
“神威·太湖之光”上Tend_lin并行优化
2019-04-08 03:13,,,,,
山东科技大学学报(自然科学版) 2019年2期
, , ,,,
(1.山东科技大学 计算机科学与工程学院,山东 青岛 266590;2.山东省计算中心(国家超级计算济南中心),山东 济南 2501013.中国科学院计算技术研究所 计算机体系结构国家重点实验室,北京 100190)
地球系统模式已成为研究和预测全球变化的有力工具,也是当前大气科学领域的研究热点之一。中科院大气物理所研发的大气环流模式(atmospheric general circulation models,AGCM),利用偏微分方程求解物理问题,是典型的高性能应用,是整个中科院地球系统模式CAS-ESM(earth system model)中最复杂的部分。其动力框架基于准一致网格[1]实现,在分辨率提高的同时,计算量增大,进程间通信量也随之增加。如何提升较高分辨率下的AGCM模式性能,已成为重要的研究课题。
“神威·太湖之光”是由我国自主研发的高性能异构众核处理器“申威(SW)26010”构建的超级计算机系统,其峰值性能超过100Pflops,曾4次蝉联世界超级计算机Top500榜首,目前在世界超算平台排名第3。申威众核处理器支持众核加速编程模型(神威OpenACC,简称SWACC)和加速线程库(Athread库)两种并行编程模型。徐金秀等[2]在神威平台上开展耦合算法的多级并行优化,并使用SWACC实现耦合算法的众核并行;李亿渊等[3]基于神威平台,利用Athread在线程级层面,对稀疏矩阵向量乘法进行并行算法设计和优化实现。众核异构平台相比传统的高性能硬件平台能提供更强大的计算能力和访存带宽[4],在国内当前主流的异构众核高性能平台上对AGCM进行众核并行化,成为目前的重要研究方向之一。
本研究面向国产众核异构平台“神威·太湖之光”,以中科院大气物理研究所研发的IAP AGCM4.0为基础,对其热点程序动力框架的适应过程构造Tend_lin应用,利用神威OpenACC编程模型实现Tend_lin应用的众核并行化。通过循环分布、循环分块并行将计算任务分配到计算核心,以高效DMA的方式将计算需要的数据批量传输到从核局存,消除计算过程中低效的全局离散访存,实现了Tend_lin应用在国产异构众核平台上的OpenACC并行化。
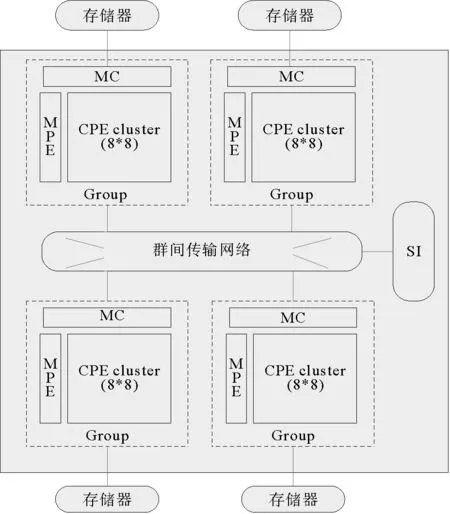
图1 申威众核处理器结构图
1 神威异构众核处理器体系结构
“神威·太湖之光”整机由40 960块SW26010处理器组成,并通过计算插件板、计算超节点和计算机仓等模式进行系统扩展。“申威(SW)26010”为主从核结构的异构众核处理器,集成4个运算核组共260个运算核心,采用片上计算阵列集群和分布式共享存储相结合的体系结构(图1)。
每个CPU包括4个异构核组(core-groups,CGs),每个异构核组由1个管理核心(management processing element,MPE,主核)、1个运算核心簇(computing processing elements clusters,CPE Cluster)、1个存储控制器(memory controller,MC)和系统接口(system interface,SI)组成[5]。
主核在大规模计算过程中通常用于完成管理计算核心以及与其他核组进行通信的任务[7]。CPE Cluster包含64个运算核心(computing processing elements,CPE,从核),以8×8的Mesh布局通过簇通信网络进行连接。每个从核具备私有的L1指令Cache,一个运算核心簇共享L2指令Cache,从核只能运行于用户模式并且不支持中断,适用于处理逻辑简单而计算相对密集的过程[8]。核组内共享内存。主/从核通过MC完成与主存的数据传输。每个从核均包括一个以SPM(scratch pad memory)方式组织的64 kB大小的局部数据存储器(local data memory,LDM),该空间需要用户显式的设计规划使用。
SW26010处理器从核LDM空间有限,往往无法满足使用大数组的科学计算程序存储要求,大部分数据存储在主存中。在计算过程中,必须通过一定的方式完成主存到从核LDM的数据传输。从核支持两种主存访问模式:1)全局读入/写出(gld/gst),直接完成主存到从核寄存器间的零散数据访问;2)直接内存访问(direct memory access,DMA),批量完成从内存到LDM的大量数据拷贝,通常延时较大,但带宽利用率较高。相比其他异构平台,从核由于存储空间和带宽限制,数据传输往往成为程序性能瓶颈。Xu等[9]在主存数据128字节对齐的前提下,在一个核组内64个从核中进行Stream Triad,PE模式下测得DMA的带宽可以达22.6 GB/s,而gld/gst方式每个核组带宽利用只有1.5 GB/s左右;延迟方面,从核gld单核延迟需要177个cycles,而从核访问局存的1d只需要4个cycles。可见,DMA方式比gld/gst能够更有效的利用带宽,但启动一次DMA需要300 cycles左右,开销较大,若DMA次数过多会大大降低程序性能。因此在SW26010异构众核处理器上,获得更好的数据传输性能的关键在于一次完整数据传输的数据量要尽可能大,并减少DMA的启动次数。
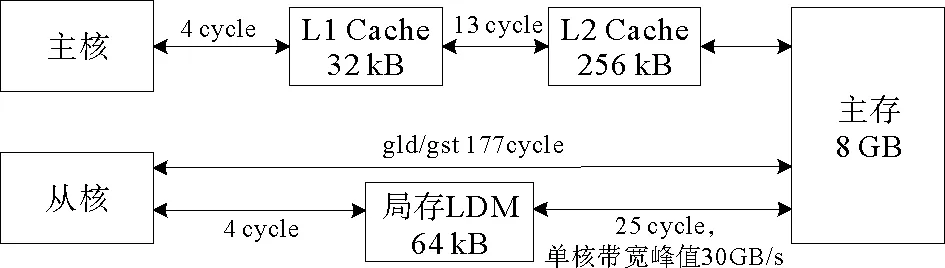
图2 单核组访存周期
2 AGCM及其适应过程Tend_lin应用的构成及特点分析
2.1 AGCM动力框架
CAS-ESM是以耦合器为核心的模块化软件,集成了大气、陆面、陆冰、海冰和海洋等分量模式的复杂系统,AGCM是其中最复杂的分量模式。
IAP AGCM主要由物理过程和动力框架两个过程组成。其中,物理过程计算量占比小,并行可扩展性较高;动力框架主要是用来求解关于时间的偏微分方程组,其计算在空间上是三维的,数值方法复杂,是主要的优化部分。IAP AGCM 4.0[12]的动力框架采用均匀经纬网格,并在高纬度采用灵活跳点格式[13]。格点模式中极区计算难以处理,模式引入滤波模块,将纬度划分为3个纬度带,不同纬度采用不同滤波方法以增加时间步长,避免计算不稳定。本研究提取IAP AGCM 4.0的热点动力框架中的适应过程Tend_lin作为研究对象。
2.2 Tend_lin构成及特点分析
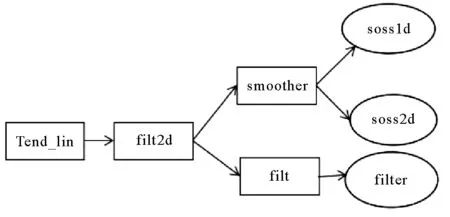
图3 Tend_lin应用中fft计算函数调用层次图
Tend_lin的计算过程主要包括两个不同的阶段,两个阶段的计算数据来自不同的数组,但都主要由stencil和1维fft两类计算组成,主要包括积分、滤波和平滑等计算类型;通信模式主要是近邻通信和集合通信。其中stencil计算涉及22组计算循环,占应用串行运行时间的71%,计算中用到临近若干点,每个计算循环的总访问足迹较大,其中14个纬度-高度-经度三维空间全遍历,计算访问3维数组较多。滤波和平滑功能的计算分别在filt和smoother中,不同纬度选择了不同的滤波方法,函数调用层次深(图3)。该阶段计算循环面对的是同一个高度上的数组区域,包含纬度-经度上遍历的两层循环,每个高度上要进行多阶段处理,不同高度间无数据依赖关系。虽然数据访问量小,但计算循环个数较多。
Tend_lin应用涉及73个计算循环和单入单出的代码块,数据访问多以数组形式在函数内动态分配内存空间。Tend_lin程序具有以下特点:①没有热点循环,任务并行代码散落于73个并行循环和单入单出的代码块上;②气候模式算法现状导致网格点分辨率不高,每个循环的并行度都不是很大,充分利用众核资源难度大;③循环间大小不一,并行度差异大;④计算/访存比值较低,访存优化为应用性能提升的关键;⑤各进程的计算行为不同构,在纬度方向上,不同进程采用不同滤波方法,且南北极需要特别处理。
为方便并行化,除适应过程的主函数Tend_lin之外,本研究增加了纬度和高度方向的区域分解,以及变量初始化部分,并为应用配备3个不同的问题规模A、B、C以匹配低、中、高不同分辨率,建立了包含59个源文件、2万行左右的benchmark程序。
下面,将AGCM中的Tend_lin串行代码移植到SW26010的主核上,并选取网格中典型分辨率即经度×纬度×高度为1.4°×1.4°×30L(下称规模B)阐述并行化过程;将B规模在经纬度的分辨率扩大2倍,得到计算规模是B规模4倍的C规模,用来进行全程序评估。B规模下,单个紧嵌计算循环最大访问足迹达62.8 M(stencil_11);2个计算循环为纬度-经度的二维计算,保持了纬度上的并行度,但缺少高度维,计算量较小;4个单入单出的代码块,包含经度-高度方向的规约操作;2个经度方向的单层循环计算。
3 Tend_lin应用的神威OpenACC众核并行化和优化
众核并行化主要目标就是将最耗时的循环迭代分散到多个从核线程上并行执行。下面主要从循环分布、循环分块及并行化、数据传输的优化以及函数调用的从核化4个方面描述Tend_lin应用在神威平台上的众核并行化方案。
3.1 循环分布
循环分布是在保证应用程序正确性的前提下,将源循环分解为多个独立的目标循环。Tend_lin应用中,并行循环均为典型的DOALL循环,DO循环中所有的循环实例都可以并行的执行,每个循环实例中的所有语句均串行执行。应用中包含了两类需要特殊处理的并行循环:一类是不同分支的数组读区域,难以被SWACC编译器合并,导致编译错误;另一类循环体中包含了多个访问区间不同的子循环且数据足迹较大,其循环体内访问了大量数据重用较低的数组,计算访存比过低。由于LDM尺寸有限,若直接并行该类循环,由于分块尺寸较小,数据重用低,会出现较大的数据传输开销,需要在并行化之前进行循环分布。
为避免出现激进的循环分布带来的开销可能会大于并行收益的情况,在对以上两种并行循环进行循环分布的同时要进行空间优化。
1) 分支结构的循环分布
stencil计算中存在带有分支结构的循环,不同分支间数组的J维访问区域冲突,如GHI(IB:IE, beglev:endlev, JB)和GHI(IB:IE, beglev:endlev, loc_JB:loc_JE),将其抽象为如图4左侧代码。由于并不知道JB和loc_JB:loc_JE的大小关系,编译器无法给出统一规则完成合并,进而不能完成编译。

图4 分支结构分布示意
经过对该循环的不同分支分布为图4右侧所示循环代码,程序能够正常编译且数据传输总量并没有变化。
2) 大数据足迹循环的循环分布
Tend_lin应用的02_stencil阶段存在非紧嵌循环(如图5左侧),并且:①最外层J循环内,有多个非紧嵌K-I子循环,这些子循环访问变量众多,对从核空间需求较大(约47 360 kB),即便最外层J维分块大小为1(约370 kB),仍远超从核LDM空间(64 kB);②不同的K-I子循环间访问数据足迹大小不一,不同循环间访问的数组不同,且循环间访问的数据无任何依赖或者重用;③K维访问区间各异,难以合并为紧嵌循环,且K维空间过小,不能提供有效的并行度,不适合K维并行。
对内层循环进行循环分布时,必须兼顾合法性和收益性问题。分布合法性指循环分布的原有数据依赖语义必须保持,既要保证源循环套并列循环间没有跨迭代依赖,又要保证两个语句组之间没有反向的数据依赖。而为保证循环分布后的收益,有数据重用的尽量放到一个循环套内[14],减少因拆分导致的同一数组的多次读取,避免额外开销。
本研究在保证J维并行的前提下进行循环分布,将一个执行次数较多的非紧嵌循环分割成若干个执行次数较少、访问足迹较小的完美紧嵌子循环(如图5右侧),以求每个小循环并行时,获得更大的循环分块尺寸,提高DMA效率。
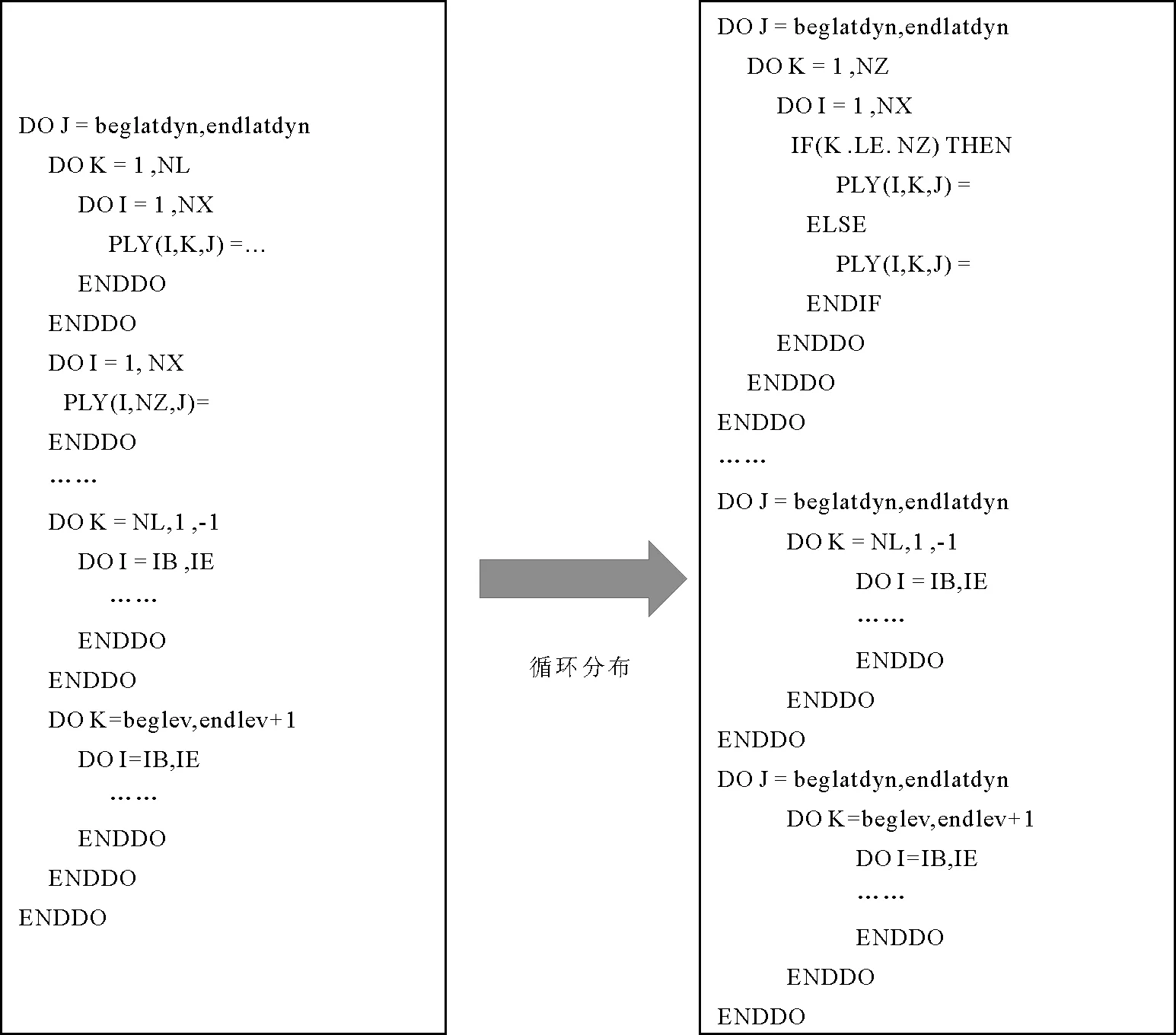
图5 大数据足迹循环分布示意
3.2 循环分块及并行化
神威OpenACC按照OpenACC 2.0[11]标准进行循环并行化,使用parallel和loop语句指示加速区代码,加载到从核并行执行。但与标准OpenACC不同的是,由于硬件结构的区别,神威上gang、worker、vector的三层循环设计没有分层的需求,默认gang设置成64,worker为1,vector也并未做SIMD功能支持。将硬件特征与程序特征进行匹配的循环分块可以充分的开发硬件架构的潜能,将串行程序生成适合粒度的并行分块程序。
1) 线程并行维度的选择
Tend_lin应用中进程间保留了IAPAGCM4.0中的纬度-高度二维的进程划分,本研究在线程间使用神威OpenACC进行众核并行化,支持一维的并行。应用中的并行DOALL循环除stencil_09外,数组索引与循环索引紧耦合,可直接选取循环索引最外层,即选择数组的最高维为并行维,以有效避免低效的低维跨步传输,提升DMA传输性能。
应用中并行循环之间访问足迹大小差距较大,导致对LDM空间的需求差异大,若使用全局一致的循环分块策略,则导致大部分的并行区LDM空间利用率不高,且OpenACC作为同步式的并行模型不需要全局一致的分块,故本文采取局部最优划分策略,保证每个循环执行时间最优。由于LDM空间有限,对于数据传输量较大的循环,即便并行维最小分块,也无法满足LDM空间需求。为了避免低效的跨步传输,本文选取最高维(纬度)和次高维(高度)使用循环分块子句tile进行二维划分,即纬度维循环并行分块,高度维做DMA流水分块。对于只划分并行维就可以满足空间需求的并行循环,则不再做次高维的流水划分。对于非耦合循环stencil_09,由于存在最内层K维的规约操作,不宜调整循环顺序,仅选取次高维(经度)流水分块。
2) 循环分块尺寸的选择
为充分利用从核LDM空间,并保证最少的DMA通信次数,编译器在对循环进行分块时,既要保证内循环块中访问的数据总量不超过LDM的大小,又要保证使用尽可能大的LDM空间。根据文献[14]中的面向异构多核处理器的循环分块方案,以访问足迹最大的紧嵌并行循环stencil_11为例,求解循环分块的可行解。分析过程如下:
step 1:计算并行循环的总空间需求
stencil_11使用的数组数据类型为双精度浮点类型,每个元素8个字节,计算该循环用到8个三维数组、3个二维数组和4个一维数组,另外还访问1个纬度方向跨度为1的3维数组和1个纬度方向跨度为2的2维数组作为阴影区,则共需要的数组尺寸为((256×128×30×8+256×128×3+256×4+256×1×30×1+256×2×1)×8)=63 774 720字节=62 280 kB,远超LDM空间64 kB,须进行循环分块后才能够放入局存当中。
step 2:确定最高维纬度j层分块大小
令该层的分块大小为1,这时循环访问的数组所占空间即数据足迹为558 kB,仍超过LDM空间,说明即便使分块大小为1,仅进行最外层(最高维)的循环分块,仍不能满足LDM空间需求的,需要对下一维进行划分。
step 3:确定次高维高度k层分块大小
当最外层大小为1时,数据足迹是LDM空间的8.7倍。由于循环访问的数组形状差异大,数据足迹和k层分块之间并不是严格成比例。当k层循环分块大小取3(30/8.7=3)时,数据足迹大小72 kB,超过LDM空间;当k层循环次外层分块大小取2时,数据足迹为54 kB,为本分块策略下最大可用空间,并为最大次外层分块尺寸。
通过以上3步,得到循环分块维度划分方案:最外层(并行维)按分块大小1划分,次外层按照分块大小2或1进行划分,最内层不划分。
3.3 数据传输优化
在第1部分介绍的从核线程的两种访存方式中,直接访存比全局离散访存能更好的利用带宽,因此从应用特征出发,最大可能地将计算所需的数据以DMA方式批量拷贝到LDM存储,消除计算过程中的离散全局访存是性能优化步骤的关键。
本研究采用将计算中所需的数据都存储在从核LDM中的数据管理策略,Tend_lin应用计算过程中访问的数组多为动态数组,编译器无法直接获取其区域信息;循环间访问行为各异,需要对数据传输进行差异化表达。经过3.1节循环分布,实现了循环中访问数组索引变量与循环的索引变量紧耦合,这些循环直接使用tile子句由编译器自动完成数组划分,搭配copy/copyin/copyout语句,在每个并行循环分块计算前,以DMA传输方式将所需数据传输到各个从核的LDM中,实现数据的提前拷贝。具体进行数据传输时需要解决以下几个问题:
1) 动态数组区域信息的表达
应用中的大量动态数组,在编译时编译器不能获得其维度信息,其形状不能被分析出来,无法在从核LDM中申请对应循环分块尺寸的空间,需要使用暗示制导语句annotate(dimension(array))来指明数组维度,为编译器划分数组提供依据。如图6所示,并行循环中DGH和GHI1数组为动态数组,利用copy/copyin子句搭配dimension暗示制导语句的形式实现动态数组的DMA传输。

图6 Dimension使用示意
2) 最低维的传输区域表达
Tend_lin应用的并行循环中,存在对非并行维非全维度的访问,如图7所示,J维为并行维,VT为动态分配内存空间的三维数组,在计算中I维只访问了区间[IB:IE],占全维度的98%,并没有访问全维度。
系统提供的parallel copy子句仅支持标量和数组,不支持子数组形式,因此copy子句只能传输全维度数据,而不是该维度的子区间(IB:IE)。若要实现非全维度的准确低维区间传输,只能利用数组声明进行手工修改。但由于精确传输的dma_get为跨步传输,单从核带宽为6.33 GB/s,64核带宽为30.48 GB/s。而直接使用copy子句进行I维全维度传输为非跨步传输,虽然数据量增加了2%,但单从核带宽可达8.14 GB/s,64核带宽为30.18 GB/s。导致两个方案在64线程时的DMA差别不到1%,即全维度传输虽然多使用了2%的存储空间,但未明显影响传输时间。因此最终选用copy子句实现I维全维度传输。
3) 循环不变数组的拷贝
图8中,相对于并行维J,只读数组A是循环不变数组,在并行循环中的每个实例是相同的,存在读读重用。循环中数组A的访问区域只与流水循环索引有关,编译器依照流水分块尺寸在流水循环内生成的多次DMA传输。这时利用annotate(entire(array))将整个数组在流水循环外以一次DMA的方式传输到每个从核LDM中,使每个从核的LDM中都保有该数组的一个完整副本。但由于LDM空间有限,该方式只适用于传输较小的数组。

图7 非并行维非全维度访问示意

图8 循环不变数组用法示意
4) 数组的转置后传输
如图9中的stencil_09循环,并行循环维度从高到低顺序为J、I、K,I循环内存在子循环K,对应TT1数组的最高维,循环内对TT1数组的访问是跨步访问,需要利用转置子句swapin对原始数据进行重新布局,改善数据传输效率。如图9所示,在数据传输前,主核使用swapin语句数据进行转置,使循环索引与数组索引的高低维顺序对应,以转置后的数组代替原数组访问,再按照循环分块进行传输。

图9 Swapin子句使用示意
对于该计算循环,转置前由于不能使用copyin将TT1拷入LDM,计算过程只能使用gld访存,计算时间占总执行时间的近80%;使用swapin转置后,该数组访问由低效的gld变为高效的ld操作,计算时间缩短了13倍,这样虽然转置时间占到了转置后计算循环总执行时间的30%,但计算时间的大幅缩短使整个循环执行时间减少2倍以上,该循环在整个程序中占计算比重20%,为tend_lin全程序带来5%左右的影响。
5) 标量的传输
每个并行循环中访问的标量最多有12个,平均5个左右,按照读写类型分为只写和只读两类。只写标量都为线程私有变量,可直接使用local子句本地化。
只读标量多带有parameter属性,即便不在制导语句中有任何体现,编译器仍然可以根据其parameter属性自动添加到copyin和annotate readonly子句中,在从核LDM中生成对等的parameter变量,直接赋值。对于不具备parameter属性的只读循环边界量,编译器也可自动添加到copyin和annotate readonly子句中,在每个从核LDM中生成一份拷贝,每个变量以一次gld的形式load到LDM中;对于不具备parameter属性的只读循环内部变量,编译器无法分析出该变量是否需要私有化,必须手动添加到copyin子句中才能在LDM中生成拷贝并以gld形式拷入。经过以上处理,将从核计算过程中所需要的数据在计算前存入从核LDM中。
为避免计算过程中不存在的低效gld/gst操作,利用“神威·太湖之光”上的性能分析工具penv_slave2_ gld_count和penv_slave2_gst_count,在编译器生成的中间代码中统计计算过程中从核gld/gst请求次数,确保完全消除了计算过程中的全局离散访存。
3.4 函数调用的从核并行
应用中,加速区存在大量routine函数调用,且关系复杂,若直接在routine函数调用层的循环外使用制导语句,循环内的routine函数调用无法直接生成从核版本,导致生成的从核代码找不到对应被调routine函数。
对于加速区的函数调用,在被调用函数内使用函数指示routine处理,为加速代码区中被调用的函数自动创建可在从核上执行的版本。
4 并行化方法的测评
本研究以Tend_lin应用在SW26010处理器1个主核上,使用-O3优化选项的串行版本为测试基准,并以主核串行版本输出为标准,相对误差控制在10-10以下。针对第3节提出的并行化方案,分别利用B、C规模进行实验性能评估。
4.1 不同分块大小对程序性能影响
根据3.2节,在B规模下,以最高维纬度为并行维,分块大小为1,次高维高度为流水维,最大访问足迹的并行循环流水分块分别使用1(36 kB)或者2(54 kB)对比测试;在最大访问足迹循环流水分块为2的基础上,为每个并行循环选取空间需求不超过LDM空间的最大流水分块尺寸,记为n。依此共设置三组对照实验,分别取分块大小为1×1、1×2和1×n,多线程相比主核单线程获得的加速比结果如图10所示。

图10 神威OpenACC版多线程不同分块尺寸性能对比
由图10(a)可看出,随着线程增加,纯计算阶段按比例加速,具有强扩展性,应用性能提升的关键在于优化访存性能。由图10(b)可知,随着流水分块的增大,应用性能不断提升,说明在满足LDM空间限制的前提下,DMA传输总量不变,随着流水分块尺寸的增大,DMA传输启动次数减少,降低了DMA开销;同时随着流水分块尺寸的增加,每次dma_get传输的向量长度增加,带宽利用率增大。以上两方面访存性能的提升使全程序性能随之提升。
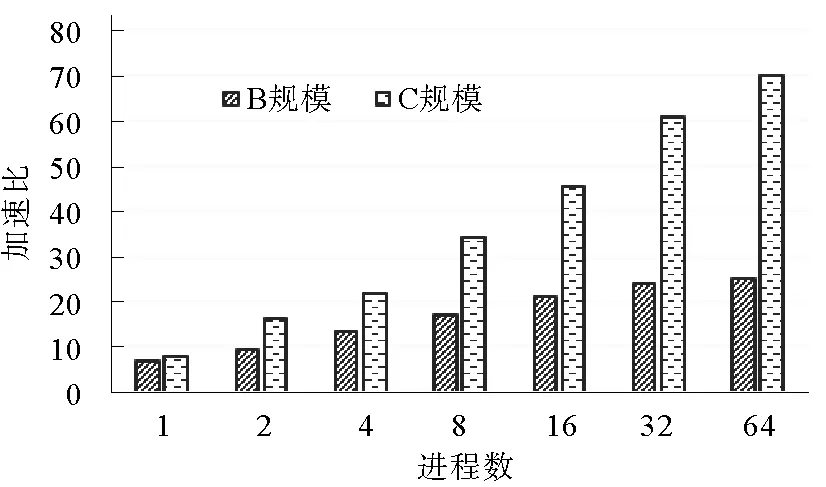
图11 Tend_lin应用不同规模多进程下加速比
4.2 全程序评估
在B、C两规模下使用二维进程布局,每个进程选取最优线程数下表现的性能,得到Tend_lin应用最终获得的全程序性能(如图11),在B规模下最终获得相比主核串行25倍的加速;随着分辨率的进一步扩大,在C规模下64进程时最高获得69倍加速。
5 总结
本研究基于国产异构众核平台“神威·太湖之光”,使用神威OpenACC并行编程模型对Tend_lin应用进行了并行化,分别从循环分布、循环分块、数据传输表达和函数调用从核化4个方面说明并行化方案。为保证高效的数据传输效率,从核并行选择数组的最高维为并行维,对于最高维并行不能满足LDM空间需求的循环,在次高维进行流水划分,并为每个并行循环选取最大的流水分块尺寸;从核并行化使用高效的DMA完成主存与LDM之间的数据传输,保证计算过程中只访问从核LDM空间,并重点对典型数据传输的表达进行讨论。最终应用在国产异构众核平台上,B规模单核组多线程获得6.8倍的全程序加速,多进程获得25倍加速;随着分辨率扩大,加速更加明显,C规模多进程下最多获得69倍加速。
猜你喜欢
中南民族大学学报(自然科学版)(2021年1期)2021-02-02
今日农业(2020年18期)2020-10-27
海外文摘·艺术(2020年3期)2020-06-13
铁道通信信号(2020年7期)2020-02-06
计算机与网络(2019年9期)2019-10-21
西夏学(2018年2期)2018-05-15
智能系统学报(2015年5期)2015-12-03
中国卫生(2014年12期)2014-11-12
组合机床与自动化加工技术(2014年10期)2014-03-01
现代电子技术(2009年8期)2009-06-25
