
移动边缘计算规模部署的技术制约因素和对策
2019-04-09 05:53:38
中兴通讯技术 2019年6期
段向阳/DUAN Xiangyang
王卫斌/WANG Weibin
(中兴通讯股份有限公司,广东 深圳 518057)
从2016年欧洲电信标准化协会移动边缘计算行业规范小组(ETSI MEC ISG)发布边缘计算7大业务场景定义开始,移动边缘计算(MEC)概念逐渐受到通信运营商、互联网业务提供商和行业用户的高度关注[1-3]。
MEC的成功需要5G切片网络大带宽、广连接、高可靠低延迟等新型管道能力提供增值价值,也需要5G网元接口的开放性、基于服务架构(SBA)导向的5G核心网(5GC)落地实现平台贯通,更需要发挥边缘计算商用价值的生态系统的建立;然而,各种技术因素和商业因素交织在一起,将给边缘计算带来较大的落地风险。
本文中,我们对边缘计算的现状和规模落地的相关制约因素进行分析,以尝试建立一些技术共识,为5G批量部署后的边缘计算业务场景集中部署做好技术储备。
1 MEC需要平衡“计算”和“连接”
MEC最早定义是移动边缘计算;后来被修改为多址边缘计算[4],这体现了固移融合和多接入的趋势。由此可见,MEC从一开始不仅关注在合适的物理位置提供算力,还注重在合适的物理位置为不同类型的设备提供对应的连接方式。
传统通信运营商和设备商更关注和擅长提供“连接”,而互联网服务提供商(ISP)和信息技术(IT)制造商则更关注和擅长提供“计算”。双方在业务认知和价值定位上有一定分歧。比如部分ISP仍然视5G网络为透明管道,更认同扁平化的MEC网络,即Far-Edge边缘盒子自备计算和存储能力,通过通信网络直达ISP分布式云化数据中心,开启“云+端”一体化模式。而一些运营商对OTT业务(OTT业务是指互联网公司越过运营商发展基于开放互联网的各种视频及数据服务业务)心存顾虑,在构建MEC网络时,过于强调自建平台即服务(PaaS)基础设施和移动边缘平台(MEP)能力平台,希望OTT业务能直接运行在电信运营商提供的MEC平台上。
客观上看,5G网络和4G网络有了很大不同。5G的控制面和用户面分离(CUPS)是在边缘部署用户面功能(UPF)的保证。而UPF的下沉使5G网络可依据签约信息和鉴权接入,基于移动性管理,在保证会话连续性和业务连续性前提下,根据服务质量(QoS)为用户选择最优的用户面功能并记录计费和账单。在可管、可控的前提下,提升体验质量(QoE)和支持高可靠低时延通信(uRLLC)等关键业务。
对于内容分发网络(CDN)时延敏感的直播类业务、云游戏,特别是随着增强现实(AR)/虚拟现实(VR)显示材料技术发展将要产生的一些交互式视频业务,如果仍然将通信网络视为透明管道,将不能通过应用程序接口(API)管理UPF的分流规则把此类业务路由到最优边缘数据中心处理,这会导致很多业务机会的损失。
如图1所示,UPF锚点与MEC结合,实现“计算”和“连接”平衡,具有如下优势:充分发挥运营商对网络连接的感知优势;可对网络连接实现精细化管理如端到端QoS;有利于快速引入ISP应用程序(APP);通过对UPF分流后业务第一跳入口处的联动和闭环处理,更快、更好地上线新业务;真正构建“云-边-端”协同业务模式,而不是简单的“云+端”模式。
2 MEC连接能力需求分析
通过标准的管理接口在网络业务呈现功能(NEF)接口实现UPF路由规则的可配置性后,用户面数据流到达边缘计算网关设备。该网关就将成为一个转发集中点,特别是当承载高清视频等业务时,该网关的转发面性能就成为关键点。即使某些流量不是特别巨大的应用,如车联网(V2X)网络的控制信息,由于交互报文小而频繁密集,对转发面的包转发率(PPS)要求也很高。
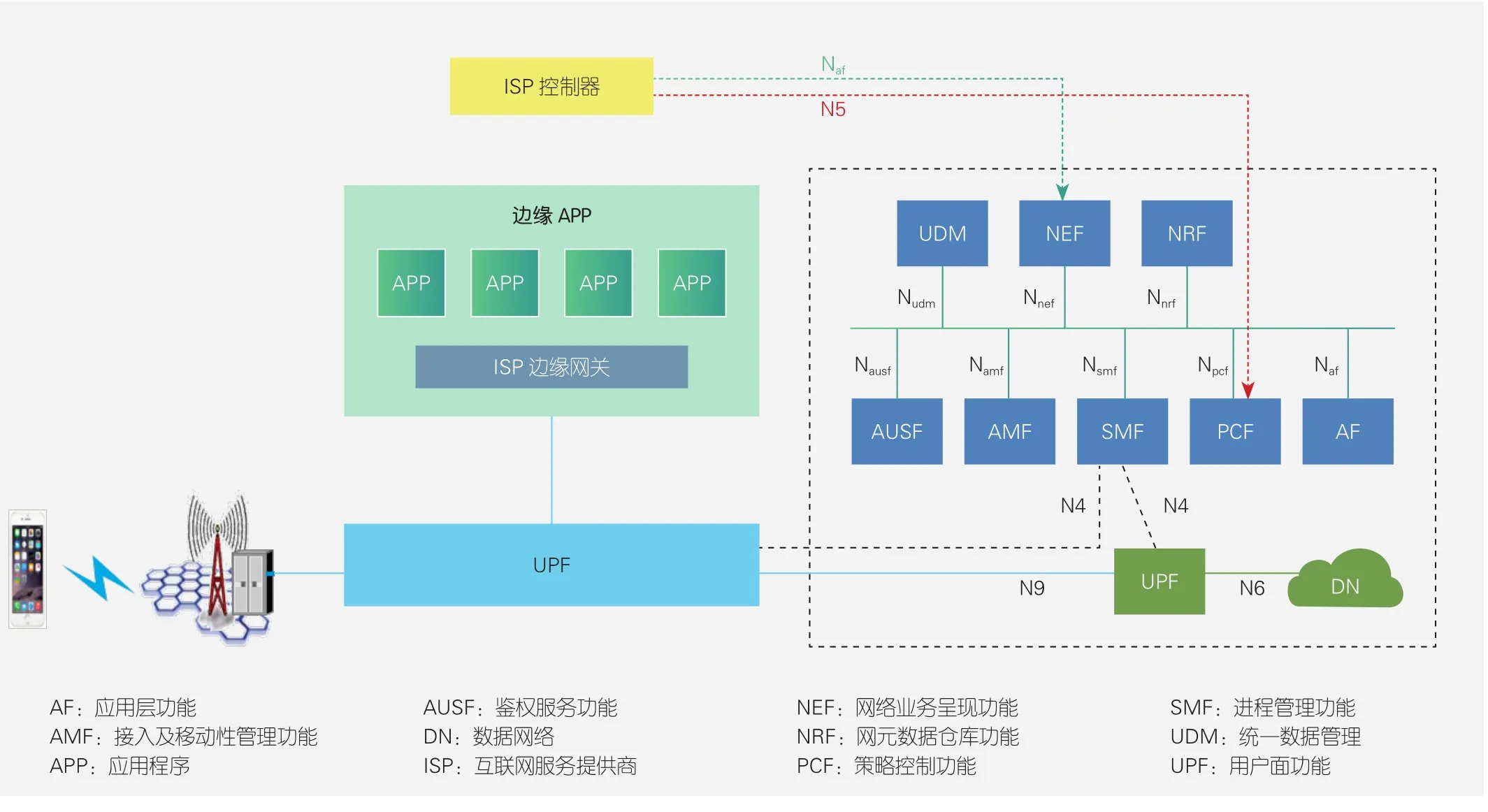
图1 5G典型场景下移动边缘计算部署组网
在云数据中心里面,网络集中点的软件转发技术多采用基于用户态的轮询机制的驱动(PMD)和数据平面开发套件(DPDK)环形队列支撑底层高效收发,配合vSwitch技术实现虚拟机之间的L2交换。当需要使用网络报文的高层次解析时,一般会采用快速数据项目(FD.io)矢量包处理器(VPP)快路径开源软件通过对报文向量化和充分利用处理器最后一级缓存(CPU LLC)缓存命中之类相关技术,将报文分发到开源用户态协议栈处理。进一步地,当需要配合业务规则如URL解析、DNS解析实现业务负载均衡时,需要通过用户态Linux 虚拟服务器(LVS)、Nginx反向代理等开源软件技术支持高性能L4-L7转发。
软件转发面加速技术基于X86平台,充分利用单指令多数据流(SIMD)操作如高级向量扩展(AVX)指令集和CPU提供的旋锁等硬件原子操作指令,也可以达到较高的性能。当前,一般在支持较为简单的L7解析规则时,单台2路Intel高配置SKU XEON可达到10 Gbit/s+ throughputs、5 M+PPS的包转发率。
5G MEC面对的转发场景能力很有可能是100 Gbit/s+、50 M+PPS入口L4 负载均衡(LB)的需求。仅仅为解决入口网关的分发而在边缘机房中放置5~10台服务器显然是比较浪费的,为此,需要更高性耗比和性价比的MEC高性能转发面解决方案来解决这一问题。
此外,针对特殊的数据流如视频流传输,也需要对传统传输控制协议(TCP)滑窗机制进行连接优化,以降低延迟、减少重传流量开销,如Google提出的新型拥塞控制算法(Google BBR)等。可见,这部分技术因素也需要一并予以考虑。
3 MEC计算力需求分析
经过L4-L7 LB后的报文到达APP Server资源池后进行业务场景的处理,而MEC计算力需求与业务场景紧密相关。业务场景决定了该APP是应该放在云中心抑或是放在边缘中心处理。传统上认为,以下几种业务场景是比较适合放在MEC的。
(1)流量大且需要就近分发以减少流量迂回的应用场景,如CDN网络。
(2)终端处理功耗高影响续航能力的场景,如需要图形处理器(GPU)渲染的云游戏或者直播类业务。
(3)需要人工智能(AI)感知类的场景,如非结构化视频数据的信息本地提取结构化处理过程。
(4)视频、雷达点云等流式数据压缩/解压缩进一步本地处理的场景。
(5)安全相关的场景,如出入口数据流的加解密/防火墙处理过程。
(6)有关通用计算存储能力的场景,如高性能非易失材料存储介质的本地数据存取、预处理、清洗过程。
除了这些计算需求外,还有一部分新技术需求。如在物联网(IoT)系统中引入区块链和分布式记账(DLT)等技术解决用户接入认证、设备资产管理、隐私数据保护等授信问题。还有针对用户数据孤岛,采用联邦学习等分布式机制支持AI模型在线增量训练、迁移学习过程等。这些都是通过计算代价换取可信性的业务场景。
总的来说,当前主要存在如下相关算力要求:
(1)AI深度学习计算。目前深度学习以卷积计算为核心,辅助以非线性变换(如Relu、Sigmoid函数)、池化、归一化等计算操作(部分可以转化为卷积操作与累加和操作)。此外,还包括在输出层通常需要做对数据带宽要求很高的全连接操作。其中,卷积操作计算量非常大,这是由于:目前深度学习层数普遍较深,多达百层以上的神经网络屡见不鲜;虽然卷积核普遍在缩小,但是按照Strip=1或者2的步长从左至右、从上至下迭代点乘累加下来的计算量却非常巨大。以目前作为Benchmark比较简单的AlexNet 8层卷积神经网络(CNN)为例,单张图片计算力就达到了1.5 GFlops,而当前主流的CNN普遍在5~10 GFlops之间。主流的神经网络模型尺寸普遍较大,几百兆尺寸的模型也不在少数,依靠片内静态随机存取控制器(SRAM)一次性载入显然不现实,而使用动态随机存取存储器(DRAM)存放又不满足数据带宽需求。
(2)GPU渲染。GPU渲染包括边缘计算云游戏、交互式视频、虚拟/增强/混合现实业务等基本计算力需求。其本质是对渲染方程求近似解的过程。计算架构从最早的固定Pipeline发展到目前可编程的Pipeline,并通过多数据(矢量化并发)、多指令(空间分区)、高主频超标量体系(时分和硬件调度)+Wrap多线程(数据流并发优化)实现了具有高性能、灵活性和通用性的主流通用图形处理器(GPGPU)。
(3)视频编解码。通过实时编解码技术可以对音视频内容进行有效的信息有损压缩。数据容量压缩比可达到数百比一,这在节省传输带宽实现高效率传输方面有重要意义。视频编解码计算力要求要比AI深度学习计算更为复杂:一方面,对视频帧数据宏块/子块划分和I/B/P帧间预测编码都需要高效的数据流调度机制以节省数据带宽;另一方面,涉及到空间数据冗余消除(帧内预测)、时间数据冗余消除(帧间预测)时,需要进行移位、累加等操作,这对残差数据还有离散余弦变换(DCT)相关性消除、游程/字码类编码无损压缩等都有较高的算力要求。由于存在通用格式标准可遵循,以及编解码算法便于专用集成电路(ASIC)化,目前高性能高密度视频编解码大部分以固化形态存在。当然也可以通过CPU/GPU/数字信号处理(DSP)进行软处理,只是效率相对较低。
(4)其他相关算力要求。比如,在V2X应用中,还存在LiDAR激光雷达的点云数据压缩和信息结构化处理的需求。随着显示材料技术的发展,AR/VR/混合现实(MR)等前瞻性业务有可能会被作为杀手级应用进行开展,这将产生新的计算力需求。对于混合现实业务,相关算力要求主要是解法拉第光场方程实现光场技术和卡尔曼滤波(KF)获取深度信息。虽然目前可以使用GPGPU完成相关计算过程,但这并不是性耗比和性价比最优的解决方案。
这些计算力都是不以分支跳转判断为主处理路径,而是基于数据流驱动的迭代型计算。在进行超标量体系处理时,会存在分支预测失败率高、Cache命中率低、Von-Neumann架构取指令、译码执行代价大等问题,需要通过SIMD矢量指令来支持软加速。
这里以Intel Skylake微架构(2.3 GHz主频/12核心/105 W 散热设计功耗(TDP))支持AVX-512,单核、单时钟周期64 浮点(FP)32/85整数(INT)8每秒操作数(OPS)为例,总算力为2.3 TOPS,性能功耗比仅仅为0.023 T/W(假设OpenVino调度和数学函数库-深度神经网络(MKL-DNN)计算库最优化状况)。以目前常见神经网络模型如Inception/暂态混沌神经网络(MTCNN)/Yolo/ResNet50等做图片推理(检测或分类),按照平均5 GFlops的计算量计算,一颗XEON大约能处理460 帧/秒的图像深度学习,参照H.264 Main Profile 24 帧/秒,处理能力不到20路视频。即5台服务器处理不了200路视频深度学习(不包含视频编解码)。
因此,目前主流做法普遍是采用优化脉动阵列,使用基于数据流驱动的新型计算架构,并通过超标量主处理器实现异构计算来支持相关算力需求。针对AI深度学习的深度学习加速器(DLA),在采用16 nm以下的工艺时,可以达到1~2 T Flops/W(FP16)以上的计算效率。
数据流驱动的计算方式需要对算力抽象并进行调度,以支持新出现的算法、算子和多实例运行。因此,在神经网络模型和实际物理算力之间需要采用软件开发工具包(SDK)软件进行封装,将模型转译成中间表达式,并通过量化压缩、稀疏化等处理手段来降低模型尺寸和算力要求。由此可见,通过调度算子、算力来完成层内计算优化和层间计算融合可以实现算法建模与真实硬件的适配。
视频编解码在边缘计算应用中还存在一个较大的问题,即引入了较大的群延迟。在5G的诸多应用中,比如V2X的摄像头视频数据结构化感知公共环境信息、基于5G uRLLC的远程操作都依赖低延迟和确定性的端到端传输。即使5G空口+MEC实现了端到端10 ms的延迟,经典视频编解码算法引入的延迟却是数量级的:如果不做任何优化,H.264典型延迟将达到400~500 ms。通过对传输协议和帧缓冲的优化,一般可以将延迟降低到200 ms内。但如果要实现50 ms内的延迟,从摄像头快门定制到ISP处理器端到端都需要进行优化。
4 MEC异构计算和虚拟化、资源池的矛盾分析
从MEC计算力需求分析可以看出,异构计算加速是边缘机房无法回避的选择。而构建“云-边-端”一体的协同业务模式,需要考虑开发运营(DevOps)快速部署、软件组件的平滑移植和第3方应用的开发成本;因此,这将会不可避免地对异构计算资源产生虚拟化和资源池化的需求。
从技术上看,异构计算属于一种领域定制架构。在硬件虚拟化层面仍存在着较大的技术问题。
目前异构计算主要以GPU、现场可编程门阵列(FPGA)和网络处理器(NP)以及部分内置DSP的ASIC为主。考虑到虚拟化基础设施的优势,主流方案采用:主处理以通用X86作为主平台,通过串行总线(PCI)Express总线外挂异构计算协处理器,对迭代类型、数据流驱动类型等强计算工作负载进行Look-Aside方式的卸载。该方案的主处理器是X86平台,保证了第三方应用在云和边的平滑移植,有利于实现APP与基础设施的三层解耦。此外,也可以通过异构计算实现性价比和性耗比的兼顾。
但是,针对外设部件互连标准(PCIe)输入输出(IO)的虚拟化方案仍然存在一些问题。目前主要采用单根IO虚拟化(SR-IOV)虚拟化方案,通过PCIe总线枚举过程中对虚拟功能(VF)的功能发现并分配IO、Memory空间和中断路由资源,将其视为虚拟设备的同时Bypass掉主机操作系统内核,通过客户操作系统来直接控制设备。这就带来了虚机热迁移和安全机制的一些问题。针对GPU设备,由于其具有多指令多数据(MIMD)特性,当实现VF功能时,还会存在任务调度核心互联网协议地址(IP)暴露等问题;因此,目前2家主流GPU厂商都只针对基于Windows DirectX的系统提供闭源或部分开源的收费软件。由此可见,当边缘需要实现视频渲染类业务时,这样的虚拟化方案是存在问题的。因此,一些方案采用基于物理GPU功能,通过远程直接内存访问(RDMA)这类低延迟网络来实现客户-服务器资源池拉远,加载基于开源的任务调度软件以替代GPU虚拟化。
针对异构协同的Look-Aside架构,也有一些基于半虚拟化IO(VirtIO)的虚拟IO技术。VirtIO本质是一种Share Memory通信技术,通过“连接”在Backend上的前、后端驱动实现硬件设备的抽象和隔离,解决了单根IO虚拟化(SRIOV)的安全性和“热插拔”缺陷。但是VirtIO机制本身是一种软件处理方式,在没有硬件加速辅助的条件下,其性能与SRIOV存在明显差距。此外,VirtIO支持的驱动类型也需要生态链的广泛支撑。也有一些厂家将虚拟操作系统模拟器(QEMU)和VirtIO的大部分功能下沉进入FPGA等加速硬件中,通过将Hypervisor定制化做薄,实现无宿主机的裸金属虚拟化硬件方案(注意与寄居型虚拟化方案中的裸金属资源调度区分),在安全性和性能上都能取得良好效果。值得一提的是,VirtIO当前主线版本由于对硬件加速考虑不足,数据结构存在3套队列,并不利于硬件的实现;因此,后续版本仍需要再继续优化。
FPGA是一种细粒度可编程异构计算芯片。完成编程固化的FPGA可以等效ASIC性能。针对虚拟化管理要求,2大厂家都提供了静态分区和可编程分区的动态重构技术路线。通过将异构接口、双倍速率数据传输存储器(DDR)、直接存储器存取引擎(DMA Engine)等必需的数据通道固化到静态分区,同时动态分区On-Fly在线重构,可以加载加速应用。针对资源发现和管理,2家都提供了OpenStack下Cyborg异构管理组件的相关插件对FPGA裸设备发现、枚举支撑Nova资源分配;然而,FPGA存在加速架构对外部Memory带宽和内部数据流的要求存在太多定制化设计的问题。比如,AI DLA往往需要2组72 bit(8 bit 纠错码(ECC))DDR4支持64 Gbit/s+的预取带宽,更有一些大吞吐设计需外部支持多组第六版图形用双倍数据传输率存储器(GDDR6)颗粒提供大带宽。而在网络加速如智能网卡应用时,又往往需要支持精确匹配表(如基于三态内容寻址存储器(TCAM)的访问控制列表(ACL)查找算法)和支持多级Hash模糊匹配表相结合。这需要大位宽外存总线的同时,也需要多组小位宽总线甚至外置4倍数据倍率(QDR)SRAM配合片内算法来实现。从这个角度来讲,能够满足特定应用的加速卡都是定制化的。另外,FPGA的综合、布线资源对内部逻辑单元和外部IO引脚都有苛刻的时序级配合需求;因此,很难在A厂家的FPGA卡上,静态把B厂家的固件综合进去,也很难把A厂家自己的固件使用动态分区与其他固件动态重构。
针对上述难题,业内提出了资源池的解决方案。针对FPGA异构资源池,微软有过并不成功的实践,最终还是选择分布式同构服务器形态[5]。从技术上看,在边缘将FPGA异构服务器单独做成资源池,会存在网络流量迂回、单点故障和维护困难等工程问题。
5 MEC设备部署位置和硬件形态
MEC部署位置区包括“边缘”“超边缘”和“现场级边缘”,并与“边缘云”“边缘网关”和“边缘设备”相对应。边缘硬件的形态千差万别:从通用架式服务器、定制化服务器等上架设备形态,到挂墙机箱、“盒子”,再到手持式现场终端。在软件部署上形态也很多样:从虚机/容器“双核”虚拟化云计算架构+微服务,到嵌入式OS和极简化协议栈。
众所周知,边缘计算得益于QoE提升与高效率网络传输相结合的理念。通过提供用户低延迟的业务感受和可控的网络传输成本,来支撑以人为中心的如沉浸式/交互式视频类新型业务,以及以物为中心的如车联网等万物互联应用。这充分发挥了5G网络大带宽、低延迟、广连接的优势;因此,边缘计算不仅要距离户足够近,使之处在网络较低位置,还要实现一定的收敛汇聚,具备较强的本地处理能力。从这个方面来说,边缘计算最理想的位置是大量无线和有线接入之后的位置,如中心单元(CU)/分布单元(DU)分离后的CU,甚至是DU,或者有线传输中的光线路终端(OLT)等接入点。位置既不适宜太高,也不适宜太低。太高或太低都将会使MEC失去价值。
位于县区、接入/站点级的众多边缘接入机房是运营商的宝贵财富,但边缘接入机房不同于云数据中心,存在如下限制条件:
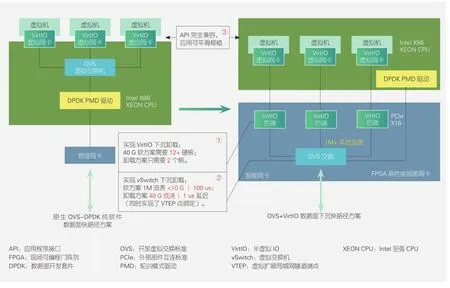
图2 中兴通讯OVS+VirtIO加速方案
(1)面积受限,通常可用剩余面积小于100 m2,缺乏腾挪空间。
(2)机房承重普遍偏低,多为4~6 kN/m2标准,达不到数据中心8 kN/m2的要求。
(3)机柜深度多是600 mm或者300 mm并柜,不支持700 mm以上深度的通用服务器。
(4)机柜功率预算受限(散热限制),单机柜为1~3 kW,平均2 kW。
(5)机房空调和制冷受限,需要满足电信级环境温度要求(网络设备构建系统标准3(NEBS L3))。
经过充分调研,目前大家都意识到:对存量接入机房的改造耗费巨大,而且缺乏可实施的工程方案;同时,边缘机房需要定制化硬件形态予以支撑。为此,开放数据中心委员会(ODCC)组织制订开放电信IT基础设施(OTII)电信服务器白皮书以促进边缘定制化服务器硬件形态的建设。
6 中兴通讯对MEC开展的针对性研究工作
中兴通讯充分认识到边缘规模部署的相关制约因素,已经开展了针对性的研究工作,并建立了开放边缘平台(OEP)。OEP是一个开放的软硬件平台,专为异构计算加速定义,支持多种定制化硬件形态。该平台不仅很好地解决了UPF用户面下沉和MEC共同部署的问题,还支持多种计算加速方案,同时还可以结合ZTE基础设施即服务(IaaS)/PaaS基础设施平台,提供MEP能力封装,为第三方应用平滑移植和业务创新提供高性价比、高性耗比、易于集成和部署的基础平台服务。
智能网卡提供的VirtIO网络隔离方案(参见图2),可达到与SRIOV同样性能,不仅同时支持虚机热迁移,还同时支持开放虚拟交换标准(OVS)加速和软件定义网络叠加(SDN overlay)组网虚拟扩展局域网(Vxlan)加速。
如图3所示,智能网卡通过In-Line加速对UPF下沉提供加速能力。2路XEON 与2块智能网卡可实现近200 Gbit/s的报文转发处理能力。单块加速卡功耗仅60 W,并且延迟低于10 um。这对uRLLC业务价值尤高。
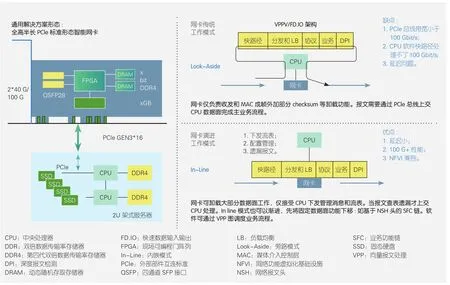
图3 网络加速模式
中兴通讯视频结构化方案(参见图4)通过视频编解码加速卡、AI加速卡支持2路XEON服务器系统对200路H.264 1 080P 24帧/秒的视频进行实时结构化。同时还支持人脸识别、人形识别、车型识别、车辆监测等AI业务。
中兴通讯OEP系列边缘定制化服务器(参见图5)功能丰富、风格统一:3U高度,450 mm深度;支持宽温工作(0~45 ℃);支持前走线维护(含前置多模电源);散热风扇三冗余设置,支持不开箱热插拔维护。
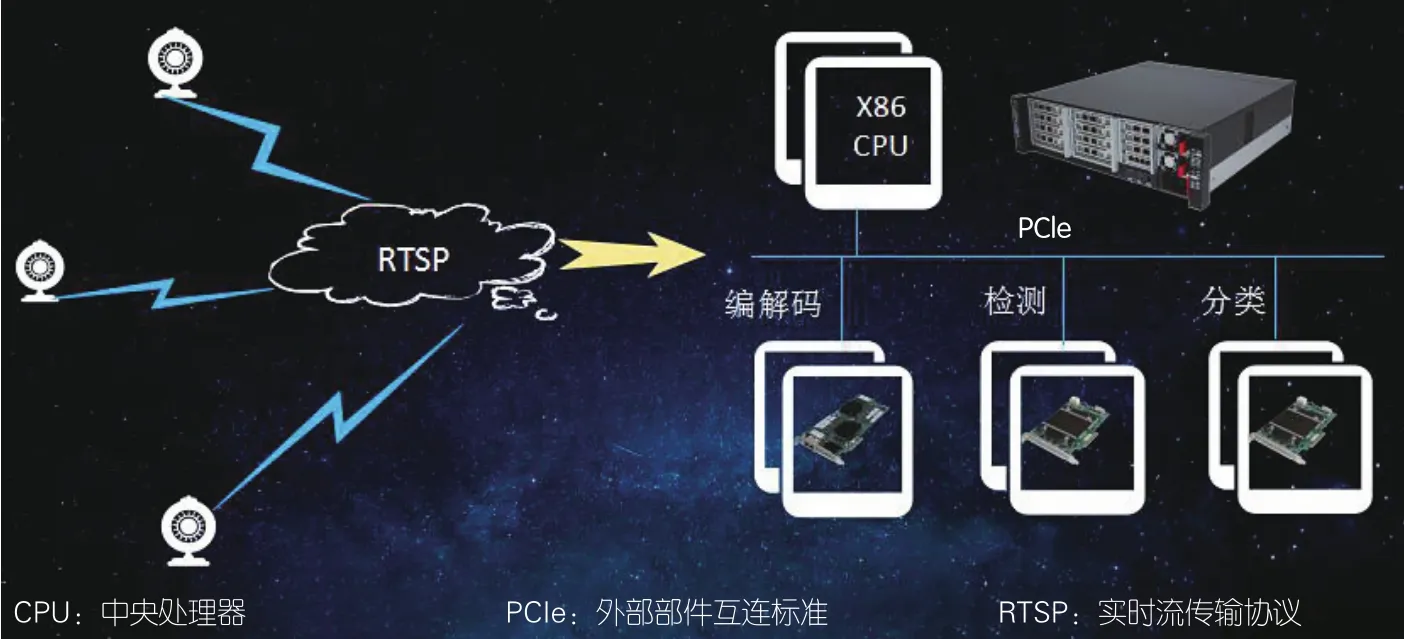
图4 中兴通讯视频结构化加速方案
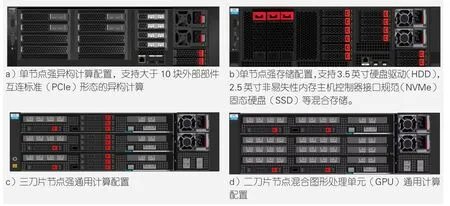
图5 中兴通讯开放边缘平台系列边缘定制化服务器
此外,针对边缘计算应用,中兴通讯还研发了网络加解密、防火墙、边缘高性能L4-L7 LB等加速智能网卡方案、边缘用户态高性能固态存储方案、裸金属GPU虚拟化方案以及超低延迟视频传输方案等多种异构计算和网络加速方案,以更好地服务各类边缘计算应用。
中兴通讯秉持开放、合作、共赢的态度,与整个生态链上的合作伙伴共同努力,为实现边缘计算的规模部署、落地和产业繁荣,积极贡献力量。
致谢
本文得到了中兴通讯股份有限公司无线产品经营部唐雄、钱健忠、强鹏辉、张启明、徐东和张景涛的鼎力帮助,谨致谢意。
猜你喜欢
美术界(2019年10期)2019-10-23 18:00:24
电子制作(2019年10期)2019-06-17 11:45:10
电子制作(2018年14期)2018-08-21 01:38:20
铁道通信信号(2018年5期)2018-06-28 03:06:08
电子测试(2017年11期)2017-12-15 08:57:56
自动化博览(2017年2期)2017-06-05 11:40:39
通信产业报(2016年44期)2017-03-13 08:41:45
中国交通信息化(2016年8期)2016-06-06 03:56:24
网络安全和信息化(2015年8期)2015-12-03 01:03:34
雕塑(1999年2期)1999-06-28 05:01:42
