
聚合CNN特征的遥感图像检索
2019-03-29 10:23:40葛芸江顺亮叶发茂姜昌龙陈英唐祎玲
自然资源遥感 2019年1期
葛芸, 江顺亮, 叶发茂, 姜昌龙, 陈英, 唐祎玲
(1.南昌大学信息工程学院,南昌 330031; 2.南昌航空大学软件学院,南昌 330063)
0 引言
随着遥感技术的发展,高分辨率遥感(high-resolution remote sensing,HRRS)图像数量急速增长,HRRS图像检索技术成为了研究热点和难点之一。基于内容的遥感图像检索(content-based remote sensing image retrieval, CBRSIR)是目前主流的检索技术,它包括特征提取和相似性度量2个部分,其中特征提取是图像检索中的关键技术。
早期CBRSIR主要通过提取图像的底层特征[1]进行检索,但是底层特征难以表达图像的高层语义信息,即存在严重的“语义鸿沟”问题[2-3]。为了缩小语义鸿沟,主要有以下3种方法: ①采用相关反馈机制[2],该方法依赖于反馈中标记的样本示例; ②融合多种特征[4],该方法可以有效结合不同特征的优点,从而更加全面地描述图像信息; ③聚合特征的方法,即在局部特征的基础上进一步构建抽象出的高一级特征,如视觉词袋(bag of visual words,BoVW)[5]是在尺度不变特征转换(scale-invariant feature transform,SIFT)特征的基础上通过K均值聚类得到的一种聚合特征,局部结构学习(local structure learning,LSL)[6]是在局部特征的基础上,结合图正则化得到的一种聚合特征。聚合特征能够减少冗余信息,有效降低特征维度,提高特征表达能力,从而缩小语义鸿沟。
传统的聚合特征都是建立在手工提取特征的基础上,但手工特征表达图像能力有限,且容易受到人为因素干扰。目前流行的深度卷积神经网络(convolutional neural network,CNN)能够自动学习图像的特征,降低了人为干扰,在图像分类、检索和目标识别中应用广泛[7-11],其中在大规模数据集(如ImageNet)上训练的CNN具有很强的泛化能力,可以有效迁移到其他小规模数据集。CNN迁移学习中,全连接层的输出值首先受到关注[7],之后表达图像局部信息的卷积层特征越来越受到重视[8],卷积层特征通常采用编码[8]和池化[9]的方法进一步构建为聚合特征。
在遥感图像检索领域,由于目前公开的遥感数据集规模较小,CNN的参数得不到充分训练,因此相关研究主要集中于将CNN迁移到HRRS图像并进行检索[12-14]。Napoletano[12]使用CNN中的全连接层特征进行检索; Zhou等[13]和Hu等[14]比较了CNN全连接层特征和基于卷积层输出值的聚合特征,并对CNN进行微调; Zhou等[13]还提出一种低维度特征(low dimensional CNN,LDCNN),但该特征的性能与数据集密切相关; Hu等[14]对卷积层特征提出了多尺度级联的方法,对全连接层特征采用了多小块均值池化的方法,但为了提取一幅图像的特征,这些方法需要多个输入来重新馈送给CNN,导致特征提取过程相对复杂。
上述文献对CNN的全连接层特征和卷积特征进行了较全面的研究,但对卷积特征采用的聚合方法均为编码方法,缺少对卷积层特征不同聚合方法的研究。因此本文根据HRRS图像的特点,研究CNN特征的聚合方法,并将其用于HRRS图像检索。首先,将CNN网络的参数迁移到HRRS图像,并针对不同尺寸的输入图像,提取表达图像局部信息的CNN特征; 然后,提出池化区域不相同的均值池化和BoVW这2种方法对CNN特征进行聚合,分别得到池化特征和BoVW特征,并对池化区域和视觉单词数目进行了研究; 最后,将这2种聚合特征用于遥感图像检索。
1 聚合CNN特征的图像检索
1.1 网络结构
在聚合CNN特征时,选用16层的VGG16网络[15]和22层的GoogLeNet网络[16]。VGG16通过扩展卷积层的数量增加了网络深度,GoogLeNet则通过使用inception modules机制,不仅增加了网络的深度,还增加了网络的广度。因此VGG16和GoogLeNet经过前面多个层次的抽象运算,后面的卷积层不仅仅获得更多的局部信息,并且具有更好的泛化能力。VGG16的CNN特征来自最后的卷积层(conv5-3)、激活函数层(relu5-3)和池化层(pool5)的输出值,GoogLeNet的CNN特征来自倒数第二层池化层(pool4)和最后2个inception层(incep5a和incep5b)的输出值。
输入图像尺寸不同时,输出值也不同,因此不同尺寸的输入图像对检索性能有较大影响。主要考虑2种尺寸: ①CNN默认的图像尺寸,即调整后的图像尺寸,VGG16和GoogLeNet的默认图像尺寸为224像素×224像素(文中涉及到图像尺寸的单位均为像素,为表达简洁,下文省略); ②数据集中的原图像尺寸,UC-Merced[5]和WHU-RS[17]为目前常用的2种HRRS数据集,256×256为UC-Merced中图像的原尺寸,比较接近默认尺寸,600×600为WHU-RS中图像的原尺寸,与默认尺寸相差较大,因此这两种数据集中图像的不同尺寸正好可以有效比较图像尺寸对检索性能的影响。表1和表2列出了不同输入图像尺寸下相应层次的输出值。以VGG16中pool5为例,在输入图像为224×224×3(3表示对应于R,G,B的3个通道)时,pool5的输出值为7×7×512,即输出值有512个通道,每个通道的特征图尺寸为7×7。

表1 不同尺寸输入图像下VGG16的输出值Tab.1 Outputs of VGG16 under different input image sizes
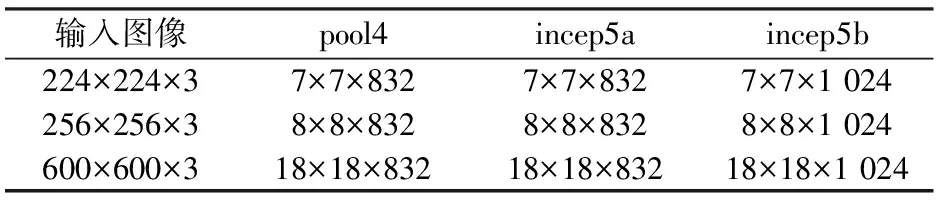
表2 不同尺寸输入图像下GoogLeNet的输出值Tab.2 Outputs of GoogLeNet under different input image sizes
1.2 特征提取
1.2.1 CNN特征
令图像I某个层次l的输出值为
fl=sl×sl×cl,
(1)
式中:fl为层次l的CNN特征;sl×sl为特征图的尺寸;cl为特征图的数目,即通道的数目。若将fl直接转化为特征向量,则维度过高,检索性能不佳,因此需要将其构建为聚合特征。
1.2.2 聚合特征
HRRS图像内容复杂,信息丰富,因此针对HRRS图像采用池化区域尺寸不同的均值池化方法,以便找到合适的池化区域来提取区分度更好的池化特征。特征编码采用经典的BoVW编码方法。
1)池化特征。目前常用的均值池化方法是令池化区域尺寸等于特征图尺寸[9],但针对HRRS图像,由于其内容丰富,直接令池化区域等于特征图区域,可能会丢失一些重要信息。因此提出池化区域尺寸不相同的均值池化方法,以获得效果更好的特征。
对于尺寸为sl×sl的图像I的l层特征图,令池化区域为ml×ml,记为rl; 令步幅为1,则池化区域的数目为(sl-ml+1)×(sl-ml+1),将其记为kl,则对于每个池化区域i,其池化特征为
(2)
式中ml×ml≤sl×sl,即池化区域小于或者等于特征图区域。当池化区域尺寸比特征图小时,可以保留更多的信息,更适合表达内容复杂的HRRS图像。根据公式(2)计算的pl的输出值为三维矩阵(sl-ml+1)×(sl-ml+1)×cl,将其转换为池化特征向量,记为Ap=[x1,x2,…,xD],其中D=(sl-ml+1)×(sl-ml+1)×cl,即池化特征的维度。
因此,本文提出的均值池化方法,图像仅需要输入到CNN中一次,通过在输出的特征图上设置较小的池化区域,可以获取图像的很多局部信息,从而提高图像的特征表达。
2)BoVW特征。传统的BoVW特征主要基于手工提取的局部特征进行聚合,而本文的BoVW特征则是基于表达图像局部信息的CNN特征进行聚合后的特征。
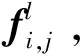
(3)
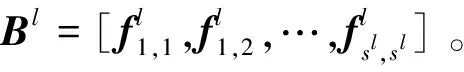
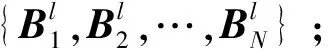
1.3 检索流程
图1以VGG16为例描述了整个检索流程,图中ci(i=1,2,3,4,5-1,5-2,5-3)表示卷积层。GoogLeNet的检索流程类似,只是提取的网络层次与VGG16不同。
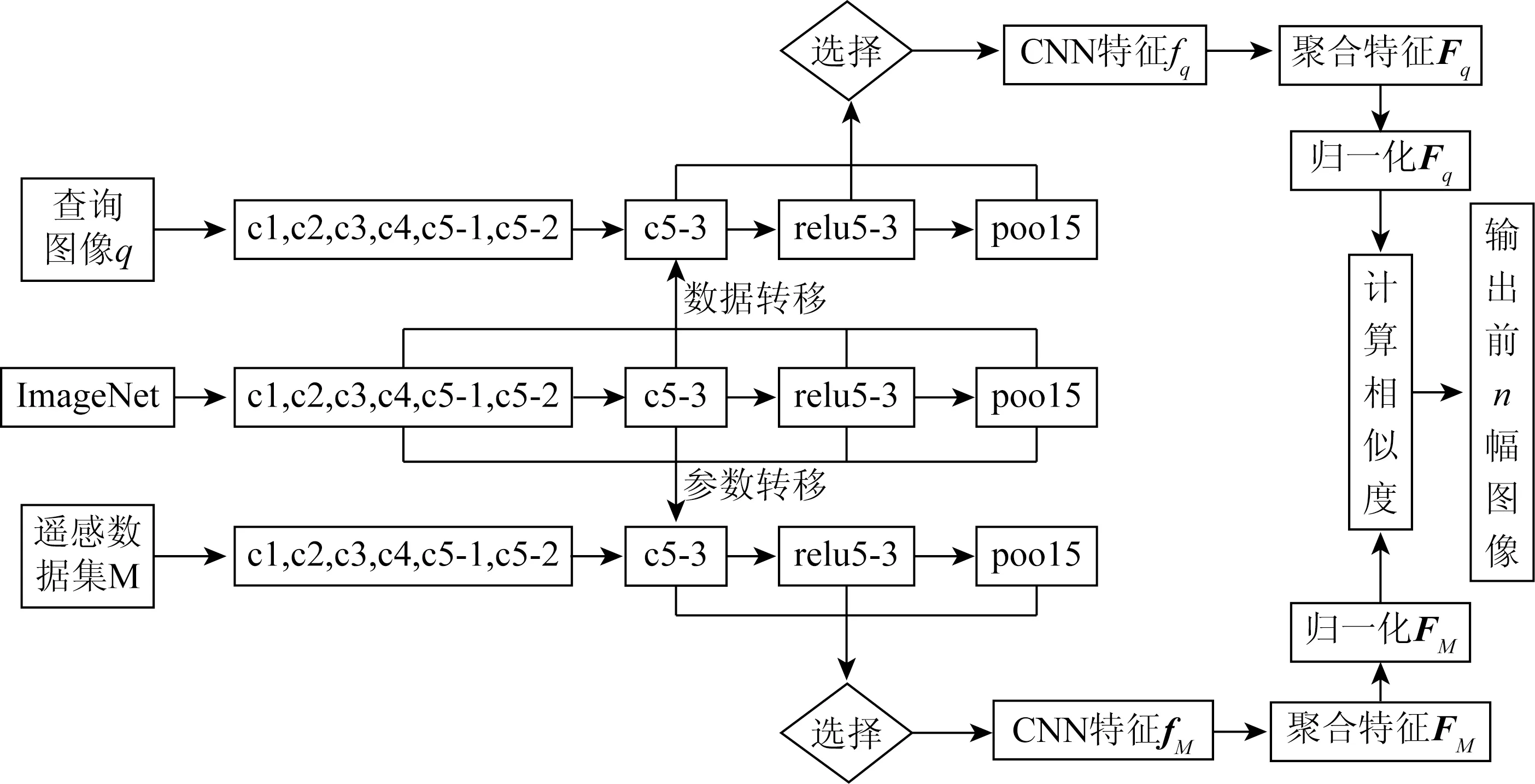
图1 VGG16检索流程Fig.1 Retrieval flow chart of VGG16
具体检索步骤如下:
1)将预训练CNN的参数分别迁移到HRRS数据集M和查询图像q。由于聚合特征是针对卷积层特征进行的,因此去除VGG16中的全连接层。将VGG16中卷积层的参数直接迁移到M和q。除了conv5-3外,其它卷积层省略了激活函数层和池化层。
2)提取M和q的CNN特征。将M中每幅图像和q分别输入到CNN,提取conv5-3、relu5-3和pool5层的输出值作为M中每幅图像和q的CNN特征。M中所有图像提取的CNN特征为fM=[f1,f2,…,fN],N为数据集M中图像的总数量,q的CNN特征记为fq。
3)提取M和q的聚合特征。M和q的CNN特征分别采用池化区域不相同的均值池化和BoVW方法,得到相应的池化特征和BoVW特征。为了简要表明,池化特征和BoVW特征用统一的方式标记:q的聚合特征记为Fq,M中的所有图像提取的聚合特征为FM=[A1,A2,…,AN]。
4)分别对FM和Fq进行归一化处理。由于图像各特征向量代表的物理意义往往不同,即使对同一个特征向量,其各个分量的取值范围也可能存在很大差异,因此需要对M和q的聚合特征进行归一化处理。对此,本文采用的是常用的L2归一化。
5)计算相似度,完成图像检索。根据归一化后的聚合特征,计算q和M中图像的相似度,并根据相似度返回最相似的n幅图像。
2 实验结果及分析
2.1 实验数据和评估标准
实验使用MatConvNet[18]提取网络模型VGG16和GoogLeNet。预训练VGG16和GoogLeNet的数据集采用ImageNet的子集ILSVRC2012,ILSVRC2012包含了1 000种图像分类,大约有130万幅训练图像、5万幅验证图像和10万幅测试图像。遥感数据集采用UC-Merced和WHU-RS。UC-Merced是从美国地质调查局收集的航空正射图像,总共21类场景,每类有100幅图像,图像大小为256×256; WHU-RS是从Google Earth下载的19类场景,每类包含50幅图像,图像大小为600×600。表3显示了这2个数据集的示例图像。

表3 UC-Merced和WHU-RS示例图像Tab.3 Sample images of UC-Merced and WHU-RS
实验的相似度采用常用的欧式距离; 评估标准采用了近几年来HRRS图像中使用普遍的平均归一化修改检索等级(average normalize modified retrieval rank, ANMRR),ANMRR取值越小,表明检索出来的相关图像越靠前,即检索性能越好。同时,实验中还比较了图像检索中重要的性能评价准则查准率—查全率曲线。
2.2 池化区域比较
采用均值池化提取聚合特征时,池化区域的尺寸影响网络检索性能。图2和图3分别比较了VGG16和GoogLeNet不同池化区域尺寸的检索结果。当输入图像尺寸为224×224时,VGG16的conv5-3和relu5-3的特征图尺寸为14×14,其他层次的特征图尺寸均为7×7。图中横坐标2~7表示池化区域尺寸从2×2到7×7。为了显示方便,对于图3的conv5-3和relu5-3来说,池化区域尺寸为横坐标值的2倍,即为4×4到14×14。
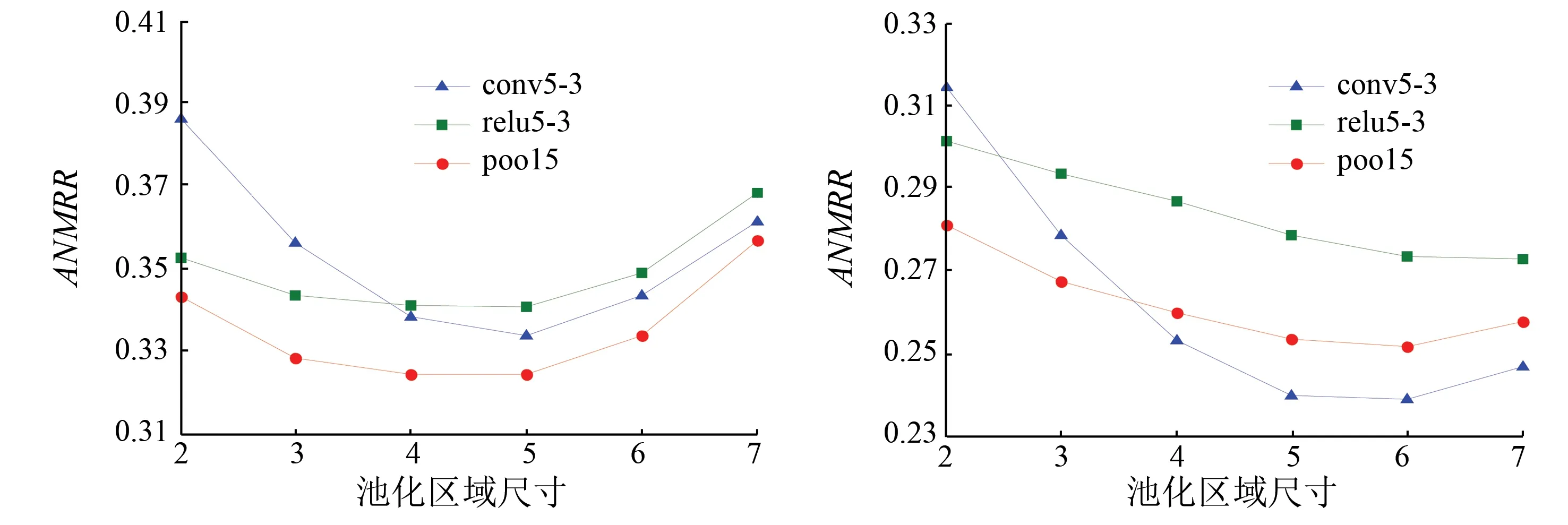
(a) UC-Merced(b) WHU-RS
图2VGG16中不同池化区域的ANMRR
Fig.2ANMRRwithdifferentpoolingregionsizesinVGG16
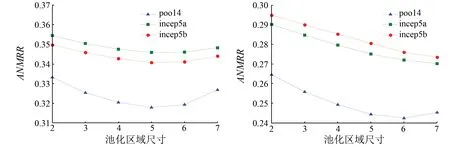
(a) UC-Merced(b) WHU-RS
图3GoogLeNet中不同池化区域的ANMRR
Fig.3ANMRRwithdifferentpoolingregionsizesinGoogLeNet
图2(a)显示,3类特征的ANMRR值都呈现先降后升的趋势,其中以conv5-3的ANMRR值下降最快,pool5的ANMRR值最小,即检索性能最好。图2(b)显示,随着池化区域的增大,relu5-3的ANMRR值呈下降趋势,而conv5-3和poo5的ANMRR值均先下降再上升。当池化区域较小时,pool5的ANMRR值最小; 随着池化区域增大,conv5-3的ANMRR值急速下降,并小于pool5的值。图3(a)中3类特征的最小ANMRR值位于接近特征图的位置,其中以pool4的结果最好。图3(b)中pool4的最小ANMRR值位于6×6的位置,而其他层次的最小值位于7×7的位置,3类特征中pool4的ANMRR值最优。
从图2和图3总体上来看,大多数特征的ANMRR值首先随着池化区域尺寸的增大而减小,到达最低值后,再随着池化区域尺寸的增大而上升。除了WHU-RS上的relu5-3,incep5a和incep5b外,其他特征在池化区域尺寸小于特征图尺寸时的检索性能最好。
2.3 不同尺寸输入图像的池化特征比较
表4和表5分别显示了UC-Merced和WHU-RS中2种输入图像尺寸(默认尺寸和原始尺寸)下池化特征的结果。为了和传统的均值池化方法比较,对于每种特征,列出了3种不同池化区域尺寸的结果: 前两个值是在池化区域尺寸从2×2增加到(s-1)l×(s-1)l(特征图尺寸为sl×sl)的结果中选择的2个最优值,第3个值为池化区域尺寸等于特征图尺寸的结果(即传统的均值池化方法)。表中粗体标注的值为该类特征中的最优结果,标注星号的值表示整体的最优结果。
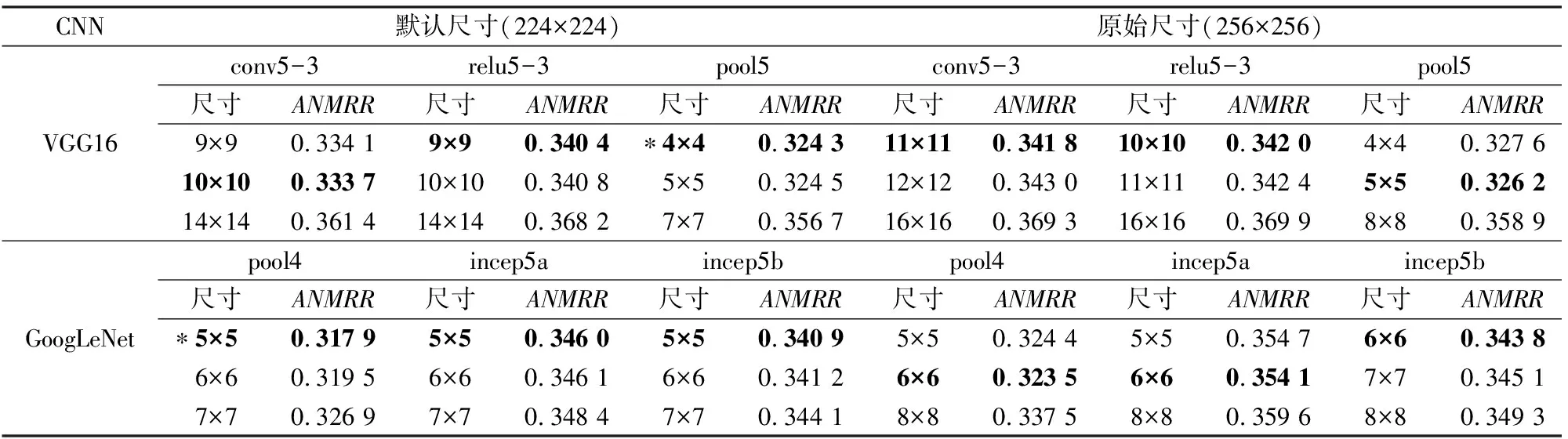
表4 UC-Merced不同池化特征的ANMRRTab.4 ANMRR with different pooling features on the UC-Merced
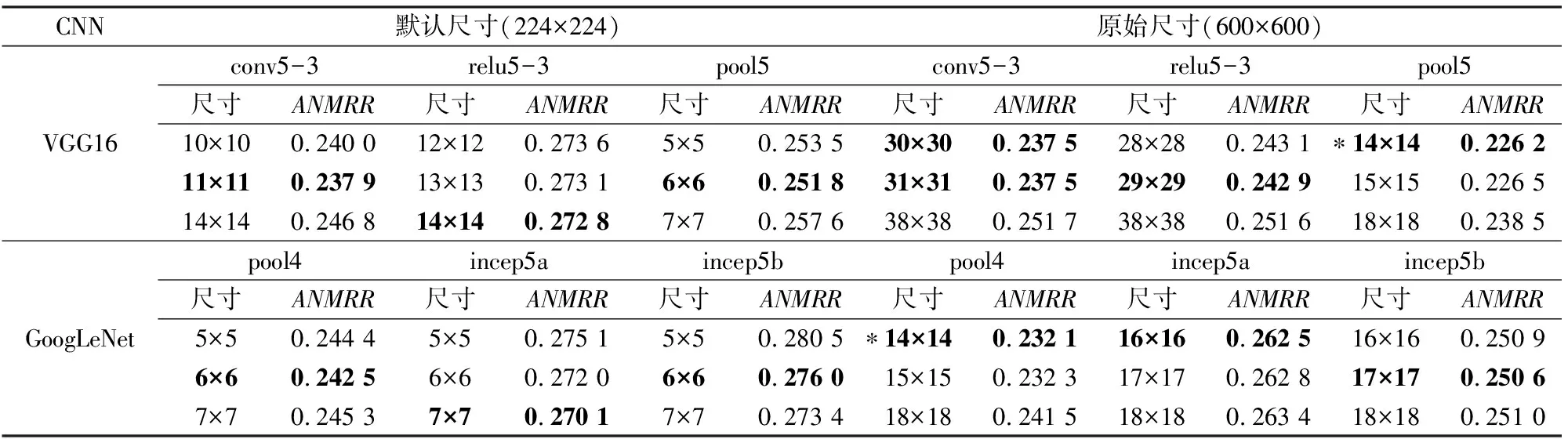
表5 WHU-RS不同池化特征的ANMRRTab.5 ANMRR with different pooling features on the WHU-RS
表4中,输入图像的默认尺寸和原始尺寸比较接近,因此检索结果也很接近,整体上256×256的检索结果比224×224的结果稍差些。这种结果可能是由于与相差不大的256×256相比,尺寸为224×224的图像更适合用于CNN中,以便输出区别性更强的特征。表5中输入图像的默认尺寸和原始尺寸相差较大,因此检索结果的差异性比较明显,600×600的结果比224×224的结果好,这是因为当图像尺寸从600×600调整到224×224时,图像丢失的信息比较多,直接导致检索性能下降。
对比2表可知,当输入图像尺寸增大时,最优池化区域的尺寸和特征图尺寸的差距也相应增大。因此简单地令池化区域尺寸等于特征图尺寸的方法容易丢失重要的特征信息,应该根据输入图像的尺寸及网络的层次选择合理的池化区域。根据实验结果,大多数特征的最优池化区域在特征图尺寸的60%~80%之间。
2.4 不同尺寸输入图像的BoVW特征比较
表6和表7显示了2种输入图像尺寸下BoVW特征的结果。为了比较视觉单词数目K对检索性能的影响,分别令K的取值为100,150,1 500,2 000和4 000。表中粗体标注的值为该类特征中的最优结果,标星号的值表示整体的最优结果。

表6 UC-Merced不同BoVW特征的ANMRRTab.6 ANMRR with different BoVW features on the UC-Merced
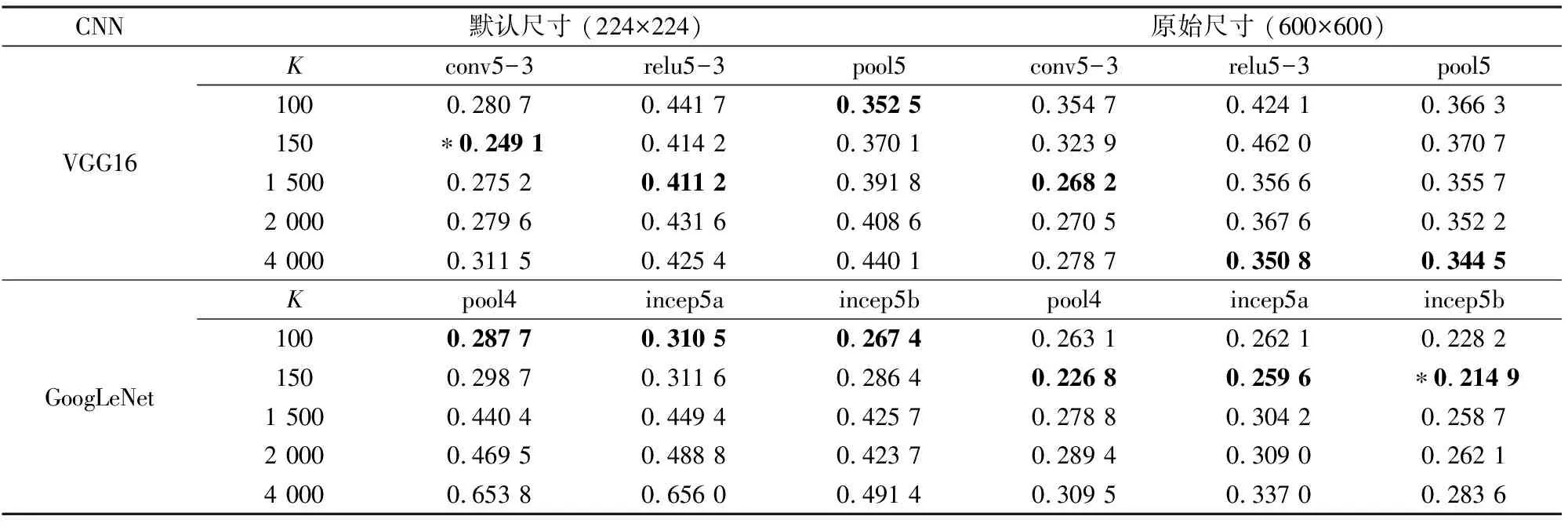
表7 WHU-RS不同BoVW特征的ANMRRTab.7 ANMRR with different BoVW features on the WHU-RS
表6中,大多数的BoVW特征在224×224尺寸下的结果优于256×256,VGG16中大多数特征的最优K值为100和150,GoogLeNet中不同特征的最优K值均为100。表7中,大多数的BoVW特征在600×600尺寸下的结果优于224×224,尤其以GoogLeNet中的结果表现更明显。当输入图像尺寸明显增大时,用于构建视觉单词的特征数目也相应增多,相应的最优K值也随之增大。例如,当输入图像尺寸为600×600时,relu5-3和pool5的最优K值增大到4 000,GoogLeNet所有层次的最优K值均增大到150。
因此在BoVW特征中,根据图像尺寸和特征图尺寸选择一个适宜的K值对提高检索结果有着重要作用。当输入图像尺寸显著增大时,K的最优取值也变大,其中以VGG16中K的最优取值变化尤为显著。
2.5 查准率—查全率曲线比较
前面实验结果中,大多数池化特征的检索结果优于BoVW特征。为了进一步比较这2种不同的聚合特征,在每种聚合特征中分别选择最优的特征(即为表4—7中标记为星号的特征)比较查准率—查全率曲线。查准率是指检索返回结果中相关图像数与返回图像数的比例,反映了检索精度; 查全率是指检索返回结果中相关图像数与所有相关图像总数的比值,反映了检索的全面性,与返回图像数目呈正相关。在查准率—查全率曲线中曲线比较高时,查准率和查全率都比较高,即检索性能比较好。
图4比较了不同特征的查准率—查全率曲线,VGG16和GoogLeNet的最优池化特征记为VGG16-P和GoogLeNet-P,VGG16和GoogLeNet的最优BoVW特征记为VGG16-B和GoogLeNet-B。UC-Merced返回图像数目最少为2,最多为2 100; WHU-RS返回图像数目最少为2,最多为950。在UC-Merced中,GoogLeNet-P的曲线位于最顶端,因此GoogLeNet-P的检索性能最优,其次是VGG16-P。当返回图像数目较少时,GoogLeNet-B的曲线高于VGG16-B的曲线,即GoogLeNet-B的检索性能优于VGG16-B; 当返回图像数目逐渐增多时,GoogLeNet-B的性能迅速下降并低于VGG16-B。在WHU-RS中,VGG16-B的曲线位于最低端,即检索性能最差,VGG16-P和GoogLeNet-P的结果比较接近。对于GoogLeNet-B,其检索性能随着返回图像数目的增大逐渐变好,甚至超过VGG16-P和GoogLeNet-P; 当返回图像数目增大到一个较大值时,GoogLeNet-B的性能又迅速下降。总体上来看,在2个数据集上,VGG16-P和GoogLeNet-P的检索性能优于VGG16-B和GoogLeNet-B。

(a) UC-Merced(b) WHU-RS
图4不同特征的查准率—查全率曲线
Fig.4Precision-recallcurvesfordifferentfeatures
2.6 与其他方法比较
表8比较了浅层特征和CNN特征的ANMRR值和维度。浅层特征选择了Aptoula提出的全局形态纹理特征[3]和基于手工特征SIFT构建的BoVW[5],以及近期提出的LSL[6]。CNN特征包含了文献[12—14]提出的特征,以及本文提出的VGG16-P,GoogLeNet-P,VGG16-B和GoogLeNet-B特征。由于大多数其它特征使用的数据集为UC-Merced,因此表8基于UC-Merced进行比较。

表8 不同特征的ANMRR和维度Tab.8 ANMRR and dimensions for different features
表8显示,CNN特征的结果普遍优于浅层特征,与BoVW相比,GoogLeNet-P和VGG16-P的值分别降低了27.31%和21.51%。
CNN特征中,VGGM-fc[12]和VGGM-fc-RF[12]分别是VGGM全连接层特征及加入了反馈信息的特征; VGG16-fc[13]是VGG16全连接层特征,VGGM-conv5-IFK[13]和VGG16-conv5-IFK[13]是对VGGM和VGG16的卷积层使用改进的费舍尔核(improved fisher kernel,IFK)编码的特征,GoogLeNet(FT)+MultiPatch[14]是微调后的GoogLeNet特征使用多个分块均值化的结果。
从表8中可以看出,除了VGGM-fc-RF和GoogLeNet(FT)+MultiPatch外,本文提出的4种CNN特征比其他CNN特征的ANMRR值低,而GoogLeNet(FT)+MultiPatch和VGGM-fc-RF的特征提取方法比本文方法复杂。因此选择合适的CNN网络以及采用合理的聚合方法能够有效提高HRRS图像检索性能。
3 结论
本文对VGG16和GoogLeNet中表达局部信息的CNN特征,采用池化区域尺寸不相同的均值池化和BoVW 2种方法得到不同的聚合特征,并将其用于HRRS图像检索。通过研究获得主要结论如下:
1)针对HRRS图像,池化特征的检索性能比BoVW特征的性能好。
2)池化特征中池化区域尺寸直接影响检索结果,大多数池化特征的最优池化区域尺寸为特征图尺寸的60%~80%之间。这种尺寸既能有效地剔除CNN特征的冗余信息,同时也能保留一些区分度明显的特征信息。
3)BoVW特征中视觉单词数目对图像检索性能影响较大。当输入图像尺寸显著增大时,视觉单词数目的最优取值也相应增大,以VGG16的取值变化尤为明显。
4)不同输入图像尺寸影响聚合特征的检索性能,当默认尺寸和原尺寸相差较大时,原尺寸得到的聚合特征检索性能更好; 当默认尺寸和原尺寸很接近时,默认尺寸有时更适合CNN网络。
5)与传统的浅层特征相比,本文提出的聚合特征的检索性能大幅度提高。GoogLeNet的最优池化特征和VGG16的最优BoVW特征的ANMRR值比浅层特征BoVW分别降低了27.31%和21.51%。与目前提出的CNN特征相比,本文选用的CNN特征更适用于聚合,采用的聚合方法简单有效。
因此本文提出的聚合特征能够有效提高HRRS图像的检索性能,其中池化特征提高幅度更为明显。但是池化特征的维度相对较高,今后将进一步研究如何有效降低池化特征的维度。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27 05:35:46
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
电子制作(2019年11期)2019-07-04 00:34:38
计算机技术与发展(2019年1期)2019-01-21 00:56:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
专利代理(2016年1期)2016-05-17 06:14:36
电视技术(2014年19期)2014-03-11 15:38:20
