
基于随机森林的藏文文本分类
2019-03-04 11:05包晗西热旦增郭龙银尚慧杰
电脑知识与技术 2019年34期
包晗 西热旦增 郭龙银 尚慧杰


摘要:针对藏文文本及其语法和词法结构,采用条件随机场进行分词,利用人工统计和标注进行停用词词典建立,然后采用tf-idf的词向量空间,予以权重计算,最后采用随机森林算法構建分类器,进行文本分类。并使用查全率、查准率和F1值三种评价函数与逻辑回归、多项式朴素贝叶斯、支持向量机三种算法相比,结果显示,随机森林算法在高维特征的藏文文本分类上优于其他分类器。
关键词:藏文;条件随机场;TF-IDF;随机森林;文本分类
中图分类号:TP391
文献标识码:A
文章编号:1009-3044(2019)34-0178-03
随着藏语言在互联网的传播,藏语语言信息数据及资源呈现海量特征,而研究藏文文本分类可有效管理和利用这些海量信息。其中,文本分类(textcategorization,简称TC)技术是信息检索和文本挖掘的重要基础,其中主要任务时在预先给定的类别标记(label)集合下,根据文本内容判定它的类别1。藏文文本分类目前还处于统计学习和深度学习的过渡阶段,尤其是在藏文文本数据语料不庞大和标注程度深度不够的前提下,随机森林(Random Forest)算法能够处理高维特征的输入样本,且不需要降维处理。
1 藏文文本分词
藏文自动分词可以看作是计算机自动辨识藏文文本字符流中的词,并在词与词之间加入明显的词切分标记符的过程2目前,已有多种分类方法,例如:最大匹配算法3、基于格助词和接续特征的书面藏语自动分词-等,在比较多种分词方法后,确定以洛桑嘎登的基于知识融合的条件随机场s进行藏文分词。
x为音节,ξ为阈值,第一种为黏着词、歧义词等音节组合规则库建立,第二种为人名、地名、非藏文字符等固定音节规则库。最后统计和人工筛选出最终的库的元素,将阈值极高的元素在分词之间先行筛除,其余元素在分词中将阈值与条件随机场输出比较。
2 tf-idf特征提取
2.1 文本向量空间模型
向量空间模型(VSM)6由哈佛大学的G Salton提出,是基于统计的代数模型。文本向量空间模型(TVSM)则是拟定一个向量空间概念,将文本中的每一个词转换为空间的不同维度,文本的表达与向量之和相似,形成一个在高维度上的带方向的点,而一个词的权重即是该点在对应维度上的绝对值。一个文本的表达式为:
在文本向量空间模型中,单个文本的维度一般在百维至千维以上,高纬度的文本所包含的内容更为丰富,词与词之间的联系也更为紧密,允许文本分类的种类更为多且层次更深。
2.2 tf-idf特征提取
Trf-idf(Term-frequency times inverse document-frequenry)词频乘以逆文本频率,公式:
tf(t,d)为词频函数,表示某个藏文词在一个文本中出现的次数,他和文本越相关,则在文本中出现的次数越多。但在大型语料库中,一些许多特定的词出现的频率极高,例如藏语中的连接词等,他们不具有分类特征,会影响分类器的判断,我们应当在构建词频矩阵前排除。
idf(t)为逆文本频率函数,表示某个藏文词在某文本类别的影响频率,即该词在某个类别出现的频率越高而在其他类别出现的频率越低,则该词对某类别的分类影响程度越高,公式6:
其中n是语料集中所有文本数,d (t)是语料集中拥有t维度的所有文本数。
Ridge回归,使用Frobenius范数,将单文本中所有的tf-idf值进行回归,最终将所有文本转换为多维浮点数矩阵,公式为:
3 随机森林分类器
3.1 决策树
决策树是将文本中的词作为节点,计算该词加上所有父节点构成的词序列对某一类别的分类误差率,设立阈值,根据阈值判别产生不同的子节点,循环此过程,直到阈值为0或无子序列。决策树主要分三个步骤:特征选择、决策树生成、剪枝。
特征选择,本文采用CART算法来进行特征选择,CART(Classification And Regression Tree)。是Breiman等人在1984年提出的,是一种二分决策树,它判别规则是要么为某一类,要么就是其他类,它使用基尼系数(Gini)来对二叉树的节点进行选择。Gini系数的公式:
决策树生成,即决策过程,根节点为特定的词序列,即只有一个词,该词在所有词中分类误差率最好,对某一个类别概率最大。随后的子节点依据上一个判定划分成左右两个子树,若基尼系数不为零或者词序列无子序列则停止决策,若不为零且不唯一,则在可能的类别里继续决策。具体决策树如图1所示(该决策树仅演示所用,取少量数据构建的部分子树)。
剪枝,裁剪决策树的一些子树并将该子树作为叶节点。决策树有时会根据所有训练样本的形成一个非常庞大的决策树,在训练样本上准确率很高而对于测试样本准确率往往不理想,形成过拟合现象。过拟合现象的解决方式需要人工的观察和调试,观察和控制每一层决策树大小,设置最小叶节点的样本个数,调整叶节点的最小权重等等。
3.2 随机森林
随机森林( RandomForest),是在bagging算法8基础上更进一步。
bagging算法是从所有文本中重采样出n个文本构建分类器,然后重复m次此过程获得m个分类器最后根据这m个分类器的投票结果决定文本属于哪一类。随机森林不需要交叉验证,步骤如下:
其中I(.)是示性函数,avk表示取平均值,边际函数表示了在正确分类Y之下X的得票数目超过其他错误分类的最大得票数目的程度。边际函数可有效地展示随机森林的决策树组合效果,此外还可以根据边际函数进行决策树的n文本个数的调整,决策树中词数的调整以及分类的组合方式。
4 实验结果
本文的数据集的文本总数为12090篇,共分为10个类。分别為:艺术、文化、教育、历史、哲学、科技、体育、政治、经济、自然。文本分布如图2:
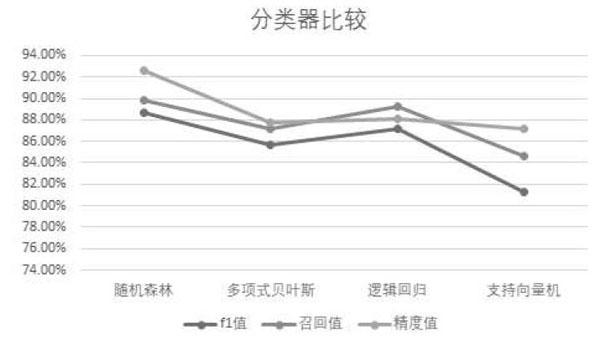
本文为了快速比较四种算法的效果,采用scikit_learn7的skleam. naive_bayes. MultinomiaINB, sklearn. linear_model. Logisti-cRegression,sklearn.svm作为多项式贝叶斯算法、逻辑回归算法、支持向量机算法的分类器。根据精度值(precisionscore),召回值(recallscore),fl值(fl score)对比效果,如图3所示。
结果显示随机森林分类器的效果要优于其他分类器。
5 结束语
本文从分词到最终的文本预测,完成了基于随机森林的藏文文本分类的全部任务。实验结果显示文本分类效果良好,且相比于多项式贝叶斯、逻辑回归、支持向量机效果更为优秀。但进步空间仍然很大,1)应该扩充语料库为大型语料库进而再做测试,在大型语料库上单一的统计算法分类器不能很好地满足分类需求,要构建多种算法加权预测。2)分类效果上还有上升空间,且目前深度学习研究前景更好,我们应该将统计算法与神经网络相互融合,从而提高分类效果。
参考文献:
[1]苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展[J].软件学报,2006(9):1848-1859.
[2]茂松,邹嘉彦.汉语自动分词研究评述[J]当代语言学,2001,3(1):22-23.
[3]罗秉芬,江荻.藏文计算机自动分词的基本规则[C]//中国少数民族语言文字现代化文集.北京:民族出版社,1999.
[4]陈玉忠,李保利,俞士汶,等.基于格助词和接续特征的藏文自动分词方案[J].语言文字应用,2003(1):75-82.
[5]洛桑嘎登,杨媛媛,赵小兵.基于知识融合的CRFs藏文分词系统[J].中文信息学报,2015,29(6):213-219。
[6] Salton G,Wang A,Yang C S.A vector space model for automat-ic indexing[J]. Communication of the ACM, 1975, 18(11):613-620.
[7] https://scikit-leam.org/stable.
[8] Breiman J. Bagging predictors[J]. Machine Learning, 1996, 24(2):123 -140.
【通联编辑:唐一东】
收稿日期:2019-08-15
基金项目:2018年大学生创新创业训练计划项目“基于随机森林的藏文文本分类”(项目编号:2018XCX045)
作者简介:包晗(1998-),男,浙江丽水人,本科;通信作者:西热旦增(1989-),男,西藏那曲人;郭龙银(1997-),男,江西九江人,本科,主要研究方向为自然语言处理;尚慧杰(1996-),女,河南周口人,本科。
猜你喜欢
布达拉(2020年3期)2020-04-13
西夏学(2019年1期)2019-02-10
计算机应用(2016年12期)2017-01-13
南水北调与水利科技(2016年6期)2017-01-06
西藏大学学报(自然科学版)(2016年1期)2016-11-15
新闻传播(2016年17期)2016-07-19
