
基于贝叶斯和F⁃measure感知机的分类器设计
2019-04-12 00:00:00马占杰杨淑莹
现代电子技术 2019年21期




摘" 要: 当样本特征向量交织时,分类很容易出错。为解决这个问题,提出一种基于Bayes和F⁃measure的分类器算法。采用替代方法评估分类器的性能正受到关注,特别是对于不平衡的问题。该算法利用F⁃measure分析不平衡数据的分类准确度,将类概率密度函数引入判据,并采用梯度下降法得到准则函数。文中将所提出的方法与传统方法进行比较,实验结果表明,该方法能够有效提高识别的准确率和精确度。
关键词: 分类; F⁃measure; 不平衡数据; 后验概率; 准确率; 实验验证
中图分类号: TN02⁃34" " " " " " " " " " " " " "文献标识码: A" " " " " " " " " " " " " 文章编号: 1004⁃373X(2019)21⁃0125⁃05
Abstract: A classifier algorithm based on Bayes and F⁃measure is proposed to solve the problem that the classification is prone to error when the sample feature vectors are intertwined. The alternative methods used for the performance evaluation of classifiers are receiving increasing attention, especially for unbalanced data classification. The algorithm is used to analyze the classification accuracy of the unbalanced data by means of F⁃measure. The probability density function is introduced into the criterion, and the gradient descent method is used to obtain criterion function. The proposed method is compared with the traditional ones, in this paper. The experimental results show that the proposed method can effectively improve the accuracy and precision of recognition.
Keywords: classification; F⁃measure; imbalance data; posterior probability; accuracy rate; experimental verification
0" 引" 言
F⁃measure又称为F⁃Score,是IR(信息检索)领域的一个评价标准,常用于评价分类模型的好坏,也是作为不同类型预测问题的性能指标,包括二分类、多标签分类(MLC)以及结构化输出预测的某些应用,如文本分块和命名实体识别等。与二分类中的错误率和多标签分类(MLC)中汉明损失等方法相比,F⁃measure方法在少数类和多数类之间都表现出很好的平衡性,因此,在非平衡数据的情况下更适合。
传统的模式识别方法通常需要多个类别的样本,因此需要设计两个或多个类别的分类器。构建分类器方法有很多,如贝叶斯[1]、决策树、人工神经网络[2]、遗传算法、支持向量机(SVM)[3]遗传编程、粗糙集[4]、模糊判别等,在这些分类方法中,贝叶斯方法已经成为最引人注目的焦点之一,因为它的精度高[5],可以有效地处理不完整的数据。然而,当样本特征向量相互交织时,贝叶斯分类器容易出错。为了提高贝叶斯分类器的性能,提出一些方法和技术,例如,树扩张型贝叶斯(TANB)、Generalized Naive Bayes分类器[6]。 TANB算法通过查找属性之间的依赖关系来减轻朴素贝叶斯中任何属性之间的独立性假设。在学习参数方面,TANB模型比朴素贝叶斯模型面临更多的困难,特别是在训练集数据较少时。GNB认为整个数据集只有一个概率依赖关系,当整个数据集单一分布时,GNB性能会更好,但是,当整个数据集不是单一分布时,GNB性能较差,近年来,评估措施在分类器分析和设计中起着至关重要的作用。准确率、召回率、精度、F⁃measure、Kappa、ACU等新的措施已经被提出[7]。F⁃measure被认为是测试有效性的重要措施[8]。由于Bayes和F⁃measure的优势,本文结合了两者对不平衡数据进行分类。
当大多数类的输出数量远远超过其他几个类时,很难将错误的样本与这几个类别分开。近年来,研究人员在不平衡问题上做出了很大的努力,并得到了更好的解决方案[9],例如,改变类分布,结合决策成本,在学习过程中用性能测量来替代标准算法的准确性。大多数方法更适合于平衡域中的分类。
本文提出一种不同的方法来解决这个问题,给出一种基于贝叶斯和F⁃measure的新的分类器算法。所提出的算法不会改变类的分布和任何决策成本。首先计算后验概率,当样本不在混合交叉域时,本文应用Beyes分类器进行分类。其次,当样本处于混合交叉域时,本文采用新的框架对易错分类区进行分类。
1" 在条件分布密度的混合交叉域内的F⁃measure感知器
当样本在混合交叉域内时,贝叶斯分类器容易出错。感知器算法适用于小样本,它是收敛算法,具有计算简单、存储容量小和易于实现等优点。F⁃measure在分类器分析和设计中起着至关重要的作用。F⁃measure被认为是测试有效性的有效措施。
1.1" F⁃measure评估标准
当样本特征相互依存时,分类容易出错。为了解决这个问题,本文提出一种新的分类算法。
在本文中假设有两个类[ω+],[ω-],定义[C={ω+,ω-}]为可能类的集合,其中,[ω+]表示为正相关类,[ω-]表示为负相关类。TP(Ttrue Positive)表示类别为[ω+]的样本被系统正确判定为类别[ω+]的数量,FN(False Negative)表示类别为[ω+]的样本被系统误判定为类别[ω-]的数量,显然有[P=]TP+FN;FP(False Positive)表示类别为[ω-]的样本被系统误判定为类别[ω+]的数量,TN(True Negative)表示类别为[ω-]的样本被系统正确判定为类别[ω-]的数量,显然有[N=]FP+TN。
1.2" 普通感知器
由于函数[f(W)]的数值解通常只是某种意义上的最优解。 定义准则函数,然后在最大或最小的条件下使此准则函数找到解[f(W)]。梯度下降法确定准则函数[J(W)],然后选择初始值[W(1)],迭代公式如下:
当[u(X)gt;0]时,表示样本正确分类,[W(k+1)=W(k)],无需修改权重;否则,当[u(X)≤0]时,表示样本错误分类,[W(k+1)=W(k)+CX(k)],需要修改权重。普通感知器只考虑调整单个样本,而不考虑样本分布的调整。为了解决这个问题,本文提出F⁃measure感知器算法。
1.3" F⁃measure的最优边界确定
传统的贝叶斯分类器是使后验概率最大化,改进的算法是使F⁃measure最大化。最大化F⁃measure等于最小化[E]:
当偏微分方程达到稳态时,式(21)得到满足。
本文首先计算样本的后验概率。如果后验概率大于阈值,则样本不在容易出错的区域中。如果后验概率的最大值小于或等于阈值,则样本处于容易出错的区域,然后采用新方法进行分类。对于[n]维空间,样本由矢量[X=(x1,x2,…,xn)T]表示,识别函数如下:
矢量的方向主要取决于最大分量的值。负梯度矢量表示最速下降的方向。当梯度矢量为零时,它可以达到函数的极值。如果[∂E∂W=0],[E]可以达到极值,得到式(21)的最优解。[W(k)]被定义为[W]的第[k]个迭代解,[W(k+1)]是第[k+1]次迭代解。
2" 实验结果
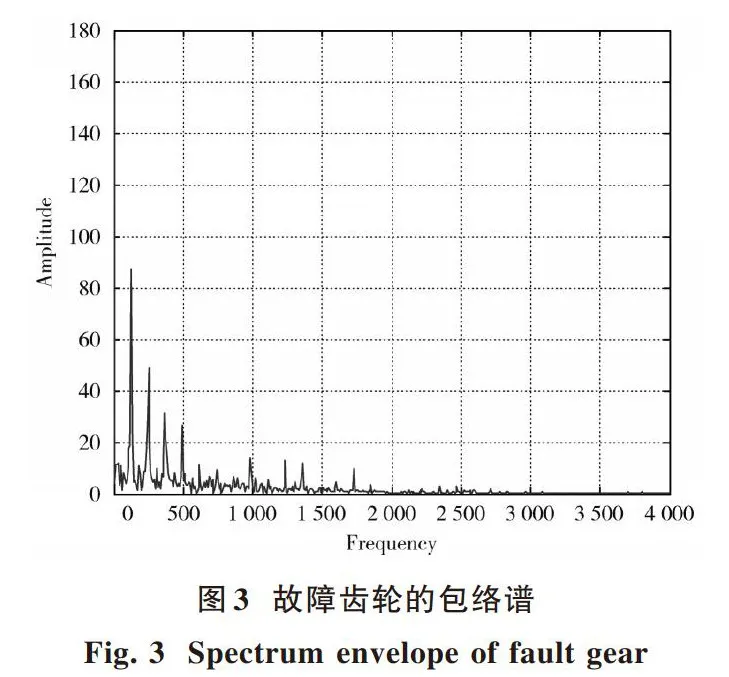
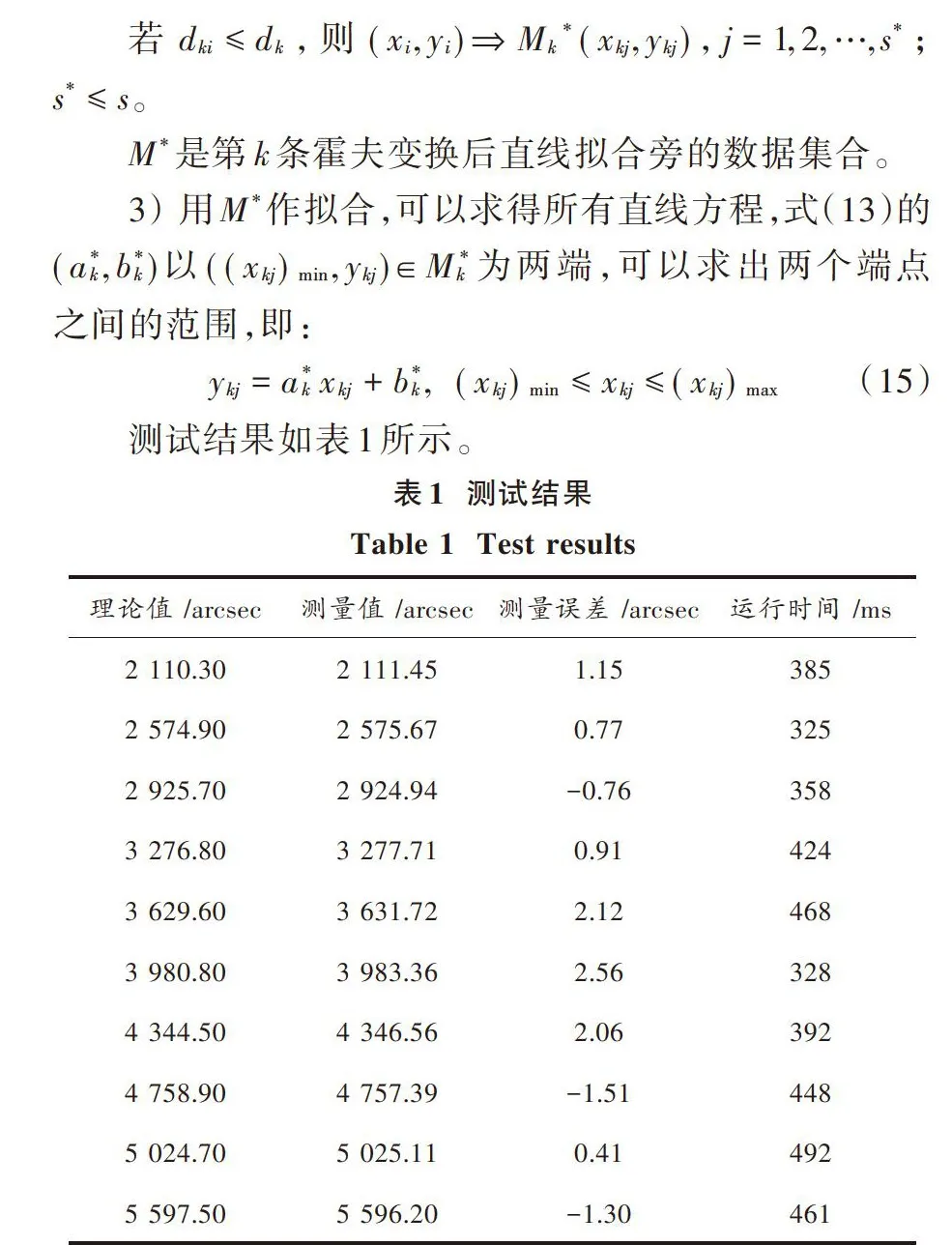
将本文提出的方法用于齿轮故障诊断,使用100个正常齿轮样本和30个异常齿轮样本的不平衡数据集。小波包和包络谱的能谱用于故障诊断。正常齿轮有[100×9]个特征,异常齿轮有[30×9]个特征。去噪后的齿轮故障信号波形如图1所示。故障信号由3层小波包分解,得到8个频带能量,如图2所示。小波包分解后的能量分布可以清楚地显示故障信息齿轮,证明故障诊断有用。异常齿轮的包络谱如图3所示。
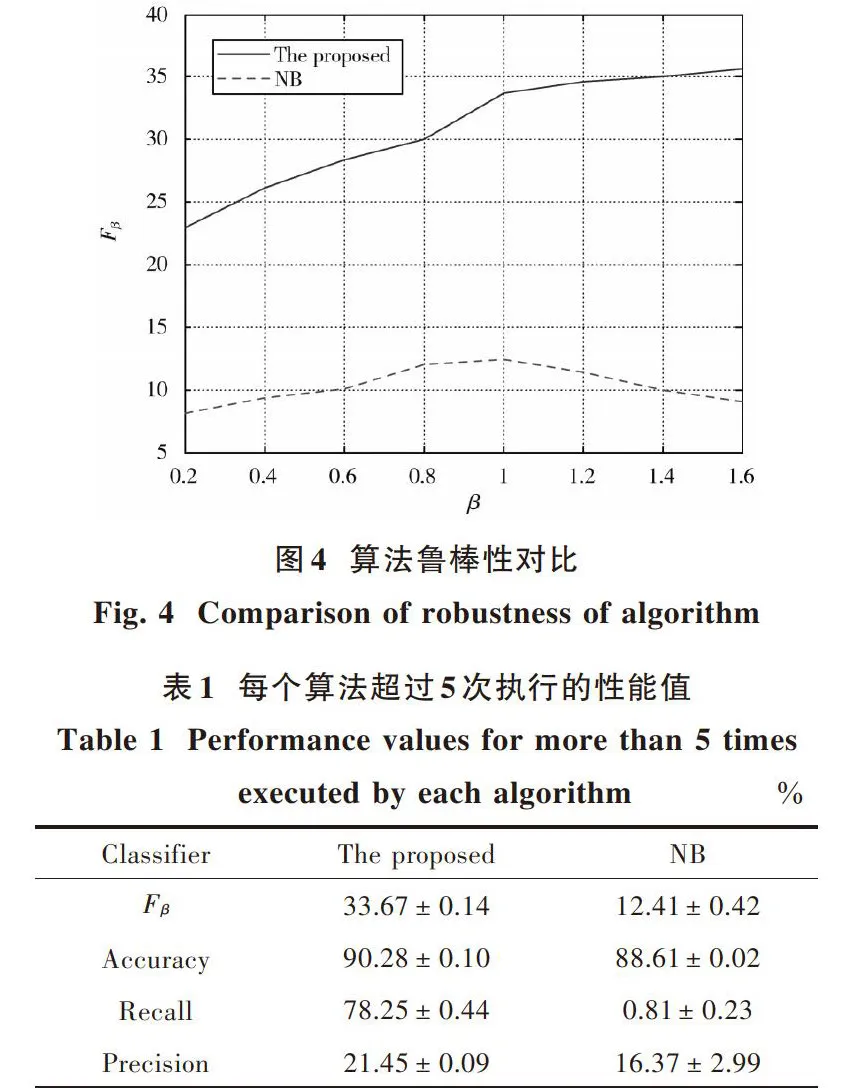
将本文提出的算法与传统的朴素贝叶斯分类器进行比较。图4显示了所提出的算法和传统的朴素贝叶斯分类器在[β]变化时的鲁棒性。表1给出了实验结果的详细情况,每个算法执行5次。所提出算法的参数为 [β=1],[C=1]。实验的收敛速度取决于初始向量[W(1)]和[C]。从表1可以看出,朴素贝叶斯分类器具有差的F⁃measure、召回率和准确率。本文所提出的算法得到了更好的F⁃measure,得到了更高的召回率和准确率。由于样本的特征向量不是完全独立的,所以本文提出的方法比传统的朴素贝叶斯分类器具有更高的识别率。
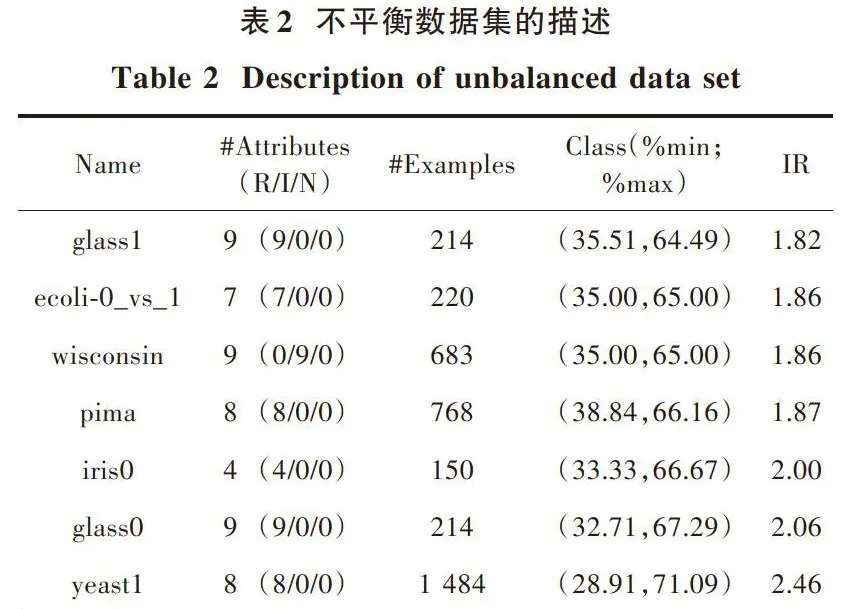
对于实验验证,用KEEL数据集[10]中提供的公开实际数据进行了实验验证。对多类数据集进行修改以获得两类不平衡问题,以便一个或多个类的联合成为正类,其余类中的一个或多个类的联合被标记为负类。表2给出了实验研究中使用的不平衡数据集的描述。表2中显示的信息包括:数据集名称(数据集);属性数(Atts.);样本数(Ex.);少数群体和多数群体的百分比(%min;%max);不平衡比(IR)。
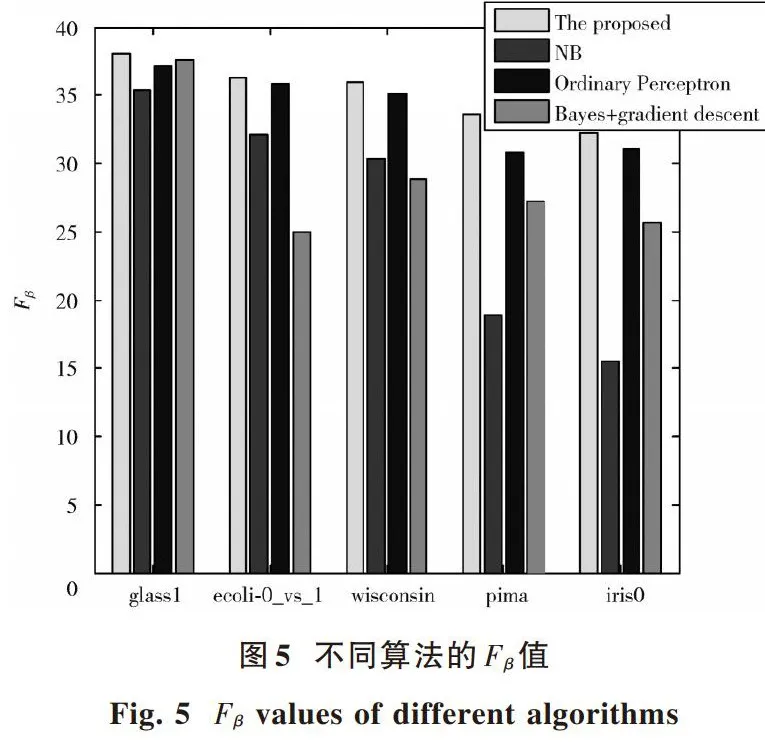
在研究中,将提出的算法与普通感知器、结合贝叶斯和梯度下降的感知器以及传统的朴素贝叶斯分类器进行比较。每个算法进行10次交叉验证。应用95%置信水平的双尾[t]检验系统地比较NB算法、普通感知器算法和结合贝叶斯和梯度下降的感知器算法的分类精度。在图5中,通过使用5个数据集获得[Fβ]值。所提出的算法具有最好的结果。表3给出详细实验结果。实验结果表明,随着不平衡数据的增加,NB、普通感知器和结合贝叶斯和梯度下降的感知器算法的分类精度逐渐降低。与这三种方法相比,本文提出方法的分类精度最高。虽然提出方法的准确性随着失衡数据的增加而减小,但平均准确率为90.42%。
3" 结" 论
本文提出一种新的分类算法处理不平衡问题,尤其在样本特征相互依赖时。首先计算后验概率以判断样本是否位于易错区域。采用该算法对易于误分类的样本进行分类,在研究中,将所提出的算法与传统的分类器方法进行了比较,实验结果证明了该方法的优越性。
参考文献
[1] JIANG R, YU J, MAKIS V. Optimal Bayesian estimation and control scheme for gear shaft fault detection [J]. Computers amp; industrial engineering, 2012, 63(4): 754⁃762.
[2] WU J D, CHAN J J. Faulted gear identification of a rotating machinery based on wavelet transform and artificial neural network [J]. Expert systems with applications, 2009, 36(5): 8862⁃8875.
[3] BANSAL S, SAHOO S, TIWARI R, et al. Multiclass fault diagnosis in gears using support vector machine algorithms based on frequency domain data [J]. Measurement, 2013, 46(9): 3469⁃3481.
[4] RAJESWARI C, SATHIYABHAMA B, DEVENDIRAN S, et al. A gear fault identification using wavelet transform, rough set based ga, ann and c4. 5 algorithm [J]. Procedia engineering, 2014, 97: 1831⁃1841.
[5] LIU H, HAN M. A fault diagnosis method based on local mean decomposition and multi⁃scale entropy for roller bearings [J]. Mechanism and machine theory, 2014, 75: 67⁃78.
[6] LARSEN K. Generalized naive Bayes classifiers [J]. ACM SIGKDD explorations news letter, 2005, 7(1): 76⁃81.
[7] SARAVANAN N, RAMACHANDRAN K I. A case study on classification of features by fast single⁃shot multiclass PSVM using morlet wavelet for fault diagnosis of spur bevel gear box [J]. Expert systems with applications, 2009, 36(8): 10854⁃10862.
[8] MATÍAS D M, GUZMAN H, MARCELO F, et al. A new framework for optimal classifier design [J]. Pattern recognition, 2013, 46(8): 2249⁃2255.
[9] SUN Y, WONG A K C, KAMEL M S. Classification of imba⁃lanced data: A review [J]. International journal of pattern recognition and artificial intelligence, 2009, 23(4): 687⁃719.
[10] ALCALÁ J, FERNÁNDEZ A, LUENGO J, et al. Keel data⁃mining software tool: data set repository, integration of algorithms and experimental analysis framework [J]. Journal of multiple⁃valued logic and soft computing, 2011(17): 255⁃287.
