
基于机器学习算法的冬小麦不同生育时期生物量高光谱估算
2019-03-15 09:04李映雪张缘园张雪红邹晓晨
麦类作物学报 2019年2期
吴 芳,李映雪,张缘园,张雪红,邹晓晨
(1.南京信息工程大学应用气象学院,江苏南京 210044;2.南京信息工程大学遥感与测绘工程学院,江苏南京 210044)
高光谱遥感具有分辨率高、波段连续性强、光谱信息量大等特点,通过对光谱数据挖掘,可获得较多的植物化学组分、生理生态等参数信息,使其不仅可以用来提高识别作物和植被类型的能力,还可以用来监测作物的长势和反演作物的理化参数。这也促使高光谱遥感技术在农业领域上得到广泛重视。目前,高光谱数据挖掘技术在叶面积指数、生物量、水分和氮素营养的遥感估测等方面已做大量的研究,并在大范围农业资源监测、作物产量预测、农情预报等方面发挥了重要作用[1]。
在农业生态系统中,生物量是表征作物冠层结构的重要参数和作物长势的重要指标,同时也是作物产量估算的重要依据。黄春燕等[2]认为,基于棉花在敏感波段构建的光谱参数,可定量估算棉花地上部鲜生物量。 贺 佳等[3]发现,在拔节期、孕穗期、抽穗期、灌浆期、成熟期可以用GNDVI、RVI、MSAVI、RTVI和MTVIⅡ有效监测冬小麦生物量。作物生物量的实时、动态监测对农业生产管理具有重要的意义。
生物量的估算大多基于遥感数据。Prasad[4]用窄波段归一化植被指数分别建立棉花、马铃薯、大豆和玉米的鲜生物量模型,解释了不同作物64%~66%变量的生理变化。Hanson等[5]研究表明,NDVI与冬小麦绿色生物量的指数关系最佳。陈鹏飞等[6]认为,红边三角植被指数RTVI是估测作物冠层生物量的最好指标。近年来,很多学者用机器学习算法建立农作物的遥感估测模型[7-8]。其中随机森林(RF)算法是由Breiman[9]于2001 年提出的一种预测具有较高准确率的分类、回归算法,其对异常值和噪声具有较好的容忍度,对高光谱遥感等高维度数据训练和学习效果较佳,近年来被应用于多个领域[10]。王爱丽等[11]使用随机森林回归算法构建小麦叶片SPAD值遥感反演模型;程立真等[12]建立基于高光谱数据的磷素含量随机森林模型,对苹果磷素营养状况进行估测。RF回归算法应用于作物生物量监测方面的研究较少[13-14],也少有针对作物不同生育时期来建立植被指数与生物量之间的随机森林回归模型。
本研究利用2011-2014年冬小麦抽穗期前、抽穗期、开花期和灌浆期的生物量值和同步获取的高光谱数据,分析了8种常用的植被指数与冬小麦生物量的相关性。以冬小麦生物量为因变量,8个植被指数为自变量,采用随机森林算法(RF)、支持向量回归(SVR)和偏最小二乘算法(PLS)针对冬小麦生长的4个生育时期,分别构建生物量估算模型。通过对3种机器学习算法在冬小麦不同生育时期估算生物量的精度和稳定性分析,探索适用于冬小麦不同生育时期的高光谱估算方法,以期为实现冬小麦生物遥感监测提供技术和方法。
1 材料与方法
1.1 研究区概况
本研究区位于南京信息工程大学农业气象试验站(118°7′E,32°2′N),属于亚热带季风气候,无霜期237 d,年平均降水量1 106.5 mm。试验田前茬为水稻,土壤为黄棕壤土,2010年试验前观测的土壤有机质含量为1.89%,全氮0.07%,速效磷15.08 mg·kg-1,速效钾174.65 mg·kg-1,碱解氮80.275 mg·kg-1。试验田一共划分为18个小区,每个小区面积为9 m2(3 m×3 m),基本苗为2.0×106个·hm-2,行距25 cm。设3个施氮水平,分别为0、150、300 kg·hm-2(分别用N1、N2、N3表示)。氮肥60%作基肥,40%作拔节肥。每小区基施P2O5150 kg·hm-2和K2O 150 kg·hm-2。本研究一共进行了4个田间试验,涉及4个年份,每年2个冬小麦品种,其中2010-2011年度供试冬小麦品种为徐麦31和宁麦12,2011-2012年度为扬麦13和镇麦168,2012-2013年度为扬麦13和扬麦16,2013-2014年度为扬麦13和宁麦13。
1.2 数据获取
1.2.1 冬小麦冠层高光谱测量
光谱仪选用美国ASD公司生产的FieldSpace 3,其光谱范围为350~2 500 nm,其中,350~1 000 nm波段的采样间隔为1.4 nm,1 000~2 500 nm波段的采样间隔为2 nm,视场角是25°。选择晴朗无风无云的天气,于上午10:00到下午14:00时间段,分别在抽穗期前、抽穗期、开花期和灌浆期测量冬小麦的冠层光谱反射率,每项光谱测量重复3次,求平均值,每次数据采集前都进行标准白板校正(标准白板反射率视为1,这样所测得的目标物光谱是无量纲的相对反射率)。
1.2.2 冬小麦生物量获取
每次测量光谱后,在相应的样区进行实地采样,在实验室将冬小麦叶、茎分离,分别测鲜重和干重,然后分别计算各生育时期冬小麦的生物量。
将4年的数据按生育时期分别集合在一起,按7∶3的比例分为2部分,其中70%的数据作为训练样本用来建模,30%的数据作为测试样本用来评价模型。抽穗期前、抽穗期、开花期和灌浆期的训练样本分别是63个、50个、63个和50个;测试样本则分别为27个、22个、27个和22个。
1.2.3 光谱指数的计算
光谱数据可以构建许多对植株相对敏感的植被指数,本研究选取了表1中所示的与生物量相关性较高的高光谱指数,用来进行生物量的估测。

表1 与生物量相关性较高的光谱指数Table 1 Higher spectral index associated with biomass
1.3 随机森林(RF)回归算法
RF实质是包含多个决策树的分类器,它是利用多个决策树算法对相同现象做重复的预测[23]。每一个决策树是由叶子节点和分叉组成,在生成树的时候,系统会随机生成每棵树的每个节点,然后每个节点再进行分叉形成多个决策树,所以称为“随机森林”[24]。建立随机森林过程就是寻找叶子节点过程,用随机森林算法做回归,来算出因变量的预测值。RF算法的具体过程是:
(1)从原始样本集中使用Bootstraping方法随机抽取n个训练样本,然后进行k轮抽取,得到k个训练集,并且k个训练集之间相互独立,元素可以有重复。
(2)对于这k个训练集,可以建立k个训练模型,并且可根据具体问题而定,比如决策树等。每棵树自顶向下递归分枝,并遵循分枝优度准则,直到满足分割终止条件。
(3)对于回归问题,由k个模型预测结果的均值作为最后预测结果(所有模型的重要性相同)。
1.4 数据分析与利用
在EXCEL中计算表1中的光谱植被指数。将冬小麦4年数据的训练样本分为抽穗期前、抽穗期、开花期和灌浆期,利用SPSS分析冬小麦各生育时期的生物量与光谱植被指数之间的相关性,在Matlab中编程实现RF算法、SVR算法和偏最小二乘(PLS)算法。基于每种算法,分别建立4个生育时期的4种回归模型,用拟合的决定系数r2和均方根误差RMSE作为评价指标,评价每个模型的适用性能。为检验模型的预测能力,利用划分的预测样本,将模型预测值与生物量实测值进行回归拟合并绘制1∶1关系图,比较每个生育时期3种算法模型的预测能力。
2 结果与分析
2.1 冬小麦生物量与光谱植被指数的相关性
将选取的表1中8个植被指数与冬小麦实测的生物量进行相关性分析。结果(表2)表明,抽穗期、开花期和灌浆期的冬小麦生物量与8个植被指数均存在极显著相关关系;在抽穗前期,除WII和NDMI外,其余6个植被指数与冬小麦生物量有极显著相关性。因此,可以用这8个植被指数建立回归监测模型。
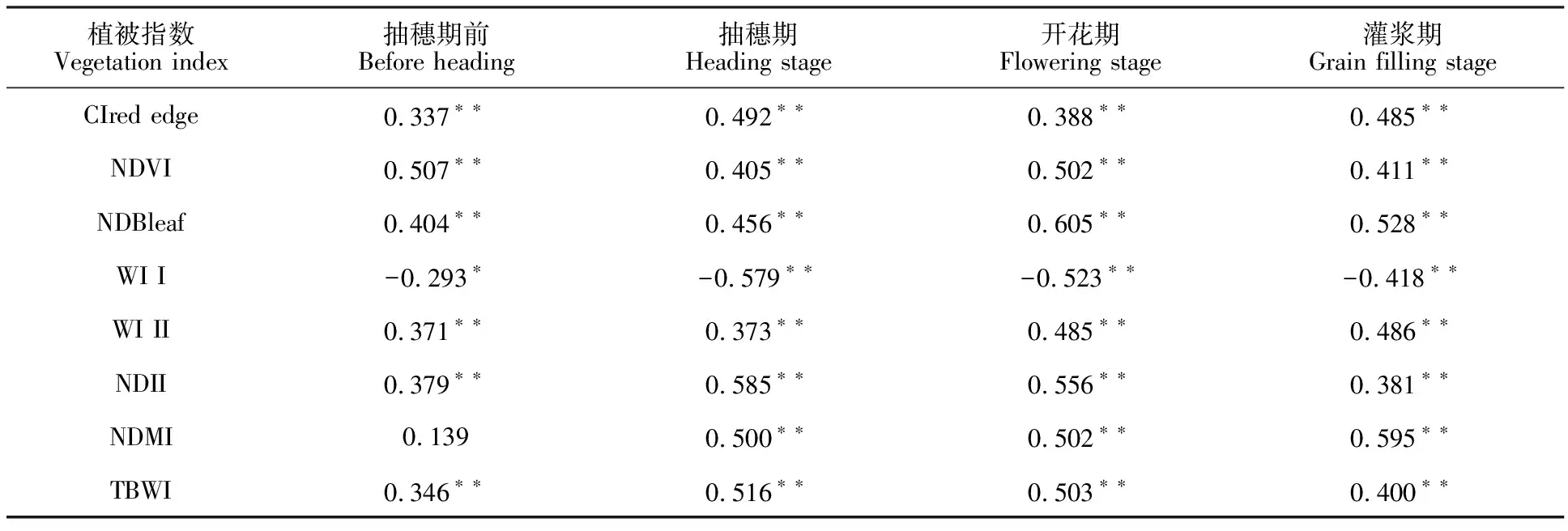
表2 冬小麦生物量与光谱植被指数间的相关性Table 2 Correlation between winter wheat biomass value and spectral vegetation index
*:P<0.05; **:P<0.01.
2.2 冬小麦生物量遥感监测模型的构建
基于以上的相关性分析结果,以冬小麦生物量作为因变量,以表1中的8个植被指数作为自变量,采用随机森林回归算法、支持向量回归算法和偏最小二乘回归算法分别构建冬小麦4个生育时期的生物量高光谱估测模型RF-biomass、SVR-biomass和PLS-biomass。
构建RF模型时,经过参数优选和多次训练,确定4个生育时期中决策树均为2 000,节点处的变量数均为3。
构建SVR模型时,通过对不同类型及核函数的SVM学习算法进行比较,选择了最优的径向基函数(RBF),需要优化该算法的2个参数即惩罚系数c和核函数参数g。用交叉验证法和网格搜索法确定最优参数(表3)。
构建PLS模型时,通过交叉有效性分析确定,开花期的最佳成分个数为2,其余3个生育时期的最佳成分个数为3。

表3 SVR算法参数Table 3 SVR algorithm parameters
2.3 模型适用能力和预测能力的比较
以r2和RMSE为依据,比较3种模型的适用能力和预测能力。结果(表4和图1~图4)相关表明,这三个模型中冬小麦生物量实测值和模型预测值都相关极显著,其中评价指标r2和RMSE结果也是较为理想,说明可以用这三个模型来估测冬小麦生物量。综合考虑,当r2最大且RMSE最小时可作为冬小麦生物量监测的最佳模型。对于模型的适用能力,RF-Biomass模型在每个生育时期r2都超过0.7,均高于另外两个模型,并且RMSE也是低于或接近于另外两个模型。对于模型的预测能力,由表5可知,RF-Biomass模型的r2均在0.6以上,抽穗期前、抽穗期和开花期RF-Biomass模型的r2均最大,同时相应的RMSE均最小,那么RF-Biomass模型可作为这三个生育时期监测的最佳模型;灌浆期,SVR-Biomass模型的r2最大且相应的RMSE最低,此模型可作为该生育时期的最佳模型。结果还表明,RF-Biomass模型在每个生育时期的预测能力相比于适用能力都稍低,可能是因为随机森林算法生成树的时候出现一些差异较小的树,影响了部分决策。

表4 冬小麦生物量值估算模型比较Table 4 Comparison of winter wheat biomass estimation models
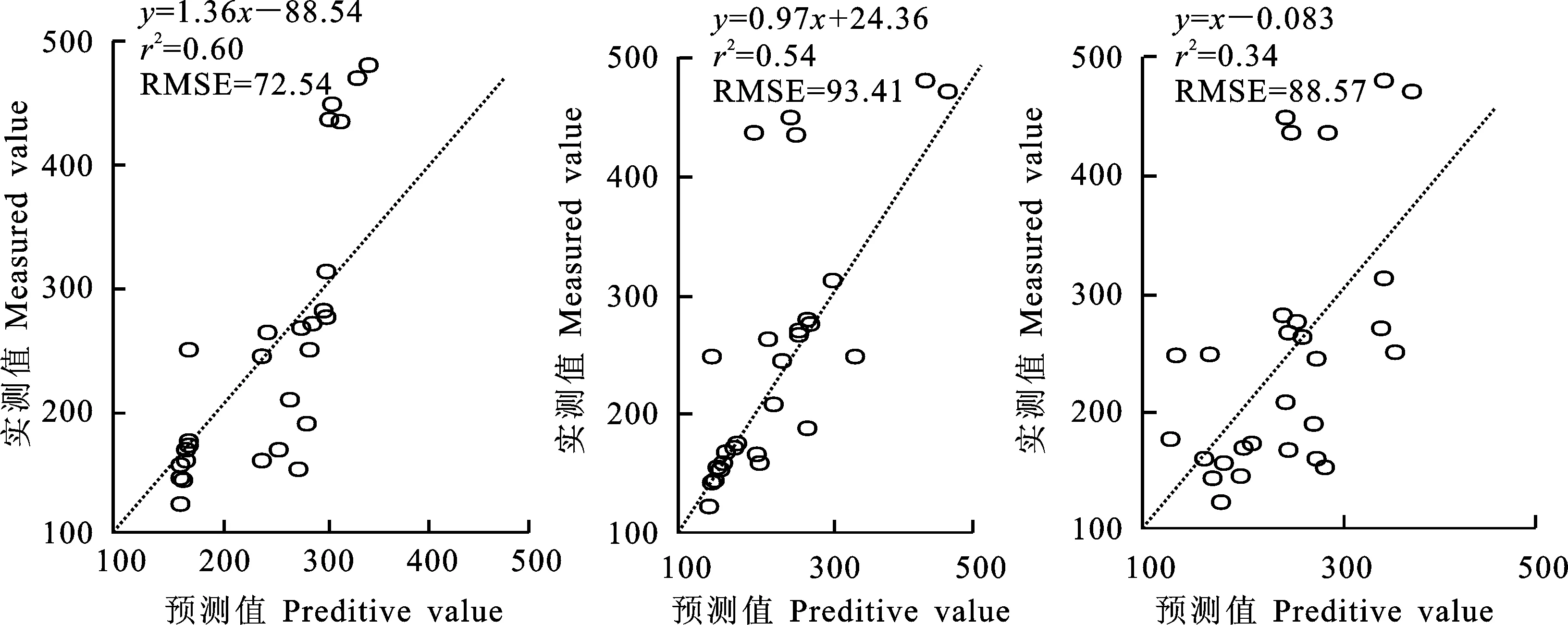
图1 抽穗期前冬小麦生物量实测值与模型预测值关系Fig.1 Relationship between measured winter wheat biomass and model prediction before heading date

图2 抽穗期冬小麦生物量实测值与模型预测值关系Fig.2 Relationship between measured biomass values and model predictions at heading stage of winter wheat
总之,RF-Biomass模型与另外两个参比模型想比,反演得到的冬小麦生物量预测值也较为理想,适用能力和预测能力均较好,可用来监测冬小麦生物量。

图3 开花期冬小麦生物量实测值与模型预测值关系Fig.3 Relationship between measured values of biomass and model prediction at flowering stage of winter wheat

图4 灌浆期冬小麦生物量实测值与模型预测值关系Fig.4 Relationship between measured biomass values and model predictions at grain filling stage of winter wheat
3 讨 论
农作物生物量在不同生育时期、不同营养状况条件下存在差异,并且冠层结构和作物叶片生理生化参数的季节性变化[25]也会引起冠层光谱反射率的变化,导致光谱反射率对作物参数的敏感性在不同的生育时期存在差异[26-27],进而基于植被光谱指数构建的估算模型会受到作物生长状况和环境的影响,造成多个生育时期遥感估算作物参数存在困难,并且不同的研究人员构建的模型往往不一致[3,13],这些因素导致了高光谱遥感估算模型精度不高。
植被指数在估算作物参数方面存在饱和问题,单纯的植被指数法在生物量估算时往往造成较大误差[13],因此许多学者尝试利用机器学习算法估算作物生物量,如支持向量回归、偏最小二乘、神经网络等算法[7,8,28]。但针对于冬小麦不同生育时期构建高光谱估算模型的研究却十分有限。为了构建适用于冬小麦不同生育时期的高光谱估算模型,本研究采用的是随机森林(RF)回归算法与植被指数相结合,在Matlab软件中编程实现对冬小麦生物量的估测,同时与支持向量回归和偏最小二乘回归这两种算法进行比较,表明可以用RF回归算法构建冬小麦生物量的高光谱遥感估测模型,模型训练集的预测值与实测值之间的拟合r2和RMSE在抽穗期前分别为0.79和44.82 g·m-2,在抽穗期分别为0.71和62.07 g·m-2,在开花期分别为0.70和97.63 g·m-2,在灌浆期分别为0.71和106.98 g·m-2;模型预测集的预测值与实测值之间的拟合r2和RMSE在抽穗期前分别为0.60和72.54 g·m-2,在抽穗期分别为0.60和75.07 g·m-2,在开花期分别为0.68和109.9 g·m-2,在灌浆期分别为0.61和127.93 g·m-2。三种方法比较,RF算法对冬小麦生物量的预测能力高于或接近于SVR算法,高于PLS回归算法。随机森林算法在4个生育时期均表现出很好的稳定性,预测精度r2都在0.6以上,这与Wang等[29]对冬小麦生物量的估算研究精度一致(针对不同生育时期r2在0.6~0.7之间)。虽然,目前还不能实现对冬小麦生物量的高精度估算,但用RF回归算法遥感监测冬小麦生物量值,在精度上还有很大的提升空间,可进一步优化模型做到更加精确,满足农业生产需求,为冬小麦精确管理提供基础信息和技术支持。
RF回归算法优势在于有较强的抗噪音和快速运算能力,而且不容易过度拟合;而SVR算法关键在于核函数,由于确定核函数的已知数据存在一定的误差,且引入松弛系数和惩罚系数两个参变量也有限制,此算法在应用上具有一定的局限性,PLS回归算法用于建立预测模型的得分因子之间必须线性无关,而且需要降维,会损失点数据信息。因此,优选RF回归算法来构建冬小麦生物量的高光谱遥感估测模型。
如今,算法用来遥感建模已炙手可热,选择一个合适的算法,有利于遥感估算精度的提高。本文利用RF回归算法建立用光谱植被指数反演冬小麦生物量的模型,从抽穗期前、抽穗期、开花期和灌浆期4个生育时期分别反演,能够很好地反映整个研究区域小麦的生长状况。但RF算法是否和其他算法一样,适用于其他作物的其他长势参数的反演,需要进一步的研究与验证,从而来提高RF算法在农业遥感监测中的应用价值。
猜你喜欢
中国农学通报(2022年29期)2022-11-25
今日农业(2022年4期)2022-06-01
农业灾害研究(2022年1期)2022-05-07
草业科学(2022年3期)2022-03-26
少儿科学周刊·儿童版(2021年21期)2021-12-11
农业机械学报(2021年8期)2021-08-27
今日农业(2021年4期)2021-06-09
现代农业科技(2018年22期)2018-01-15
绿色科技(2017年7期)2017-05-12
江苏农业科学(2016年12期)2017-04-05
