
基于动态层次K-Modes的电网数据聚类分析
2019-04-14 07:37:12林红阳1翼1林1杨1马汉斌
四川电力技术 2019年6期
林红阳1,杜 翼1,刘 林1,易 杨1,蔡 菁,马汉斌
(1. 国网福建省电力有限公司经济技术研究院,福建 福州 350012;2. 国网信通亿力科技有限责任公司,福建 福州 350000)
随着电力工业的发展与电力计量体系的不断完善,在电力用户侧积累了海量的历史数据。针对既有数据,展开用户用电行为特性的挖掘,可以为电力公司开展相应电价制定与需求侧管理工作提供有益指导[1]。聚类分析是数据挖掘(data mining)的重要组成部分,作为一种无监督学习方法,根据其思想的不同,聚类算法主要可分为以下5种方法:划分法(partitioning method)、层次法(hierarchical method)、基于密度法(density-based method)、基于网格的方法(grid-based method)、基于模型法(model-based method),并且在此基础上发展出更为灵活的组合及变形。而K-means算法作为一种基础的划分法,从提出以来就受到人们的普遍关注,至今仍有不少学者对K-means及其同类型方法在应用及算法上做出研究贡献[2-11]。K-modes作为K-means的一种变形,能够对类属型数据进行分类,其主要区别在于中心和距离的定义[12]。而层次聚类法作为另一种广泛被人们使用的算法,其优势在于分类准确且可以生成直观的分类树,便于判断类的数目;但其计算量过大,算法复杂度至少为O(n2),仅适用于小规模数据聚类。也有将两种或多种传统聚类算法结合而成的新算法,例如层次K-means算法[3,11]。此类算法能够保留每种算法的优良性并弥补算法缺陷,使得算法的适应性和准确性都得到提升。下面通过引入合适的聚类算法对厦门岛内地区电力用户数据进行试验,以验证算法的可行性,为进一步推广至其他数据集筹备基础。
1 算法介绍
1.1 K-modes算法
作为一种被普遍运用于各类问题的聚类算法,K-means常用于数值型数据的分类,距离一般采用欧氏距离,所以对其他类型数据,例如类属型(0-1型)数据并不适用。作为改进,由Huang在1998年提出的K-modes算法在K-means的算法基础上引入modes取代means(中心),并提出差异匹配(matching dissimilarity)替代传统的欧氏度量(距离)。正是引入差异度量(dissimilarity measure)这种距离计算方式,使得其能对类属型数据进行有效的划分。
K-modes算法从构造思想上与K-means基本一致[6,9]。定义信息集合(X,A,Q),其中X={xi|i=1,2,…,n}表示数据集合;A={ai|i=1,2,…,m}表示数据每一维度的属性;Q={qi|i=1,2,…,k}表示k个分类,而{qi|i=1,2,…,k}表示每个类的中心(mode)。其中xij∈z,(i=1,2,…,n;j=1,2,…,m)表示样本点xi在aj属性上的取值。
定义任意两点x,y的差异度量为d:
其中,
定义目标函数为
其中,

在上述3个条件下使目标函数F达到最小值,K-modes基本实现步骤如下:
1) 随机选取k个modes。
2)计算每个数据点与k个modes的差异度量d(距离),将每个数据点分入度量值最小的类。
3)判断是否达到迭代终止条件(一般设置终止条件为分类结果不再改变),若终止迭代则返回结果,否则进入步骤4)。
4)对每一类中所有数据点在每一维度上取众数,更新每个类的mode:qzj=mode(xij|xi∈Qz),j=1,2,…,m,返回步骤2)。
1.2 层次K-means算法
K-means聚类算法复杂度为O(n)阶,即不需要进行样本点的两两距离计算,在处理一般聚类问题时速度较快。但K-means算法也存在2个公开问题:1)类数目无法自适应得到;2)算法仅能保证收敛到局部最优解。而层次聚类算法能够得到较好的聚类结果,同时可以通过聚类系谱图来指导确定类的数目,但由于其算法复杂度过大,当处理大规模数据时就会遇到困难。
由Arai于2007年提出的层次K-means[3]从一定程度上解决了这些问题。其利用所有在特定k值下运行K-means所得到的结果,这些结果可能均收敛到局部最优解,但通过大量结果所带来的信息,结合层次聚类算法对其进行转换便能确定出更为准确的K-means初始值中心点。
层次K-means算法主要步骤如下:
1) 取定k值,并进行p次重复的K-means计算,得到聚类中心点集合;
2)结合层次聚类法,对步骤1)所得的聚类中心点集合进行再聚类;
3)将步骤2)所得的聚类中心点作为K-means的初始聚类中心点,并运行K-means算法得到最终聚类结果。
1.3 层次K-modes算法
考虑到K-modes算法对类属型数据的适应性,以及其在迭代过程中与K-means算法的相似性,因此提出层次K-modes算法。将K-modes算法与层次聚类算法进行结合,继承两种算法的优点而直接作用于类属型数据。值得注意的一点是差异度量(dissimilarity measure)的计算快于同等维度的二范数计算,因此从速度上层次K-modes也比层次K-means更具优势。其算法实步骤与层次K-means类似,不过类中心必须使用mode,并且在层次聚类时也必须选取适合类属型数据的距离公式进行计算。
1.4 动态层次K-modes算法
进一步,还希望借助聚类系谱图来选取适合的k值。层次K-modes中,由于固定了k值,因此进行p次相同k值的K-modes并完成层次聚类后所生成的系谱图所呈现的划分很大程度上受到所选取k的影响,通常与初始选取的k值相同。为了克服这个弱点,提出让每次K-modes的k值变动起来,从而弱化人为选取k值的影响[14]。在这种改动下,p次K-modes带来更多的分类信息,从而能从更广范围内寻找更优的k值。
动态层次K-modes主要算法步骤如下:

2)利用层次聚类法对集合M中的modes进行分类;
3)通过系谱图选定适当的k值以及对应的modes;
4)利用步骤3)中结果作为初始条件进行一次K-modes,并返回结果。
2 数据特征提取
将曲线数据按照曲线形态进行聚类,考虑到直接利用原始数据进行聚类会忽略掉时间序列上段与段间的形态差异,造成聚类结果不合理。
如文献[13]将原始数据进行平滑后取一阶差分值,将原始矩阵X转化为差分矩阵D,其每一行为di,由一个m维行向量构成,表示第i个差分后样本;更进一步,分别将“±0.1×差分样本极差”作为阈值t(di)。
(1)
式中,j=1,2,…,m。
对所有差分样本进行式(1)处理后得到类属型矩阵C,为n×m维的矩阵。其每一行为ci,由一个m维行向量构成,以此来反映曲线形态。
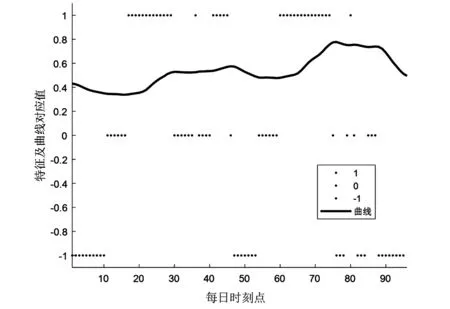
图1 特征提取
图1为数据特征提取图,图中的曲线为某样本xi在经过平滑后得到,经过差分及式(1)处理后得到的圆点,表示在每一时刻该样本曲线的升、平、降3种状态,将连续型的时间序列数据转化成类属型的离散状态值,从而提取出样本的形态特征,可利用动态层次K-modes算法进行聚类。
3 算法实验
3.1 模拟数据试验
为了检验动态层次K-modes相较于传统K-modes的优良性,首先使用计算机模拟出一个维度为10,类数目为3,类内样本量分别为500、200、50的曲线数据集,如图2至图4所示,其中双峰形类样本数为500,单峰型类样本数为200,单谷型类样本数为50。

图2 双峰型类

图3 单峰型类

图4 单谷型类
进行算法比较前,首先给出分类准确率的计算规则为
式中,ni为当前聚类结果中第i类包含正确分类中最多一类的数目。
对于传统的K-modes算法而言,k必须经由人工进行初始化。为了进行更客观的比较,假定已知类数目为k=3,并利用K-modes算法对该模拟数据进行聚类,聚类结果如图5所示。

图5 普通K-modes聚类(k=3)
如图5中各子图以及图2至图4,分类准确度仅达到CE=47.87%,即该聚类结果大部分类都未能准确对应正确分类情况。
而使用动态层次K-modes算法对此模拟数据进行聚类,并不需要人为取定k值,而仅需通过返回的系谱图来决定所希望的k值以及初始modes。取K-modes运行次数p=8,因此8次计算的k值分别为2~9。在层次聚类时选择“hamming”距离,应用“average”的类间距计算方式,得到如图6所示系谱图。

图6 聚类系谱
从图6中可见,聚类树在k=3时的高度差最为明显,可从k=3处进行截取,同时返回对应的中心(modes)。在此基础上进行一次K-modes可得到如图7所示层次K-Modes聚类图。
如图7所示,在同样k=3的情形下,动态层次K-modes相较于传统K-modes,分类准确度达到CE=76.93%,明显高于传统K-modes;并且类数目k也能被正确确定,因此其分类效果明显优于传统K-modes。

图7 层次K-modes聚类
3.2 真实数据试验
所采用的真实数据为来自厦门某地区2016年3月1日至4月13日的用户电流数据,为曲线数据。数据规模为44×9026×96,每一维度含义分别为:采集天数为44,用户变压器数目为9026,每日共96个观测值(每日隔15 min一次观测)。
考虑到用户用电曲线基本以日为周期,因此对44天内所有用户的每日96次观测分别取平均值,将数据降维,得到矩阵X(9026×96),其中矩阵每行xi为一个样本,由一个96维行向量构成。
对X运用式(1)的数据处理方法,将其转化成类属型数据矩阵,并利用动态层次K-modes对数据进行分类。取K-modes的运行次数p=8,在层次聚类时同样选择“hamming”距离,类间距计算方式选择“average”得到聚类系谱图,如图8所示。
对图8聚类树进行水平截断,具有明显高度差的分类情形为k=3、k=6。因此分别选取k=3和k=6的情形,给出中心(modes)作为初始值,进行K-modes聚类。
在k值为3的情形中,得到图9所示分类结果。


图9 层次K-modes聚类(k=3)
如图9中3个子图所示,前两个类特征明显,属于双峰型类,但峰型却有差异;第一个类双峰集中在30~70时段内,第二类中两个峰在分布在24~50以及65至85时段内。在k=3的情形中,此算法抓住了曲线数据的主要形态特征给出合理的分类结果。
在k值为6的情形中,得到如图10所示的分类结果。

图10 层次K-modes聚类(k=6)
相较下,图10所示的各类峰型均表现出较明显的差异。相较于模拟数据,真实数据表现出了更复杂的分布特性。正是由于这种复杂性,很难简单给出唯一的分类结果;正如图8中聚类树的枝干在k=3、k=6时都有明显分化。
4 结 语
传统K-modes算法与层次聚类算法结合,成功地将层次K-means的算法优点移植到类属型数据中。并且所提出的动态层次K-modes算法还可以通过聚类系谱图确定k值,一定程度上解决了k值须初始给定的公开问题。算法也具有更强的适应性和异常点识别等优良性质,可以对真实数据给出有效聚类结果。
考虑到动态层次K-modes算法从结果上虽然明显优于传统K-modes算法,但在进行聚类时仍会出现一定的错分现象,在后续工作中考虑引入robust思想,无须将所有样本带入聚类迭代过程,而是仅选取一部分重要样本进行迭代,以此提高算法准确度。同时在特征提取方面,也希望引入更精细化的自适应阈值给定,从数据角度提高聚类质量。
猜你喜欢
卫星应用(2022年7期)2022-09-05 02:36:02
卫星应用(2022年3期)2022-05-23 13:44:30
卫星应用(2022年1期)2022-03-09 06:22:20
华北电力大学学报(社会科学版)(2021年2期)2021-07-21 02:27:36
环球慈善(2019年6期)2019-09-25 09:06:24
电子测试(2017年15期)2017-12-18 07:19:27
中国奶牛(2017年2期)2017-03-22 02:04:46
求学·理科版(2017年1期)2017-03-02 19:57:15
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
