
用于车辆识别的深度学习模型的优化
2019-03-25 05:54:06刘泽康孙华志姜丽芬马春梅
天津师范大学学报(自然科学版) 2019年1期
刘泽康,孙华志,姜丽芬,马春梅
(天津师范大学计算机与信息工程学院,天津300387)
随着日常生活中汽车数量的增多,单纯依靠人工识别已经无法满足需求,所以需要利用计算机识别代替人工.传统的车辆识别方法一般可以分为3类:帧间差分法[1]、背景差分法[2]以及光流法[3].传统方法虽然针对不同问题提出了有效的解决办法,但是由于模型结构简单、训练不充分等问题,依然存在实时检测性差或过于依赖外部环境等缺陷[4-6].近些年用于车辆识别的深度学习理论迅速发展.文献[7]结合手工特征和深度玻尔兹曼机方法,将方向梯度直方图等3种手工设计的特征作为输入,并通过学习融合各特征的优点,以提高识别精度.文献[8]在深度置信网络结构的基础上,交替使用有监督和无监督过程训练,有效解决了梯度消失问题.文献[9]将提取的25种基线特征和局部纹理特征融合,进行栈式自编码器训练,简化了网络结构,提高了识别精度.卷积神经网络(CNN)作为深度学习理论的一个重要分支,在车辆识别方面有着突出的贡献.文献[10]在CNN的基础上使用Adaboost算法训练多个不同的弱分类器,再将弱分类器联合起来进行车辆识别.文献[11]通过对遮挡物进行处理,再利用卷积神经网络,提高了有物体遮挡的汽车的识别精度.文献[12]将基于卷积神经网络的车辆检测用于正面碰撞预警.文献[13]通过反复堆叠3×3的小型卷积核和2×2的最大池化层构建了16层的卷积神经网络(VGG16).文献[14]通过使用1×1、3×3、5× 5的卷积核尺寸对输入数据进行卷积,再将3个卷积的输出结果组合起来构成模型(GoogLeNet).虽然以上方法有较高的识别精度,但其对于深度学习网络的改造大多是通过加深模型层数的方法实现的,而网络层数和网络参数的增加,会导致模型计算开销大、响应时间慢,并且对硬件要求较高,所以这些方法不易于运用到现实中的车辆识别中.本文通过参数优化的方法,使模型以较小的网络层数在短时间内达到理想的精度.另外,本文选取真实拍摄场景中车辆的大小进行建模,针对真实拍摄场景车辆尺寸较小的问题,采用复制边界的方法降低卷积过程中的信息损失,在特定的分辨率下对比分析了不同大小的卷积核对车辆识别精度的影响.利用公开数据集ImageNet和PKUVD进行实验,结果表明,用于车辆识别的最佳卷积核尺寸分别为5×5、4×4、3×3,优化后的模型识别精度可达99.74%,优于CNN+Adaboost的97.02%和GoogLeNet-lite的99.35%.
1 网络结构设计
1.1 基于原边界保留的卷积神经网络模型构建
卷积神经网络模型包括各网络层的构建以及各网络层参数的训练.本文卷积神经网络由5部分构成,分别为输入层、卷积层、池化层、全连接层和Softmax分类器.输入层输入像素大小为m×n的图像.卷积层的计算公式为

其中:al为第l卷积层的输出;f(·)为卷积层的激活函数,wl为卷积核,*代表卷积操作,bl为卷积层的偏置参数.在传统卷积神经网络中,图像通过卷积层后尺寸会减小.为尽量保留图像中的像素点,卷积层采用保留原边界像素的方法,即在图像边界补零,使得图像卷积后输出的图像尺寸与原图像尺寸保持一致.池化层选用最大池化,最大池化的公式为

其中:xl为池化层的输出;g(·)为次抽样层的激活函数, down(·)为次抽样函数, βl为池化层权重, bl为池化层的偏置函数.池化层选择下采样框中像素值最大的像素点进行下采样,提取主要特征,进而简化网络复杂度.全连接层连接所有特征图共同做出决策,得到特征向量.全连接层得到的特征向量放入Softmax分类器中进行二分类.图1为大小64×64的图像通过3×3的卷积核进行卷积的过程.
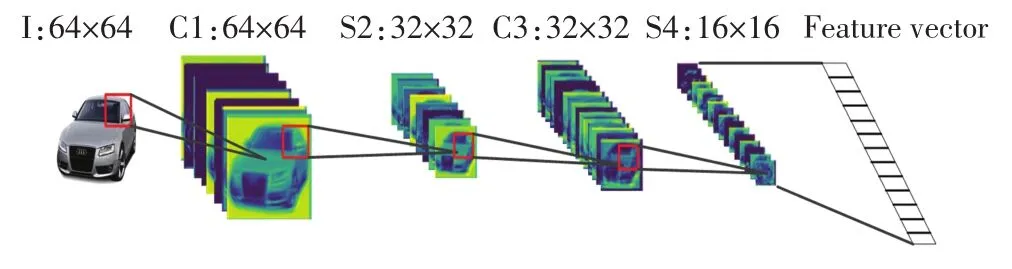
图1 卷积神经网络搭建过程Fig.1 Construction process of CNN
卷积神经网络通过训练自动更新权重和偏置值,网络参数训练分为2个阶段:正向传播阶段输入图像,经过各层过滤,最后由分类器输出分类结果;反向训练阶段由分类器输出结果计算出误差值,反向传播训练各层参数.
1.2 图像预处理
由于卷积神经网络要求输入层输入图像的大小要保持一致,而通过摄像头等方式采集到的样本大小不一致.所以利用多相位图像插值(Lanczos)算法进行图像预处理,通过缩放尺寸计算新的像素点,在将图像缩放到目标大小的基础上,尽量保留原图像的特征.
设f(i,j)为缩放前像素点,g(u,v)为缩放后像素点,首先计算缩放前后像素点移动距离(x,y).其中:x=(u × Win)/Wout, y=(v × Hin)/Hout; Win和 Wout分别为缩放前后的图像宽度,Hin和Hout分别为缩放前后的图像高度.则输出点 g(u,v)可由下式得出
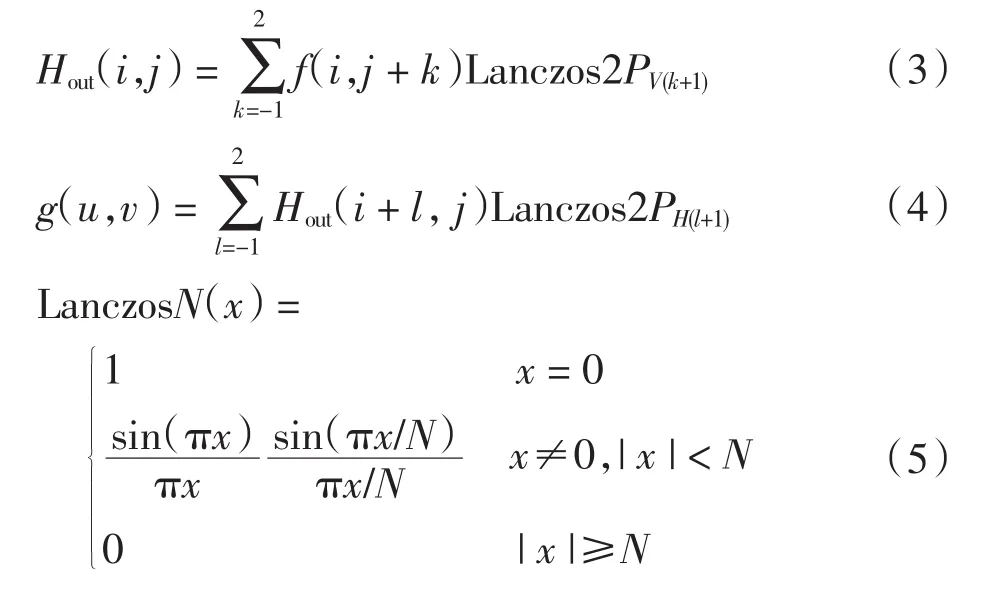
其中:Hout(i,j)为原像素点进行纵向移动后的像素点,LanczosN(x)为滤波函数.图2为大小4×4范围内进行的Lanczos算法缩放示意图.

图2 预处理示意图Fig.2 Preprocessing diagram
图2中,水平相位值PH0=1+x,PH1=x,PH2=1-x,PH3=2-x,垂直相位值 PV0=1+y,PV1=y,PV2=1-y,PV3=2-y.根据上述关系式可得到8个相位值,从而实现多相位滤波.原图像与经过缩放后的图像示例见图3,图3(a)为像素值 300 × 240的原图像, 图3(b)为缩放后像素值64×64的图像.

图3 图像缩放对比Fig.3 Comparison of image zoom
2 样本库建立
卷积神经网络属于深度神经网络,需要大量的训练集进行训练,本文使用斯坦福大学的ImageNet数据库和北京大学的PKU-VD[15]数据库,从中选取了8 588张车辆图像以及11 375张背景图像作为样本库.其中训练集样本占总数的80%,测试集样本占20%.
2.1 样本标记
将样本中的非车辆图像和车辆图像分别用“0”和“1”标记.为防止过拟合导致检测框将含有车辆一部分的背景图像认定为汽车,本文将设置只包含车辆一部分的图像为非车辆图像.训练集和测试集中样本具体标记见表1.

表1 样本标签统计Tab.1 Sample label statistics
2.2 样本裁剪
由于收集到的样本图像像素大小不同,因此需要将样本裁剪成大小一致的图像.按照1.2节的Lanczos算法将所有样本图像统一裁剪为像素64×64的图像作为输入,裁剪后的部分图像如图4所示.

图4 部分裁剪后图像Fig.4 Partial cropped images
3 实验结果分析
3.1 默认参数设置
本文选取5层卷积神经网络.第1层为输入层,输入大小为64×64的裁剪后图像.中间3层为卷积层,卷积层的卷积核大小按默认设置,然后依次从第1个卷积层逐层改变卷积核大小,分别采用2×2、3×3、4×4、5×5大小的卷积核进行实验,3个卷积层分别使用32、64、128个卷积核提取特征.全连接层设置500个卷积核进行全连接.之后将输出的向量放入Softmax分类器进行分类.另外,本文选择对数损失函数用作多分类,此函数为与Softmax分类器相对应的损失函数,主要使用极大似然估计的方式.学习速率设置为0.001,并且使用随机梯度下降的算法作为优化器.
3.2 实验结果对比
输入层输入经过预处理后的64×64 RGB图像,进行卷积神经网络训练.首先固定第2层和第3层卷积网络卷积核大小为默认的3×3,第1层卷积网络分别使用 2×2、3×3、4×4、5×5大小的卷积核进行实验,结果见图5.
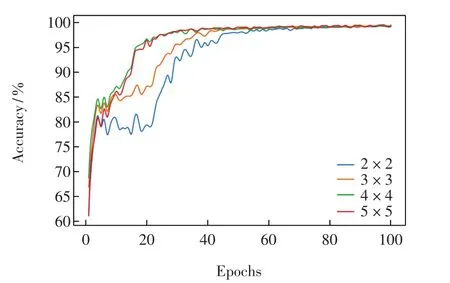
图5 第1层卷积网络实验结果Fig.5 Experiment results of the first convolutional layer
由图5可以看出,卷积核大小为2×2、3×3的神经网络收敛速度较慢,卷积核大小为4×4的神经网络收敛速度在前期略高于卷积核大小为5×5的.由于图5给出的是全部100次训练的测试结果,随着训练次数的增加,不同卷积核网络的识别精度曲线几乎重合,为了更准确地观察识别精度,截取训练次数为90至100的精度识别曲线,见图6.
由图6可见,当训练次数较大时,使用5×5大小卷积核的神经网络的整体识别精度高于其他3种尺寸卷积核的网络.因此,第1层卷积网络最佳的卷积核尺寸为5×5.

图6 第1层卷积网络实验部分结果Fig.6 Partial experiment results of the first convolutional layer
下面固定第1层卷积网络卷积核大小为5×5,固定第3层卷积核大小为默认的3×3,第2层卷积网络分别使用 2×2、3×3、4×4、5×5大小的卷积核进行实验,结果见图7.
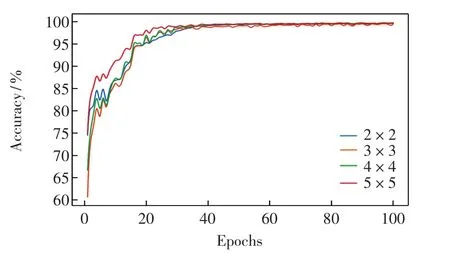
图7 第2层卷积网络实验结果Fig.7 Experiment results of the second convolutional layer
由图7可以看出,卷积核大小为5×5的神经网络收敛速度快于其他3种尺寸卷积核的网络.这是由于在训练次数较少的情况下,尺寸较大的卷积核对于图像像素点的计算更充分,可以使得浅层特征得到充分提取,所以在图像像素损失不大的情况下可以更快达到较高的精度.但是,随着训练次数的增加,各尺寸卷积核网络的识别精度趋近相同.同样截取训练次数为90至100的精度识别曲线,见图8.
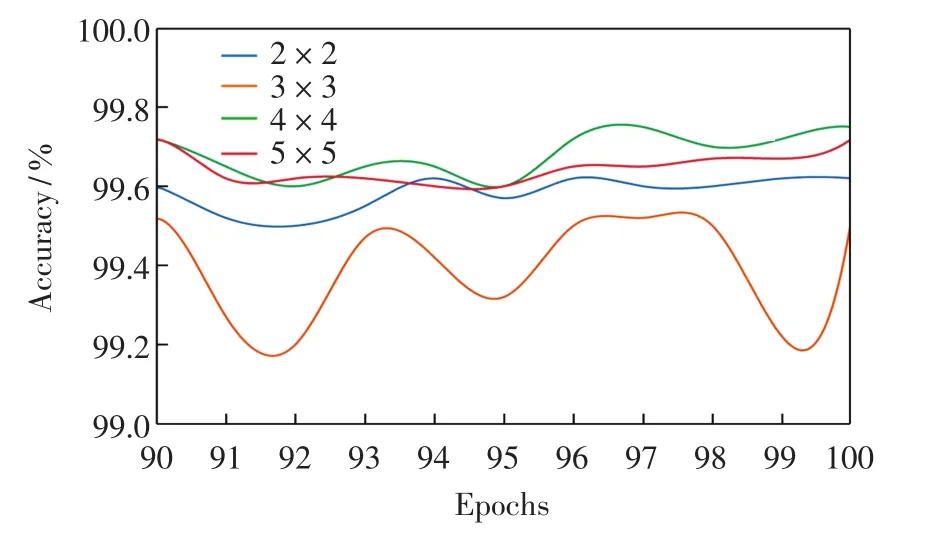
图8 第2层卷积网络实验部分结果Fig.8 Partial experiment results of the second convolutional layer
由图8可见,训练次数较大时,卷积核大小为4×4的网络的识别精度整体高于其他3种卷积核的网络.这是由于经过长时间的训练,随着网络层数的加深,特征图尺寸变小,较大尺寸的卷积核会造成特征信息的丢失,而较小尺寸的卷积核又不足以充分提取特征信息.综合考虑收敛速度和识别精度,第2层卷积网络最佳的卷积核尺寸为4×4.
固定第1层卷积网络卷积核大小为5×5,第2层卷积网络卷积核大小为4×4,第3层卷积网络分别使用2×2、3×3、4×4、5×5大小的卷积核进行实验,结果见图9.

图9 第3层卷积网络实验结果Fig.9 Experiment results of the third convolutional layer
由图9可见,各尺寸卷积核的网络收敛速度大致相同,甚至使用较小卷积核(2×2)的网络收敛速度要稍快于其他较大卷积核的网络.这是由于深层特征图尺寸较小,较大的卷积核不能充分提取车辆的细节特征,导致其收敛速度变慢.截取训练次数为90至100的精度识别曲线,见图10.
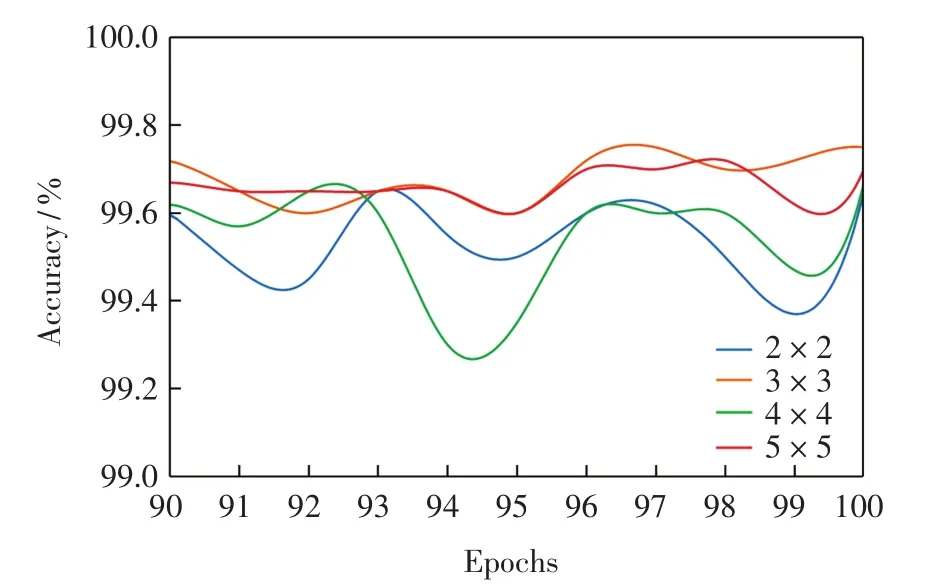
图10 第3层卷积网络实验部分结果Fig.10 Partial experiment results of the third convolutional layer
由图10结果可以看出,训练次数较大时,卷积核大小为3×3的网络效果最好.这是由于深层特征图尺寸较小,较大的卷积核会造成特征细节的丢失,较小的卷积核又不足以提取车辆特征.因此第3层卷积网络最佳的卷积核尺寸为3×3.
根据以上实验结果,分别选取3层卷积网络卷积核尺寸为5×5、4×4、3×3,搭建卷积神经网络模型并进行训练.将车辆图像输入训练好的卷积神经网络中,车辆图像经过(卷积层+池化层)处理,得到特征提取图,部分特征提取图见图11.
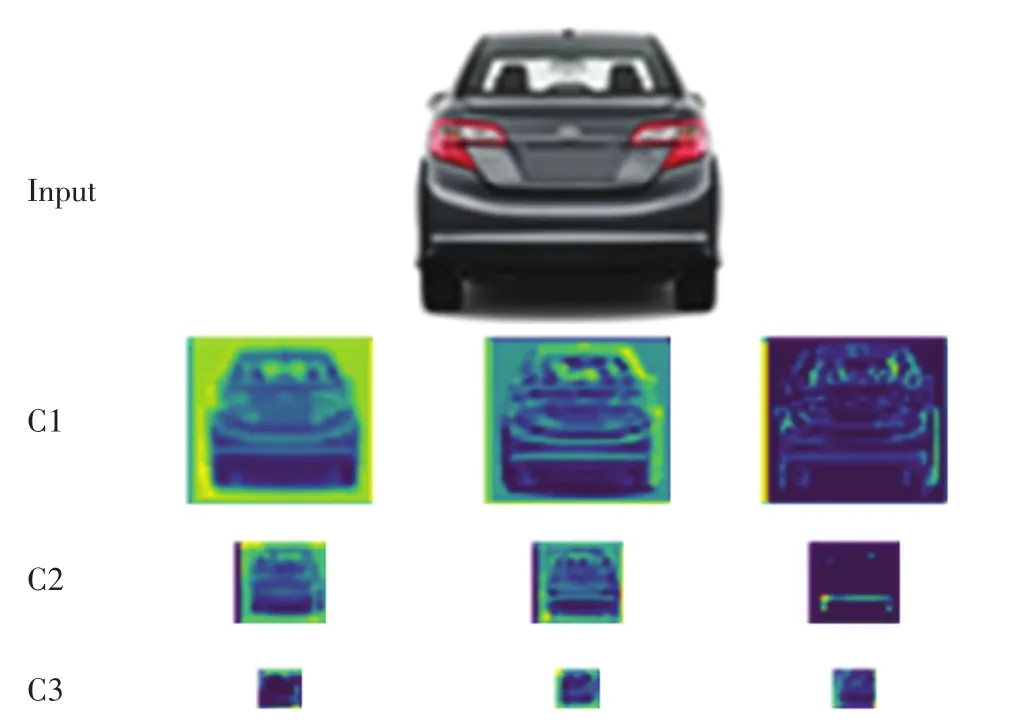
图11 特征提取图Fig.11 Feature extraction map
为验证本文方法的有效性,选取车辆识别精度较高的 CNN+Adaboost[10]、VGG16[13]以及 GoogLeNet-lite[14]与本文方法进行对比实验,实验数据均采用第3节构建的数据集,对比结果如表2所示.
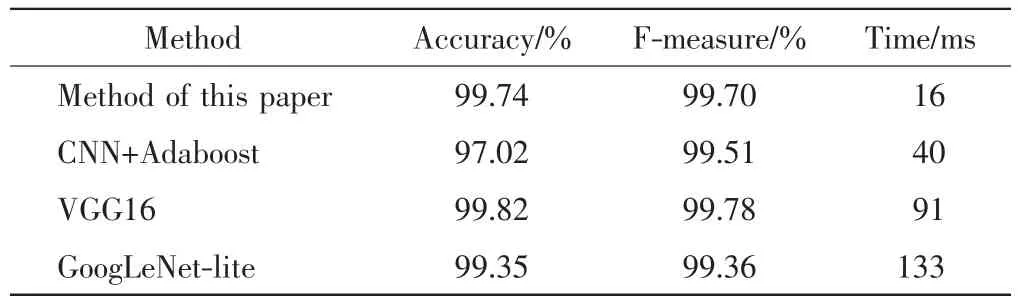
表2 不同算法实验结果对比Tab.2 Comparison of different algorithms
由表2可以看出,本文优化后模型的最终识别精度可以达到99.74%,高于CNN+Adaboost的97.02%和GoogLeNet的99.35%.另外,优化后模型的F-measure达到99.70%,也高于CNN+Adaboost的99.51%和GoogLeNet的99.36%.由于VGG16的模型结构复杂,一定程度上减小了卷积核大小对于模型识别的影响.所以,VGG16模型的最终识别精度为99.82%,虽然略高于本文优化后的模型,但是其识别时间远远大于本文方法,而且本文方法的识别时间在4种方法中是最优的.综合实验结果各指标,本文方法更适用于现实场景的车辆检测.
4 结语
本文根据真实场景车辆大小进行建模,针对真实场景中车辆图像较小的问题,使用复制边缘像素进行填充的方法,减小了卷积造成信息丢失的影响,采取控制变量的方法对网络参数设置进行了优化实验,通过实验找到了各网络层的最优参数设置,并与目前的高精度方法进行实验对比,结果表明本文方法的识别性能较好.
猜你喜欢
智族GQ(2022年12期)2022-12-20 07:01:18
China’s foreign Trade(2021年6期)2021-12-26 06:22:58
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电脑知识与技术(2018年35期)2018-02-27 13:29:44
汽车与新动力(2017年3期)2017-06-29 12:00:21
自动化学报(2017年11期)2017-04-04 02:52:44
中华奇石(2015年5期)2015-07-09 18:31:07
电视技术(2014年11期)2014-12-02 02:43:28
