
面向数据挖掘类课程的挑战性综合实验的设计与实践
2019-04-10 01:57:58刘梦娟曾贵川
实验科学与技术 2019年1期
刘梦娟,曾贵川,刘 瑶,陆 庆
(电子科技大学 信息与软件工程学院,四川 成都 610054)
随着互联网数据的爆炸式增长,数据分析与挖掘技术产生的学术和商业价值日益受到学术界和工业界的广泛关注。作为目前计算机领域最为热门的发展方向之一,已有许多学校开设了相关课程,如清华大学开设的“数据挖掘:理论与算法”,南京大学开设的“数据挖掘导论”,上海交通大学开设的“数据挖掘”和“机器学习”等。然而遗憾的是,目前针对数据挖掘类课程配套的实验多是针对每种数据挖掘算法(模型)单独设计的,缺少系统性的综合实验,特别是与解决工业界实际问题密切相关的实验,使得学生在面对实际问题时,很难综合利用所学的数据挖掘算法来解决问题。另一方面,挑战性学习(challenge based learning,CBL)[1]作为一种新的教育理念正在国内高校逐渐兴起。例如,清华大学在2012年提出将在全校开展20门校级挑战性学习课程[2];电子科技大学在2017年也提出了挑战性学习课程建设项目[3]。所谓挑战性学习是指通过增大课程挑战度,强调对学生实践动手能力的培养,从而达到激发学生的学术志趣,建立学术自信,培养创新意识和团队协作精神的目的。
根据数据挖掘类课程对综合实验的实际要求,以及将其定位为挑战性实验的考虑,课程组对综合实验的内容、教学方式和评价方式进行了全新的设计。首先,在应用场景上,将实验题目设计为学生在实际互联网中遇到的真实应用——从评论中抽取用户意见以及预测广告投放点击率;其次,在内容深度和挑战度上,将每个实验内容设计为由浅入深的完成性和挑战性两部分,在完成性部分学生可利用课堂中学到的基本模型来完成实验,在挑战性部分鼓励学生探索最新的研究成果和解决方案来提升实验的性能指标。在整个实验指导过程中,教师的作用从传统的灌输讲授型转变为启发引导型,同时由于是探索性实验,实验方案的评价是可以通过性能指标进行量化的,因此实验成绩的评判将由学生完成实验的性能指标以及实验报告质量来综合决定。学生在实验过程中,将不会再有完整的实验指导书,实验方案由学生自行设计完成,学生需要完成一个涵盖实验方案调研(文献查阅)、数据集分析、难点分析、实验方案介绍、实验结果分析等方面内容的挑战性实验报告。
1 挑战性课程的现状
文献[2]中指出,课程挑战度不足是我国世界一流本科教育事业发展中的瓶颈问题之一。究其原因是因为国内高校的第一课堂很大部分都采用单向的知识传授型授课模式,使得学生“学得容易,忘得也快”。为此2008年清华大学开始推动挑战性课程的建设,希望以此为引领,提高第一课堂的学业挑战度。这类课程期望通过有趣、有价值的挑战性问题吸引学生,激发学生的好奇心和想象力,通过高强度师生互动、生生互动,使学生快速获取新知识并综合运用相关知识,培养学生沟通、合作和创新能力,促进学生敢于善于挑战自我、主动学习,使学生在完成挑战性任务的过程中获得成就感。目前挑战性课程已经逐渐受到国内其他一流大学的认可和跟随。如电子科技大学在2017年已经启动了“物联网多元传感探测芯片技术”“数据科学中的数学方法”“电子信息科学与技术导论”等多门挑战性课程的建设[3]。
相对于国内高校以单向知识传授为主的授课模式,国外著名高校的授课则更强调内容的难度和广度,鼓励学生对工程知识和前沿知识的探索。如MIT开设的“Introduction to Computational Thinking and Data Science”课程[4],虽然是一门导论课,但是非常注重训练学生利用所学知识解决问题的能力,以及与教师(助教)的互动,为此课程设计了5个由浅入深的题目,要求学生自主完成,并且每个题目都严格限制了完成时间,课程为每个小组(1~2人)分配1位助教,展开1对1的研讨。如其中一个题目是要求学生完成美国各地温度变化的分析和可视化模型,同时要求学生利用回归模型对各地未来的温度进行预测,以及分析各地的极限温度。CMU开设的“Machine Learning”课程[5],是由大师Tom Mitchell开设的,其课程的覆盖内容非常广泛且具有一定难度,包括代数和概率论、机器学习的基础工具、概率图模型、AI、神经网络、主动学习、增强学习等。这门课程也包含一个课程设计,Mitchell没有固定题目,但是给出了若干题目建议,这些题目的难度也是相当具有挑战性的,包括KDD 2010年挑战赛的题目[6]、Netflix竞赛的题目[7]等,这些课题的完成帮助学生在实践过程中,强化对所学知识的理解和运用。本综合实验的题目正是借鉴了上述两门课程的题目设计思路。
数据挖掘作为一门前沿性理论课程,由于其与现实互联网应用的密切关联以及实证性研究的特点,具有较好的建设挑战性课程的基础,同时考虑到学生对课程的接受度问题,课程组尝试从综合实验开始改革,首先从实际应用及学生兴趣角度出发确定实验题目,其次按照由浅入深、循序渐进的方式加大实验内容和考核指标的挑战度,然后将教学方式从讲授型改变为以讨论建议为主,由学生自行查阅文献完成实验的方式,最后将考核方式改变为以性能指标为主,辅以实验报告的评价方式。
2 实验内容及教学手段设计
首先从互联网实际应用以及学生兴趣出发设计综合实验题目,考虑到每个题目都需要对应完成性和挑战性两个部分,因此题目对应的实验方案应该具有可扩展性,即题目可以基于由易到难的多种方案来解决,而不是基于一种确定性方案。为此,课程组设计的两个实验题目分别如下:评论意见抽取[8]和广告投放点击率预测[9]。这两个综合实验题目的要求如表1所示。

表1 综合实验的题目要求阐述
题目1的应用场景是电子商城中面对商品的海量评论,如何自动从评论中快速抽取出评论者对这个商品的意见,以提供给潜在用户作为参考。这里意见的形式以<特征词,情感词>词对的形式体现,同时要求判断评论者对这个特征词表达的意见是褒义还是贬义。如一条关于手机的评论如下:“外观漂亮,信号不错,性价比高”。要求提取的词对为“外观,漂亮”“信号,不错”“性价比,高”,判断评论者对这三个特征的感情色彩都是褒义的。题目1的难点在于准确提取词对,以及准确判断词对的情感色彩,这需要学生在设计实验方案时能够掌握中文分词、词性标注的自然语言处理工具,以及设计良好的词对提取规则;对于情感分析需要学生掌握情感词典的构建和使用。题目1的内容简要总结如图1所示。

图1 题目1的实验内容总结
题目2的应用场景是网站上广告的定向投放,当一个用户浏览网页时,网站会根据网页信息、用户信息以及与广告的匹配程度,将广告定向投放到那些更有可能感兴趣的用户浏览的网页嵌入的广告位上,为了准确评估用户的感兴趣程度,要求学生对将广告投放到一个特定用户浏览的网页的广告位后,用户的点击概率进行预测。例如,一个运动服广告投放到一个正在浏览体育赛事网页的男性用户的预测点击率应该高于投放到一个正在浏览母婴网页的女性用户的预测点击率。题目2的难点在于建立准确的点击率预测模型,这需要学生灵活掌握各种预测模型(如逻辑回归模型[10-11]、支持向量机模型[12]等)的学习算法,以及训练这些模型的工具。题目2的内容简要总结如图2所示。
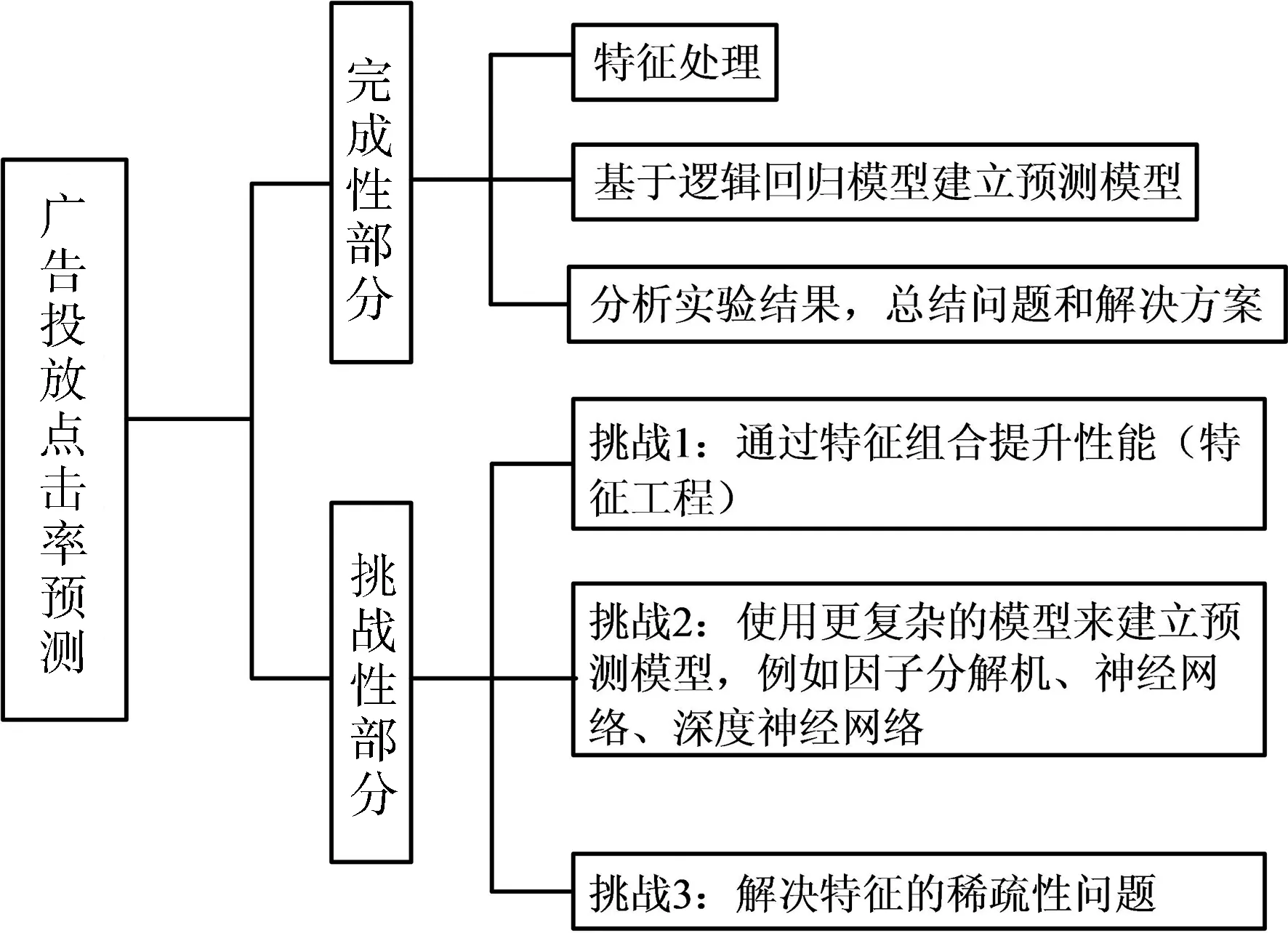
图2 题目2的实验内容总结
对于挑战性综合实验最重要的改革是教学方式的变化,将“听中学”的模式改变为“做中学”,即促使学生能够通过查阅文献、做实验、与同学讨论等多种方式自主探索解决问题的方案,而不是依赖教师给出实验具体步骤。实验过程中采用的教学模式如图3所示,首先抛出实验需要解决的问题,由教师对题目进行阐述,使学生充分理解实验目标;然后教师讲授两个题目的完成性部分涉及的基本模型和算法,包括基于词性搭配的词对提取算法,逻辑回归模型等,以及一些常用工具,如哈工大的自然语言处理平台[13],python的数据分析工具包numpy、scipy、pandas、sklearn等;在此基础上,由学生给出完成性实验的初步方案,通过讨论确定方案的可行性,最后完成实验并对实验结果进行分析。与传统教学模式不同的是,挑战性综合实验会要求学生进一步分析实验结果,探讨现有方案的不足和改进措施,并通过查阅文献,迭代形成新的实验方案,继续挑战性实验。特别说明的是,教师在指导过程中仅参与方案可行性讨论和给出建议,不需要告诉学生正确的实验方案;此外,在挑战性实验中会对实验的性能指标给出最低要求,只有达到性能指标的实验方案才能通过,否则会要求学生继续迭代完善实验方案。对于已达到性能指标最低要求的学生,通常会自愿进一步完善实验,从而提升实验方案的性能。

图3 启发式教学模式示意图
在挑战性综合实验中采用了一种全新的考核方式,由于实验的性能指标均是可量化的,因此每组实验中,学生只需要将测试数据集的实验结果提交到考评系统,考评系统根据测试数据集中的真实标记,计算实验方案的性能指标,反馈给学生,同时可以反馈给学生其实验方案的性能在班级所有提交方案中的排名情况,从而激励学生进一步探索更为完善的方案。在实验的性能指标达到要求后,学生需要完成挑战性实验报告,内容包括对题目的理解、转化为数学问题的描述,对解决该问题的现有方案的综述,数据集分析,难点分析,本实验采用的方案和改进方案,以及最终的性能指标对比和分析。最终的实验成绩将以达到的性能指标作为主要参考,实验报告的质量作为成绩的补充参考。更多的介绍可参考课程设计在GitHub上的课程主页[14]。
3 实践中出现的问题总结
目前挑战性综合实验已经在部分高年级本科生中开展,实践结果显示,通过挑战性综合实验,学生确实在理论学习深度、实践动手能力、学术研究兴趣以及团队协作方面有较大程度的提升。例如有学生在完成了题目1以后对自然语言处理中的情感分析特别感兴趣,自主学习了斯坦福大学的自然语言处理公开课,并参与到相关课题的研究中[15];例如有的学生在完成点击率预测时接触到深度学习模型,尝试利用目前最为前沿的深度学习算法来处理点击率预测建模中的特征筛选问题。但是在实践过程中仍然发现存在以下问题:
1)选题问题。由于挑战性实验要求实验内容具有一定的难度和发散性,因此对指导教师的知识水平要求较高,目前课程组设计的实验题目只有两个,也就是所有学生都必须完成这两个实验,然而并不是所有学生都对这两个题目感兴趣,在实践中不少学生也提出了一些有创意的题目,因此课程组考虑在后续增加更多的综合性题目提供给学生选择;
2)自由组队问题。由于实验内容和难度都比较大,因此实践中是由学生每三人自由组队进行分组实验,这种方法的好处是可以促进学生的团队协作能力,但是也可能导致“强-强联合”的情况,即有的小组学生能力特别突出,完成的性能指标非常好,而有的小组只以达到最低要求为目标,从而造成实验成绩的两极分化;
3)实验评价问题。目前实验成绩的构成主要是70%的性能指标成绩+30%的实验报告成绩,通常将性能指标优异的小组认为采用的实验方案也更为优异,但是在实践中出现了这样的例外情况,即尽管学生最终的实验性能指标不是最优的,但是在实验方案中提出了一些特别巧妙地解决思路和方法,这些方法不是借鉴其他文献中已有的方法,而是学生自己思考提出的,非常具有创新性,但是目前的考评方法没有考虑到这部分的贡献,在后续的开展中将对于这类实验方案给出特别贡献分。
4 结束语
综上所述,通过挑战性综合实验能够培养学生的以下4个方面的能力。1)对数据挖掘类课程中学到的各种算法和模型的灵活运用能力,要求学生在遇到实际问题时,能够将问题转化为需要求解的数学问题,例如在构建词对的情感词典时,明确这是一个二分类问题,将词对划分为褒义和贬义两个类别,可以采用分类算法来完成实验,而在预测用户对广告的点击率时,明确这是一个回归(或分类)问题,可以采用回归(或分类)算法来完成实验;2)能够基于实验方案正确编写实验代码完成实验,这不仅要求学生具有较好的编程能力,而且要求学生对数据挖掘的相关工具包有一定程度的掌握,如numpy、scipy、pandas、sklearn等,此外有的能力突出的学生还尝试对大数据实时处理方面进行改进,例如提高运行速度,减少内存占用等;3)能够查阅科学文献,完成解决同类问题的方案调研和综述,通过学习其他文献的实验分析方法,学会分析自己的实验结果,从而提出针对自己实验方案缺陷的改进措施;4)在实验过程中学生需要通过与其他学生进行分工合作,方案探讨来完成实验,从而提升学生的团队协作能力以及与人交流的能力。
猜你喜欢
石油沥青(2021年1期)2021-04-13 01:31:08
大众投资指南(2021年35期)2021-02-16 01:06:26
文苑(2020年7期)2020-08-12 09:36:22
宁夏医学杂志(2020年3期)2020-02-27 14:17:11
中学生数理化·八年级数学人教版(2019年11期)2019-09-10 09:43:04
电力与能源(2017年6期)2017-05-14 06:19:37
制冷技术(2016年4期)2016-08-21 12:40:30
测绘科学与工程(2016年4期)2016-04-17 06:51:14
信息通信技术(2015年6期)2015-12-26 01:16:46
求知导刊(2015年15期)2015-05-30 00:51:54
