
支持高并发的Hadoop高性能加密方法研究
2019-04-01 11:44金伟余铭洁李凤华杨正坤耿魁
通信学报 2019年12期
金伟,余铭洁,李凤华,杨正坤,耿魁
(1.中国科学院信息工程研究所,北京 100093;2.中国科学院大学网络空间安全学院,北京 100049;3.中国科学技术大学网络空间安全学院,安徽 合肥 230027)
1 引言
Hadoop是一种可以对海量数据集进行分布式存储与处理的开源软件框架,该框架通过搭建单一服务器或多台服务器集群,为用户提供高可用性、可扩展性和高容错性服务。目前,Hadoop平台在电子凭据、医疗服务等结构化和非结构化数据的服务领域均占有广泛的市场。
伴随着Hadoop的快速发展,其安全问题也日益凸显。据CVE(common vulnerabilities and exposures)漏洞列表显示,从2013年到2019年6月,已暴露出的Hadoop漏洞数量共计21个,其中包括6个关于信息泄露的漏洞,这些漏洞带来了严重的安全隐患。
为确保存储在Hadoop平台中的数据不被泄露,现有的典型技术包括访问控制、数据加密等。其中,访问控制作为数据保护的第一道防线,通过开启Kerberos等身份认证机制,确认用户真实身份,并通过Sentry、Ranger等组件为用户对数据的访问提供细粒度控制。然而,访问控制具有边界性,一旦数据脱离了数据控制域,访问控制将会失效。相反,数据加密技术通过引入加密算法对大数据平台中的关键数据进行加密保护,以密文方式存储和传输,即使数据脱离访问控制域,也将为数据提供持续保护。目前,加密技术已成为确保Hadoop平台中数据安全的“护城河”。
目前,Hadoop的加密包括传输加密和存储加密。在传输加密方面,Hadoop平台的多数组件已有SASL(simple authentication and security layer)、SSL/TLV(secure sockets layer/transport layer security)等成熟稳定的传输协议实现数据高效加密传输;在存储加密方面,Apache Hadoop自2.6.0版本起增加了KMS(key management server)密钥管理模块,并增加了透明加解密机制,允许用户或管理员设置加密区,向加密区上传/下载数据时,Hadoop平台自动加密后进行传输和存储。然而,现有的KMS存在如下问题。
1)密钥检索效率低。当前,Hadoop发行版中的加密区密钥是按照密钥名与版本号的散列值将密钥散乱排列到HashTable中,相同密钥的不同版本也散乱排列到HashTable中,这种散乱排列导致密钥检索效率低。
2)加解密性能低。Hadoop平台本地文件加密过程包括以下3步:待加密明文准备、明文加密和密文发送准备。在当前Hadoop发行版中,这3个步骤串行执行,即在某个步骤执行过程中其他步骤处于空闲状态;在明文加密过程中,对明文的加密也是串行执行。上述2种原因导致加密资源利用不充分、性能低。
3)加解密算法非国产。当前,Hadoop发行版中主要采用的加解密算法是美国国家标准与技术研究院的AES(advanced encryption standard)算法,这些发行版不支持密码算法动态配置。特别地,对中国来说,未采用国产密码算法,使密码应用关键环节存在重要不可控因素,这可能导致在Hadoop平台中“门是自家的,但钥匙在别人手中”的后果。
针对上述问题,本文提出一种面向Hadoop平台的高效密钥管理方案,实现国产商用密码算法补充AES算法,利用新的密钥存储结构提高密钥的存取效率,采用流水线方法异步优化加解密算法处理流程,提升Hadoop平台文件加解密速度。本文主要贡献如下。
1)提出基于国产商用密码算法的Hadoop平台三层密钥管理体系,对密钥库口令、加密区密钥、文件密钥这三层密钥逐级加密,确保密钥安全。
2)针对密钥检索效率低的问题,设计“密钥串”存储结构,该结构能够紧凑组织二级密钥的存储,提高密钥存取效率。
3)针对加解密性能低的问题,提出了异步流水模式的并发加解密方案,替代Hadoop原有的串行加解密流程,提高Hadoop文件加解密效率。
4)实现了基于商用密码算法的Hadoop平台三层密钥管理,实验结果表明,本文方法可有效提升Hadoop平台数据加解密效率。
2 相关工作
2.1 面向Hadoop平台的加解密
如前文所述,面向Hadoop平台的加解密主要聚焦于传输加密、存储加密及其高性能实现。
在传输加密方面,Hadoop主要使用SASL认证框架,从认证、消息完整性、机密性等多方面保护客户端与服务器之间交换的数据[1]。在Apache Hadoop 2.9.2版本中,Hadoop服务可开启RPC(remote procedure call)数据加密。Apache Hadoop自2.5.2版本始支持SSL/TLS v1,Apache Hive自1.0版本起添加SSLv2协议。HDFS(Hadoop distributed file system)、YARN(yet another resource negotiator)、MapReduce、Oozie等组件均支持SSL网络传输,并且不影响KMS和HttpFS的安全使用。
在存储加密方面,HBase支持HFile v3单数据项级的数据库加密,使用两级密钥,并使用SASL协议和Kerberos协议分别为RPC和ZooKeeper进行认证。Apache Hadoop自2.6.0版本始添加了端到端的透明加解密机制,用户可设置加密区,向加密区上传/下载文件时,数据在客户端自动加解密,实现传输安全和存储安全,支持AES、3DES(triple data encryption algorithm)和RC4(rivest cipher 4)等多种算法,其中AES算法速度最快,但文件加密模式仅支持“AES/CTR/NoPadding”(CTR为counter,表示计数器模式;NoPadding表示无补丁)。梁胜昔等[2]提出一种HDFS混合加密保护方案,支持AES、RC4混合加密模式,可用于实现云数据安全共享。文献[3]在Hadoop平台中建立基于双线性椭圆曲线的认证和加密机制,并对数据访问进行审计,保护Hadoop平台数据安全,但基于非对称密钥的运算开销较大,配置复杂。Wang等[4]借助Hadoop平台和Sqoop组件,分布式处理数据库的加密运算,保护海量数据安全。
在加密算法替换与补充方面,Song等[5]在HDFS透明加密机制含有AES算法的基础上,添加了ARIA分组加密算法,使HDFS加密系统双算法可选。Lin等[6]提出了HDFS-RSA算法和HDFS-Pairing算法2种实现补充,使用混合加密机制保护Hadoop平台数据机密性,并进行仿真验证。上述工作主要聚焦于Hadoop平台下传输与存储中加解密的透明性,忽略了Hadoop环境下对加解密的性能需求。
在高性能实现方面,Bhatotia等[7]使用GPU提升Hadoop的计算和存储速度。Cloudera与Intel合作的Rhino项目为HBase 0.98贡献了关键的安全特性。它提供了数据单元(cell)级别的加密和细粒度访问权限控制的功能。同时,Intel研制的AES-NI可为HDFS提供硬件加速。Cohen等[8]使用可信平台模块(TPM,trusted platform module)进行密钥保护,应用AES-NI指令集进行硬件加速,最高计算速度可达1.84 GB/s,是同数量级软件加密速度的18倍。
但是,CPU层面的硬件加速仅适用于X86处理器,对硬件品牌要求高,操作系统支持的通用性较差,无法广泛适配Hadoop平台的各种服务器机型,并且,AES-NI主要针对AES算法,对于其他算法的速度暂无提升。
2.2 密钥管理机制
目前,针对Hadoop系统的密钥管理的研究相对较少,但从云环境密钥管理出发,已有很多研究可供借鉴。本文从云环境密钥管理入手,对相关研究进行论述。
Zhou等[9]针对面向群组的应用中层次化访问控制的密钥管理问题,从密钥管理拓扑模型、密钥更新方法与策略等方面分析了安全分发和密钥更新的典型需求,枚举了密钥管理方案所需机制。Kandah等[10]针对大数据环境下无线传感网动态环境低耗能密钥分发需求,提出了中心状态链接(CSC,centralized stateful connection)方案,动态地管理传感网密钥,并通过公钥加密对称密钥,然后使用对称密钥加密传输数据,从而减少开销。Albakri等[11]提出了一种基于多项式的轻量级层次密钥机制,管理雾节点(fog node)与其他用户设备间的密钥共享,有效保证物联网设备安全接入的同时,不增加用户设备的存储空间占用。
3 Hadoop平台密钥管理架构
3.1 基于商密算法的三层密钥管理体系
如图1所示,本文所提架构采用三层密钥管理体系对Hadoop平台中的海量密钥进行保护和管理。其中,一级密钥为加密区密钥库口令,将该口令采用SM3单向函数进行散列处理后用于加密二级密钥,该口令存储在本地文件中;二级密钥为加密区密钥,该密钥与加密区绑定(即加密区与二级密钥存在一一映射关系),并用散列化后的一级密钥加密,将加密后的二级密钥存储在加密区密钥库中;三级密钥为文件密钥,用于加解密存储在加密区中的文件,文件密钥使用二级密钥加密,以密文方式存储在NameNode文件目录的扩展属性中。
1)一级密钥管理
一级密钥即密钥库口令,在KMS部署时,由管理员进行配置,以明文的形式存储于本地文件中。当KMS启动时,从文件中读取口令,以字节数组的形式存储在内存中。当KMS加载或存储加密区密钥时,对该口令使用SM3单向函数散列处理,用散列化的口令对二级密钥进行加密或解密。
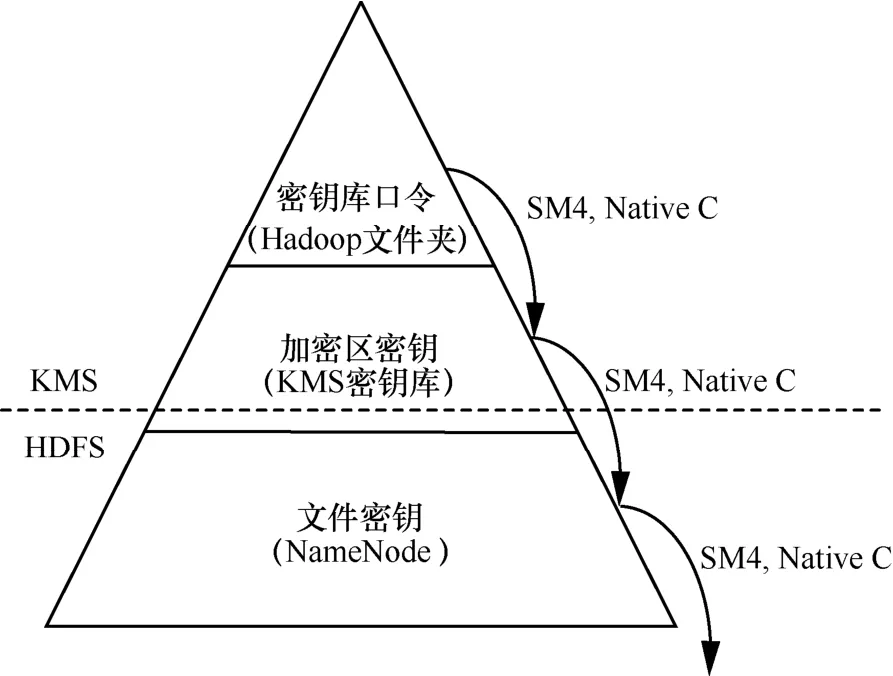
图1 三层密钥管理结构
2)二级密钥管理
二级密钥即加密区密钥,用来加密指定加密区内所有文件的密钥,二级密钥包含8个部分:密钥名、密钥长度、密钥、所采用的加密算法、生成时间、当前密钥版本号、密钥描述信息以及用户自定义属性,二级密钥由散列化后的密钥库口令加密,并以文件等方式存储在密钥库中。
当某空文件目录被用户指定为加密区后,它会与用户所指定的二级密钥绑定,该密钥即成为该目录的加密区密钥,其密钥名存储在该目录的扩展属性中。二级密钥可以更新,在二级密钥更新后,KMS采用新版本密钥对加密区内新文件的密钥进行加密。注意:旧文件的密钥仍以旧二级密钥加密。
3)三级密钥管理
三级密钥即文件密钥,用于加解密上传至加密区的文件。每个文件拥有独立的文件密钥,经二级密钥加密后,密态存储在NameNode文件系统的文件扩展属性中,与文件名的文件属性绑定。
文件的密钥由KMS随机生成,并由该文件所在加密区的二级密钥加密。NameNode将二级密钥名、版本号和密态的三级密钥存储在文件INode节点的扩展属性中,并与文件永久绑定。加解密文件时,NameNode将该文件所在加密区的二级密钥名、版本号和密态的文件密钥发送给客户端,客户端再将这三部分数据发送给KMS。KMS根据加密区密钥名和版本号查询存储在密钥库中的加密区密钥,然后对密态文件密钥进行解密,得到明文的文件密钥,并以HTTPS协议封装后发送给客户端,客户端收到文件密钥后即可对文件执行加解密操作。
3.2 二级密钥的快速存取
如上所述,客户端对文件加解密前,需等待KMS返回明文的文件密钥。而KMS在解密密态的文件密钥并将明文的文件密钥返回给客户端前,需要根据二级密钥名与版本号从密钥库中读取该文件所在加密区的二级密钥,因此二级密钥的读取速度是制约文件密钥的解密性能的关键因素之一。现有方案中二级密钥的元数据、不同密钥、相同密钥名的不同版本均散落在HashTable中,并使HashTable空间占用率高,导致需要对HashTable频繁扩容与复制,二级密钥的存取效率低下。针对上述问题,本文设计了更为便捷高效的二级密钥存取结构,以降低文件加解密时延。
3.2.1 二级密钥的数据结构
为了使密钥的组织不松散,本文设计了“密钥串”新方案,其数据结构如图2所示。首先,将同一密钥名对应的各版本密钥依版本号组织在ArrayList中(即ArrayList的下标为该密钥的版本号);然后,将ArrayList与该密钥的元数据节点组成一个KeyChain,这样同一密钥名对应的元数据信息和密钥信息均有序地组织在一起,通过密钥名即可获取该密钥相关的全部信息。不同密钥名对应的KeyChain以
生成或更新密钥时,在对应密钥名的ArrayList中顺序添加新生成的密钥,并更新元数据节点即可。查找密钥时,先由密钥名找到当前密钥名的KeyChain节点,再根据版本号直接读取ArrayList下标,获取对应版本的密钥,操作简捷、直接。
删除密钥时,不需要遍历同一密钥名的各个版本,只需将一个密钥的
3.2.2 二级密钥存取效率分析
以“密钥串”新方案组织内存中的二级密钥,可达到减少时间、降低空间、提升效率的效果,简析如下。
1)查询/删除效率提升,新增/更新效率稳定

图2 二级密钥数据结构
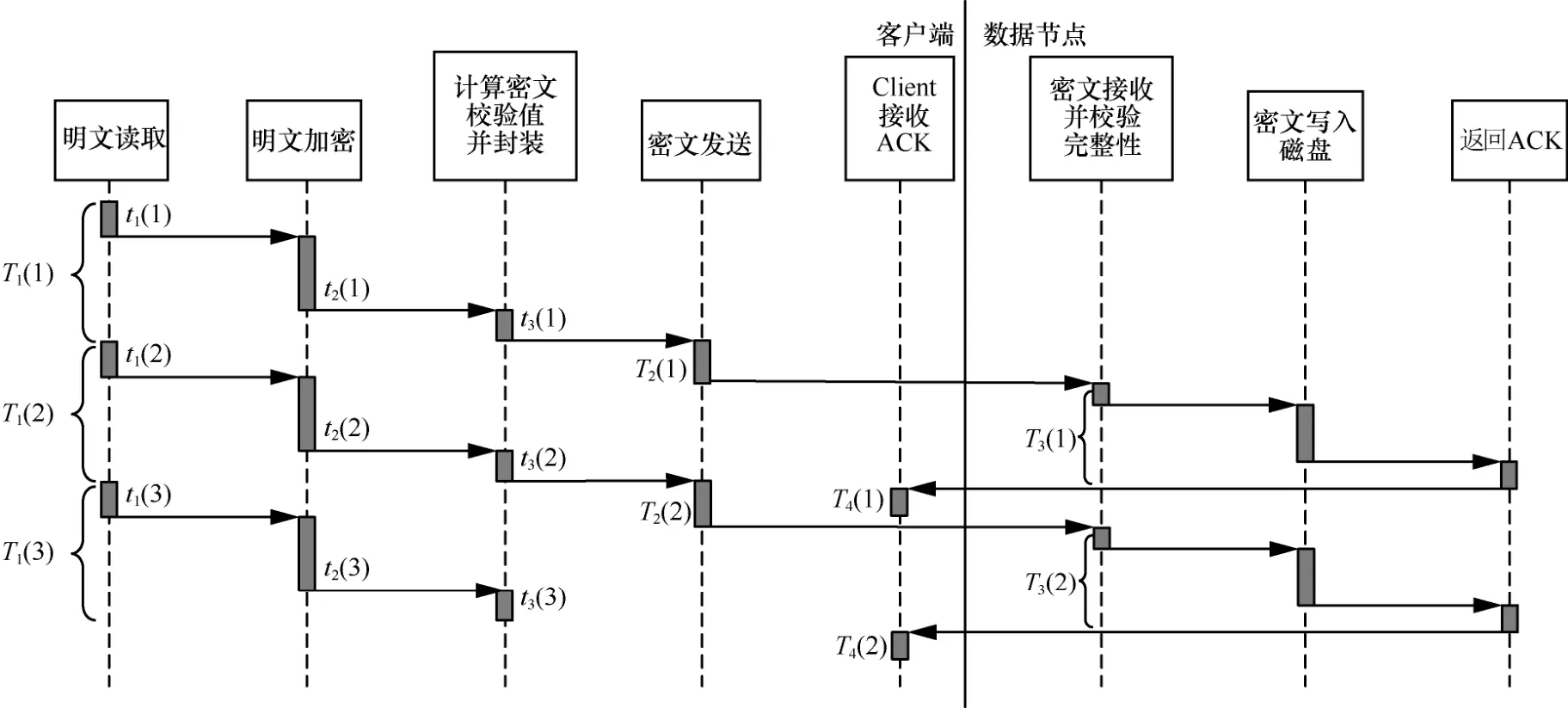
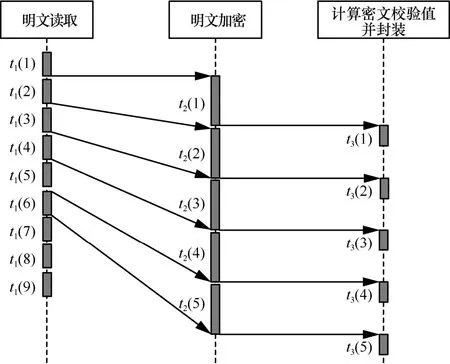
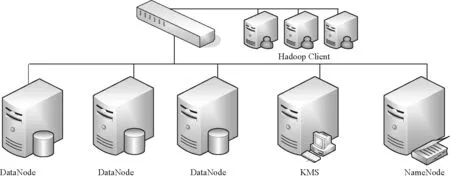
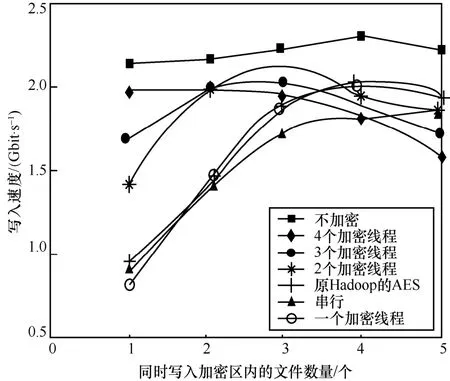
在密钥查询方面,原有Hadoop方案的查询需先经过密钥名或密钥别名的hash值定位,随后在同hash值的链表中依次匹配,效率为O(1)[+O(m)]。“密钥串”新方案则是先通过密钥名获取ArrayList,再使用版本号作为ArrayList的下标直接获取密钥,效率为O(1)[+O(n)]+O(1)。其中,O(m)和O(n)分别为2种结构的HashTable中发生冲突时遍历链表节点所需时间。在总密钥数量相同时,“密钥串”新方案的冲突概率远小于原有Hadoop方案,因此O(n) 在密钥删除方面,原有Hadoop方案需先获取待删除密钥的当前版本号n,随后逐个移除HashTable中的密钥节点,最后移除元数据节点,故删除效率为O(n+1)。“密钥串”新方案则是根据待删除的密钥名直接移除KeyChain节点,删除效率为O(1),与密钥版本数量无关。 在密钥增加方面,原有Hadoop方案直接向HashTable中添加2个键值对(一个密钥描述信息的 在密钥更新方面,更新流程为:首先,查询该密钥名的当前元数据信息,获取版本号并自加1,更新元数据;其次,添加新版本的密钥信息键值对。原有Hadoop方案获取元数据节点、更新元数据节点、新增密钥节点,效率均为O(1)[+O(m)];“密钥串”新方案在相同步骤下的效率均为O(1)[+O(n)]+O(1)。同理,在密钥名多、版本少的情况下,“密钥串”新方案的效率会退化为与原有Hadoop方案类似。 2)扩容次数减少,内存组织速度加快 采用HashTable作为存储加密区密钥的数据结构,在加密区密钥数量达到阈值时会触发扩容。HashTable的最小数组元素数量为n=11,阈值为数组长度的,即最初数组元素数量达到时即触发扩容,扩容后长度为n'=2n+1。当加密区密钥数量很大时,频繁触发HashTable扩容会耗费大量时间空间。 原有Hadoop方案中,新建一个二级密钥会在HashTable中添加2个元素,更新一次再添加一个元素;而新方案中,新建一个密钥只会在HashTable中添加一个元素,更新密钥不添加元素。因此,原有Hadoop方案中HashTable的元素数量会频繁到达阈值,触发扩容;而新方案的元素数量相对稳定,不会频繁触发扩容。 3)存储空间降低 输出至文件存储时,不再采用Java自身的序列化机制,而是采用TLV(tag-length-value)格式紧凑输出。存储一个相同内容的密钥时,Java序列化将输出2.48 KB大小,而TLV格式的输出仅需1.64 KB,节省的存储空间。 如图3所示,当前,Hadoop发行版的写入文件过程包括4个阶段。1)客户端准备文件数据阶段。客户端从数据源中读取数据,将该数据切分成多个固定长度的数据分组,计算校验值,并将数据分组和校验值添加至发送队列,消耗时间为T1。当发送队列已满时,该阶段会进入阻塞状态直到发送队列有空闲位置。2)客户端从发送队列中获取数据分组,将其通过网络传输给数据节点DataNode,并添加该数据分组至待确认队列,消耗时间为T2。3)DataNode接收到数据分组后,校验数据完整性,检查后将数据写入文件块中,并向客户端返回确认信息ACK,消耗时间为T3。4)客户端收到DataNode返回的确认信息后,从待确认队列中删除数据分组,消耗时间为T4。在需要发送多数据的情况下,这4个阶段并发执行,但每阶段内部的执行是串行的,每个阶段各由一个线程完成。 特别地,当需要向加密区写入文件时,需要在客户端对文件进行加密,其加密过程在上述第一阶段完成,即客户端待发送数据分组为密文。具体地,第一阶段可细化为3个步骤。步骤1,从明文数据源(例如客户端的明文文件)中获取明文,消耗时间为t1;步骤2,将明文加密为密文,消耗时间为t2;步骤3,将密文打包为固定长度的数据分组,并计算校验和,添加至发送队列,消耗时间为t3。当前,Hadoop版本存在如下问题使加解密效率低:1)这3个步骤串行执行,不能并发执行,存在加密空闲期,导致资源利用不充分;2)同步骤1和步骤3相比,步骤2耗时较长,即使这3个步骤并发执行,也会使步骤1和步骤3需要等待步骤2完成,导致长时间阻塞。针对上述问题,本文提出了多线程流水线式并发加解密方案。 3.3.1 文件加密并发调度 为了解决加密空闲导致的低效率问题,必须尽可能确保加密过程不间断。为此,本文提出基于流水线的并发加密方案,如图4所示。 每条流水线至少包括3个线程:明文读取线程、加密线程和密文处理线程。其中,明文读取线程从明文数据源中读取固定长度的明文,将其写入明文缓冲队列;加密线程从明文缓冲队列中读取固定长度的明文进行加密,将得到的密文写入密文缓冲队列,在实际中可设置多个加密该线程(具体见3.3.2节);密文处理线程从密文缓冲队列中取出密文计算校验和,封装并添加至发送队列。从图4可以看出,该流水线式调度方案中加密过程几乎不间断,加密资源被充分利用。 在Hadoop原加密流程的第一阶段中,第k个数据段从明文数据源到进入发送队列总耗时T1(k)为 图3 当前Hadoop发行版的写入文件过程 图4 基于流水线的并发加密方案 若明文被切分为m个数据段,并且加密速度比文件读写速度慢,那么发送队列不会满,即第一阶段不会进入阻塞状态,因此第一阶段的总耗时为 由于加密时间较长,因此原始加密方式和流水线式加密方式具有如下特征 在式(3)情况下,流水线加密方式的第一阶段总耗时为 由式(2)和式(4)可以得到 由于时间始终为正数,因此有 即流水线式的加密过程能缩短明文从数据源读取经过加密后被写入密文缓冲队列的总时间。 此外,式(5)可以说明流水线方案比原Hadoop方案缩短的时间包含2个部分,一是明文读取线程与加密线程的并发时间,二是加密线程与密文处理线程的并发时间,这两部分分别对应式(5)最右侧表达式中的第一项与第二项。 3.3.2 数据分段加密与同步 为了解决明文加密时间长问题,本文在上述流水线中设置多个加密线程,每个加密线程均可从明文缓冲队列里取明文数据,并将加密得到的密文放入密文缓冲队列,实现多段明文数据的并发加密,从而缩短整个明文的加密时间。 在分段加密中每个加密线程加密时间不相同,可能导致同步问题。例如,加密线程A1和A2顺序取明文段P1和P2,并独立加密,若A2对P2的加密时间小于A1对P1的加密时间,则可能导致P2的密文先写入密文缓冲队列,从而导致乱序密文。为此,本文提出基于密文排序的多加密线程密文同步方案。 该方案为每一个明文段/密文段依照其先后顺序依次分配唯一的递增整数序列号seq,相邻数据段序列号之差为1。为了对密文进行重组排序,采用临时链表tmpList来按照seq序列号顺序存储密文段。当密文缓冲队列接收到来自临时链表中序列号为n的密文段后,通过设置与临时链表共享的等待序列号ackSeq为n+1来告知临时链表:下一个需要发送的密文段序列号为n+1;当临时链表中第一个密文段序列号为ackSeq时,它将该密文段发送给密文缓冲队列,并从临时链表中移除。 图5给出了一个例子,在该例中,3个加密线程(记为encrypt1、encrypt2和encrypt3)分别加密第6、4、8段明文(即encrypt1=6,encrypt2=4,encrypt3=8)。临时链表tmpList中按序存储第5、7段密文,记为tmpList={5,7}。密文缓冲队列中已有密文2、3,正在等待第4段密文的写入,记为outQueue={2,3},ackSeq=4。图5的编号①~⑩为第4段明文与第8段明文先后加密完成时本文算法所执行的10个步骤。 步骤1加密线程2加密完第4段明文后,将第4段密文按序插入临时链表中,此时tmpList={4,5,7}。 步骤2临时链表判断首元素序列号4是否与ackSeq相等,判断结果为“是”,然后将第4段密文从临时链表中移除,添加至密文缓冲队列中,此时tmpList={5,7},outQueue={2,3,4}。 步骤3密文缓冲队列将等待序列号ackSeq增加1,此时ackSeq=5。 图5 并发加密的密文重排序算法 步骤4临时链表判断首元素序列号5是否与ackSeq相等,判断结果为“是”,然后将第5段密文从临时链表中移除,添加至密文缓冲队列中,此时tmpList={7},outQueue={2,3,4,5}。 步骤5密文缓冲队列将等待序列号ackSeq增加1,此时ackSeq=6。 步骤6临时链表判断首元素序列号7是否与ackSeq相等,判断结果为“否”,不能向密文缓冲队列中写入第7段密文。 步骤7加密线程2从明文缓冲队列中读取明文段9并开始加密,此时encrypt2=9。 步骤8加密线程3加密完第8段明文后,将第8段密文按序插入临时链表中,此时tmpList={7,8}。 步骤9临时链表判断首元素序列号7是否与ackSeq相等,判断结果为“否”,不能向密文缓冲队列中写入第7段密文。 步骤10加密线程3从明文缓冲队列中读取明文段10并开始加密,此时encrypt3=10。 从上述例子可看出,尽管明文段4、5、7、8的加密不是按序完成的,但它们的密文会在临时链表内排序重组,从而确保将原本乱序的4个密文段顺序写入密文缓冲队列,所以本文方案能够有效地解决多加密线程密文同步问题。 基于上述分析,本文给出多线程流水线式并发加解密算法流程,该流程包括3个部分的算法:明文读取线程算法、加密线程算法、密文处理线程算法,如算法1~算法3所示。其中,inQ表示明文缓冲队列,outQ表示密文缓冲队列,list表示临时链表,len表示数据源dataSource内的待加密明文长度,seq表示下一个明文段应分配的序列号,ack表示密文缓冲队列正在等待的密文段序列号,buffSize为每个明文段/密文段的长度,stop表示明文是否读取完毕。 基于本文架构在局域网中搭建实验环境,实验环境分别包括一个NameNode管理节点node 0、3个DataNode数据节点node1~node3、一个KMS服务器节点node4,以及若干Client客户端节点模拟用户访问。根据Hadoop大数据平台架构,NameNode节点node0存储文件密钥节点,并管理3个DataNode数据节点,node2和node3为node1的备份节点,KMS服务器节点node 4管理和存储一级密钥(密钥库口令)和二级密钥。拓扑如图6所示。 4.2.1 二级密钥的存取效率性能 本文所提密钥串管理方案的关键在于存储结构的变化。为避免JDK(Java SE development kit)调用带来的影响,本次实验共设置6组对比实验。1)使用Hadoop原有方案的结构,在本地实现HashTable和3DES加密算法。2)使用本文的“密钥串”新方案的数据结构,在本地实现HashTable和3DES加密算法。3)使用本文的“密钥串”新方案的数据结构,在本地实现HashTable和SM4加密算法,数据存储过程无序列化。4)仅实现本文“密钥串”新方案的数据结构,不实现加密过程,作为空白对比。5)仅实现本文的“密钥串”新方案的数据结构,不实现加密过程,数据存储过程无序列化,作为空白对比。6)仅实现本文“密钥串”新方案的数据结构,不实现加密过程,数据存储过程无序列化,且删除过程简化,作为空白对比。 密钥管理包括密钥的生成、更新和查询等,Hadoop平台的二级密钥均在KMS本地使用,不涉及分发的问题。因此依次测试各类结构在以下4个生命周期的密钥管理中所需的时间:创建n个密钥,每个密钥更新100个版本的密钥,随机查找n个密钥,删除所有密钥。 图6 所用实验部署环境 因每一次的操作耗时在纳秒级,小量测试不足以区分各方案之间的优劣。本文采用逐级递增的大数据量进行测试,即n的范围为1~200(以10为单位递增),以全部运算之后的总时长进行比较。 实验结果如图7所示。由图7可以得出多种方案中密钥创建、更新、查询、删除的效率对比。图7的共有特点是所有不加密的方案比同结构的加密方案效率高,所有不使用序列化的方案比使用序列化的方案效率高,与已知常识一致。 在密钥创建方面,“密钥串”新方案比原有Hadoop方案速度快,使用无序列化的SM4加密方案比3DES加密方案速度快。在密钥更新方面,当前为少密钥名、多版本号的情况,“密钥串”新方案比原有Hadoop方案速度快,使用无序列化的SM4加密方案几乎可与序列化的无加密方案速度持平。在密钥查询方面,“密钥串”新方案比原有Hadoop方案速度快,可以提升Hadoop密钥使用过程中的查询效率。在密钥删除方面,只有第6组实验优化了删除流程,只需按密钥名删除整个节点、不需要逐个删除密钥,效率明显优于其他5组实验。与3.2.2节效率分析一致。 4.2.2 多线程流水线式并发加解密 图7 多种方案的密钥操作效率对比 本文所提出的流水线式并发加解密方案中,提高加解密速度的关键因素在于两点:一是串行加解密改为流水线式加解密,将明文读取、密文处理与加解密3个步骤并发执行,从而缩短明文从数据源中被读出经过加密并打包添加至发送队列的总时间;二是增加加解密线程的个数,使不同的明文段能够同时加密,从而缩短整个明文的加密时间。 根据上述两点因素,本实验测试了不加密、串行加密、流水线式加密、2线程并发加密、3线程并发加密以及4线程并发加密共6种条件下的文件写入速度。由于同一时间内,用户可能会同时向加密区内写入多个文件,因此实验在上述各条件下分别测定了同时向加密区内写入1~5个文件所花费的时间,根据写入文件的总大小计算得出文件的写入速度。实验结果如图8所示,在明文数据段大小为8 KB下测得的写入速度。 图8 文件分段大小为8 KB时的加密写入速度 从图8中可以看出,不加密时文件写入速度基本稳定在2.2 Gbit/s左右,而HDFS原本的串行加密方式在同时写入一个文件时,速度只有0.8 Gbit/s,与不加密时相比性能大打折扣。随着同时写入文件数的增大时,各文件的并发加密使加密资源逐渐被充分利用,从而写入速度逐渐提升。 采用流水线式加密方案后,文件写入速度相对于串行加密方式有小幅提升,与前面的分析一致,这部分速度的提升来自式(5)所计算的时间差。 采用多线程并发加解密方案后,可以看出,随着加密线程数量的增多,文件写入速度大幅提升。当采用4个线程进行并发加密时,即使同时只写入一个文件,写入速度也几乎接近不加密的写入速度。 与原有Hadoop方案的AES算法相比,替换SM4算法在串行方案中并不占优,而在流水线式加密方案和多线程并发加解密方案中,快于原有Hadoop方案的AES算法。 由此可见,本文的多线程并发加解密方案确实能够高效地完成文件加密,能够使用户在通过文件加密的方式保障安全性的同时,不损失文件读写的效率。 本文针对Hadoop平台密钥管理复杂、数据加解密性能低的问题,提出一种面向Hadoop平台的高效密钥管理方案,该方案通过Hadoop平台三层密钥管理体系,结合国产商用系列密码算法,实现多级密钥系统管理与保护,优化二级密钥组织方式提高密钥的存取效率,流水线作业的异步调度加密资源,优化文件加密的流程,提升加密性能,并通过密文重排机制,恢复异步加密数据的原有顺序。模拟实验结果表明,该方案可以有效提升Hadoop静态加密速度,同时减少空间占用。3.3 三级密钥异步调度加解密文件
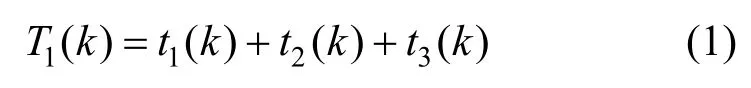
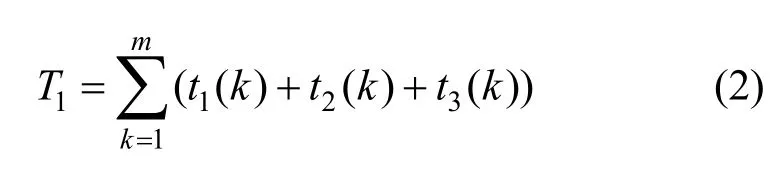
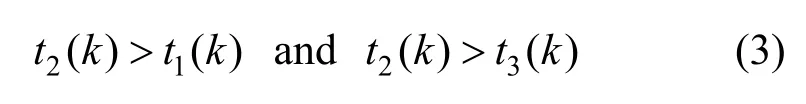






4 实验分析
4.1 实验环境
4.2 效果分析

5 结束语
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
网络安全技术与应用(2020年11期)2020-11-14
沈阳工业大学学报(2020年2期)2020-04-11
民间故事选刊·上(2018年1期)2018-01-02
软件导刊(2017年4期)2017-06-20
网络空间安全(2016年3期)2016-06-15
小小说月刊·下半月(2016年6期)2016-05-14
故事会(2015年19期)2015-05-14
软件工程(2014年11期)2014-11-15
