
基于栅格的分布式新安江模型在三岔河流域的洪水预报研究
2019-03-18 12:55:42范火生
中国农村水利水电 2019年2期
范 火 生
(湖南五凌电力科技有限公司,湖南 常德 415000)
流域水文模型是进行流域产汇流计算的重要手段。近些年来,一方面,随着计算机、地理信息采集等高效便捷技术的普及,以及学科交叉思想的兴起,使得能够融合大量流域属性特征的分布式水文模型的实现成为可能;另一方面,下垫面的变化及人们对水文过程精细化模拟的要求,也使得分布式水文模型的研究成为必然的发展趋势,已逐渐成为行业研究热点之一。目前已有许多学者利用分布式水文模型实现了流域洪水的精确模拟以及小流域山洪雨量预警,杨大文等[1]通过构建黄河流域的大尺度分布式水文模型来探索流域水文时空演变规律;李致家等[2]将CASCD2D以及基于此改进的GSSHA模型运用于栾川流域的径流模拟,结果表明,改进后的GSSHA模型洪峰、径流深模拟以及确定性系数方面均比CASC2D模型有较大提升;刘淑雅等[3]将分布式水文模型用于小流域山洪预警临界雨量计算,实现了全流域的精细化模拟,得出了各流域不同初始土壤含水量、不同预警时段组合条件下临界雨量;石朋等[4]在蓄满产流基础上忽略计算单元间的局部水流交换构建了一套分布式水文模型,实验表明该模型在实验流域同样具有较强的适用性;雷晓辉等[5][6]在综合国内外现有分布式水文模型特点的基础上组织开发了一套功能齐全、可扩展性强的分布式水文模型EasyDHM。
虽然分布式水文模型在我国各地区有着较为广泛的实例应用研究,但其大多未考虑流域内水库调蓄作用。近年来,随着我国基础水利设施建设蓬勃发展,已在全国各地尤其是南方地区修建了大量中小型水库,故未考虑水库调蓄作用的分布式水文模型适用性已逐渐受到制约。基于此本文构建了考虑水库调蓄作用的分布式新安江模型,并运用于乌江上游三岔河流域,通过在普定水库洪水的实时调控作用对下游高车水文站洪水进行实时模拟,以期能为该地区洪水预报以及流域内分布式山洪预警提供技术支撑。
1 考虑水库调蓄作用的分布式新安江模型构建
新安江模型作为我国南方地区运用最为广泛的水文模型已成功运用于生产实际工作中,在山洪防治、洪水预报、水库调度等领域发挥了巨大作用。近年来,随着科学技术的发展以及实际生产工作的需要,已有学者[7,8]将集总式新安江改进为基于栅格的分布式新安江模型,有效避免了新安江模型未考虑流域时空分布不均匀性的特点。
本文基于此构建了考虑水库调蓄作用的分布式新安江模型,具体构建原理为:将流域栅格离散化,在每个栅格上均采用新安江模型进行产流计算,以马斯京根模型进行地表水流逐栅格汇流计算,以滞后演算法进行壤中流、地下径流汇流计算;将水库属性赋予对应位置栅格处,当水流汇流至水库栅格处时则根据水库防洪调度规则向下出流,随后继续进行逐栅格汇流计算直至汇流至流于出口处。
1.1 分布式新安江模型产流参数计算
分布式新安江模型将流域栅格离散化,每个栅格内均采用新安江模型进行产流计算,各栅格单元张力水蓄水容量WM、自由水蓄水容量SM与下垫面属性相关,可通过土地利用、土壤质地属性计算,具体计算公式如下:
WM=(θf-θr)L包
(1)
(2)
式中:θf为田间持水量;θr为凋萎含水量;L包为包气带厚度,其中包气带的厚度-般为0.5~0.9 m;θs为饱和持水量;L腐腐殖质土的厚度,其中腐殖质厚度为0~0.3 m,-般平均厚度为0.1 m。
不同土壤特性条件下张力水蓄水容量WM、自由水蓄水容量SM取值见表1。

表1 土壤特性参数与WM和SM
1.2 栅格拓扑关系计算
在进行逐栅格的汇流计算前必须先确定栅格的汇流演算次序,本文采用分级确定法计算各栅格的汇流级别并以此确定汇流演算次序,具体实现步骤如下。
(1)DEM填洼。
(2)流向计算。
(3)累计流量计算。
(4)搜索流域面积上累计流量最大值(即为流域出口),并赋值为当前计算次序k(k=1)。
陶行知先生曾指出,教师对学生应一视同仁,不能厚此薄彼。我以确立孩子的自我管理、自信心为切入点。平时,对于他一些调皮捣乱的事,我不是不分青红皂白的质问或是大声地训斥他,而是分情况在合适的场所和风细雨地教导他,教他认识什么是对的什么是错的,我应该做什么不应该做什么,学会遵守《小学生行为规范》。同时与家长取得联系,让他们平时做好孩子的表率,勤于孩子的卫生习惯、养成习惯的教育和培养。有一次他高兴地来到我面前,甜甜地说,老师你看,今天我干净吗?说着还把小手伸给我看,我和同学们都感到十分惊讶,也许是我的所作所为起到了“润物细无声”的作用。
(5)累加k(k=k+1),按照顺时针方向(从正北方邻点开始)依次扫描所有前一赋值点周围8个邻点,如果邻点流入前赋值点,则赋值该邻点当前计算次序k。
(6)重复步骤(5)直到没有栅格可以赋值。
(7)将得到的计算次序矩阵排序,即将最大值与最小值交换,依次类推,得到栅格演算次序。
1.3 汇流计算
地表汇流采用马斯京根法,壤中流地下汇流采用滞后演算法。
马斯京根汇流公式如下:
(3)
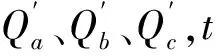

图1 栅格马斯京根汇流示意

(4)
其中:
(5)
式中:xe、ke分别为流量比重因子和蓄量常数。
产流模型的输出结果包括各栅格的流量过程和土壤饱和度,因此在逐栅格汇流过程中如栅格d未蓄满,则上游来水首先保证d栅格蓄满才能向下出流。
1.4 流域集水面积阈值确定
逐栅格马斯京根汇流中河道栅格与坡面栅格参数取值不同,故需计算流域集水面积阈值来区分坡面与河道栅格。阈值的确定方法大致可分为以下几种:平均坡度法、试错法、河网密度法等。其中,平均坡降法对于流域面积变化不敏感[9]。孔凡哲[10]等根据水系河网密度确定集水面积阈值,随着集水面积阈值的变化,河网密度随之变化,在河网密度随阈值变化趋于平缓时的对应值即为集水面积阈值。本文采用河网密度法确定研究区集水面积阈值。
2 实例应用研究
2.1 研究区域概况
本文以乌江上游三岔河中上游河段流域为研究区域,流域主要位于贵州省普定县境内。流域内有普定水库、高车水文站2个实测流量站点,集水面积分别为2 893、4 391 km2,降雨量分配不均匀,主要集中于5-10月,多年平均降雨量为1 187 mm,多年平均气温为14.7 ℃ ,多年平均流量约为123 m3/s;流域内雨量丰沛、气温光照适宜,植被发育良好多为森林、灌木,土壤类型以壤土、黏壤土为主。图2为三岔河流域水系站点分布图。

图2 三岔河流域水系站点分布
2.2 基础资料处理
基础资料处理包括降雨资料插值处理、利用DEM等地理信息数据建立流域数字水系。降雨资料插值处理采用反距离平均法,具体公式如下:
(6)
式中:X为网格中心点资料值;x1、x2、x3为临近3个站的资料值。
DEM数据来源于地理空间数据云(30 m×30 m),土地利用、土壤质地数据来源于中国科学院资源环境科学数据中心(http:∥www.resdc.cn,1 km×1 km),利用Arcgis 10.2提取的相关地理信息数据,提取流域土地利用、土壤质地资料分别如图3和图4所示,计算流域河网密度与集水面积关系如表2、图5所示。可以看出集水面积为350 km2是河网密度变化转折点,故三岔河流域集水面积阈值选取350 km2较为合适。

图3 三岔河流域土地利用情况
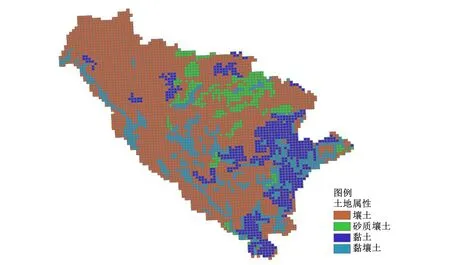
图4 三岔河流域土壤质地情况
2.3 模型参数优选
对于研究区内构建的分布式水文模型采用SCE-UA算法进行模型参数率定[11,12],该算法结合了包括基因算法在内的一些现有算法的优点,是一种以信息共享和生物演化规律为基础的非线性混合全局优化算法。以纳什效率系数为参数率定目标函数,选取2000-2014年内18场洪水进行参数率定和验证,优选所得普定水库控制面积和高车区间参数结果分别如表3和表4所示。

表2 三岔河流域集水面积与河网密度关系

图5 三岔河流域集水面积与河网密度关系

表3 普定水库控制面积参数优选结果

表4 高车普定水库区间参数优选结果
2.4 参数率定与验证
选取普定水库和高车水文站18场洪水率定与验证结果分别如表5、表6所示,部分场次洪水过程模拟结果如图6~图9所示,经普定水库调蓄后部分洪水下泄流量过程如图10、图11所示。
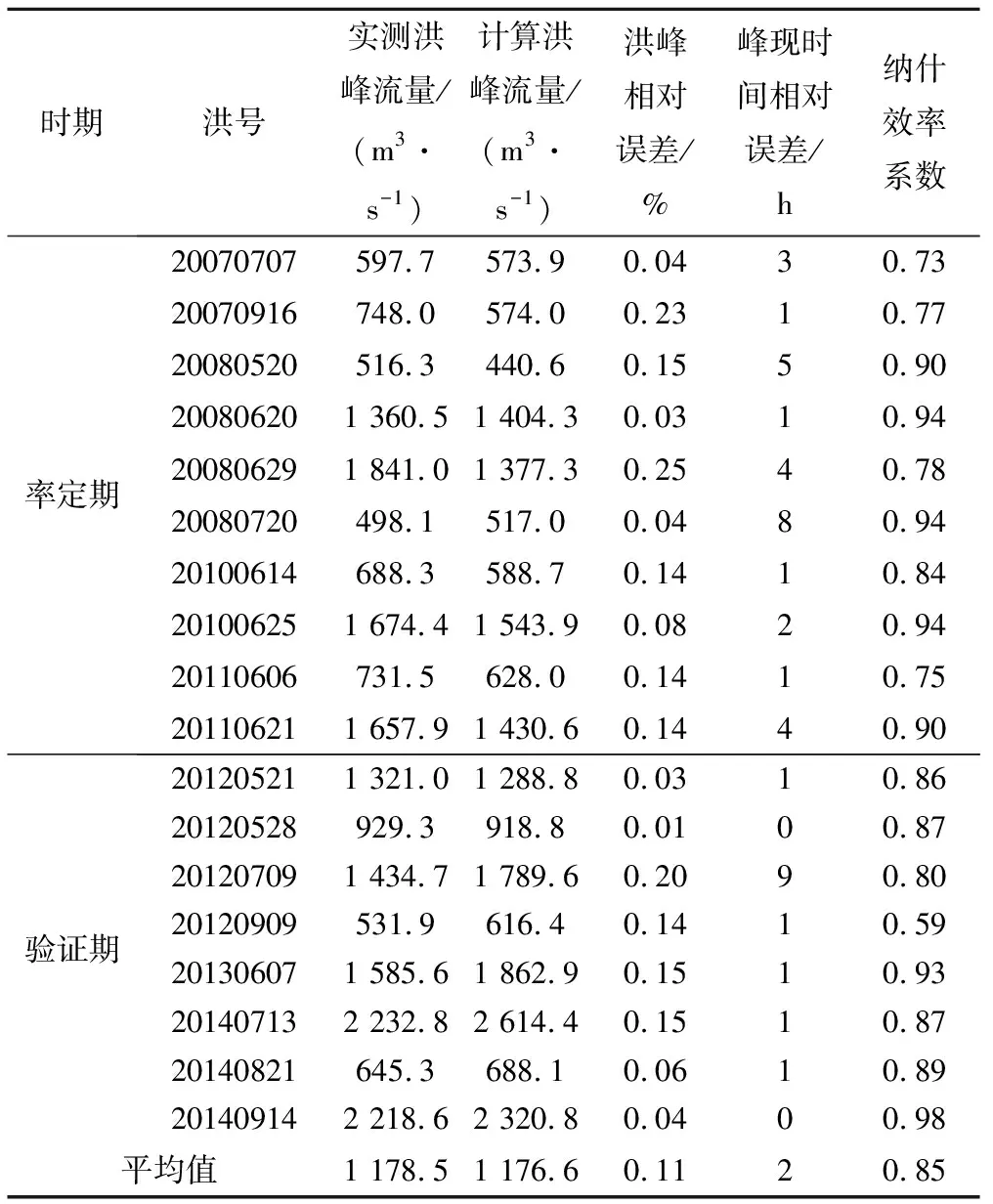
表5 普定水库场次洪水参数率定与验证结果

表6 高车水文站场次洪水参数率定与验证结果
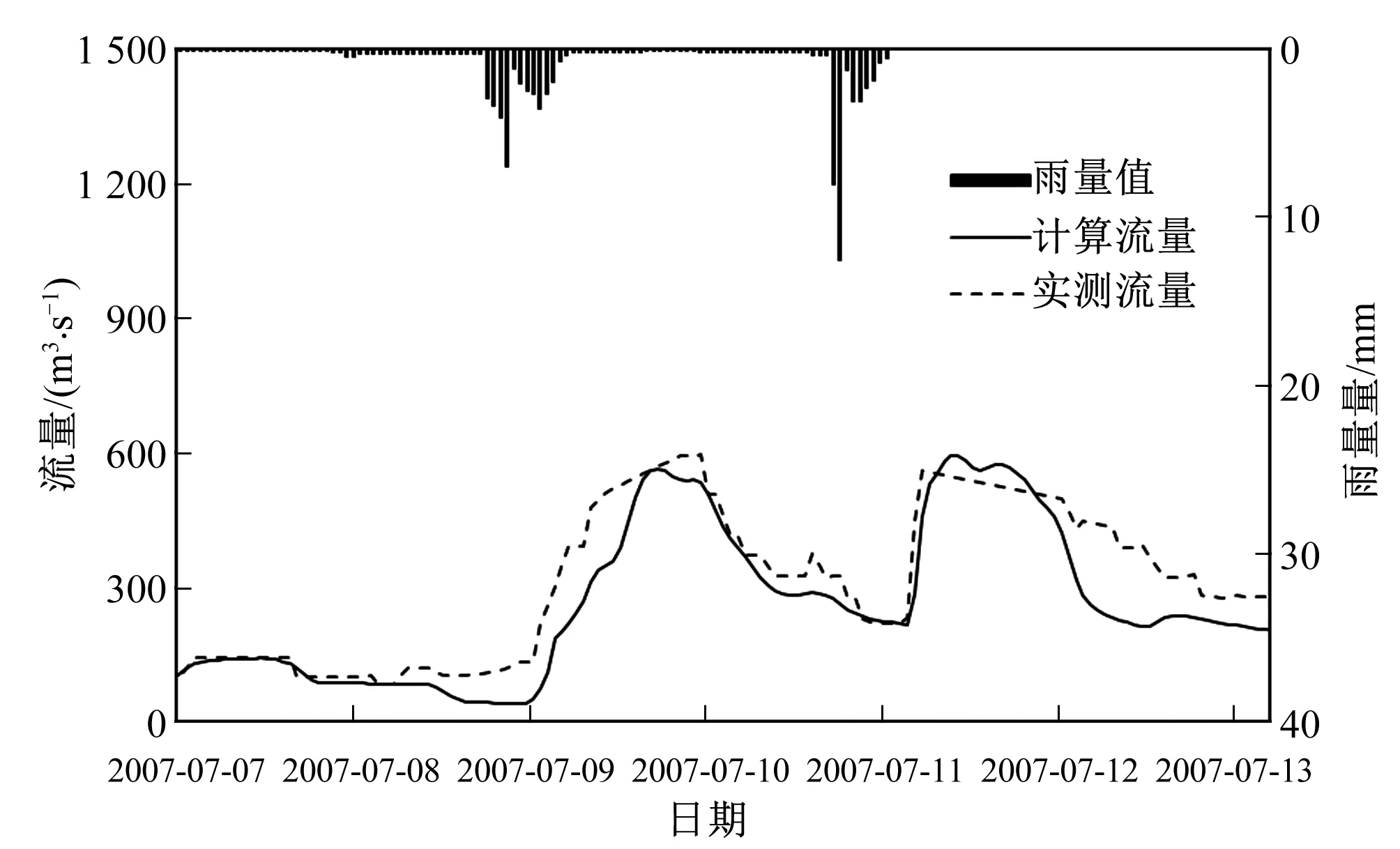
图6 普定水库20070707号洪水

图7 普定水库20100614号洪水

图8 高车水文站20070707号洪水
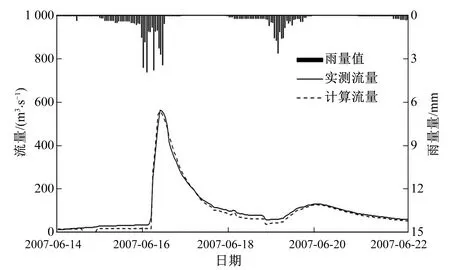
图9 高车水文站20100614号洪水

图10 普定水库20070707号洪水下泄流量

图11 普定水库20100614号洪水下泄流量
通过上述图表反映信息可知构建的分布式新安江模型可以很好地模拟三岔河流域的洪水过程。其中普定水库洪水模拟结果平均纳什效率系数达到0.85,洪峰合格率达到89%,峰现时间合格率达到77.8%;高车水文站洪水模拟结果平均纳什效率系数达到0.95,洪峰合格率达到100%,峰现时间合格率达到94.5%。通过分析图6~图9普定水库和高车水文站部分洪水模拟过程图,以及经普定水库调蓄后的下泄流量过程可知,高车水文站20070707号洪水主要来源于上游普定水库下泄流量,而20100614号洪水经普定水库调蓄之后洪峰流量仅为171.3 m3/s,故下游高车水文站洪水来源主要为区间产流。因此本文构建的分布式新安江模型在有效考虑水库调蓄作用影响的同时,实现了三岔河流域洪水过程的精细化模拟,可以作为该地区的洪水预报模型,同时可以为该地区的任意点山洪预警提供技术支撑。
3 结 语
分布式水文模型作为水文领域研究热点之一,已广泛运用于洪水预报、山洪灾害预警、水库调度等实际生产工作中,然而随着大量中小型水库的修建,分布式水文模型适用范围已逐渐受到制约。本文基于此构建了基于水库调蓄作用下的分布式新安江模型,并将其应用于乌江上游三岔河流域,通过分析模拟结果可知:所构建的模型能够很好地模拟该流域的洪水过程,有效地将普定水库对洪水的调蓄作用考虑进来,对普定水库和高车水文站洪水模拟平均纳什效率系数分别达到了0.85和0.95,可以作为该地区的洪水预报模型。同时可结合该流域内山洪灾害评价结果中各地的危险流量成果以及水库调度规则实现全流域分布式山洪雨量预警。
猜你喜欢
水利技术监督(2022年7期)2022-07-11 13:25:12
当代贵州(2019年41期)2019-12-13 09:28:58
中国科技纵横(2019年4期)2019-03-25 07:34:40
照相机(2017年10期)2017-11-22 05:51:11
水利技术监督(2017年3期)2017-06-09 06:55:34
中国资源综合利用(2016年6期)2016-01-22 07:29:00
中国资源综合利用(2016年3期)2016-01-22 07:28:17
智能建筑电气技术(2015年5期)2015-12-10 05:52:28
雷达与对抗(2015年3期)2015-12-09 02:39:00
太阳能(2015年7期)2015-04-12 06:50:03
