
Dynamic Trust Model Based on Service Recommendation in Big Data
2019-03-18 08:15:52GangWangandMengjuanLiu
Computers Materials&Continua 2019年3期
GangWangandMengjuanLiu
Abstract:In big data of business service or transaction,it is impossible to provide entire information to both of services from cyber system,so some service providers made use of maliciously services to get more interests.Trust management is an effective solution to deal with these malicious actions.This paper gave a trust computing model based on service-recommendation in big data.This model takes into account difference of recommendation trust between familiar node and stranger node.Thus,to ensure accuracy of recommending trust computing,paper proposed a fine-granularity similarity computing method based on the similarity of service concept domain ontology.This model is more accurate in computing trust value of cyber service nodes and prevents better cheating and attacking of malicious service nodes.Experiment results illustrated our model is effective.
Keywords:Trust model,recommendation trust,content similarity,ontology,big data.
1 Introduction
Trust-based security system has been an important research field nowadays since trust management was proposed by Blaze et al.[Blaze,Feigenbaum and Lacy (1996)] in 1996.When big data went into our life,work environment and physical world,trust management about big data service became an important issue [David and Ongand(2016); Liu,Dong,Ota et al.(2016); Siddiqa,Hashem,Yaqoob et al.(2016)].Trust management involves a lot of fields,and some scholars have already been going studies in these issues and proposed a series of trust models in accordance with different application systems.Zhang et al.observed that “trust model was separated into policybased and reputation-based models in terms of management mechanism in e-commerce environment” [Zhang,Cheng,Jiang et al.(2008); Nejdl,Olmedilla and Winslett (2004);Chu,Feigenbaum,LaMacchia et al.(1997)].Trust model was separated into two trust models based on centralization and distribution in a view of structure [Yu and Singh(2002); Resnick and Zeckhauser (2002); Zacharia,Moukas and Maes (2000)].Li et al.proposed “PeerTrustModel:an electronic community based on local reputation under P2P environment” [Li and Liu (2004)].Dou [Dou,Wang,Jia et al.(2004)] proposed “a global trust model that is intended to overcome the lack of security of literature” [Zhang,Cheng,Jiang et al.(2008)].Literature [Li,Jing,Xiao et al.(2007); Jin,Zhang,Qu et al.(2008)] investigated a similarity-based added-weight trust model that can help solving the problem of malicious nodes cheating.
From these literatures’ reviews,we found that they all lacked to consider difference among different services.In addition,we also found that existing trust models lacked fine granularity computing,so it is difficult to distinguish service difference among different service providers,and difference among different services of the same service provider.We proposed a dynamic trust model based on service recommendation in big data.The other parts of this paper are organized as follows:Section 2 is dynamic Trust model.Section 3 is concept similarity computing of trade goods (or services) domain ontology and trust model algorithm.Section 4 is simulation experiment and result analysis.Final section is next works and conclusions.
2 Dynamic trust model
For clearly illustrating own model,we firstly gave a few related concepts as follows.
Definition 1.Service requestor (service receiver) is to get services from network service provider.
Definition 2.Service provider is to provide services for network service receivers.
Definition 3.Node that recommends information to Service requestor is called recommendation node,and then they are classified to direct familiar recommendation node,indirect familiar recommendation node and stranger recommendation node.
Definition 4.Direct familiar recommendation node refers to have ever direct services between recommendation node and service provider.
Definition 5.Indirect familiar recommendation node refers to have already had direct transactions or indirect transactions with direct familiar recommendation nodes.
Definition 6.Direct Trust is that service requestor gives an evaluation of service provider and this evaluation is based on direct services that service provider gave service requestor ago.
Definition 7.Recommendation trust refers to an evaluation of service requestor to service provider according to their history service state.
2.1 Trust computing model
System would like to judge the whole trust value of nodek(nodekis a service provider or resource provider) is closely related to two factors.One factor is that whole trust value of nodekusually comes from evaluation of other nodes to it,and whether this evaluation is accuracy and objective is largely depended on similarity between services or service received by individual evaluating node.The other is that whole trust value of nodekis also related to a trust evaluator’s familiarity with a trust recommendation node (also known as resource recommendation node).The structure of this model is described in Fig.1.

Figure1:Trust computing model
From Fig.1,when Service Requestor applied a service to Service Provider,system computed and fed back trust value of Service Provider,and then gave an advice whether Service Requestor selected service proposed by Service Provider.During computing trust,algorithm will firstly fuse Direct Trust,Indirect Trust and Recommendation Trust,in the process of fusion we will also comprehensive consider relationship among Direct Trust,Indirect Trust and Recommendation Trust because trust in itself involves multiattribution such as service content similarity,time sensitive.Meanwhile,system updated trust value of Service Provider in User Dataset.
2.2 Direct trust computing

When there was history interaction between service provider and service receiver,we use following equation as Direct Trust.In whichDTi,jis direct trust value,Si,jis the successful number of times betweeniandj.Gi,jis all interactions times betweeniandj.Fi,jis the failures number of times betweeniandj.whenGi,j=0,we setDTi,j=0.5.Meanwhile,
2.3 Recommendation trust computing
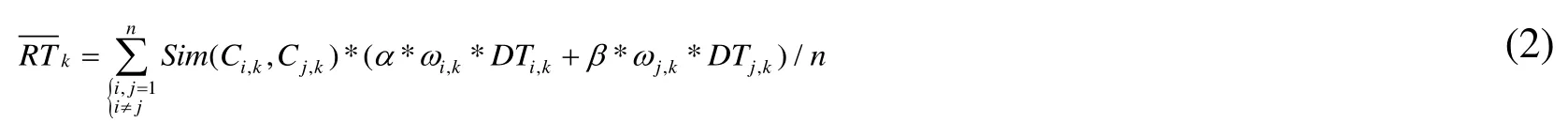
Recommendation Trust computing equation that we used is as following:
whereRTkrefers to integration evaluation value of recommendation trust to node k,andSim(Ci,k,Cj,k)is the similarity of transaction contentCi,kandCj,kof between nodei,jandk,jandk,ωikandωjkrespectively refer to acquaintance recommendation weight and stranger recommendation weight,andωikrefers to evaluation value of service requestor to service recommendation node; in whichωikandThe recommendation weight to stranger is set at 0.5,that is to say,trust and un-trust of node initially are fifty-fifty.αis the recommendation weight of direct or indirect familiar node,and thenαis set at as following.

If α<ε,this node is abandoned.ε refers to threshold value of trust chain and was set by us.is recommendation weight of stranger.Ifwhilethis node is actually a new joining node or a dormant node.

compute trust degree of node whose three square-root is used to ensure the weight of each coefficient can be within a normal range.At the same time,it also ensures that system can be easy to make reasonable trust judgment to node.In this case,Eq.(2)becomes Eq.(3).

2.4 Global synthetical trust
Global synthetical trust refers to a general trust degree.The paper used following equation to compute Global Trust Degree.
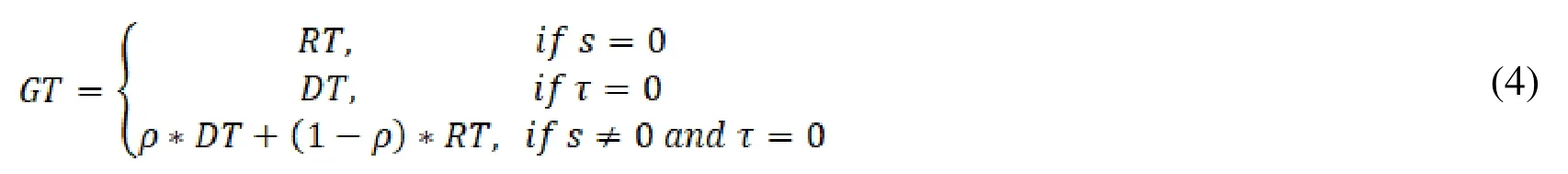
In which,sis the number of recommendation node,τis the number of direct transaction between trust evaluator and service provider.is the weight of direction transaction,is the weight of recommendation trust.With social relationship analysis,trust earned by direct interaction of two nodes is higher than trust earned by nodes recommendation,so trust evaluator believes target node by interaction of self-trust evaluator and target node.is a function to indicate that trust is a dynamic change with interactive numbers and we make argument in Eq.(5).

n∈{1,2http://china.alibaba.com/,3http://www.taobao.com/,…},xrefers to thex-thinteraction between service evaluator and service provider.xandρare positive correlation.When service requestor is the first interaction with service provider,because the number of interactions is too little,service requestor has to rely on recommendation trust evaluation given by the others.When the number of interactions is creasing between service requestor and service provider,service requestor would like to judge trust value of service provider by its own,and thenρwill enlarge gradually as increase of interactive numbers.
3 Computing of Concept similarity degrees about service domain ontology
3.1 Service or trade goods ontology building process
This paper proposed a new service domain ontology building method.We firstly gave its mainly building process as follows:
3.1.1Aim of building domain ontology
Building different domain ontology is for different application purpose in different field.Thus,the first step of building domain ontology to our model aims to complete our application purpose.
3.1.2 Determining ontology Concept and classification system
There generally are two ways to get domain ontology data sources.“The first comes from lexicons and professional dictionaries.The second relies on mathematical analysis by using set of language data and documents,and computing and analyzing the weight of conceptualizations,and then selecting concepts of those greater weight” [Jia (2006);Uschold (1996)].This paper uses the principles of Chinese Library Catalogues,Trade Marks and Commodity Catalogues of the People’s Republic of China as building way of service domain ontology,and classification and definition of Alibaba2http://china.alibaba.com/,Taobao3http://www.taobao.com/and Baidu on E-commerce products.Determining attribution and relationship among classes.Class attribution is as a classifying basis of research object,and is used to distinguish between different classes,and a subclass will inherit attributions of father class.Besides defined class attributions,it also added constraints to specific attribute during building ontology.Constraints may be derived from father class,and there are also some new attribution constraints to a subclass.e.g.,the key attributes of automobile ontology is those attributes such as design and production.However,the key attributes of automobile as commodities focus more on its applications and the attributes as commodity,such as price,color and exterior.In addition,Relationship among classes is also an attribution.Fig.2 is a service domain ontology structure built by us.
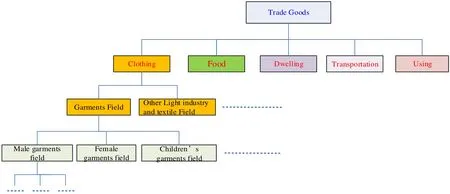
Figure2:Service domain ontology structure
3.1.3 Formal definition and explanation of ontology
Definition 8:ontology indication uses five tuples,

Of which,Cis concept set;Ris a set of relationship;ACproductis a conceptproductrattribution set composed by more attribution sets;refers to a set of more attributions component and is also a relationship set of concepts;Xproductrefers to an axiom set.

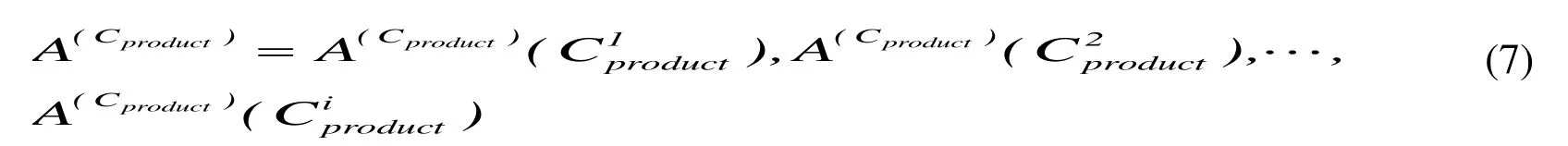
Definition12:ifto conceptsand
Definition13:
3.1.4 Ontology coding
Trade goods ontology adopts Proté gé which is a software development tool,and it can create ontology and run created ontology.In which,Fig.3 is a part of trade goods ontology.
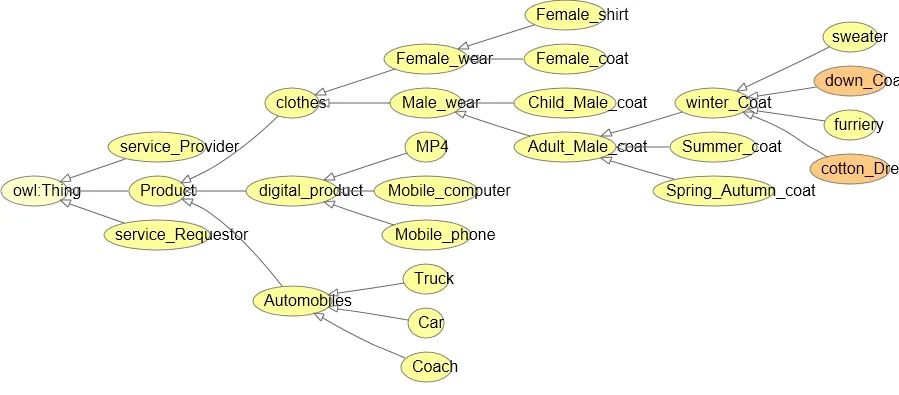
Figure3:Part of trade goods ontology picture
3.1.5 Ontology assessment
Ontology assessment is focused on clarity,coherence and extendibility.Moreover,other issues would be thought such as encoding minimal mistake probability,minimum restrict of ontology,etc.[Gruber (1995); Wu,Wu,Li et al.(2005)].
3.2 Similarity computation of ontology Concept in service domain
This paper put forward a similarity computation way of ontology concept.This method used statistical information entropy to calculate the weight of evaluation index and avoided the subjectivity of artificial weight method.At the same time,this paper also used heuristic algorithm to ensure a clear difference between two or more similar ontology concepts.
In ontology concept,conceptCihas to satisfy Eq.(8):
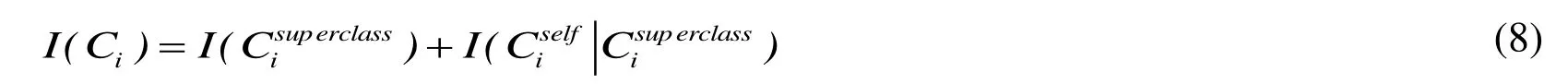
Of which,I(Csuperclass)denotes the information ofCsuperclassthat is parent class ofC;iiidenotes self-information ofCi.



this path,Csuperclassis a parental node ofC,computation equations is Eq.(13).thisthis

is a parental node of conceptsanddifference between two concepts can bring about change ofon the shortest path between them.Cκpresents a node of same side ofCthis. Two concepts similarity computing formula is as follows:

As is well known,when information of two concepts is respectively same,we think two concepts are the same,for avoiding the situation,we used heuristic algorithm to compute similarity.Heuristic algorithm is Tab.1.

Table1:Heuristic Algorithm
3.3 Trust computing algorithm
Initialization:To set the total number of node and service
Target:To get trust degree of service provider
Step 1:To initialize service path map.To define all network nodes.In which,there are never any interaction before between any two nodes.Meanwhile,to set the number of malicious nodes and good nodes.And then services are randomly distributed to nodes.When a node is defined malicious node,its service only has a half of a good node.Finally,system will create a service path map.
Step2:To compute Global synthetical trust degree,we need firstly initializeε,i,j.Secondly,whileiis larger than the numbers of loop and computing trust degree is larger than ε,system adopts this service path map,unless system cancels this service path map.
Step3:Ifiis smaller than the total number of service path and there aren’t malicious nodes in the present service path,system usessuccessNumas successful service number and usestotalNumas service total number.
Step4:Ifjis smaller than the number of service path andiandjare two different nodes,iandjare going to mutual service,and service successful ratio is the number of successful services dived by the total number of services,unless system abandons nodejand algorithm go back to Step 2.
4 Simulation experiment and result analysis
We divide service nodes into two sorts of nodes,one is good nodes,and the other is malicious nodes.Meanwhile,malicious nodes are divided into individual malicious nodes and cooperative malicious nodes.
4.1 Experiment analysis
Experiment 1:Analysis to malicious recommendation nodes scale.

Figure4:Service success ratio in malicious nodes dynamic change
Results of the experiment from Fig.4 show whole tendency to two algorithms is similar,e.g.,with increasing of percent rate of malicious node,we find service ratio of two algorithms declines gradually.However,there are a few important differences between two algorithms.Firstly,when malicious node rate is from 0 to 30%,we find that our algorithm effect is better than EigenRep algorithm.Service success ratio of our algorithm seldom decline,but EigenRep success ratio declines rapidly.From 30% malicious nodes to 70% malicious nodes,we can find though success ratio of two algorithms all declines,our algorithm effect is better than EigenRep algorithm.Secondly,when we set percent rate of malicious nodes is 50%,we find our algorithm still has a high service success rate.In a word,from these falling service success rate and numbers,no matter what it is an individual malicious node or cooperative malicious node,we can find our algorithm is better than EigenRep algorithm.
Experiment 2:Sensitivity analysis to number of service cycle.

Figure5:Service success rate with different service circulation times
In this experiment,malicious node rate we firstly set is 40%.We can find tendency of two algorithms is increase gradually with increasing of service circulation times,that is to say,tendency of two algorithms is similar.However,there are still a few differences because we can find service success rate of two algorithms is different in the different circulation times.Firstly,in 50-th cycle,we find EigenRep algorithm’s service success rate is only 69.4%,but our algorithm is 90.2%,our algorithm effect is obviously better than EigenRep.Secondly,our algorithm can constrain better cheat and pretending of malicious node.Obviously,from Fig.5 we can find that sensitivity of our algorithm to malicious attack is better than EigenRep’s.
Experiment 3:Analysis directed to malicious recommendation attack.

Figure6:Service success rate in different malicious recommendation nodes
This picture illustrates that tendency of two algorithms is decline gradually with the increasing number of malicious recommendation nodes,and we find that tendency of two algorithms is similar.However,there are still a few differences because we can find service success rate of two algorithms is different under different malicious node numbers.When the number of malicious nodes is 30%-40%,we find Hassan algorithm’s service success rate is obviously lower than our algorithm.This experiment illustrates our algorithm effect is obviously better than Hassan.Secondly,though Hassan model is good at constraint to node cheat,Hassan model has a few lacks,e.g.,Hassan has an assumption that recommendation nodes is trust,and Hassam does not have a specific punishment strategy,so its effect is not good enough to constrain malicious recommendation.
By these analyses,we can know trust algorithm proposed in this paper can effectively constrain malicious recommendation of dishonest nodes,and in same recommendation road good nodes can ensure service success rate.By compare our model with EigenRep and Hassan algorithms,experiment results illustrate our model is good enough to constrain malicious recommendation,cheat and attack.
5 Conclusions and further works
In big data environment trust is one of all preconditions in network service.Under the circumstances,we proposed trust evaluation model based on service recommendation.This model could distinguish familiar nodes from stranger nodes in cyber,and also took into account service or transaction ontology in business to make sure computing accuracy of recommendation trust,and computing effect was also better than past some trust models.Experiment results illustrated this algorithm effect is better than several typical trust models like EigenRep and Hassan model.At the same time,we’ll consider to improve algorithm efficiency and introduce more characteristics of trust so that trust compute is more accurate in further works.
Acknowledgment:This paper Supported by Natural Science Basic Research Plan in Shaanxi Province of China (Program No.2014JM2-6099) and the Project of Xi’an University of Finance and Economics (No.17FCJH13).
 Computers Materials&Continua2019年3期
Computers Materials&Continua2019年3期
- Computers Materials&Continua的其它文章
- Efficient Construction of B-Spline Curves with Minimal Internal Energy
- Modeling and Analysis the Effects of EMP on the Balise System
- R2N:A Novel Deep Learning Architecture for Rain Removal from Single Image
- Controlled Secure Direct Communication Protocol via the Three-Qubit Partially Entangled Set of States
- Research on the Law of Garlic Price Based on Big Data
- Effect of Reinforcement Corrosion Sediment Distribution Characteristics on Concrete Damage Behavior