
基于微博兴趣相似度的研究
2019-03-15 13:31刘运冲
电脑知识与技术 2019年2期
刘运冲

摘要:微博用户构成了一个社交网络,在这个结构中,各用户之间又相互联系,存在着关系上的相似性。本文针对微博中信息量大,用户之间兴趣上的某种相似性,提出了一种多态相似度模型。从不同方面综合考虑,通过用户背景,交互性,以及微博内容之间的相似性,将用户兴趣形似性加权结合得到最终的结果模型。实验结果表明,多态相似度模型较传统的方法,在用户个性化推荐中更准确地反映用户的兴趣。
关键词:社交网络;多态相似度模型;个性化推荐
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2019)02-0175-03
Research on Interest Similarity Based on Weibo
LIU Yun-chong
(Anhui University of Science and Technology,Computer Science and Engineering,Huainan 232001, China)
Abstract:Weibo users constitute a social network. In this structure, users are connected to each other and there is a similar relationship. This paper proposes a polymorphic similarity model for the similarity of interest in microblogs and the interest among users. From a variety of aspects, through the user background, interactivity, and the similarity between the content of the Weibo, the user interest form weights are combined to obtain the final result model. The experimental results show that the polymorphic similarity model reflects the user's interest more accurately in the user's personalized recommendation than the traditional method.
Key words: social network; polymorphic similarity model; personalized recommendation
1引言
隨着信息技术的发展,各种社交手段也越来越丰富,不断丰富着人们的生活,社交媒体的出现,把世界交织成一个复杂的网络圈,人们可以即时获取信息,发表自己的观点,聊天互动也不像在信息匮乏时那样变得奢望。多种多样的社交工具可供人们选择,比如国外的Twitter、Facebook,国内的人人网,新浪微博,腾讯微博等,都是人们获取信息及发表观点的社交工具。根据财报显示,截至2017年12月,新浪微博的月活跃用户已增至3.92亿,创下新浪微博上市以来的一个新纪录。日活跃用户达1.65亿。其中从国内社交媒体来说,新浪微博的使用量及活跃度遥遥领先其他社交方式。由于微博有数以亿计的用户节点,在如此多网民在线的情况下,也面临着数据过载的问题。当用户阅读到某个用户或转发的微博之前,他并不知道这条微博是否是他所喜欢的,是否能够给他带来有用的信息,当用户面前面对那么多微博内容的时候,更多的是不感兴趣的或者认为这些微博并不能给他带来有用信息,用户阅读之后才能根据微博的价值及是否感兴趣来对微博进行转发或评论。因此,个性化推荐就显得尤为重要。根据用户的兴趣来为其推荐感兴趣的潜在的用户。
微博用户兴趣分为长期兴趣和短期兴趣。长期兴趣即静态兴趣。短期兴趣即动态兴趣,随时间发生变化,每个时间段用户的兴趣可能都不一样。更多学者研究相似用户只是从背景方面考虑,只考虑到了长期兴趣,有的只是单独从短期兴趣方面研究。本文结合长期兴趣和短期兴趣,从背景和微博内容方面综合考虑研究用户之间兴趣的相似度。
2相关工作
针对微博短文本相似性度量不精确的问题 ,黄贤英 ,陈红阳等人提出了多视角微博短文本相似度算法。实验表明,该算法在微博话题检测应用方面,能有效降低话题检测的漏检率和误检率。徐志明 ,李栋等人提出了各种用户属性信息的用户相似度计算方法,并根据实验对每个方法进行对比,结果表明在用户关系方面,基于社交信息的用户相似度具有更好的效果。黄宏程,陆卫金等人提出了基于用户兴趣相似性的关系预测算法。通过余弦相似性指标计算用户间的兴趣相似度来预测用户关系。实验结果表明,该算法能够准确描述用户兴趣,提高用户关系预测的准确性。
以上提到的工作都是从某一方面提出的解决问题方法,虽然都能实现,但从问题的全面性考虑,本文针对此问题从多方面综合考虑提出了多态相似度模型。
3相似性计算
研究两个用户之间的兴趣相似性,从背景和微博内容两个方面来考虑,对于背景信息,根据用户u,v的一些属性,分别出它们的相似度,最后通过加权得到背景信息相似度。对于微博内容兴趣相似度,研究两微博文本之间高频关键词术语的相似性。
3.1基于微博背景的相似度
(1)关注列表
通常微博用户都会对他人进行关注,一旦用户对其他用户进行关注,就可以从中获取到用户所关注他人用户的微博内容信息,这相当于用户对其关注用户的微博内容有所感兴趣,因此被关注的用户博文也能反映用户的兴趣。
用户的关注列表体现用户之间的兴趣相似度,比如用户U1关注了NBA球星勒布朗詹姆斯,用户U2也关注了勒布朗詹姆斯,则在一定程度上说明用户U1,U2有着共同的兴趣,他们都喜欢NBA,喜欢篮球。
设用户U1关注的用户集合为S(N1),U2关注的用户集合为S(N2),由关注列表得到的相似度为
simL=[S(N1)?S(N2)S(N1)?S(N2)-S(N1,N2)] (1)
(2)用户标签
新浪微博为用户提供了添加标签的功能,该功能部分可以最多添加10个标签,大多以关键词的形式进行描述。用户可以描述自己的职业,公司,兴趣爱好,其他用户可以根据兴趣爱好找到志同道合的人,用户添加的标签是对自己兴趣爱好的直接描述,用户的标签可能会影响用户的微博内容,因此获取用户的这些兴趣爱好比较方便。根据标签所提供的信息用KL距离来表示两者之间的相似性。距离越大,说明两标签之间的相似度越小。反之,二者相似度越大。
SimT=[i=1TPiulogPiuPiv] (2)
(3)用户转发
用户转发某好友的微博的频率越高,用户与该好友的兴趣相似度越大。通常情况下,如果用户对另一个用户的微博感兴趣,他就会对这个用户的微博进行转发,通过这种方式传递着一种信息,此用户和另一用户有着相同的意见或观点。如果一个用户多次转发另一个用户的微博,说明这两个用户之间可能存在着兴趣上的相似性。如果两个用户之间多次相互转发对方的微博,说明这两个用户之间一定存在着兴趣上的相似性。因此,利用转发提出了用户之间的相似性计算公式。
如果用户U1转发用户U2的微博数量为N1,用户U2转发用户U1的数量为N2,用户U1微博中为转发的数量为D1,用户U2微博中转发的数量为D2,则用户转发相似度为
[SimF=N1*N2D1*D2] (3)
綜合以上信息,最终得到的基于背景的兴趣相似度为
SimB=w1SimL+w2SimT+w3SimF (4)
其中,
W1+w2+w3=1 (5)
3.2基于内容的兴趣相似度
文本内容的相似性在一定程度上反映了两者之间有一定的共同爱好。文本内容通过一定的逻辑关系把一系列术语串联起来,从而形成一篇完整的文本。为了计算微博文本内容的相似度,将基于向量的概念语义相似度方法扩展至文本语义相似度,一般认为,如果两篇文本内容里面的术语概念向量语义相似度越大,那么这两篇文章的内容相关性越强,语义关联也越强。通过计算文本的高频术语相似度来替代两文本内容之间的相似度,计算公式为
SimText=[i=li=ni=lj=mconceptsimilary(Ci,Cj)m*n] (6)
最终根据背景和内容得出用户之间的兴趣相似度为
SimI=αSimB+βSimText (7)
其中,α,β的值各取0.5
3.3个性化微博推荐
一段时间一个用户U的关注用户所发布的最新微博集合为Cnew,对于其中的每个新的微博cnew,计算该用户U对此微博的兴趣度,公式为
InterestLevel(U,Cnew)=[t∈T(Snew*Ut)]· (8)
其中,T是用户所感兴趣的主题集合,Snew为主题分布向量。
当用户的关注用户发布或转发新的微博内容时,对新微博集合按兴趣度的降序排列,将TOP-N个新微薄推荐给用户
4实验
实验数据:
本实验的数据来自新浪微博。数据的获取过程包括采集和筛选两个部分。数据采集阶段,利用数据采集工具获取新浪微博用户的基本信息和内容信息;筛选数据阶段,去除信息缺失严重的无效数据。最后得到169788个用户数据。其中包括微博的个人信息和关注列表数据。在用户个人信息这方面,有职业、年龄、注册时间、兴趣爱好等。本文将利用信息检索领域的评价指标排序准确率作为评价用户相似度的性能。通过用户之间的关注序列,对比用户之间的相似度所产生的相似序列,评价用户之间相似度。
本部分实验采取排序准确率和MAP作为评价指标。排序准确率公式如下
Accuracy=[1|U|u∈U1|F(u)|i=1|F(u)|11+|S(u)_ri-F(u)_ri|] (9)
其中,将U的相似序列S(u)作为待测结果,将U的关注序列F(u)作为标准答案.对于关注序列F(u)中的每个用户i,它在F(u)、S(u)中出现的次序位置分别记为F(u)_ri,、S(u)_ri
MAP=[1|U|u∈U1|D(u)|i=1|D(u)|iS(u)_ri] (10)
(1)基于背景和内容的相似度实验结果
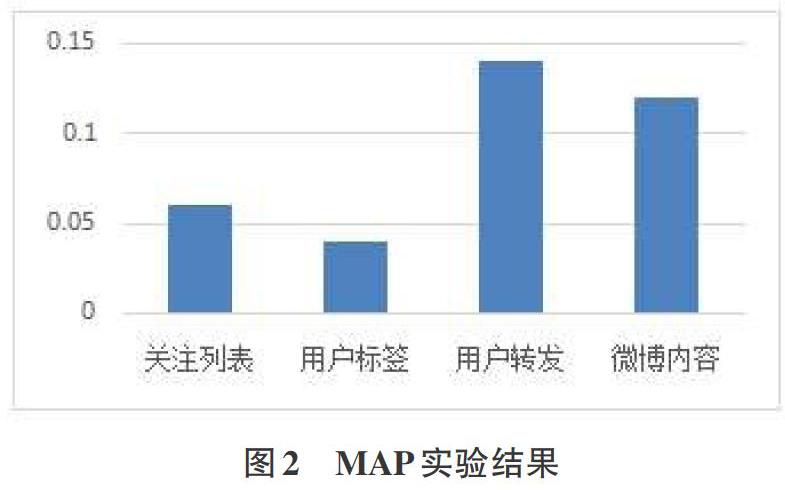
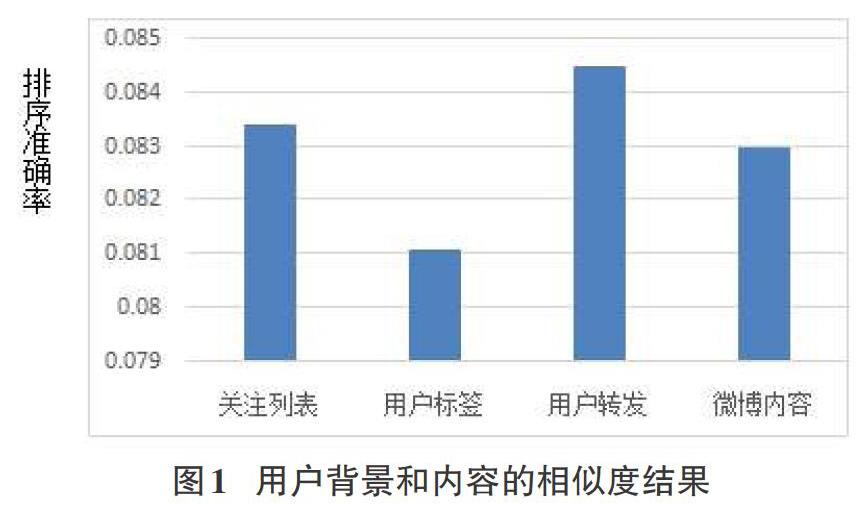
该实验部分是考察微博用户的背景信息和文本内容对用户兴趣相似度的影响。实验内容:首先计算用户的关注列表相似度、用户标签相似度、用户转发相似度,然后将它们加权融合,得到用户的背景信息相似度。通过文本内容关键词的相似性糅合得到内容相似性。最后和背景信息加权得到最终相似性。图1给出了上述各种相似度在排序准确率上的实验结果。实验结果显示:用户转发相似性具有较好的实验效果,综合地看,3种属性信息和文本内容相似度加权融合而成的最终结果效果最好。
从实验结果可以看出:用户标签准确率最低。可能的原因有(1)标签信息的不完整性,用户的标签中涉及用户的个人隐私信息,用户可能不会真正描述自己,或者随意填写,有的甚至不写。用户的转发最能体现用户的兴趣,如果用户对此微博转发说明对微博感兴趣,否则也不会去转发。
通过结果观察,用户之间的微博转发准确率最高,最能说明转发对兴趣相似性的判断所起的作用最大,而关注列表仅次于微博转发,可能只是短暂的兴趣,时间久之,兴趣会发生变化,但变化不会太大。但用户之间共同关注用户的比例较大,也能说明二者具有相同的爱好。
(2)推荐用户的准确率比较
分别应用上述各种相似度,进行用户推荐.图2给出了上述各种相似度在用户推荐上的实验结果。实验结果显示:对于用户推荐来说,用户信息的3种属性信息相比,用户转发相似度取得了最好的推荐效果。
5结束语
本文结合前人研究的基础上,进一步完善了相似度计算的方法。针对多态相似度模型,给出了微博用户的属性信息以及计算方法。在此基础上,完成了微博用户相似度的整体计算方法。最后通过实验来验证他们的性能。
利用微博数据,根据微博用户信息,分别给出了用户属性信息、用户转发、内容的相似度计算方法。
参考文献:
[1] HUANG Xianying ,CHEN Hongyang ,LIU Ying‐tao.Research on Microblog short text similarity and its application in Microblog topic detection[J].
[2] Xu zhi-Ming,LiDong,Liu Ting,et al.Measuring similarity between microblog users and its application[J].Chinese Journal of Computers.2014,37(1):207-218(in Chinese)
[3] HUANG Hongcheng, LU Weijin,et al.User Relationships Prediction Algorithm with Interest Similarity Measurement[J].Computer Science and Exploration.2017,11(7)-1068-12
[4] Wang Xiao-Yu,Xiong Fang,Ling Bo,Zhou Aoying.A similarity-based algorithm for topic exploration and distillation.Journal of Software,2003,14(9):1578-1585(in Chinese)
[5] 邢千里,劉列,刘奕群,张敏,马少平.微博中用户标签的研究[J].软件学报,2015,26(7):1626?1637.
[6] 彭泽环,孙乐,韩先培,石贝.基于排序学习的微博用户推荐[J].中文信息学报,2013,27(4):96?102.
[7] 杨圩生,罗爱民,张萌萌.基于信任环的用户冷启动推荐[J].计算机科学,2013,40(11a):363?366.
[8] 张园美.微博用户兴趣分析方法应用研究[D].大连:大连理工大学,2015.
[9] 李峰,侯加英,曾荣仁,等.融合词向量的多特征句子相似度计算方法研究[J].计算机科学与技术,2017(11).
