
网络表示学习算法的分析与验证
2019-04-02 03:08:18王岩,唐杰
中文信息学报 2019年2期
王 岩,唐 杰
(清华大学 计算机科学与技术系,北京 100084)
0 绪论
在互联网和多媒体技术兴起之前,社交网络分析领域所使用的数据量一直都比较小,但是随着一大批新兴社交媒体的普及,例如,Facebook、Twitter、Sina Weibo、Wechat和百度贴吧等,这些社交网络上的数据规模开始爆炸性增长,它们动辄具有上亿的用户,由这些用户产生的数据,如好友关系、发布的文本、图片乃至视频信息也到达了惊人的量级。除此之外,还有在学术研究中论文合作者或论文引用组成的网络,在专利申请中构成的网络,在网页相互链接构成的网络等等,这些超大规模数据的产生,也进一步推动着社交网络分析这一领域的发展。
网络表示学习算法是近年来网络分析中一个热点研究方向。对网络型数据或者对网络中的点或边的分析,一直以来都在构建各种评价指标的层面,而网络表示学习则给出了另一种看待网络的观点。在得到整个网络的特征表示,网络中各节点的表示乃至各边的向量表示之后,就可以使用各种传统机器学习方法(例如,支持向量机分类算法)来对各种表示进行更深层次的研究。从这个层面上来说,网络的表示学习意义重大,因为它在社会网络分析领域和传统机器学习领域搭建了一个连接的桥梁。网络表示学习的要求大致有以下两点: (1)通过学习网络的表示来保留网络的拓扑结构信息。(2)根据网络的表示学习进一步进行网络推断任务。例如,节点标签分类任务,边的存在与否的预测问题等。
此外,研究各类网络表示学习算法是否学习到了高阶或低阶的结构信息,在稀疏网络还是稠密网络上表现如何,算法是否具有较强的鲁棒性(是否对参数敏感)等问题,可以全面评价各类算法的性能、效率和应用范围等,也可以帮助以后的研究者或者在工业界的工程开发算法的选择上提供借鉴参考。
1 相关研究
网络表示学习吸引了大量数据挖掘和社会学的研究者,本文主要研究网络表示学习中的节点表示学习算法。初期的网络表示学习与维度缩减(Dimension Reduction)的经典方法相关,例如,多维缩放(Multi-dimension Scaling, MDS[1])、IsoMap[2]、LLE[3]和拉普拉斯特征映射(Laplacian Eigenmap[4])。 这些方法通常先使用数据点的特征向量构建亲和度图(例如,数据的K最紧邻图),再将这个图映射到低维空间中。然而,这些算法通常依赖于求解亲和度矩阵的主导特征向量,其时间复杂度很高,至少为节点数量N的二次方,使得它们很难处理大规模网络[2]。
此外,A Ahmed等在2013年WWW中提出了一种图分解(Graph Factorization[5])的技术。它通过矩阵分解找到图的低维表示,而后使用随机梯度下降算法(Stochastic Gradient Descent, SGD)来优化其节点的低维空间表示,该技术也具有同样受限于时空间复杂度的问题。
Shaosheng Cao等在2015年提出了一个能够很好地保留网络拓扑结构的算法GraRep[6]。该算法通过操作图中的不同阶的节点转移概率矩阵来捕捉不同阶的结构信息,而不需要任何缓慢和复杂的抽样过程。它将不同的转移概率矩阵进行分解以获得不同阶的特征表示,在各自归一化后并将它们合并起来作为最终的节点表示,通过适当选择最高阶数,GraRep就能最大程度保留网络的高、低阶的结构信息。
而后,在2016年Peng Cui等提出了模型HOPE[7],用于捕捉网络的高阶结构信息和保留有向图中节点之间的反对称关系,他们使用几个不同的网络结构描述矩阵,例如,Katz矩阵、Personalized PageRank矩阵或Adamic-Adar矩阵,并将它们应用到矩阵分解技术中,从而获得节点的特征表示。由于他们保持了图的非对称关系,所以在有向图中获得了很好的实验效果。
Bryan Perozzi在2014年根据图中随机游走的路径中节点出现的频率服从长尾分布,与自然语言处理中词频的分布十分相似,因而提出了使用语言模型中的深度学习技术Word2Vec来学习图的邻接矩阵的隐含表示的算法DeepWalk[8]。通过简单的随机游走策略生成一些路径后,将其作为语言模型Word2Vec的输入文本语料而学得每个节点的向量表示,取得了十分突出的效果。
此后,北京大学的Jian Tang等在定义了一阶接近度(First-order Proximity)与二阶接近度(Second-order Proximity)后,通过定义一个设计精妙的目标函数从而同时保留节点的一阶或二阶接近度,分别得到了节点的特征表示,并将每个节点的两类特征表示连接起来,成为最后表示的算法LINE(Large-scale Information Network Embedding)。又因其考虑到网络结构中较为高阶的信息,从而获得了良好的效果[9]。
Vincent W Zheng于2017年提出将节点的社区结构特征这种更高阶的信息增加到目标函数中。将基于LINE和高斯混合模型(Gaussian Mixure Model,GMM)加入到学习中而提出了ComEmbed[10]。它考虑将每个社区结构用一个高斯分量来代表,每个社区具有一个社区中心向量(社区特征表示)和该社区中所有节点特征表示的协方差矩阵,通过坐标下降(Coordinate Descent)迭代地优化节点特征表示和社区特征表示,ComEmbed获得了较好的效果。
Aditya Grover与Jure Leskovec在DeepWalk的基础上对其随机游走的策略提出了改进算法node2vec[11],使得随机游走的过程兼顾了广度优先搜索(Breadth-First Search, BFS)与深度优先搜索(Depth-First Search, DFS),从而提高了随机游走生成的路径的质量。但由于其在抽样的过程中要构建图中每一条边(节点v到u)到下一个点(u的一个邻居节点)的转移概率表,因而具有比DeepWalk更高的时间和空间复杂度。
Shaosheng Cao等在2016年考虑到使用Skip-gram 语言模型+ Negative Sampling优化算法,DeepWalk的目标函数的一个可行解是节点互信息矩阵(Pointwise Mutual Information,PMI)[12],因而将PMI矩阵的一个变形矩阵: 非负节点互信息矩阵(Positive Pointwise Mutual Information,PPMI)作为深度学习模型堆栈式自编码器(Stacked Denoising AutoEncoder,SDAE[13])的输入,将SDAE的最中间层的特征作为节点的最终表示,该深度学习模型为DNGR[14]。
Peng Cui等在2016年也提出了一个深度学习模型(Structral Deep Network Embedding, SDNE[15])。该模型能够通过一个半监督学习的框架,同时捕捉到节点的一阶接近度和二阶接近度[9]。具体来说,一阶接近度被用来保留节点的局部结构信息而作为模型的有监督部分,而二阶接近度被用来保留节点的全局结构信息而作为模型的无监督部分,是深度学习模型深度自编码器(Deep AutoEncoder,DAE)的输入。通过在半监督学习模型中联合优化节点的一阶接近度和二阶接近度,该模型能够同时保留网络的局部结构和全局结构,从而获得很好的效果[15]。
2 网络表示学习算法分析
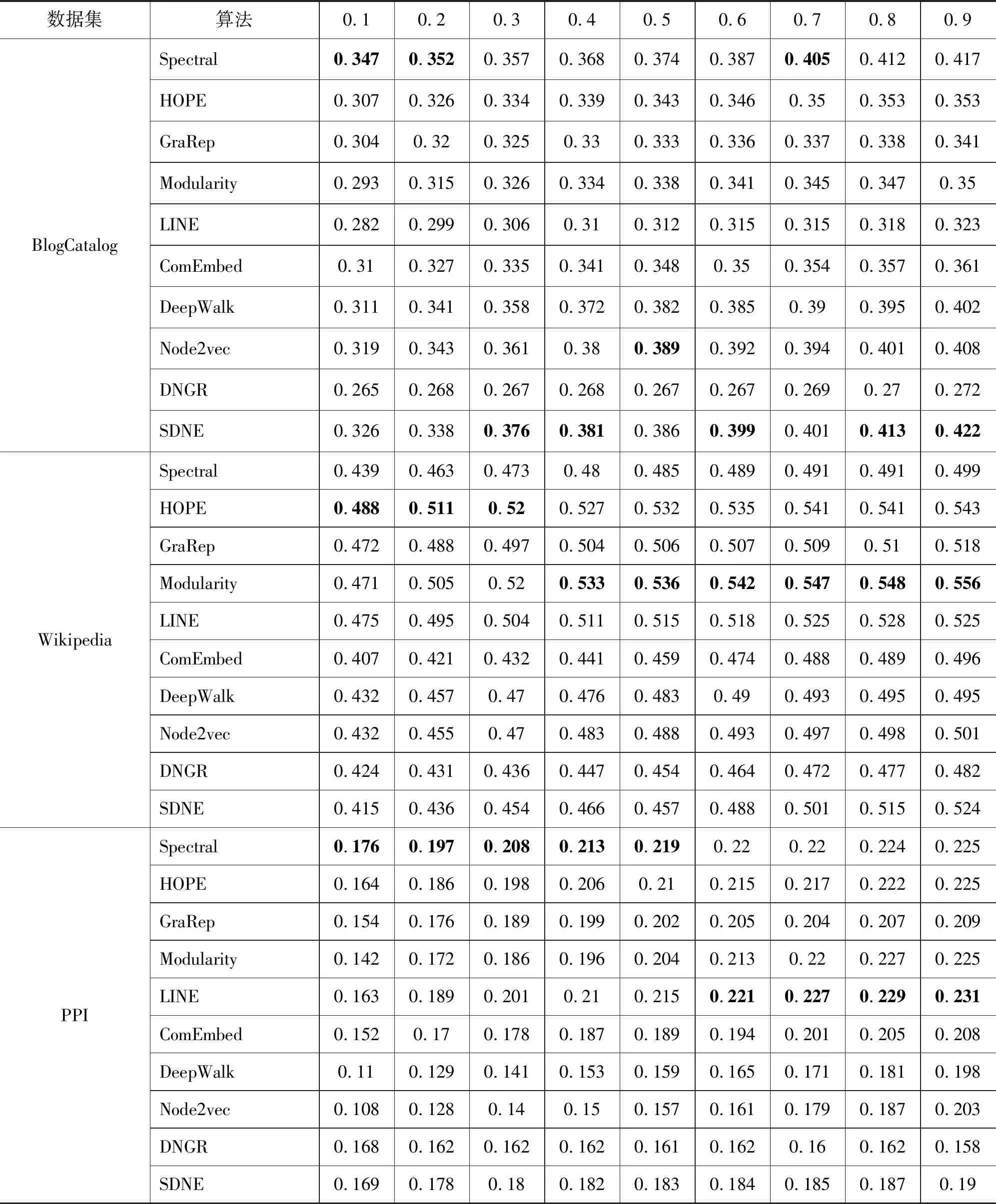
网络表示学习意在学习一个网络的结构信息在一个较低维空间的特征表示,形式化来说,给定一个网络G(V,E),网络中节点个数|V|=n,wv,u代表节点v与u之边的权重,边的总条数|E|=m。网络表示学习意在将每个图中的节点v∈V映射到一个低维空间Rd,也就是说学习一个函数fG:v→Rd,其中d 从这些不同的算法所使用的主要技术手段来分类,现有的网络表示学习方案大概有三类。 (1) 基于矩阵分解的算法,包括MDS[1],谱聚类算法(Spectral Clustering)[16],GraRep[6],Hope[7]等。 (2) 基于生成模型的算法,包括LINE[9],ComEmbed[10]等。 (3) 基于深度学习的算法,例如,DeepWalk[8],node2vec[11],DNGR[14],SDNE[15]等。 基于生成模型的算法,其一般会根据网络结构的特征建模一个概率分布,通过利用KL距离(Kullback-Leiler Divergence)等技术构建一个目标函数,再将其转化为目标函数的优化问题。然后,通过各种优化算法或近似技术,例如,随机梯度下降算法、负采样算法(Negative Sampling)来进行优化,最终获得网络的节点特征表示,例如,LINE[9]。 基于深度学习的模型,一般都会先定义一个目标函数,再利用现有的深度模型进行学习,例如,多层感知器,各种自编码器的变形,或者分层softmax等。 本文想要探究各类网络表示学习算法是否学习到了网络的结构信息,学到的是高阶还是低阶信息,算法的性能与网络的稀疏情况,节点聚集情况是否有关,算法在实际应用中是否具有稳定性等等问题。本文收集了不同类型的8个现实世界数据集,并利用这些网络来研究各类算法的表现。 在各种不同的网络上对那些算法进行评测,包括WebKB、Citeseer、BlogCatalog、Wikipedia、PPI、Aminer等。现在简单介绍这些网络的来源与构成。 WebKB[18]网络由4个子网组成,共有877个点和1 608条边。子网分别来自于美国四所大学: Cornell、Texas、Washington、Wisconsin,这里将节点的社区编号作为其标签,实验中独立使用四个子网。 Citeseer[19]网络是从Citeseer电子库中抽取的引用关系网络,节点是出版物,而有向边代表一个引用关系,由于出版物可以引用他们自身,所以网络中存在着自环。 Blogcatalog[20]是一个博客的社交网络,每个点代表了一个博主,而每条边代表了博主之间的社交关系。博主在提交博文时会附加一些兴趣标签,本文考虑将这些兴趣标签作为参考标准。 Wikipedia[21]是一个在维基百科前一百万字节中的单词共同出现的网络,而其标签代表由斯坦福的POS-Tagger推断出的Part-of-Speech(POS)。 Protein-Protein Interactions(PPI)[22]是Homo Sapiens网络的子图,该子图对应具有标记基因并代表生物状态的节点所构成的图。 表4.1 数据统计信息 实验中主要实现并评估了以下算法: Spectral Clustering[16]: 这个算法生成图的归一化的Laplace矩阵在低维空间的表示。 HOPE[7]: 该算法通过分解Katz矩阵以保留有向图的反对称性质,并集成了图中拓扑结构的高阶的接近度的信息。 Modularity[17]: 该算法用SVD矩阵分解的算法来分解图的模块度矩阵,其中模块度矩阵Q代表了图中分割的信息。因此,最终的表示编码了如何分割图G的信息。 GraRep[6]: 此算法基于节点的k步转移概率扩展了节点的高阶的接近度,将从矩阵分解中获得的不同阶的表示归一化后,连接在一起作为最终的表示。 LINE[9]: 这个算法精心设计了两个目标函数用来分别保留节点的一阶接近度和二阶接近度的信息,并将从两个目标函数中分别学习到的表示连接起来。 ComEmbed[10]: 该算法通过联合优化节点的表示与社区的表示,来保留一阶接近度与更高阶的社区结构的接近度。 DeepWalk[8]: 该算法通过截断的随机游走路径,将网络结构转化为线性的节点序列,而后利用Skip-gram模型与分层softmax技术来学习节点的表示。 Node2vec[11]: 它利用广度优先搜索和深度优先搜索来进行一个有偏置的随机游走,以便在节点的同质相似性和结构等价相似性上达到一个均衡。 DNGR[14]: 它利用堆栈式自编码器来学习非负节点互信息矩阵在低维空间的表示。 SDNE[15]: 此算法提出了一个基于深度自编码器的半监督学习模型,来联合地学习节点的一阶接近度与二阶接近度来保留网络的结构信息。 为了使算法的比较尽量公平,每个算法最终节点的表示维度d=128。 对GraRep而言,矩阵的最高阶次K=5。 对于HOPE而言, Katz矩阵构造过程中的参数β=0.01。 而对于DeepWalk,设置从每个节点开始的路径数γ=10,路径长度l=80,窗口大小w=5[8]。Node2vec与DeepWalk具有相同的参数,而其另外两个超参数p,q则通过网格搜索来从{0.25, 0.50, 1, 2, 4}中择优选择[11]。对LINE来说,设置初始的学习速率α=0.025,而负抽样的数量为mne=5,总的边抽样的条数为T=γ×l×n[9]。对ComEmbed算法,其参数设置也与DeepWalk相似,而初始的学习速率α=0.01。对DNGR而言,其随机平滑的总步长step=10,随机平滑的比例α=0.98,其模型的堆栈式自编码器的隐藏层数layer=2。最后对于SDNE,其深度自编码器的层数layer=2。 与DeepWalk相同,我们在节点的多标签分类任务上对所有算法进行评测,随机选择不同比例的有标签的节点及其部分标签作为训练集,而其他部分则作为测试集。所有算法最终的节点特征表示都用一个使用L2正则技术的one-vs rest的逻辑回归分类器训练,重复分类试验10次,并报告10次结果的平均微观F1值。由于宏观F1值的趋势与微观F1值相似,因此在这里就不报告了[11]。 表2和表3中,报告了所有网络表示学习算法(3.2节中的10种)在所有数据集(3.1中的8类)上的分类效果的实验结果。每一行代表了某一个算法在某一个数据集上进行学习其网络表示,而后使用分类器进行训练。训练数据和测试数据的比例从10%到90%不等,表格中的每一项代表使用分类器进行分类的准确率。数值越大,代表分类效果越好,也代表了网络表示学习算法的性能越好,能捕捉更多的结构信息。根据表中的结果,可以得到如下的观察与分析。 (1) 基于矩阵分解的算法,例如,Spectral Clustering、HOPE、GraRep以及Modularity在较为稠密的网络上表现一般,但在一些特别的网络上有些算法表现很好(GraRep 在Wisconsin,HOPE在Cornell)。而在较为稀疏的网络上,它们表现得较好一些(Spectral Clustering在BlogCatalog、PPI,HOPE、Modularity在Wikipedia)。但是由于它们都有较高的时空复杂度,因此很难应用到大规模的网络上,从而限制了它们的实际应用。 (2) 对于LINE来说,在稀疏和较为发散(低聚集系数)的网络上表现很好(LINE在Citeseer、PPI),ComEmbed比LINE表现的更好,因为它将更高阶的接近度信息(社区结构信息)纳入到考虑中。 (3) 深度学习模型表现出了最稳定的效果以及在大多数网络上有着最佳的表现(DeepWalk、node2vec在Washington、Texas、BlogCatalog上)。然而node2vec运行的速度要比DeepWalk慢得多。此外,DNGR表现的很一般,因其实质上就是对一个非负节点互信息矩阵进行分解,只不过不是通过显式的SVD等技术,而是通过深度学习中的堆栈式自编码器来学习其潜在表示, 在细致地调节其参数时,可以获得不错的效果。至于SDNE,精心对深度学习模型的参数进行调整后,在某些数据集上,它拥有着最佳的表现(SDNE在BlogCatalog),但是复杂深度学习模型所拥有的参数过多,难以调节,运行时间较长等因素也会影响其应用[15]。 表2 各类算法效果1 续表 表3 各类算法效果2 本文研究了现有各种网络表示学习算法,并分析各类算法在不同类型网络中的性能。将这些算法利用SAE平台实现后,在各类不同网络数据集上进行了网络节点的多标签分类任务评测,以此评估这些算法的效果,且对算法的效率、使用范围、性能等进行了分析。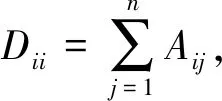
3 实验
3.1 数据集
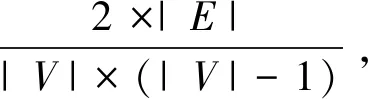

3.2 实验算法
3.3 参数设置
3.4 实验分析


4 总结
猜你喜欢
数学物理学报(2021年1期)2021-03-29 03:13:48
数学物理学报(2020年6期)2021-01-14 01:00:36
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
哈尔滨轴承(2020年1期)2020-11-03 09:16:02
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
