
基于神经网络的藏语语音合成
2019-04-02 02:55:34都格草才让卓玛南措吉算太本
中文信息学报 2019年2期
都格草,才让卓玛,南措吉,算太本
(青海师范大学 计算机学院 藏文智能信息处理与机器翻译重点实验室,青海 西宁 810008)
0 引言
语音合成(speech synthesis)是人机交互的核心技术之一,也是中文信息处理领域的一项前沿技术。语音合成的目标是将文字信息自动转换为清晰、流畅的语音,它的研究对自动控制、智能机器人和人机语音通信系统等的研制具有重要的理论意义和实用价值。随着计算机技术和通信技术的发展,语音合成技术越来越引起社会的关注。
语音合成技术的发展按时间顺序大致经历了机械式、电子式和计算机语音合成[1]三个阶段。尽管计算机语音合成技术由于其侧重点的不同,分类方法也有所差异,但当前主流和获得较认同的分类是将语音合成方法按照设计思想分为规则驱动(rule-based)方法和数据驱动(data-based)方法。前者的主要思想是根据人类发音的物理过程制定一系列规则来模拟语音合成过程,例如共振峰合成和发音规则合成;数据驱动方法则是对语音库的数据用统计方法实现合成,例如波形拼接(concatenative synthesis)合成[2]、基于隐马尔可夫模型(hidden markov model,HMM)的统计参数语音合成[3]及深度神经网络(deep neural networks,DNN)的语音合成[4-8]。相对而言,基于数据驱动方法更为成功,也更受研究人员的青睐。近年来,随着神经网络方法在机器翻译、文本分类、问答系统及信息抽取等领域的广泛应用,基于神经网络的语音处理技术在语音合成中也取得了显著成绩[9-12],从而成为当前研究语音识别及合成的主流技术。
藏语语音合成技术是中文信息处理的重要任务之一,目前藏语语音合成系统的实现主要采用波形拼接技术[13]或基于隐马尔可夫模型(HMM)统计参数语音合成技术[14-15]。考虑到波形拼接技术对存储容量要求高且系统构建周期长,而统计参数语音合成技术的合成语音效果不稳定且韵律表现不佳,本文通过分析藏文字结构与拼读规则,融合Sequence to Sequence(简称Seq2Seq)模型和注意力机制(attention),研究基于神经网络的藏语语音合成技术。
本文分为几个部分:引言主要介绍语音合成技术的发展及藏语语音合成研究现状;第1部分介绍语音合成模型相关技术;第2部分给出了基于神经网络的藏语语音合成方法;第3部分进行了实验及实验结果分析;第4部分是结语与展望。
1 语音合成模型
随着神经网络理论的不断深入,基于神经网络的各种模型被广泛地应用于语音合成中。例如,文献[4]中使用DNN模型进行语音合成、文献[5-7]使用循环神经网络(recurrent neural network, RNN)模型进行语音合成,而文献[8]使用长短时记忆网络(long short term memory,LSTM)模型进行语音合成等。考虑到Seq2Seq模型突破了传统神经网络的固定大小输入问题,并在英语-法语翻译、英语—德语翻译[16-17]等的应用中有着不俗的表现。本文采用基于Seq2Seq模型和注意力机制融合研究藏语语音合成。Seq2Seq模型主要通过深度神经网络模型(常用的是LSTM,长短时记忆网络)将一个作为输入的序列映射为一个作为输出的序列。
1.1 Seq2Seq
2014年,Google Brain团队和Yoshua Bengio团队针对机器翻译的相关问题不约而同地提出了Seq2Seq模型[17-18],该模型通过使用长短时记忆网络或者递归神经网络(recursive neural network,RNN)将一个序列作为输入映射为另外一个输出序列,机器翻译的准确率因为该模型的应用而有了较大的提升。同时,由于Seq2Seq模型突破了传统的固定大小输入问题,从而被广泛应用于自动编码、分类器训练、句法分析、文本自动摘要、智能对话系统、语音合成与识别等领域。Seq2Seq模型结构如图1所示。

图1 Seq2seq模型
从图1中可见,Seq2Seq模型是一个编码器到解码器结构的网络,通过编码器来产生上下文向量C(其中C有可能是一个输入序列X={x1,x2,…,xT}的向量或者向量序列),向量C输入到解码器,得到输出序列Y(输出序列Y={y1,y2,…,yT})。
1.2 注意力机制
Seq2Seq模型中输入序列的所有信息都被编译成一定维度的特征向量C,但随着序列的不断增长,Seq2Seq模型处理较长数据时会出现两个问题,其一是无论输入有多长,都被编码成一个固定长度的向量,当句子比较长时编码结果可能会损失较多的信息,这将不利于接下来的解码工作;其次,每个时刻的输出在解码过程中用到的上下文向量都相同,也会给解码带来困难。为了解决这些问题,需要引入注意力机制,该机制的核心目标是从输入序列和输出序列中选择出对当前任务目标更关键的信息。计算上下文向量C如式(1)所示。
(1)
其中h(t)为编码器输出的特征向量,a(t)为权重。a(t)权重向量在Decoder每次进行预测时都不一样,计算方法如式(2)所示。
(2)
其中的eij代表Encoder的第j个输入与Decoder的第i个输出的注意力匹配程度。
2 基于神经网络的藏语语音合成
藏语文字是一种拼音文字,主要由30个辅音字母和4个元音组成[20]。辅音字母中有10个后加字,4个下加字。后加字中5个字母也可作前加字、2个字母也可作重后加字、3个字母也可作上加字。藏语虽有卫藏方言、康方言和安多方言等不同方言,但各方言都遵从相同的文法与拼接规则[19]。藏文字以基字为中心呈横向与纵向结构。其基字的横向有前加字、后加字、重后加字拼写,而基字的纵向还有上加字、下加字和元音拼写。藏文字的基本结构如图2所示。藏文字的拼读按照其文字结构逐项叠加进行[21],即将藏文字按其基本结构从左往右、从上到下逐项拼读,便可得到相应的音节,音节中的元音通常只出现一次。藏文字拼读顺序示意图如图3所示。

图2 藏文字的基本结构
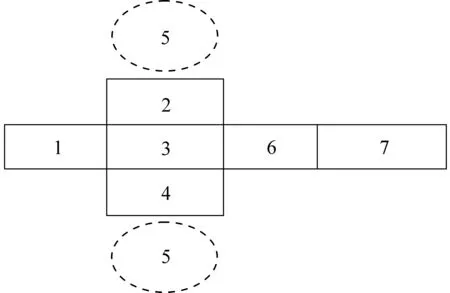
图3 藏文字拼读顺序示意图
2.1 字符嵌入
在基于神经网络的语音合成模型中,输入为一系列文本字向量,输出为声谱图, 然后使用Griffin_Lim算法[22]生成对应音频。以下将对模型进行简单介绍。


图4 藏文字符嵌入过程
2.2 提取语音特征
人的听觉系统是一个特殊的非线性系统,它响应不同频率信号的灵敏度是不同的。在语音特征的提取上,人类听觉系统做得非常好,它不仅能提取出语义信息,而且能提取出说话人的个人特征。因此,为了使合成系统能更好地模拟人类听觉感知处理特点,本文在语音特征的选取中主要考虑了参数维度低且更符合听觉系统的梅尔频率倒谱系数(mel frequency cepstral coefficients,MFCC)。MFCC的主要思想是先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上,其主要过程如下:首先,对语音进行预加重、分帧和加窗;其次,对每一个短时分析窗,通过快速傅里叶氏变换(fast fourier transformation,FFT)得到对应的频谱(spectrum),并通过Mel滤波器组得到Mel频谱;最后,在Mel频谱上面进行倒谱分析,即取对数,做傅里叶变换逆变换,获得Mel频率倒谱系数MFCC。
2.3 模型构建
第1节已介绍Seq2Seq模型与注意力机制。该模型主要由编码器与解码器两大模块组成。
2.3.1 编码器模块
编码器模块主要包含预网(pre-net)结构与CBHG(全称conv bank highway gru_rnn)结构。模块训练过程如图5所示。

图5 编码器模块训练过程
Pre-net的主要功能是对输入进行一系列非线性的变换。它是一个3层的网络结构,有两个隐藏层,层与层之间均为全连接。第一层的神经元个数与输入藏文词向量个数一致,第二层的神经元个数为第一层的一半。两个隐藏层采用的激活函数均为ReLu,并保持0.5的dropout来提高泛化能力。CBHG主要用于提高模型的泛化能力。Pre-net的输出经过一个卷积层。它有K个大小不同的1维滤波器(filter),其中Filter的大小为1,2,3,…,K(16)。大小不同的卷积核提取长度不同的上下文信息。然后,将经过不同大小的K个卷积核的输出堆积在一起。下一层为最大池化层(max-pool),步长(stride)为1。经过池化之后,会再经过两层一维的卷积层。第一个卷积层的Filter大小为3,Stride为1,采用的激活函数为ReLu;第二个卷积层的Filter大小为3,Stride为1,没有采用激活函数。然后把卷积层输出与字符的序列相加输入到Highway layers中,同时放入到两个一层的全连接网络,两个网络的激活函数分别采用ReLu和Sigmoid函数。假定输入为Input,ReLu的输出为H,Sigmoid的输出为T,Highway layer的输出为:Output=H×T+Input×(1-T)。它的输出提供给GRU模型,得到上下文向量C。
2.3.2 解码器模块
解码器模块主要分为Pre-net、Attention RNN、Decoder RNN三部分。模块训练过程如图6所示。

图6 解码器模块训练过程
Pre-net的结构与Encoder中的Pre-net相同,主要是对输入做一些非线性变换。Attention RNN的结构为一层包含256个GRU的RNN单元,它将Pre-net的输出和注意力机制的输出作为输入,经过GRU单元后输出到Decoder RNN中。Decode RNN为两层Residual GRU,它的输出为输入与经过GRU单元输出之和。
在Decoder-RNN输出之后并没有直接将输出转化为音频文件,所以添加了后处理的网络。后处理的网络在一个线性频率范围内预测幅度谱(spectral magnitude),并且后处理网络能看到整个解码的序列从左至右地运行。后处理网络通过反向传播来修正每一帧的错误。最后使用Griffin-Lim算法生成音频。
3 实验及结果分析
训练神经网络模型时语料是必不可少的主要要素,本实验使用的语料是藏族第1部哲理格言诗集《萨迦格言》,诗集强调知识、智慧的作用,它既是藏族学者必读著作,也在群众中口头广泛流传。诗集中有456个韵文,每个韵文由四个句子构成,每个句子有7个音节,总共有1 824个句子和12 768个音节。这些语料作为本文的训练数据。采样率为16kHz,采样精度为16bits。
为了评估模型的性能和模型拟合的好坏,本文从客观和主观两方面进行分析。客观上用模型训练的误差函数来度量拟合程度。误差(loss)函数极小化,意味着拟合程度最好,对应的模型参数即为最优参数。由图7可知,模型训练的误差逐步极小化,说明模型的拟合程度最好,收敛速度最快。图中train/loss是快速傅里叶变换与MFCC语音特征和的误差图,train/loss1是MFCC特征在训练过程中的误差图,误差接近0,说明训练后的MFCC值靠近原始MFCC的值。train/lr是不同的学习率下每轮完整迭代过后的loss应该呈现的变化状况,初始学习率设为0.001,先使用较大的学习率来快速得到一个较优的解,然后随着迭代的继续,逐步减小学习率,使得模型在训练后期更加稳定。


图7 训练藏语语音合成模型的误差
主观上,由7位测听员通过对合成语音与原始语音(设定为5分)进行对比打分给出了MOS分。
表1是不同测试语料下合成语音的清晰度、自然度的MOS值。

表1 合成语音的MOS值
由表1可见,合成语音的清晰度和自然度分别为3.46和3.9分,基本能达到预期效果。评分中测听员一致认为能够完全听清楚合成语音的内容,语音自然、清晰,但与原始真人语音相比有较重的机器味。
4 结语与展望
语音合成技术的主要任务是将文本映射为音频信号。为了提高语音合成的自然度和清晰度,本文通过分析藏文字结构与拼读规则,融合Seq2Seq模型和注意力机制研究基于神经网络的藏语语音合成技术。基于神经网络的语音合成模型中,输入为一系列文本字向量和MFCC语音特征,并进行神经网络模型训练,输出为声谱图, 然后使用Griffin_Lim算法生成对应音频。为了评估模型的性能和模型拟合的好坏,本文从模型训练的误差和MOS评估两方面进行客观和主观分析,合成效果均达到预期目标。
在本文研究内容的基础上,后续的工作主要是收集更多的语料,并加强语料文体的多样化,对藏语的语言学和语音学内在关系进行深入研究。
猜你喜欢
客联(2022年2期)2022-04-29 22:05:07
中国音乐学(2020年2期)2020-12-14 03:07:24
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
西藏研究(2017年3期)2017-09-05 09:44:58
电子设计工程(2017年20期)2017-02-10 03:39:29
海外华文教育(2016年1期)2017-01-20 08:21:58
西藏研究(2016年5期)2016-06-15 12:56:42
电子器件(2015年5期)2015-12-29 08:42:24
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
