
大数据环境下基于云计算的图书馆用户信息挖掘技术研究
2019-04-12 00:00:00张凤霞
现代电子技术 2019年21期





摘" 要: 为了应对大数据环境下图书馆个性化信息服务的发展趋势,提供更加精准的用户服务,构建基于Hadoop云计算平台的图书馆数据挖掘系统,并设计一种新型混合决策树算法。首先,设计包含4个层次的数据挖掘系统架构。然后,在算法层提出一种采用混合策略的决策树算法,该算法结合分布式改进的SPRINT算法和并行化的朴素贝叶斯算法,以便满足HDFS和MapReduce的运作方式,从而能够在Hadoop平台上进行实现。Hadoop集群环境的用户信息测试结果表明,相比单一的SPRINT算法和朴素贝叶斯算法,提出的新型混合决策树算法具有最佳的数据挖掘分类性能。
关键词: 大数据; 云计算; Hadoop; SPRINT; 朴素贝叶斯; 决策树
中图分类号: TN911.2⁃34; TP393" " " " " " " " " "文献标识码: A" " " " " " " " " " 文章编号: 1004⁃373X(2019)21⁃0036⁃05
Abstract: In order to deal with the development trend of library personalized information service in big data environment, a library user information mining system based on Hadoop cloud computing platform is constructed, and a new hybrid decision tree algorithm is designed. The data mining system architecture consisting of four levels (computing storage layer, Hadoop platform layer, algorithm layer and user interaction layer) is designed, and then, a decision tree algorithm based on hybrid strategy is proposed in the algorithm layer. The algorithm combines the improved distributed SPRINT algorithm and the parallelized naive Bayesian algorithm to meet the operation mode of HDFS and MapReduce, so that it can be used in Hadoop, and implemented on the Hadoop platform. The results of user information testing in Hadoop cluster environment show that the new hybrid decision tree algorithm has the best data mining classification performance in comparison with the single SPRINT algorithm and naive Bayes algorithm.
Keywords: big data; cloud computing; Hadoop; SPRINT; naive Bayes; decision tree
0" 引" 言
随着全球互联网和现代移动网络等技术的发展,数据呈现爆炸式增长的态势,传统数据库系统己经很难满足大数据时代的需求。云计算的出现很好地解决了此类海量数据的存储问题,并为相关数据挖掘处理应用提供了技术支撑。然而,云计算信息数据时代的来临,导致普通用户在面对众多图书的选择问题时无法快速找到自己需要的对象,这就是典型的图书馆个性化用户信息服务需求。如何在海量的图书馆用户信息中通过大数据挖掘技术寻找出符合用户需求的结果,从而提供高精准度的个性化需求服务,是现阶段图书管理领域的研究重点和难点[1⁃2]。
因此,本文设计一种基于Hadoop云计算平台的图书馆数据挖掘系统。首先,利用Hadoop平台的海量数据存储和分布式计算能力,设计包含4个层次(计算存储层、Hadoop平台层、算法层和用户交互层)的数据挖掘系统架构。其次,为了提高数据的处理性能,本文在算法层中提出一种采用混合策略的决策树算法,通过将SPRINT算法和朴素贝叶斯算法有效结合,并分别进行并行化处理从而能够在Hadoop平台上运作。测试结果验证了所提混合算法的可行性。
1" 研究问题与主要思想描述
目前,由Google提出的分布式计算模型Hadoop是主流的云计算平台框架,具有经济、可靠、扩容能力强、并行性好、效率高等诸多优点[3]。Hadoop大数据平台帮助政企、金融、教育等多个行业及领域实现了海量数据的计算存储管理、数据深度挖掘以及品牌舆情等多样化。为了支持对应用数据高吞吐量访问,Hadoop采用了分布式文件系统(Hadoop Distributed File System,HDFS) [3]。此外,为了将数据分散到集群的各台机器上,以便提高计算效率,Hadoop具有MapReduce并行运行模型。然而,传统的串行大数据挖掘算法不能有效地在Hadoop平台上执行,即无法应对海量数据挖掘问题。
因此,研究人员为了解决上述问题提出了许多方法。文献[4]提出一种面向大数据挖掘的Hadoop框架K均值聚类算法,将大数据划分成许多数据块,在Reduce和Map阶段进行加权融合。文献[5]设计一种Hadoop下基于朴素贝叶斯分类的大数据挖掘方法,分析了MapReduce计算模型。文献[6]通过Hadoop系统中的MapReduce模型对改进支持向量机SVM过程进行处理,提高了海量文本数据分类的效率。
但是上述单一的经典数据挖掘分类算法(如决策树算法、支持向量机SVM等)在处理海量图书馆用户信息数据时总显得力不从心,无法在准确率方面获得较好的结果。因此, 本文在图书馆用户信息Hadoop挖掘系统中提出一种采用混合策略的决策树算法,该算法结合了分布式改进的SPRINT算法和并行化的朴素贝叶斯算法,从而符合HDFS和MapReduce的工作模式。
2" 基于Hadoop云计算平台的信息挖掘系统设计
2.1" 关键技术
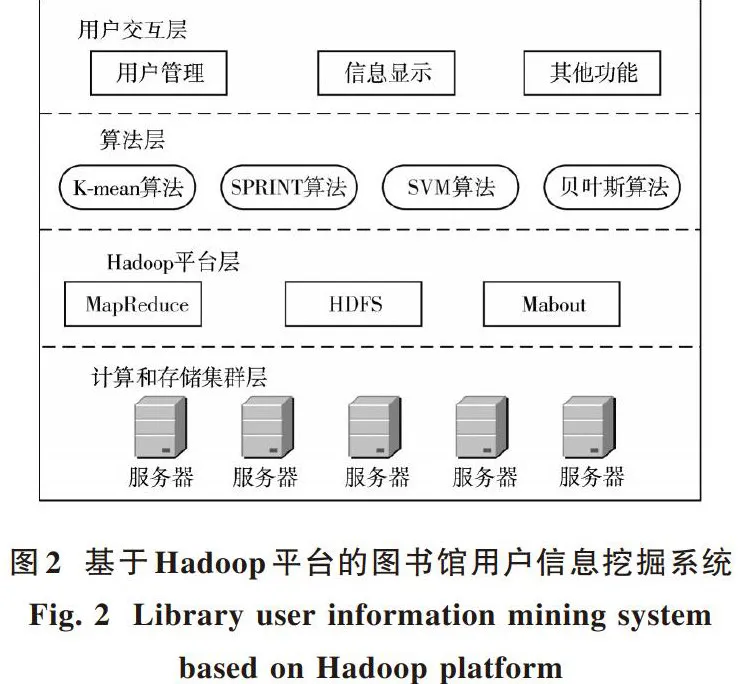
Hadoop云计算平台包含分布式文件系统HDFS和MapReduce计算模型[7]两个关键技术。分布式文件系统HDFS具有一次写入多次读取的能力,实现了高度容错,较大的访问带宽特点避免了网络阻塞,降低了对硬件的要求,实现了一定意义上的数据批量处理。而MapReduce计算模型是Hadoop平台实现超大规模数据并行运算的关键,其本质为一种软件编程架构(模式),能够通过Hadoop集群上的多个节点访问HDFS上存储的分散数据且进行并行计算,避免大量数据的复制传输操作,有效节约了网络带宽,其标准的运作方式如图1所示[8]。
2.2" 系统框架
基于Hadoop云计算平台的信息挖掘系统必须充分发挥HDFS和MapReduce的作用,将数据存储和数据挖掘任务工作分配到Hadoop集群中的各个节点上。因此,本文设计的信息挖掘系统框架如图2所示,主要包括计算存储层、Hadoop平台层、算法层和用户交互层,其中算法层是研究的重点,负责快速有效地处完成数据的相应挖掘任务。
3" 提出的新型图书馆大数据挖掘算法
经过研究分析,传统的经典数据挖掘分类算法有许多在数据挖掘系统的算法层可以实现并行化,但是单一的分类算法在处理海量图书馆用户信息数据时仍旧存在准确率不够理想的问题。因此本文提出一种新的混合型图书馆大数据挖掘算法,将SPRINT算法和朴素贝叶斯算法有效结合。
3.1" SPRINT算法的分布式改进
首先,要对典型的SPRINT算法[9]进行分布式改进。SPRINT算法属于决策树算法,但是不同于ID3、C4.5和CART等算法,在对数据样本集判断最佳分裂属性的度量时使用的是Gini指标。Gini值的计算公式如下:
式中:[S]表示一个集合;[Pi]表示种类[i]出现的频率;[n]为种类的总数。
如果将集合[S]分裂为两个子集[S1]和[S2],则两者之间的Gini值为:
式中:[m]表示集合[S]中数据记录的总行数;[m1]和[m2]分别表示集合[S1]和[S2]中数据记录的总行数。
为了有效利用图1中MapReduce框架的映射功能(Map),需要进行分布式改进,因此,将SPRINT决策树算法中位于相同层的所有Node树节点的工作,映射到不同的Reducer进行分布式操作。然后,仅需不断迭代调用过程就能够实现所有节点的分裂,从而建立所需的决策树。Map函数的伪代码如下:
输入:训练样本集
输出:根据Key排序后lt;Key,valuegt;键值对
格式化处理;
初始化lt;Key,valuegt;值,进行combine操作;
处理后的键值对输出到文件中;
3.2" 朴素贝叶斯算法的并行化
贝叶斯分类的基础是概率推理[10],可表示为[PCx1,x2,…,xn],其中[C]表示类别变量,[X={x1,x2,…,xn}]表示属性变量集合,[xi]为特征。根据贝叶斯定理,朴素贝叶斯概率模型的定义如下:
为了在Hadoop平台上实现朴素贝叶斯算法,需要对其进行并行化改进。在Map阶段的操作同SPRINT算法一致,而将Reduce阶段分为两个步骤。第一步需要获取概率信息文件,即获取每个属性在不同类别变量中的平均值[E(X)]和标准差[D(X)]。假设连续属性服从高斯分布,两者的计算方式如下:
根据第一轮得到的有关概率文件,利用式(5)完成第二步的分类,得到不同类别的概率乘积并按照从小到大排序选取最小值对应的结果作为样本类别。
3.3" 混合决策树算法的实现
利用SPRINT算法和朴素贝叶斯算法相结合的方法实现数据挖掘分类的流程如图3所示。可以看出,混合决策树算法的Map阶段如3.1节伪代码所示,Reduce阶段利用SPRINT算法构造决策树,然后分别对其每个叶子节点上的数据集执行3.2节中朴素贝叶斯算法的式(6)和式(7)得到有关概率文件,最后利用计算概率乘积并按照从小到大排序,选取最小值对应的结果作为样本类别。
4" 实验结果与分析
4.1" 实验环境
为了对本文提出的新型混合决策树数据挖掘算法进行分析和验证,进行Hadoop集群测试。虚拟机中搭建一个包含3个节点的Hadoop集群环境(1个master,2个slaves)。每个集群节点的硬件环境为: Intel Core i5 2.8 GHz处理器,4 GB内存,500 GB硬盘。软件环境为:CentOS 6.0操作系统,Hadoop 1.0.4版本,Java JDK。
4.2" 数据预处理
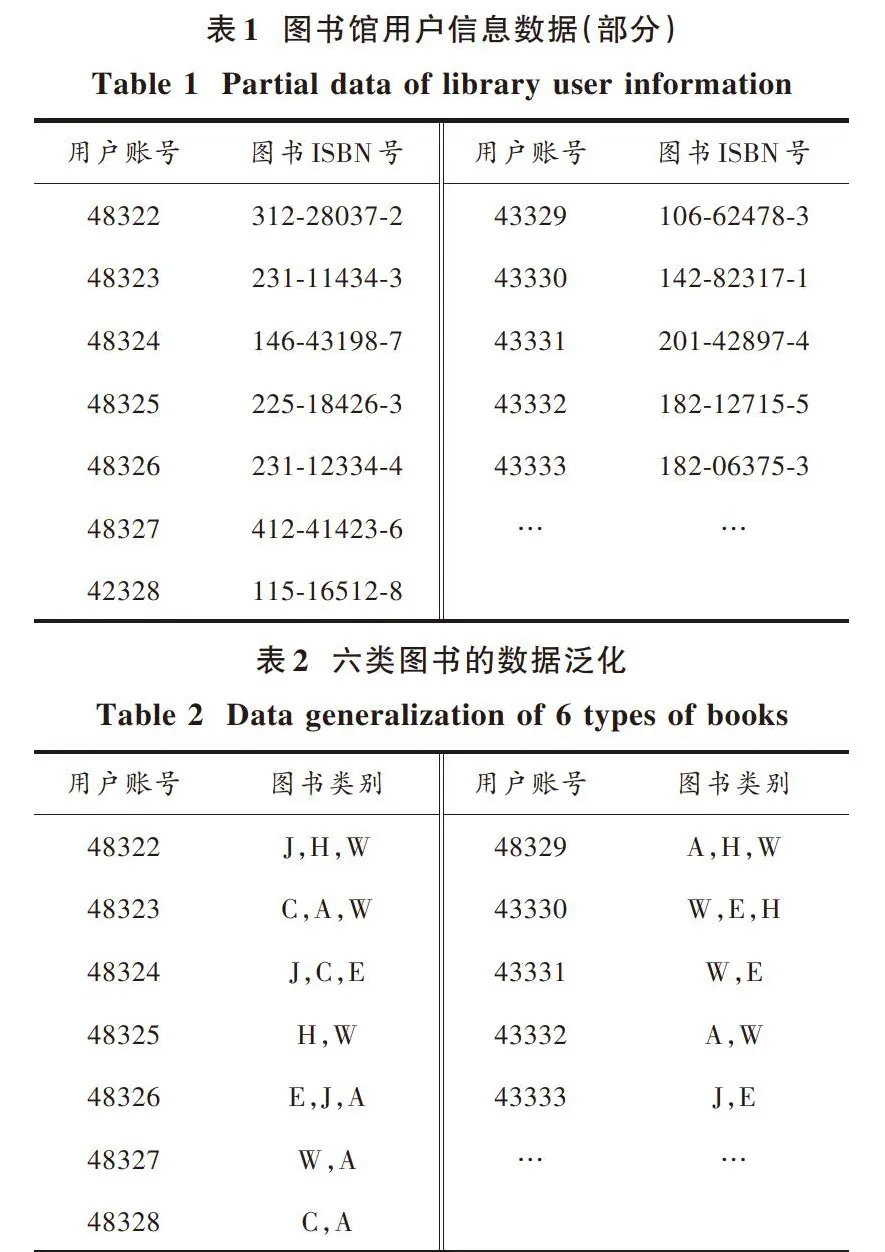
实验采用某高校中图书管理系统的数据库数据集。该数据集包含图书馆2018年的用户信息1 020 513条,如表1所示。
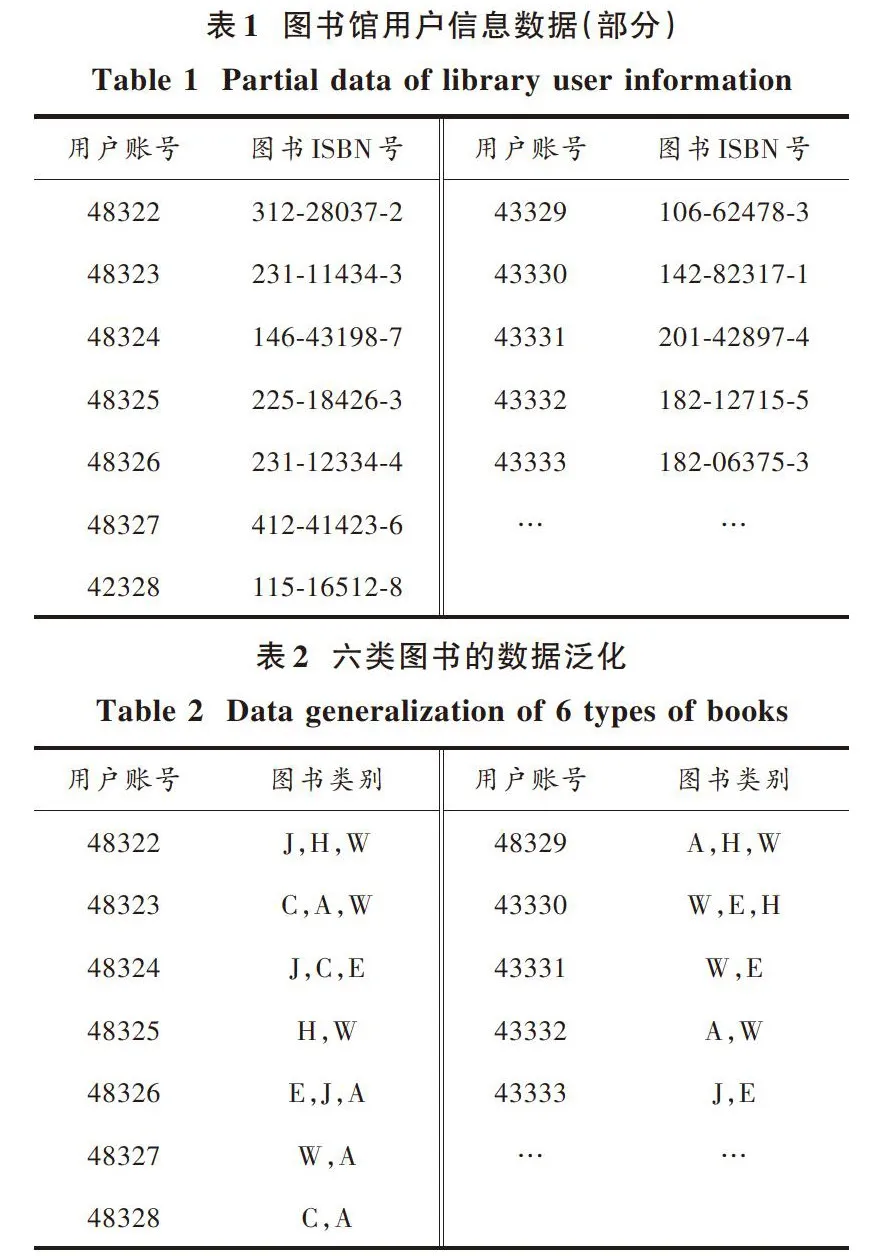
首先要将图书馆用户信息数据划分为训练集和测试集两个部分。训练集中的所有书籍通过人工标记分为E(计算机类)、H(英语类)、W(自动类)、A(艺术类)、C(社会类)、J(文学类)六大类,对这六类图书进行数据泛化得到表2。
4.3" 评估指标
为了对数据挖掘分类算法的性能进行有效量化评估,本文采用三个评估指标[12]:准确率(Accuracy)、召回率(Recall)、[F]值([F]⁃Measure)。准确率计算公式为:
4.4" 分类性能分析
在测试数据集上进行分类实验,基于朴素贝叶斯算法[5]、SPRINT算法[9]和本文混合决策树数据挖掘算法的分类器结果对比如图4~图6所示。
从图4~图6可以看出,朴素贝叶斯分类算法的性能最差,SPRINT算法有所提升,本文混合决策树数据挖掘算法的准确率最高,且综合评估指标[F]值也最高,有效提供了更加精准的用户服务。
5" 结" 语
本文提出一种适用于Hadoop云计算平台的混合决策树数据挖掘分类算法,这种算法结合了分布式改进的SPRINT算法和并行化的朴素贝叶斯算法,从而符合HDFS和MapReduce的工作模式。Hadoop集群环境的用户信息测试结果验证了该算法的可行性和准确性。但是在召回率指标上,相比单一分类算法,混合算法的优势不突出。此外,算法运行时间有所增加,后续将对如何在不降低精确度的条件下,提高运行效率开展进一步研究。
参考文献
[1] HASHEM I A T, YAQOOB I, ANUAR N B, et al. The rise of “big data” on cloud computing: review and open research issues [J]. Information systems, 2015, 47(C): 98⁃115.
[2] GANDOMI A, HAIDER M. Beyond the hype: big data concepts, methods, and analytics [J]. International journal of information management, 2015, 35(2): 137⁃144.
[3] LYU Yisheng, DUAN Yanjie, KANG Wenwen, et al. Traffic flow prediction with big data: a deep learning approach [J]. IEEE transactions on intelligent transportation systems, 2015, 16(2): 865⁃873.
[4] 李爽,陈瑞瑞,林楠.面向大数据挖掘的Hadoop框架K均值聚类算法[J].计算机工程与设计,2018, 39(12):142⁃146.
LI Shuang, CHEN Ruirui, LIN Nan. K⁃means clustering algorithm of Hadoop framework for large data mining [J]. Computer engineering and design, 2018, 39(12): 142⁃146.
[5] WU J, PAN S, ZHU X, et al. Self⁃adaptive attribute weighting for naive Bayes classification [J]. Expert systems with applications, 2015, 42(3): 1487⁃1502.
[6] 赵颖.基于改进SVM的文本混沌性分类优化技术实现[J].现代电子技术,2016,39(20):39⁃43.
ZHAO Ying. Realization of text chaotic classification optimization technology based on improved SVM [J]. Modern electronics technique, 2016, 39(20): 39⁃43.
[7] GUO Y, JIA R, JIANG C, et al. Moving Hadoop into the cloud with flexible slot management and speculative execution [J]. IEEE transactions on parallel amp; distributed systems, 2017, 28(3): 798⁃812.
[8] HUANG W, WANG H, ZHANG Y, et al. A novel cluster computing technique based on signal clustering and analytic hierarchy model using Hadoop [J]. Cluster computing, 2017(4): 1⁃8.
[9] 杨洁,黄刚.基于云计算的SPRINT算法研究[J].计算机技术与发展,2017,27(3):108⁃112.
YANG Jie, HUANG Gang. Research on SPRINT algorithm based on cloud computing [J]. Computer technology and deve⁃lopment, 2017, 27(3): 108⁃112.
[10] 张晨阳,马志强,刘利民,等.Hadoop下基于粗糙集与贝叶斯的气象数据挖掘研究[J].计算机应用与软件, 2015(4):72⁃76.
ZHANG Chenyang, MA Zhiqiang, LIU Limin, et al. Research on meteorological data mining based on rough set and Bayesian under Hadoop [J]. Computer application and software, 2015(4): 72⁃76.
[11] WOLFSON J, BANDYOPADHYAY S, ELIDRISI M, et al. A naive Bayes machine learning approach to risk prediction using censored, time⁃to⁃event data [J]. Statistics in medicine, 2015, 34(21): 2941⁃2957.
[12] BO Y, LEI Y, BEI Y. Distributed multi⁃human location algorithm using naive Bayes classifier for a binary pyroelectric infrared sensor tracking system [J]. IEEE sensors journal, 2015, 16(1): 216⁃223.
