
基于大数据分析方法的微博热点建模与预测
2019-04-12 00:00:00王哲刘贵容彭润亚
现代电子技术 2019年21期

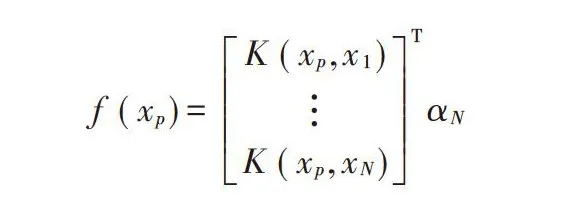

摘" 要: 微博热点反映一个社会对某一事件的看法,其受到许多因素的影响,具有一定的规律性,同时具有一定的随机性,数据规模庞大,传统方法无法准确、客观描述,微博热点预测错误大,为此设计基于大数据分析方法的微博热点建模与预测方法。首先对微博热点变化特点进行分析,找到引起微博热点预测错误大的原因,然后收集微博热点历史数据,通过聚类分析选择最优样本点组成训练样本,减少数据的规模,最后引入大数据分析方法建立微博热点预测模型,并与其他微博热点预测方法进行对比测试,所提方法的微博热点预测精度超过95%,预测误差远小于当前其他微博热点预测方法,而且建模与预测时间明显减少,加快了微博热点建模与预测效率,具有更高的实际应用价值。
关键词: 微博热点分析; 网络管理; 大数据分析; 预测模型; 微博热点建模; 预测效率
中图分类号: TN911.1⁃34; TP391" " " " " " " " " "文献标识码: A" " " " " " " " " " 文章编号: 1004⁃373X(2019)21⁃0073⁃04
Abstract: A microblog hotspot modeling and forecasting method based on large data analysis method is designed. The characteristics of microblog hotspot change are analyzed to find out the reasons for the large errors in microblog hotspot prediction. The historical data of microblog hotspots is collected. The optimal sample points are selected by clustering analysis to form training samples and reduce the size of data. The prediction model of microblog hotspots is established by introducing big data analysis method, and is tested and compared with other microblog hotspot forecasting methods. The accuracy of this method is more than 95%, and its prediction error is much less than that of other micro⁃blog hotspot prediction methods. Moreover, the time of modeling and prediction is obviously reduced, which speeds up the efficiency of microblog hotspot modeling and prediction, and has high practical application value.
Keywords: microblog hotspot analysis; network management; large data analysis; prediction model; microblog hotspot modeling; prediction efficiency
0" 引" 言
近年来,随着互联网应用的不断深入,网络成为一个多元开放平台,网络上的舆情直接影响人们生活、工作以及社会的稳定。在网络舆情中,微博热点是一种描述社会热点问题突发事件等的观点和建议[1⁃3]。一些积极的微博热点可以推动社会的前进,另一些负面的微博热点如反动的思想、虚假的信息迅速扩散,会影响社会稳定和人身安全,因此对微博热点的预测及监控成为当前一个重大的研究课题[4⁃6]。
准确的微博热点建模和预测可以帮助政府对负面事件进行及时控制,维持社会的稳定,相对于一般的博客,微博内容的实时性更强,同时其与移动终端结合,扩散速度更快,传统微博热点建模和预测方法为多元回归分析,多元回归分析从微博热点数据中提取一些特征项,研究特征之间的变化关系,然后建立一种描述特征之间变化关系的数学表达式,从而实现微博热点的预测[7]。但是多元回归分析主要反映特征之间的线性变化关系,实际上微博热点特征之间同时存在着非线性变化关系,这样使得多元回归分析的微博热点预测准确性差。随后提出基于聚类分析的微博热点建模方法,其是一种定量分析方法,聚类分析方法可以对微博热点数据之间的关联性进行挖掘,首先提取微博热点问题中的关键词,并对关键词进行打分,然后对微博热点类别进行划分,该方法只能区别微博热点的类型,对微博热点将来变化的趋势无法预测,因此缺陷十分明显[8]。随后出现了基于灰色理论的微博热点预测方法、基于神经网络的微博热点预测方法,灰色理论需要的微博热点样本小,预测速度快,但是其微博热点预测误差比较大[9]。神经网络需要的微博热点样本数据多,此时,其微博热点预测精度高;反之,如果微博热点样本数量少,那么预测结果不稳定,而且建模时间比较长[10⁃11]。随着现代统计学理论的发展,近年来出现了大数据分析方法,通过对问题的原始数据进行分析,然后采用机器学习算法对数据进行分析,找到隐藏在其中的变化规律,在网络流量、电力负荷预测等领域得到了成功的应用[12]。
本文结合微博热点的周期性、随机性、数据规模大等特点,针对当前微博热点建模与预测方法存在的缺陷,提出基于大数据分析方法的微博热点建模与预测方法,并与其他微博热点预测方法进行仿真对比测试,本文方法的微博热点单步预测精度超过95%,多步预测误差也处于实际范围内,相对于当前其他微博热点预测方法,预测误差更小,建模与预测效率得到提升。
1" 建模与预测原理
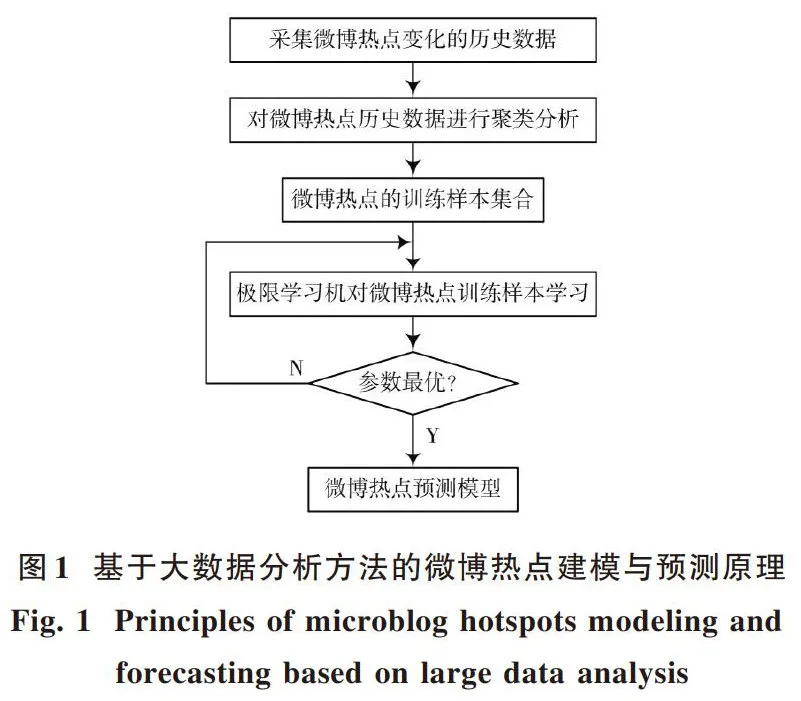
基于大数据分析方法的微博热点建模与预测原理为:首先收集微博热点的相关数据,如历史点击率、回帖数等,然后对数据进行聚类分析,找到与待预测点相关的样本作为训练样本,最后采用极限学习机对训练样本进行学习,并确定极限学习机相关参数,构建微博热点预测模型,并对其性能进行分析,具体如图1所示。
2.1" 微博热点数据的聚类分析算法
当前聚类分析的方法很多,如模糊聚类算法、K均值聚类算法等,相对于其他聚类算法,K均值聚类算法的迭代次数少,可以很好地将微博热点原始数据根据聚类中心划分为多种类型,其具体工作步骤为:
Step1:设原始微博热点数据集合为[I={xi,i=1,2,…,n}],共有[K]个类别,它们均有一个聚类中心,即[Zj(I)," "j=1,2,…,k]。
Step2:根据式(1)计算微博热点样本和每一个聚类中心之间的距离[D(xi,Zj(I))]:
Step3:如果满足条件[D(xi,Zk(I))=min{D(xi,Zj(I))}],则表示样本[xi]属于该类样本集合。
Step4:采用式(2)对聚类结果好坏进行评价。
Step5:如果满足[JC(I)-JC(I-1)lt;ζ],那么聚类终止,否则迭代次数增加,采用式(3)计算新聚类中心,并转到Step2继续迭代。
经过以上步骤,可以将待预测的微博热点样本划归到相应的微博热点类别中,将该类别中所有的微博热点样本作为训练样本。
2.2" 极限学习机的微博热点建模与预测
构建微博热点的训练样本,那么采用极限学习机可以建立如下预测模型:
要建立最优微博热点预测模型,首先要得到权值[βN],根据KKT最优化条件解得:
由于微博热点变化具有非线性、随机性,因此引入满足Mercer′s条件的核矩阵,具体为:
式中[K(xi,xj) ]表示核函数。
由于径向基核函数具有通用性,而且十分简单,因此选择其为[K(xi,xj) ],具体为:
基于极限学习机的微博热点输出结果为:
3" 微博热点建模与预测性能的验证
3.1" 微博热点原始数据
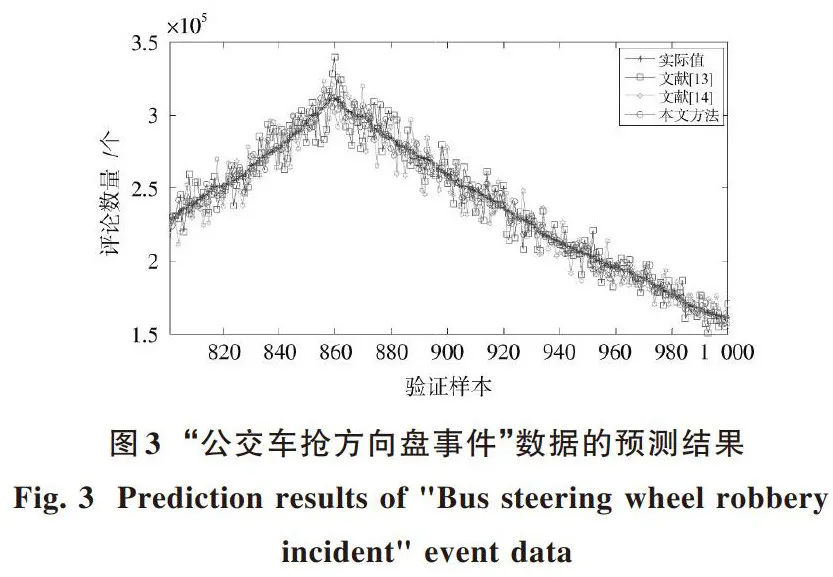
为了分析大数据分析方法的微博热点建模与预测效果,选择当前一个微博热点话题作为研究对象,其为“公交车抢方向盘事件”,其变化曲线如图2所示,最后200个数据作为验证数据,其他作为训练数据。为了使本文方法的实验说服力更强,选择文献[13⁃14]的微博热点预测模型进行对比实验。
3.2" 微博热点预测结果分析
三种方法的“公交车抢方向盘事件”数据预测结果如图3所示,对“公交车抢方向盘事件”数据预测结果进行分析可知:
1) 文献[13⁃14]的“公交车抢方向盘事件”数据预测误差大,“公交车抢方向盘事件”数据预测精度低,无法准确描述“公交车抢方向盘事件”数据的随机性变化态势,难以获得理想的微博热点预测效果。
2) 本文方法的“公交车抢方向盘事件”数据预测精度高,预测误差低于文献[13⁃14]的微博热点预测方法,主要是因为本文方法首先引入了聚类分析对“公交车抢方向盘事件”数据进行处理,选择了最优训练样本,然后引入极限学习机对“公交车抢方向盘事件”的变化特点进行建模,提高了“公交车抢方向盘事件”的预测精度。
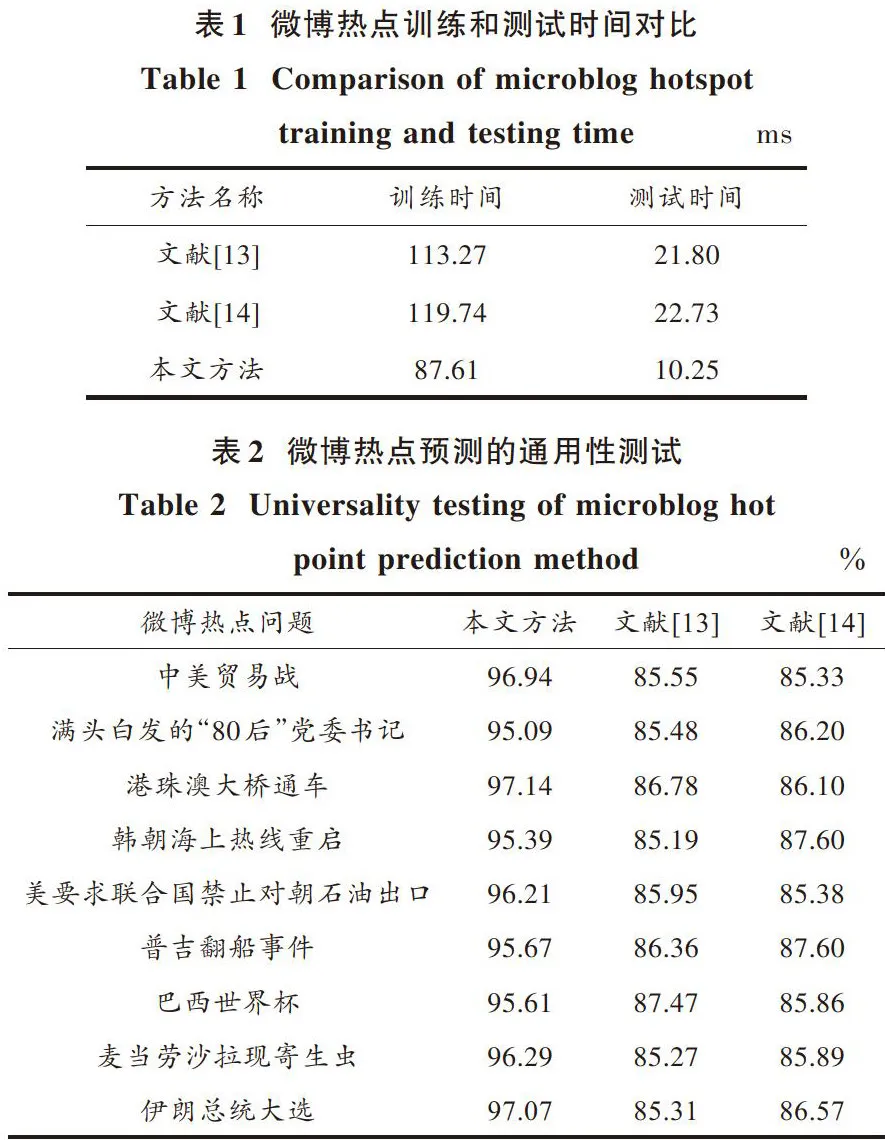
统计三种方法的训练和测试时间(单位:ms),结果如表1所示。从表1可知,本文方法的微博热点建模的训练和测试时间更短,这是因为通过引入聚类分析对微博热点样本数据进行预处理,减少了训练样本的规模,加快了聚类分析对微博热点建模速度。
3.3" 本文方法的通用性测试
为了分析本文方法的微博热点预测通用性,采用当前9个典型微博热点作为测试对象,预测精度如表2所示。从表2可以看出,本文方法的微博热点预测精度平均值超过了95%,达到了网络舆情监控的要求,具有较好的通用性,但是对比方法的微博热点预测结果不稳定,微博热点平均预测精度低,难以获得较好的微博热点结果预测。
4" 结" 论
为了解决当前微博热点建模与预测过程中存在的不足,本文提出了基于大数据分析方法的微博热点建模与预测方法,并采用具体数据对其进行测试。通过引入聚类分析对微博热点样本数据进行预处理,选择重要的样本组成训练样本,减少微博热点建模计算复杂度,建模时间大幅度减少,解决了当前方法对大规模微博热点数据建模效率低的缺陷。通过引入极限学习机对微博热点样本数据的周期性、随机性变化特点进行拟合,全面描述微博热点的发展趋势,使得微博热点的预测精度得到提高,微博热点的预测误差变小,充分说明了本文方法的微博热点预测效果要优于当前微博热点的建模与预测方法,解决了当前方法微博热点预测误差大的缺陷。本文方法是一种预测精度高、速度快的微博热点建模方法,同时为其他具有相似变化特点的问题提供了一种建模预测思想,具有广泛的应用前景。
参考文献
[1] 孙念,李玉强,刘爱华,等.基于松散条件下协同学习的中文微博情感分析[J].浙江大学学报(工学版),2018,52(8):1452⁃1460.
SUN Nian, LI Yuqiang, LIU Aihua, et al. Microblog sentiment analysis based on collaborative learning under loose conditions [J]. Journal of Zhejiang University (Engineering science), 2018, 52(8): 1452⁃1460.
[2] 叶永君,李鹏,周美林,等.面向领域的高质量微博用户发现[J].中文信息学报,2018,32(7):109⁃115.
YE Yongjun, LI Peng, ZHOU Meilin, et al. Domain specific high⁃quality microblogging user detection [J]. Journal of Chinese information processing, 2018, 32(7): 109⁃115.
[3] 金海.基于改进神经网络算法的微博热点预测系统设计[J].现代电子技术,2018,41(12):157⁃160.
JIN Hai. Design of micro⁃blog hot spot prediction system based on improved neural network algorithm [J]. Modern electronics technique, 2018, 41(12): 157⁃160.
[4] 朱海龙,云晓春,韩志帅.传播加速度的微博流行度预测方法[J].计算机研究与发展,2018,55(6):1282⁃1293.
ZHU Hailong, YUN Xiaochun, HAN Zhishuai. Weibo popula⁃rity prediction method based on propagation acceleration [J]. Journal of computer research and development, 2018, 55(6): 1282⁃1293.
[5] 朱颢东,杨立志,丁温雪,等.基于主题标签和CRF的中文微博命名实体识别[J].华中师范大学学报(自然科学版),2018,52(3):316⁃321.
ZHU Haodong, YANG Lizhi, DING Wenxue, et al. Named entity recognition of Chinese microblog based on theme tag and CRF [J]. Journal of Central China Normal University (Natural sciences), 2018, 52(3): 316⁃321.
[6] 刘培磊,唐晋韬,王挺,等.基于词向量语义聚类的微博热点挖掘方法[J].计算机工程与科学,2018,40(2):313⁃319.
LIU Peilei, TANG Jintao, WANG Ting, et al. A twitter hotspot mining method based on sematic clustering of word vectors [J]. Computer engineering science, 2018, 40(2): 313⁃319.
[7] 李依霖,朱嘉奇,吴云坤,等.一种微博热点事件子话题的可视分析方法[J].中国科学技术大学学报,2017,47(1):48⁃56.
LI Yilin, ZHU Jiaqi, WU Yunkun, et al. A visualization method for analyzing sub⁃topics of hot events in microblogs [J]. Journal of University of Science and Technology of China, 2017, 47(1): 48⁃56.
[8] 刘培玉,侯秀艳,朱振方,等.基于热度联合排序的微博热点话题发现[J].计算机科学与探索,2016,10(4):573⁃581.
LIU Peiyu, HOU Xiuyan, ZHU Zhenfang, et al. Micro⁃blog hot topic detection based on heat co⁃ranking [J]. Journal of frontiers of computer science and technology, 2016, 10(4): 573⁃581.
[9] 孙曰昕,马慧芳,师亚凯,等.融合词语关联关系的自适应微博热点话题追踪算法[J].计算机应用,2014,34(12):3497⁃3501.
SUN Yuexin, MA Huifang, SHI Yakai, et al. Self⁃adaptive microblog hot topic tracking method using term correlation [J]. Journal of computer applications, 2014, 34(12): 3497⁃3501.
[10] 谢思发,林琛,苏旋,等.Hadoop平台的微博热点事件挖掘[J].小型微型计算机系统,2014,35(4):797⁃801.
XIE Sifa, LIN Chen, SU Xuan, et al. Mining hot event from microblog with Hadoop [J]. Mini⁃micro systems, 2014, 35(4): 797⁃801.
[11] 张贵红,李中华.基于数据挖掘技术的微博热点话题预测[J].现代电子技术,2017,40(15):52⁃55.
ZHANG Guihong, LI Zhonghua. Micro⁃blog hot topic forecas⁃ting based on data mining technology [J]. Modern electronics technique, 2017, 40(15): 52⁃55.
[12] 蒋玉婷.支持向量机修正ARIMA误差的微博热点预测[J].计算机应用与软件,2014,31(9):187⁃190.
JIANG Yuting. Microblogging hot topic prediction based on correcting ARIMA error by support vector machine [J]. Computer applications and software, 2014, 31(9): 187⁃190.
[13] 姬建新.捕鱼算法优化核极限学习机的微博热点话题预测[J].激光杂志,2015,36(1):128⁃131.
JI Jianxin. Hot topic prediction of micro⁃blog based on kernel extreme learning machine and fishing algorithm [J]. Laser journal, 2015, 36(1): 128⁃131.
[14] 饶浩,文海宁,林育曼,等.改进的支持向量机在微博热点话题预测中的应用[J].现代情报,2017,37(3):46⁃51.
RAO Hao, WEN Haining, LIN Yuman, et al. Application of optimized support vector machine in microblog hot topic prediction [J]. Journal of modern information, 2017, 37(3): 46⁃51.
