
基于混合方法的SSL VPN加密流量识别研究
2019-04-01 12:44:04封化民崔明辉孙曦音
计算机应用与软件 2019年2期
王 琳 封化民, 刘 飚 崔明辉 赵 会 孙曦音
1(西安电子科技大学 陕西 西安 710071)2(北京电子科技学院 北京 100070)
0 引 言
随着信息技术的飞速发展,互联网规模快速扩张,各种类型的网络服务不断增多,信息的安全性问题也受到越来越多的关注。为了保障数据传输的安全性,越来越多的流量都在加密后进行传输,这在保障信息安全的同时,也给流量的审计带来了挑战。
流量识别是网络监管的重要组成部分,也是近些年来的热门研究方向。自“棱镜”监控项目曝光以后,全球的加密网络流量急剧增加。安全套接层SSL协议在流量加密传输的过程中得到广泛使用,SSL加密在打击非法信息窃取和黑客攻击,保护敏感数据等方面起着至关重要的作用。SSL VPN(基于安全套接层的虚拟专用网)也因其安全性和易用性在安全传输中得到广泛使用,但这也使得一些恶意流量有了可乘之机。
目前对于SSL VPN流量识别的研究还比较少,本文提出一种混合方法,通过两步来实现SSL VPN流量的识别。首先利用指纹识别的方法从网络流量中提取出SSL流,然后利用统计学习方法,根据时间相关的流特征,使用改进的RF算法,识别出其中的SSL VPN流量。
对于SSL流量的识别,目前常用的方法有基于机器学习的方法和基于指纹识别的方法,它们有其各自的优缺点。由于混合方法分两步实现,考虑到识别效率和准确率的因素,本文提出一种改进的“指纹识别”方法,通过匹配分组特定位置的字段信息来判断当前数据包是否使用SSL协议进行加密,进而判断当前流是否为SSL流。对于第二阶段的SSL VPN流量识别,本文提出两种基于遗传算法的改进RF算法,并与RF算法及其他机器学习方法进行了比较。实验结果表明,改进的RF算法有更好的识别效果。
1 相关研究
Paxson等[1]在20世纪90年代初就开始了基于分组大小和基于流的流量分类研究,其中一些统计特征,如:分组长度、分组到达时间间隔和流持续时间等,被认为对协议识别有较好的效果。后来,文献[2]仅使用流量的前几个分组统计数据,提高了流量识别的效率。此外,为了提高大规模、高速网络的分类效率,文献[3]提出了基于签名的流量识别方法。此方法缩短了流量分类的时间,但无法检测出未知的或手动创建的签名。
对于SSL加密流量,文献[4]在2010年对HTTPS加密流量进行了研究,使用SVM算法来区分WebMail流量和其他HTTPS流量,但没有更进一步地细分其他类型的流量。
文献[5]在2010年提出一种混合框架,结合签名和统计的方法,来实现SSL流量的分类。首先使用签名匹配的方法来识别出SSL流量,然后使用统计的方法(朴素贝叶斯方法)来判断SSL流的具体应用协议。
目前的流量识别研究中,大多是对某种协议流量的识别,而对于VPN流量识别的研究很少。文献[6]在2016年首次提出仅利用时间相关的流特征识别VPN流量,比较了KNN和C4.5两种算法的识别效果,并公开了实验所使用的数据集。
西佛罗里达大学的Bagui等[6]在文献[7]发布的数据集的基础上做了进一步的研究,比较了Logistic回归、SVM、朴素贝叶斯、KNN、随机森林(RF)和梯度提升树(GBT)六种方法的识别效果,并对算法参数进行了适当优化,对VPN流量实现了90%以上的识别率。
2 SSL加密流量识别
2.1 SSL握手协议
SSL位于传输层和应用层之间,是一种在主机之间提供安全通信的协议,保证了数据的可靠性传输[7]。SSL协议由握手协议、记录协议、更改密文协议和警报协议组成,如图1所示。
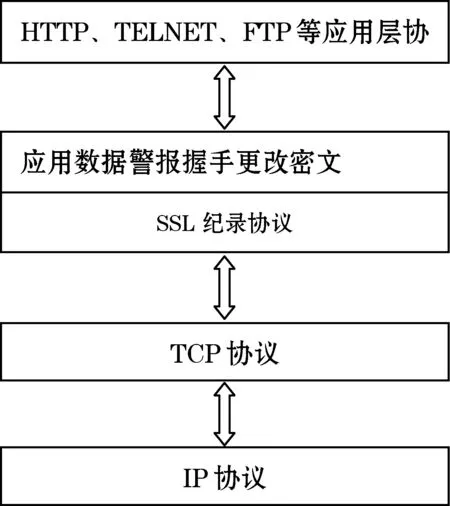
图1 SSL协议位置与组成
握手协议是SSL协议中十分重要的协议,通信双方通过握手来提供身份验证。客户端和服务器在此过程中确认所使用的密钥和算法,此外,还需协商双方的信息摘要算法、数据压缩算法等数据加密传输时需要用到的信息。握手协议完成后,双方开始数据的加密传输。握手协议的通信流程如图2所示。
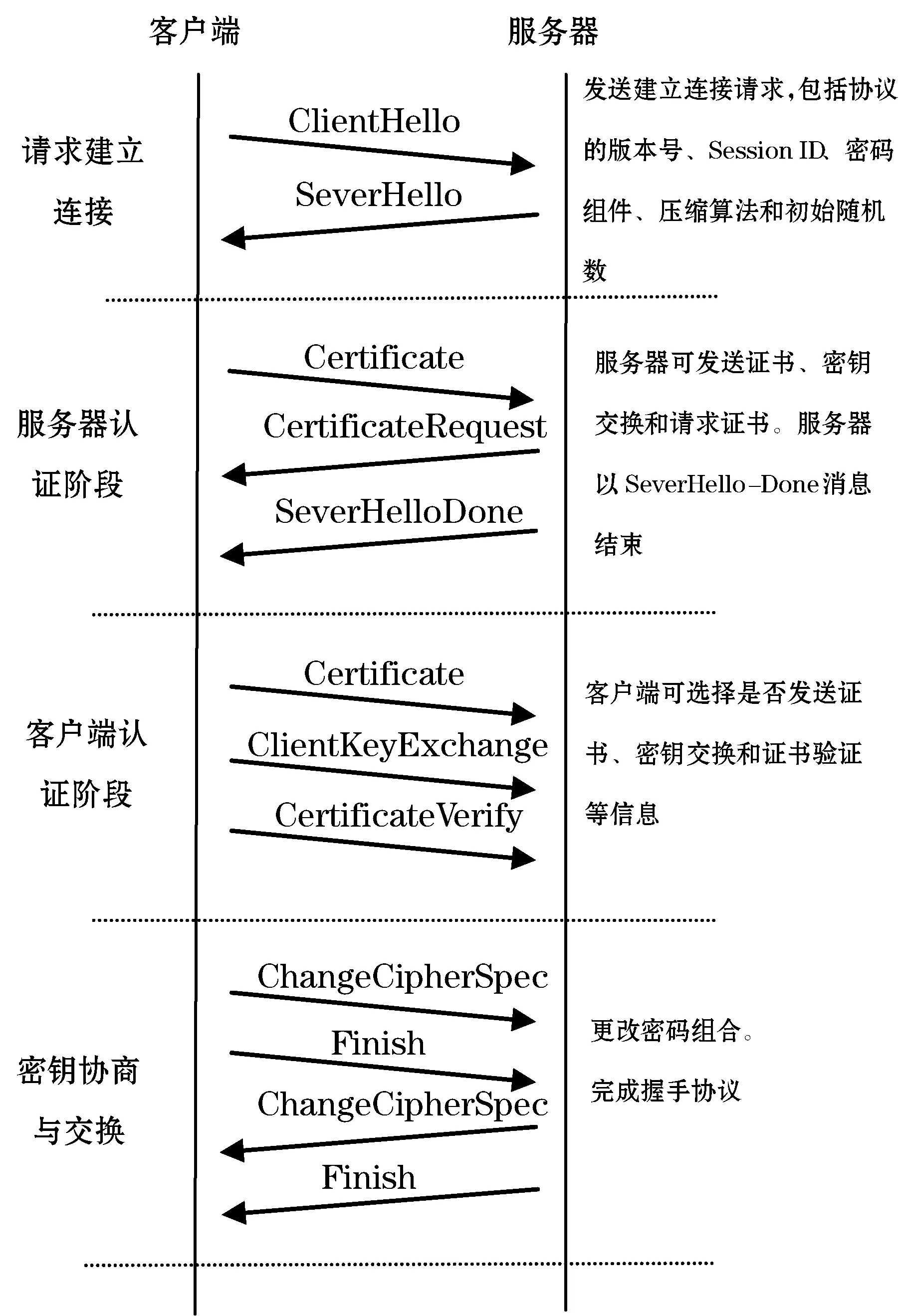
图2 SSL握手协议通信流程
(1) ClientHello消息。客户端发送此消息到服务器,包括客户端所支持的算法和初始随机数。
(2) ServerHello消息。服务器从可选的加密算法中选择一种作为通信使用的加密算法。
(3) ServerCertificate消息。ServerCertificate包含服务器标识和用于生成加密参数的随机数。
(4) CertificateRequest消息。可选消息,当服务器需要验证客户端的身份时可发送此消息。
(5) ServerHelloDone消息。这条消息在上面几条消息完成后发送,表明服务器在等候客户端的回应。客户端收到这条消息后便开始验证数字证书的合法性。
(6) ClientKeyExchange消息。此消息负责传输客户端生成的预主密钥。
(7) ChangeCipherSpec消息。通知服务器开始使用协商好的各项参数。
(8) Finish消息。这是第一条安全处理过的消息,包含了之前所有握手消息的验证码。
2.2 SSL握手协议报文结构
SSL握手协议的各类消息都有其特定的报文结构特征,下面对其进行介绍,主要包括ClientHello报文、SeverHello报文、Certificate报文、SeverHelloDone报文、ClientKeyExchange报文、ChangeCipherSpec报文。
2.2.1 ClientHello报文结构
根据RFC6101[9],ClientHello报文数据结构如表1所示。

表1 ClientHello报文结构
(1) ClientHello消息的TCP数据段第1个字节为0x16,表示当前数据包是HandShake消息报文,属于SSL握手协议的一部分。
(2) 第2、3两个字节表示SSL协议版本号,其中第2字节的值均为0x03,表2为SSL各个版本号对应的字节表示。

表2 SSL协议版本
(3) Length1占两个字节,表示剩余数据包的长度。
(4) 第6个字节为HandShake Type,0x01表示当前数据包为ClientHello消息。
(5) Length2占三个字节,表示其后剩余数据包的长度。
2.2.2 SeverHello报文结构
SeverHello报文数据结构如表3所示。

表3 SeverHello报文结构
(1) SeverHello报文第一个字节为0x16,表示当前数据包为握手协议的一部分。
(2) 与ClientHello对应的Type值不同,SeverHello的第6个字节为0x02,表示当前数据包为SeverHello消息。
2.2.3 Certificate报文结构
Certificate数据报文结构如表4所示。

表4 Certificate报文结构
(1) Certificate报文第一个字节为0x16,表示当前数据包为握手协议的一部分。
(2) Certificate的第6个字节为0x0b,表示当前数据包为Certificate消息。
2.2.4 SeverHelloDone报文结构
SeverHelloDone数据报文结构如表5所示。

表5 SeverHelloDone报文结构
(1) SeverHelloDone报文第一个字节为0x16,表示当前数据包为握手协议的一部分。
(2) ServerHelloDone的第6个字节为0x0e,表示当前数据包为SeverHelloDone消息。
2.2.5 ClientKeyExchange报文结构
ClientKeyExchange数据报文结构如表6所示。

表6 ClientKeyExchange报文结构
(1) ClientKeyExchange报文第一个字节为0x16,表示当前数据包为握手协议的一部分。
(2) ClientKeyExchange的第6个字节为0x10,对应ClientKeyExchange消息报文。
2.2.6 ChangeCipherSpec报文结构
ChangeCipherSpec数据报文结构如表7所示。

表7 ChangeCipherSpec报文结构
(1) 由SSL协议格式可知ChangeCipherSpec报文第一个字节为0x14,表示这是ChangeCipherSpec协议的一部分。
(2) 第6个字节为0x01,对应当前数据包为Change-CipherSpecMassge消息。
2.3 SSL流识别
2.2节介绍了SSL握手协议的通信过程以及报文结构。由于SSL握手协议是通过明文传输的,所以,可以通过解析捕获的PCAP文件获取数据包的头部信息,与上面几种不同类型消息的报文结构进行比对,从而可以识别出当前数据包是否为SSL握手协议的特定消息类型。对于一个完整的SSL会话,其通信过程一定包含以下几种类型的消息:ClientHello、SeverHello、SeverHelloDone、ClientKeyExchange、ChangeCipher-Spec。若某个数据流中没有检测到以上消息,则可以将其判断为非SSL流。若数据流检测到其中部分消息,则存在两种可能:一是SSL握手过程不完整,导致SSL连接建立失败,因此将这类数据流判断为非SSL流;二是这条数据流本身是SSL流,但抓包时由于网络延迟等各种原因,存在丢包的可能。若数据流中没有全部包含以上5种类型的消息,则将此流判断为非SSL流。反之,则判断为一个SSL流。具体识别流程如图3所示。
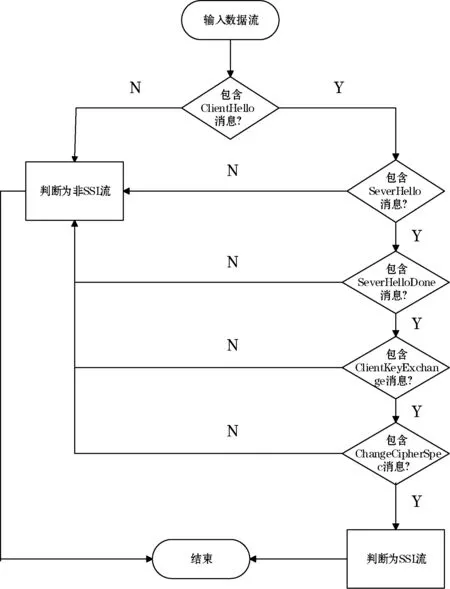
图3 SSL流识别流程图
在实际的实验环境中,通常会确定一个截断时间,把这个时间段内相同ip和端口号的数据包识别成一个流,而将超过截断时间的数据包分配到下一个流中。因此,可能出现如下情况,即一个流本身为SSL流,但并不是从其握手阶段开始截取的,而是从数据加密传输阶段开始截取的。这时,用上面的方法没有检测到SSL握手协议的消息,会产生漏识别的情况。为了解决这一问题,这里提出一种改进的指纹识别方法。
2.4 改进的指纹识别方法
使用SSL加密的数据包根据其消息类型的不同有不同的消息格式,但其前五个字节的格式是固定的,分别表示通信的阶段(握手(Handshake)、开始加密传输(ChangeCipherSpec)还是正常通信(Application)等)、SSL协议版本号和剩余包长度,如表8所示。

表8 SSL协议前五字节格式
其中ContentType和Version的字节表示与其对应的类型见表9和表10。

表9 ContentType对应信息

表10 Version Type对应信息
改进的指纹识别方法通过tcp数据段的头几个字节信息识别当前数据包是否使用SSL协议加密,包括ChangeCipherSpec、Alert、Handshake、Application几种类型的消息。这种方法扩大了SSL流识别的范围,不仅能够识别SSL握手阶段的流,同时也能识别数据传输阶段的SSL流。具体的识别流程如图4所示。

图4 改进的SSL流识别流程图
3 改进的RF算法实现VPN流量识别
3.1 RF算法介绍
与普通的机器学习方法相比,集成学习在实践中通常表现出更好的效果。集成学习利用多个学习器的协作来完成学习任务,有时又被称为多分类器系统、基于委员会的学习等[10]。
根据个体学习器的生成方式,目前的集成学习方法大致可分为两类:一是序列化方法,个体学习器之间存在强依赖关系,且必须以串行的方式产生;二是并行学习方法,个体学习器间不存在强依赖关系并且可以同时生成;其代表分别是Boosting和随机森林算法RF。
随机森林算法是由LeoBreiman(2001)提出的,它利用Bootstrap方法,从原始训练样本集N中有放回地重复随机抽取样本,生成k个新的训练样本集合(这k个新的训练样本集合可能存在部分重合),然后利用这些新的训练样本集构建随机森林。RF算法本质上是对决策树算法的改进,将多个决策树结合到一起来做决策。由于森林中的每棵树都由不同的训练样本集构建,因此也有着不同的分布。
随机森林算法的构建过程如下:
(1) 从原始训练集出发,使用Bootstraping方法进行有放回的随机抽样,选出m个样本,重复进行n次采样,生成n个训练集。
(2) 对于n个训练集,分别训练生成n个决策树模型。
(3) 对于单个决策树模型,假设训练样本特征的个数为N,那么每次分裂时根据信息增益/信息增益比/基尼指数选择最好的特征进行划分。
(4) 每棵树都按同样的方式分裂,直到该节点的所有训练样例不再可分。同时,在构建决策树的过程中不需要剪枝。
(5) 将构建好的多棵决策树组成随机森林,用投票的方式决定分类结果。
相比于传统的决策树算法,随机森林算法通过生成多棵树来避免过拟合的问题,为了使预测效果更好,应尽可能使生成的每棵树之间保持足够的差异性。因此,选择合适的参数十分重要,其中最为重要的两个参数分别是n_estimators和max_features,它们分别代表弱学习器的最大迭代次数和RF划分时考虑的最大特征数。
本文的原始特征集合使用Lashkari[6]在其论文中提出的时间相关的流特征,一共23个特征,具体信息如表11所示。
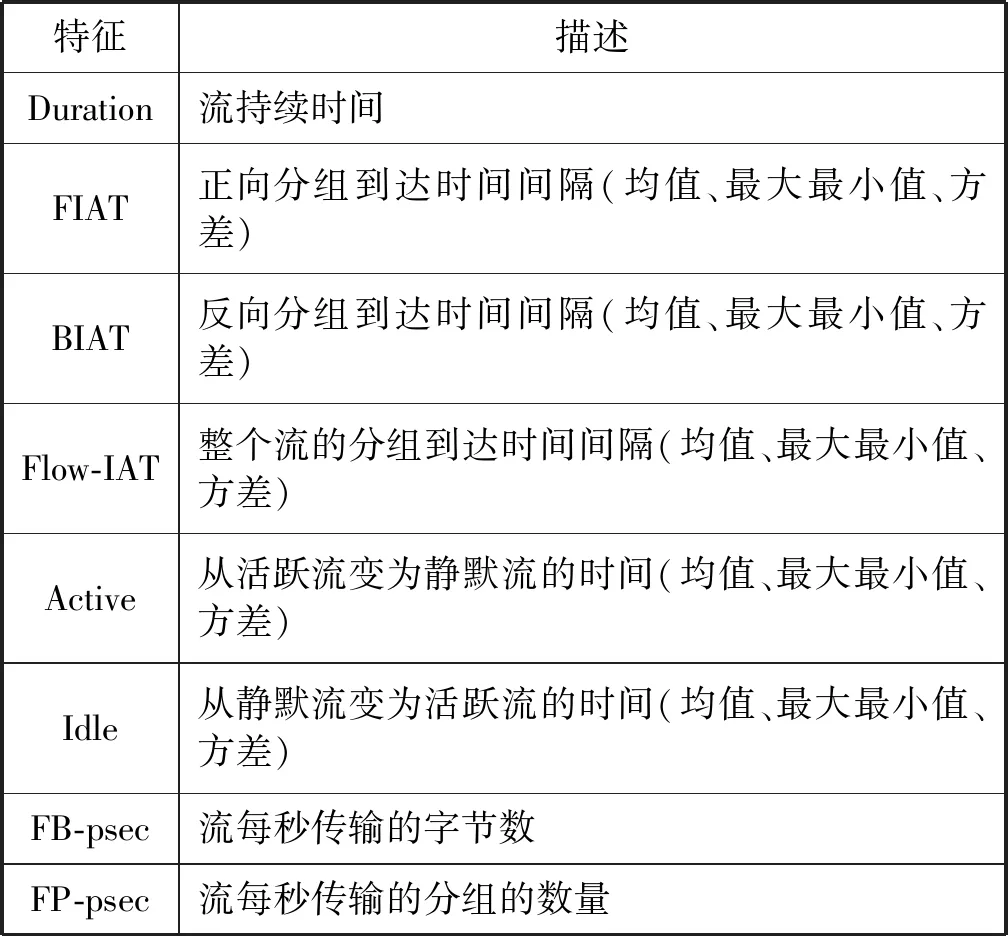
表11 识别SSL VPN流量使用的流特征
3.2 遗传算法介绍
遗传算法GA是根据遗传学知识和生物进化理论提出的一种模型,它通过多次迭代来实现特定目标的优化。遗传算法利用遗传、突变、杂交和自然选择的概念实现启发式搜索,最终得到最优解或准最优解,其流程图如图5所示。
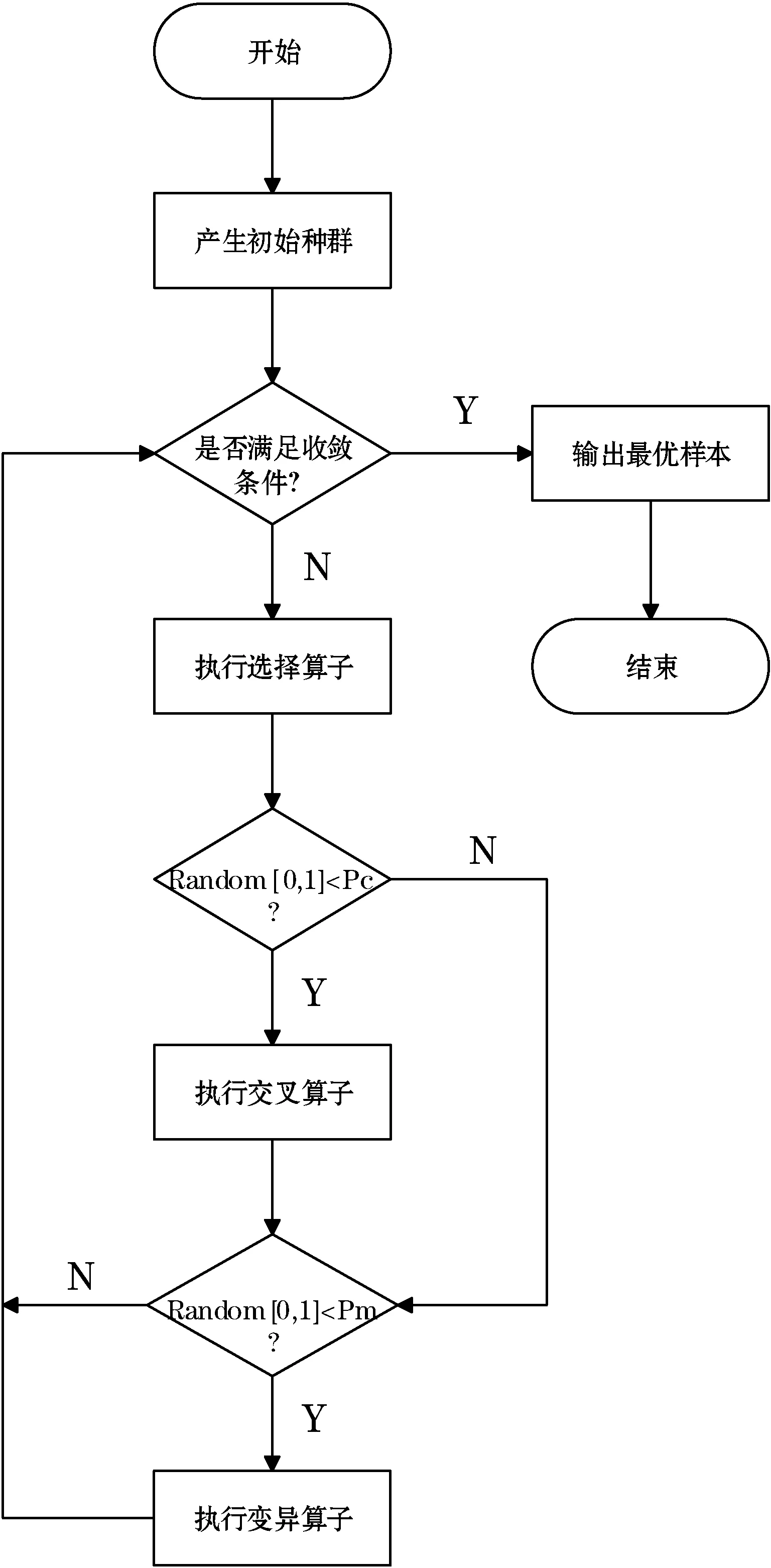
图5 遗传算法流程图
3.3 基于参数优化的改进RF算法
前面讲到,RF算法中有两个需要人为设定的重要参数,分别是max_features和n_estimators,其中max_features表示随机森林允许单个决策树使用特征的最大数量。max_features对于算法的性能有着重要的影响,当增加max_features时,通常可以提高模型的性能,因为我们在每个节点上都有更多的选择。然而,这并不完全正确,因为它降低了单个树的多样性,而这正是随机森林独特优势。但是,增加max_features会降低算法的速度。因此,有必要平衡和选择最佳max_features。n_estimators表示建立子树的数量,理论上来说,更多的子树可以使模型性能更好,使预测的结果更加稳定。但受限于机器的处理性能,较大的n_estimators会使代码变慢,大大降低模型的效率。因此,需要选择一个合适的n_estimators值,使得模型在满足性能要求的同时也具有较好的预测效果。
本文提出一种基于遗传算法改进的RF算法,通过遗传算法来实现RF算法中上面两个参数的优化。对于模型效果的评估,本文将流量识别的准确率与召回率作为评价标准,并将其作为遗传算法的适应度函数。
本文的特征集合里共有23个特征,为了比较不同max_features值的效果,需要选出当前条件下的最优特征子集。由于特征子集的选取存在的可能性较多,采用枚举的方式显然是不可取的。本文利用遗传算法,采用迭代的方式选出最佳的特征子集。将23个特征分别编号为1~23,染色体的长度为max_features的值,染色体每个位点上的取值规定为1~23之间的一个常数,且不能重复出现。适应度函数设置为模型的F值,对于某一个特征子集模型的F值计算,为了保证结果的准确性,这里计算10次取平均值作为最后的F值结果。表12为分类结果混淆矩阵,F值的计算公式如式(1)-式(3)所示:

查准率: (1)
算法构建如图6所示。

图6 PGA-RF算法构建
3.4 基于子分类器优化的改进RF算法
考虑到参数优化对分类器性能的影响有限,本文同时采用选择性集成方法与参数优化方法进行比较。选择性集成的概念由文献[11]提出,它利用某种策略从已构建的个体学习器集合中选出一部分构成新的集成。研究表明选择性集通过把预测性能不好的个体学习器去除,只保留少量优质的个体学习器,能够提高集成预测性能。此外,选择性集成还可以提高集成的泛化能力。
随机森林由决策树构成,因此每棵决策树的好坏在很大程度上影响着模型的效果。随机森林最大的特点是通过增加样本扰动和属性扰动使个体学习器之间产生差异性,进而使集成的性能增加[12]。选择优质的个体学习器使得子分类器有更高的准确率,但这也可能导致个体学习器之间的差异性减少,从而使得集成模型的效果下降。为了解决这一问题,本文在生成决策树时限制可用特征的数量,从而增大每棵树之间的差异性。同时,通过遗传算法的多次迭代,可以保证筛选得到的集成模型的子分类器之间有较好的差异性。
基于子分类器优化的改进RF算法主要流程如下,首先用训练集构建一定数量的决策树,组成原始的决策树集合。然后根据选择性集成的思路,从原始的决策树集合中筛选出性能较优的决策树,构成新的决策树集合。最后利用遗传算法迭代多次得到最优的随机森林模型,构建方法如图7所示。
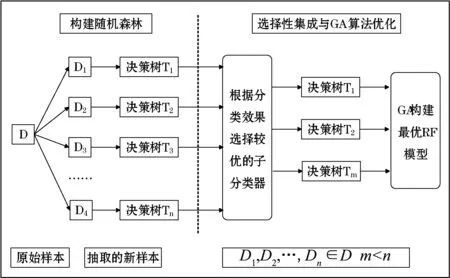
图7 CGA-RF算法构建
4 实验结果及分析
4.1 数据集
本文采用的数据集是Lashkari等[6]在2016年发布的VPN-nonVPN数据集,该实验室官网对数据集有详细介绍并且提供下载。为了产生一个有代表性的真实流量数据集,他们定义了一系列任务来保证数据的多样性和质量。他们创建了Alice和Bob两个账号来使用Skype、Facebook等服务,以产生相关流量。这些流量根据应用类型的不同共分为7个类别,每个类别又包括普通会话流量和VPN会话流量,因此共有14个类别的流量。
数据集的流量是通过wireshark和tcpdump捕获的,一共28 GB数据。对于VPN流量,实验使用Open-VPN进行SSL VPN连接。同时,对于文件传输流量,实验使用Filezilla作为客户端来产生SFTP和FTPS流量。不同类别的流量生成方式如表13所示。

表13 数据集中各类流量的生成信息
4.2 SSL流识别结果
对于SSL流的识别,本文使用改进的指纹识别方法除ICQ等少数流量无法识别外,其余应用的SSL流识别率均达到99%以上,结果如图8所示。

图8 SSL流识别结果
4.3 改进RF算法识别VPN流量实验结果
本文对比了KNN(K近邻)、LR(逻辑回归)、RF(随机森林)、PGA-RF(基于参数优化的改进RF算法)、CGA-RF(基于子分类器优化的改进RF算法)5种算法的识别效果,分别对比了Accuracy(准确率)、Precision(精确率)、Sensitivity(召回率)、Specificity(特异性)四个指标,结果如表15所示。

表15 SSL VPN流量识别结果
从实验结果可以看出,LR的准确率为68.6%,KNN的准确率达到83.5%,而RF的准确率达到90.3%,可见集成算法的效果要明显好于普通的机器学习算法。同时,基于参数优化的改进RF算法准确率为91.6%,基于子分类器优化的改进RF算法准确率为92.2%,其效果都要优于直接使用RF算法的效果,且CGA-RF的效果要优于PGA-RF,可见选择性集成对模型效果有所提升,实验结果对比如图9所示。
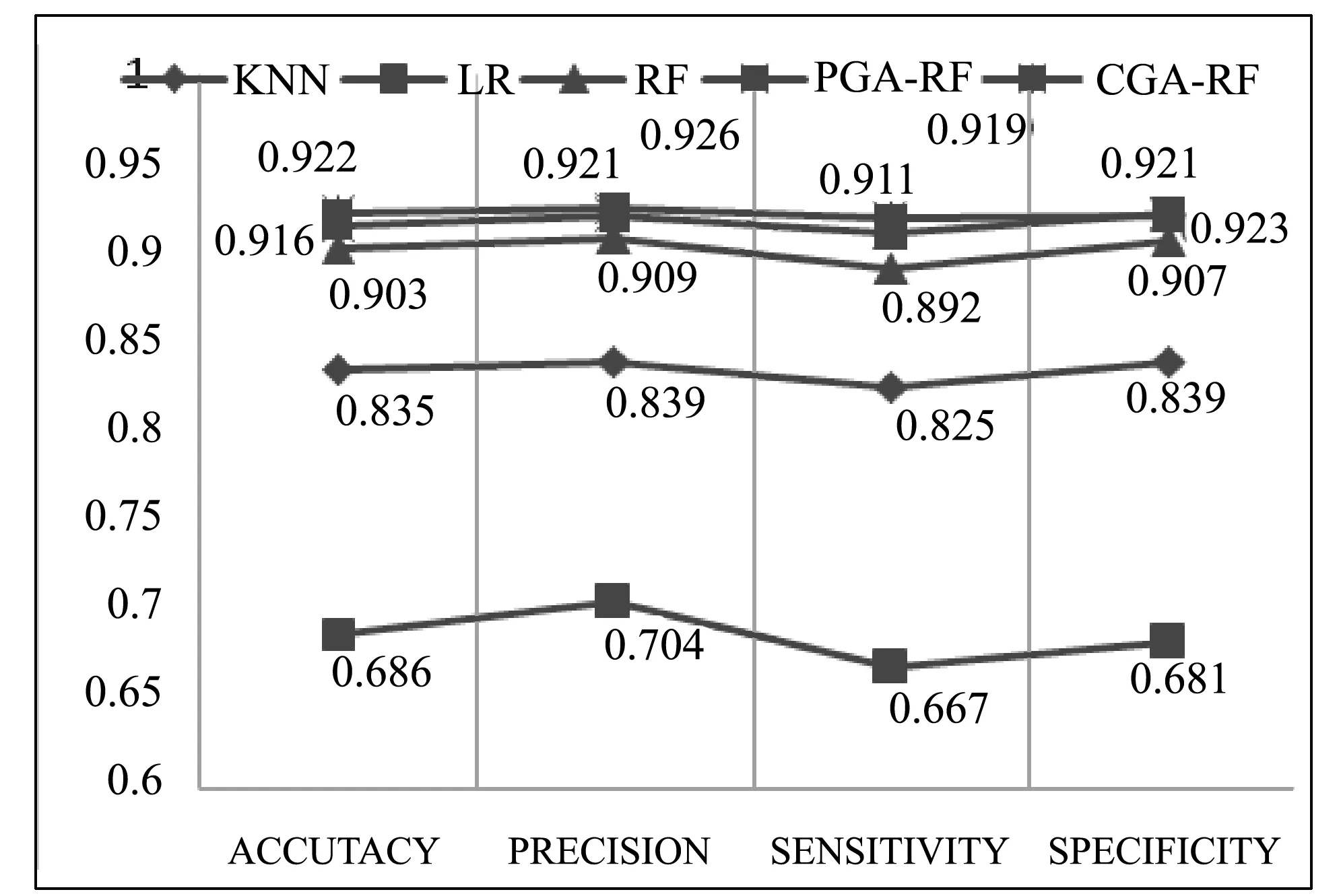
图9 SSL VPN识别结果
5 结 语
由于网络中的SSL加密流量越来越多,对于加密流量的监管也变得越来越重要。本文提出的混合方法,将指纹识别与机器学习方法相结合,实现了SSL VPN加密流量的识别。对于SSL流的识别,本文提出的改进的指纹识别方法对流漏识别的情况有所改善,使得识别效果更好。对于SSL VPN的识别,本文提出的改进RF算法也对准确率有所提升。实验结果表明,当前方法能够到达92.2%的准确率,实现了SSL VPN加密流量的有效识别。
猜你喜欢
汽车电器(2022年9期)2022-11-07 02:16:24
销售与市场(营销版)(2021年10期)2021-11-21 20:15:03
铁道通信信号(2020年4期)2020-09-21 09:15:24
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
中国外汇(2019年11期)2019-08-27 02:06:30
销售与市场(营销版)(2019年6期)2019-06-21 01:16:38
电子制作(2018年16期)2018-09-26 03:27:06
网络安全技术与应用(2017年9期)2017-09-20 09:54:28
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
铁道通信信号(2016年8期)2016-06-01 12:10:21
