
距离度量学习算法的精确性研究
2019-04-12 00:00:00许小媛黄黎
现代电子技术 2019年21期





摘" 要: 距离度量学习是机器学习领域较为活跃的研究课题之一,文中利用UCI(加州大学欧文分校)数据库的数据对度量学习算法进行比较研究。为了寻找一种可靠的没有明确定义标志的算法,选择四种算法在UCI的六个数据集上对距离矩阵进行比较。每个样本数据集的性质(尺寸和维度)是不同的,因此算法的结果也不同。编码相似度算法在大多数情况下表现良好。在未来的实际应用领域,对于提高无标记数据和相似集的距离度量学习算法的精确性提供了研究基础。
关键词: 距离度量学习; 机器学习; 距离矩阵; 马氏距离; UCI数据库; 比较研究
中图分类号: TN911.1⁃34; G231.5" " " " " " " " " "文献标识码: A" " " " " " " " " "文章编号: 1004⁃373X(2019)21⁃0150⁃04
Abstracts: Distance metric learning is one of the most attractive research subjects in machine learning. The objective of this research is to compare and research the distance metric learning algorithms by using the data in UCI database. To find a reliable algorithm without any symbols with clear definition, four algorithms are selected. The comparison of distance matrixes is made on 6 datasets of UCI. The nature (size, dimension) of each dataset is different, so the algorithms′ results may vary. The coding similarity algorithm performs well in most cases. In the field of practical application in the future, the research foundation for the accuracy of metric learning algorithms is provided for unlabeled data and similar sets.
Keywords: distance metric learning; machine learning; distance matrix; Mahalanobis distance; UCI database; comparative study
0" 引" 言
距离度量学习或者称为相似度学习,是指在给定的训练样本集上,通过学习得到一个能够有效反映数据样本间的距离或者相似度的度量矩阵, 目的是使在新的样本空间中,相同类别的样本相似度更大,也就是分布更紧密;不同类别的样本相似度更小,也就是分布更松散。距离度量学习算法[1⁃5]在计算机视觉及模式识别等领域应用非常广泛,对距离度量学习算法的研究已成为近年比较活跃的研究热点之一,因此,该项研究具有重要的意义和价值。
距离度量学习算法依据不同分类标准,有多种分类方法。例如,依据学习方式的不同,可以将度量学习算法分为有监督的距离度量学习算法[6⁃7]和无监督的距离度量学习算法[7]两类。有监督的距离度量学习算法的主要思想是对于训练集的样本信息建立优化函数,获得能够合理反映样本空间特性的度量矩阵,然后利用算法进行训练。文献[7]提出最大化互信息熵的思想,通过此方法进行距离度量学习。无监督的距离度量学习算法倾向于通过寻找集群来分散数据,对数据进行标记。其基本思想是将原始数据集通过降维映射到一个低维子空间中, 从而得到关于原始数据集更紧密的低维表示。文献[8]提出基于AML 算法,结合核学习技术,提出非线性自适应距离度量学习算法。文献[9]提出自适应距离度量学习(Adaptive Metric Learning,AML)算法,该算法将距离度量学习和聚类结合,将原始数据集进行降维,形成新的更紧密的低维子空间后,再进行距离度量学习。
本文研究主要是基于无监督的距离度量学习算法。选择单位矩阵、邢氏算法、信息论度量学习算法和编码相似度算法,在选取的不同数据库上进行比较,对提高距离度量学习算法的精确性提供研究基础,对于实际应用中度量学习算法的选择提供依据。
1" 算" 法
基于约束条件(未标记的数据和相似集)选择四种算法对距离矩阵进行比较。这四种算法分别是:单位矩阵或欧几里得距离;邢氏算法[10](一种迭代算法);信息论的度量学习[11](一种迭代算法);编码相似度算法[12]。
四种算法可以用不同的方式确定相似性问题。
1.1" 邢氏算法
邢氏算法是可以考虑用来解决问题的最简单的算法。 一般的思路是最小化相似点与相异点之间的距离。为此考虑一个距离矩阵,并进行优化:
该算法的主要缺点是集合的收敛性不确定。有时根据数据集或初始条件可能无法计算出一个很好的结果,并被卡在一个循环中,每个迭代步骤产生的新矩阵都远离了前一个矩阵。在某些数据集上,还可能出现[A=0],这是不应该的。
在本文中,该算法仅运用于学习全矩阵[13]。
1.2" 信息论的度量学习算法
式中:[ξ0]是描述相似性与差异性之间临界值的集合;[ξi,j]是[S]或[D]中[i,j]的临界值;[γ]控制着对任意矩阵[A0]进行学习的矩阵与对预计算的阈值进行调整之间的平衡问题,这个问题可以有很多参数,用来获得更好的计算结果,但是在算法开始时,必须设定好[A0],[ξ]和[γ] 的初始值,因为它们很难进行预先估算。
1.3" 编码相似度
编码相似度指的是一个数据包含了另外一个数据的信息量的多少。相似度codsim[x,x]表示[x]传递了[x]的信息量,这是一个基于分布的方法。信息量的大小通过两个分布之间编码长度的差异进行评估:一个分布认为[x]和[x]之间并不存在真正的联系,另一个分布则认为有。需要注意,这个算法只使用相似的数据对。编码长度为[clx-logpx],最终计算公式为:
该算法通过降低维度避免了过拟合[9]。虽然它不需要进行迭代,但是计算过程很复杂(逆矩阵),而且在求解逆矩阵的过程中容易出现一些问题。为了避免这种情况,将零特征值尽量减少。在本文的实验中,没有计算出任何维度的减少。
2" 实验方法
在每个数据集中,给定每个数据的分类,通过相似或相异的数据对,对每个可能的数据对进行标记,作为算法的输入。在此基础上,进行双重交叉验证,另外还需要一个阈值来评估其相似度。本文使用的算法并没有给出这个阈值,因此在评估过程中要筛选出一个阈值。在给定的距离矩阵和几个阈值中,计算几个混合矩阵。选择阈值,以便描述有用值的整个范围:从对相异数据的所有映射中,再到相似数据的所有映射中进行选择,然后计算接受者操作特征曲线(ROC),并且模型的精度由ROC曲线下半部分的面积(AUC)给出,ROC曲线如图1所示。
对于信息论度量学习算法(ITML),需要初始化[ξ0]。按照经验对它进行初始值设定,尽管这种选择是完全随机的:所有数据对的距离分布中,5%为相似性,95%表现为相异。然后研究不连续的数据对整体结果的影响。这些集合表现出了精确的相似度,但人造的数据不具备这个属性。因此,选择通过“翻转”一些数据对的相似度来添加一些矛盾数据。该方法不是添加新对,而是修改现有的对,因此数据集不具有矛盾对,但包含相似性评估错误。
由于可能产生不一致性,在一个真正的数据集中选择将它们从测试集中排除。人造的编码不能选择,这只会降低结果准确性,并且对算法的比较也没有帮助。
3" 实验结果
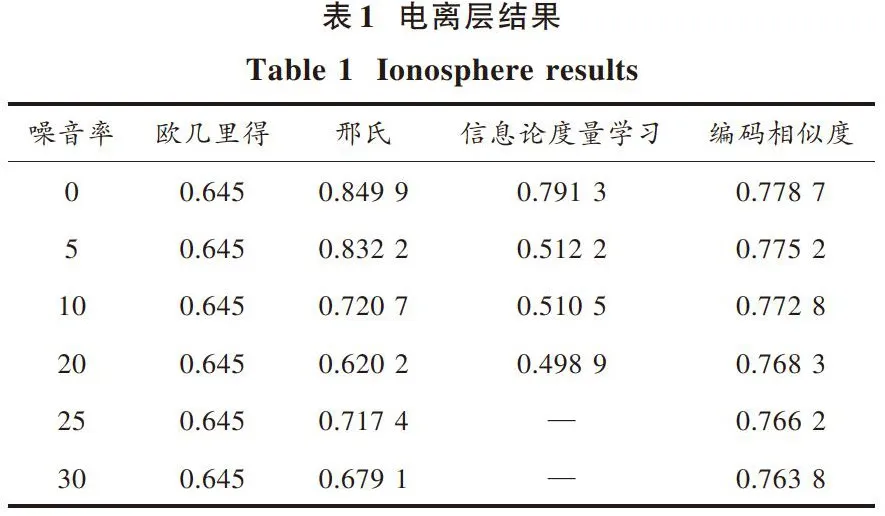
3.1" 电离层
电离层结果如表1所示。由表1可知,运用欧几里得定理得到的结果不理想;邢氏算法结果较好,但是当内部关联数据出现时,健壮性较差;编码相似度算法给出了基本一致的稳定性。
3.2" 虹膜(IRIS)
虹膜层结果如表2所示。由表2可知,小规模的IRIS数据集的尺寸解释了相似性准确度上的急速下降。根据欧几里得定理得出的结果,使用学习过的距离函数效果不好。
3.3" 酒" 类
酒类结果如表3所示。由表3可知,编码相似度算法在正确的数据集上效果很好。但意外的是,邢氏算法针对错误的数据却得出最好的结果。而且这些精确度与欧几里得距离得出的结果非常接近。
3.6" 平衡量表
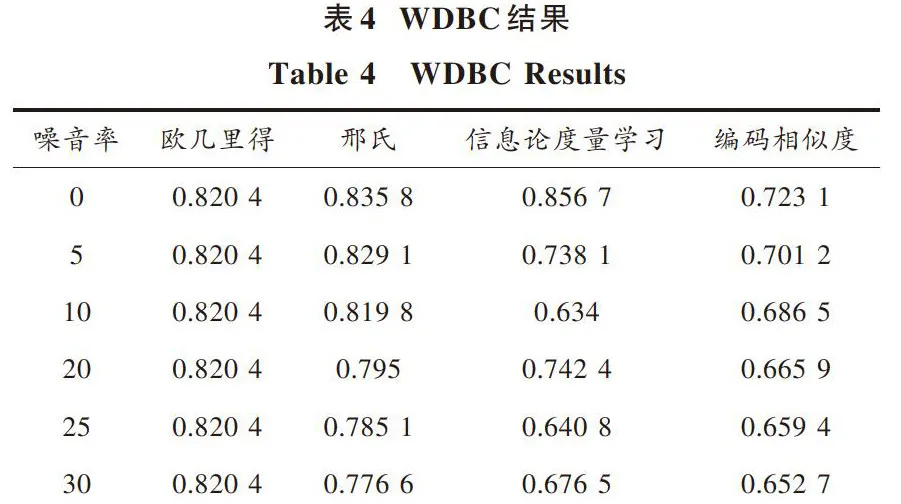
平衡量表结果如表6所示。由表6数据可得出,邢氏算法出现很多错误数据,因此至少在某一时间段或某些迭代的情况下是不能收敛的,就如同信息论度量学习算法一样。这可能是由数据集尺寸导致的。
4" 结" 论
本文研究的主要结论是基于数据驱动算法的准确性中,算法并不处于主导地位的。此外,明确定义的集合的结果并不能代表随机产生的数据集合的结果。当没有明确分类时,相似性的区别和分类问题值得研究。
由于真实数据集中可能存在错误,可以选择一种具有良好稳固性的算法。实验证明,数据的不同特性影响到算法的结果。虽然加入非相关数据的方法是模拟部分坏数据集的一种快速而有效的方法,但无法评估相似性。相似性不能理解为二元评估(相似/不相似),也不能被视为二次函数。相似性评价的误差可以遵循一定的模式,而不是完全随机地分布。这些“选择”也可以是个人的。如果测试集由某一用户创建,那么距离矩阵就反映了对相似度的描述。数据可以是近距离的,也可以是连续的。此外,本文研究仅限于Mahanalobis距离[3⁃10]。
某些算法的结果不理想,但并不应该受到限制。比如,如果编码相似性算法很好,就可以用来学习一个很好的距离函数,并且可以通过在线捕获的数据(如ITML的在线版本)来调整矩阵。关于人造数据集和非二元距离的领域,在未来的实际应用中还有很多值得研究的地方。
参考文献
[1] BAR⁃HILLEL A, HERTZ T, SHENTAL N, et al. Learning a mahalanobis metric from equivalence constraints [J]. Journal of machine learning research, 2005, 6: 937⁃965.
[2] DAVIS J V, KULIS B, JAIN P, et al. Information⁃theoretic metric learning [C]// Proceedings of the 24th International Conference on Machine Learning. New York, NY, USA: ACM, 2007: 209⁃216.
[3] GLOBERSON A, ROWEIS S T. Metric learning by collapsing classes [C]// Advances in Neural Information Processing Systems(NIPS). [S. l.: s.n.], 2005: 451⁃458.
[4] HILLEL A B, WEINSHALL D. Learning distance function by coding similarity [C]// Proceedings of the 24th International Conference on Machine Learning. New York, NY, USA: ACM, 2007: 65⁃72.
[5] WANG X Y, HUA G, HAN T X. Discriminative tracking by metric learning [C]// Proceedings of the 11th European Confe⁃rence on Computer Vision. Heraklion, Greece: Springer, 2010: 200⁃214.
[6] CHEN J H, ZHAO Z, YE J P, LIU H. Nonlinear adaptive distance metric learning for clustering [C]// Proceedings of the 2007 International Conference on Knowledge Discovery and Data Mining. California, USA: ACM, 2007: 123⁃132.
[7] YE J P, ZHAO Z, LIU H. Adaptive distance metric learning for clustering [C]// Proceeding of the 2007 Computer Society Conference on Computer Vision and Pattern Recognition. Minnesota, USA: IEEE, 2007: 1⁃7.
[8] JIANG Liangxiao, CAI Zhihua, WANG Dianhong, et al. Bayesian citation⁃KNN with distance weighting [J]. International journal of machine learning and cybernetics, 2014, 5(2): 193⁃199.
[9] 王燕,李凤莲,张雪英,等.改进学习率的一种高效SVD++算法[J].现代电子技术,2018,41(3):146⁃150.
WANG Yan, LI Fenglian, ZHANG Xueying, et al. An efficient SVD++ algorithm for learning rate improvement [J]. Modern electronics technique, 2018, 41(3): 146⁃150.
[10] 万韩永,左家莉,万剑怡,等.基于样本重要性原理的KNN文本分类算法[J].江西师范大学学报(自然科学版),2015,39(3):297⁃303.
WAN Hanyong, ZUO Jiali, WAN Jianyi, et al. The KNN text classification based on sample importance principals [J]. Journal of Jiangxi Normal University (Natural science), 2015, 39(3): 297⁃303.
[11] 沈媛媛,严严,王菡子.有监督的距离度量学习算法研究进展[J].自动化学报,2014,40(12):2674⁃2686.
SHEN Yuanyuan, YAN Yan, WANG Hanzi. Research progress on supervised distance metric learning algorithm [J]. Journal of automation, 2014, 40(12): 2674⁃2686.
[12] RUTKOWSKI L, JAWORSKI M, PIETRUCZUK L, et al.The CART decision tree for mining data streams [J]. Information sciences, 2014, 266: 1⁃15.
[13] XING E P, NG A Y, JORDAN M I, et al. Distance metric learning with application to clustering with side⁃information [C]// Advances in Neural Information Processing Systems(NIPS). [S. l.: s.n.], 2003: 505⁃512.
[14] JINDALUANG W, CHOUVATUT V, KANTABUTRA S. Under⁃sampling by algorithm with performance guaranteed for class⁃imbalance problem [C]// Computer Science and Engineering Conference. [S. l.: s.n.], 2014: 215⁃221.
[15] WANG B, JIANG J Y, WANG W, et al. Unsupervised metric fusion by cross diffusion [C]// Proceedings of the 2012 Confe⁃rence on Computer Vision and Pattern Recognition. Providence, RI, USA: IEEE, 2012: 2997⁃3004.
