘金”,能有效发掘在数据背后的千丝万缕联系。通过发掘等离子点火系统故障发生背后的影响因子,建立数据与故障现象、以及故障调试的映射关系。例如:
故障报警(故障码):
SIEMENS 6RA28 F02 ABBDCS500 F38
其调试方法:
整流器三相电源进线相序错误,校对交流电源相序。
3 结论
火电厂锅炉等离子点火系统预测性可以避免在很多极端工况下出现异常,且能够有效地提供预防式警告,可以有效地最大化资源使用。
从机器学习的模型构建过程中,企业对历史大量数据的保存、格式化至关重要,企业需要充分利用好已有的数据,其数据的真实性和可靠性直接影响预测模型的准确性。
通过前期已有的技术特征进行训练、测试、评估模型,能够得到后期的特征集,并且能够找到变量之间隐藏的联系。
采用机器学习模型对火力发电厂部分重要部件进行故障预测,比较有效地进行故障发生的预判,减少损失,节约企业成本,降低作业风险。
本文尚未检查特征之间的关联性进行深入探讨,这是未来继续此课题研究的重点。
猜你喜欢
红领巾·探索(2022年5期)2022-06-02
中华养生保健(2020年7期)2020-11-16
阅读(快乐英语高年级)(2019年2期)2019-09-10
中国生物医学工程学报(2019年4期)2019-07-16
电子制作(2018年12期)2018-08-01
制造技术与机床(2017年6期)2018-01-19
中国核电(2017年1期)2017-05-17
电子制作(2017年19期)2017-02-02
消费者报道(2016年3期)2016-02-28
风能(2016年12期)2016-02-25
