
作者关键词集的文献计量分析*
——以图情学科为例
2019-03-02 07:46王婧怡
图书情报研究 2019年1期
袁 润 李 莹 王婧怡
(江苏大学科技信息研究所 镇江 212013)
1 引言
关键词最初特指单个媒体在制作使用索引时所用到的词汇。关键词是学术论文不可缺少的组成部分,是论文主要内容的浓缩,是作者精炼出的概括论文主题的词汇。通过关键词,读者可以迅速地了解论文的主要内容。
基于关键词集的文献计量能够为图书馆参考咨询服务提供帮助。陈卫静等学者[1]认为“一个学术研究领域较长时域内的大量学术研究成果的关键词集合,可以揭示研究成果的总体内容特征、研究内容之间的内在联系、学术研究的发展脉络与发展方向等”。随着文本挖掘技术的逐渐成熟,文献计量研究正在向以文献中知识元为基本单位的方向发展[2]。例如,通过作者学术论文关键词集的文献计量分析可以探究作者的研究主题,可以挖掘学者的研究兴趣和专长,可以揭示作者之间潜在的合作关系,可以帮助学者寻找最佳的学术研究合作对象,还可以根据学者之间合作的可能性,预测该学科领域未来的合作趋势。
本文通过梳理“学科-期刊-文献-作者-关键词集”的逻辑关系,采集了图情学科18种CSSCI期刊近10年(2007~2016)以来的论文题录数据形成数据集,再按作者提取关键词,并称之为作者关键词集,以此作为分析单元,通过词频分析、相似性比较、关键词共现等文献计量方法,探索作者关键词集的文献计量特征,对发展词频分析理论具有一定的学术意义;利用R语言编程技术创建作者关键词共现网络,计算网络特征参数,构造作者关键词集的特征“画像”,为这一层面的知识挖掘提供一个崭新视角,对发展文献计量方法具有一定的参考价值;同时,将关键词集转换成更有价值的量化信息和可视化图形,能客观、形象地展示作者的研究主题或方向,发掘作者的研究兴趣或专长,为图书馆“用户发现服务”提供一些有价值的量化信息,对知识发现服务具有一定的应用价值。
2 数据获取与处理
本文选择了题名、作者、机构、期刊、关键词、基金、年度等7个字段采集数据,在整体分析作者发文情况的基础上,选择了若干作者开展关键词的词频分析、相似性分析和共现网络分析,数据获取与处理步骤如下。
第一步,检索论文。本文以CNKI为检索数据源,按照期刊名称和年代检索,获取了2007年至2016年全部论文数据,其结果保存到Excel表格,共计得到180张数据表。
第二步,创建数据集。在R语言环境下,通过编程循环读取每一张Excel数据表,全部数据保存到数据框paper.dat中,共计得到53 397条记录,即10年的发文总量。
第三步,创建作者数据子集。CNKI数据库将每篇论文的多个作者或者多个关键词用“;”分隔,所以需要采取以下步骤从paper.dat中提取并分离数据。①用strsplit函数拆分AU字段;②用unlist函数将拆分结果转换成字符串;③用data.frame函数将字符串转变成数据框;④用table函数将数据框结构转换成作者频数表;⑤用sort函数按照作者频数从高到低排序;⑥排序结果存储在数据框dataset.authors中。R语言代码如下,作者发表论文数量排名前100位的统计情况如表1所示。
aus 〈- data.frame(unlist(strsplit(paper.dat$AU,";", fixed = TRUE)))
dataset.authors 〈- data.frame(sort((table(aus)),decreasing = TRUE))
为了更丰富公司的营销体系,南通鹏越纺织有限公司应不断着眼公司的直复营销,优化促销策略。构建更及时、更直接和更完善的人员推销体系,公司与联络点建立更加完善便捷和及时的联络沟通体系。更为重要的是,面对互联网技术的竞争规则和营销手段,南通鹏越纺织有限公司应紧跟时代步伐,探索网络营销新模式。
类似地,按照这种方法还可以创建关键词数据子集、作者单位数据子集、期刊名称数据子集等。18种期刊10年的数据集中一共采集到62 404个关键词,31 277个作者和16 343个作者机构(包含机构的二级单位)。表1列出了本学科的高产作者,本文主要针对这些作者开展了进一步的作者关键词分析。
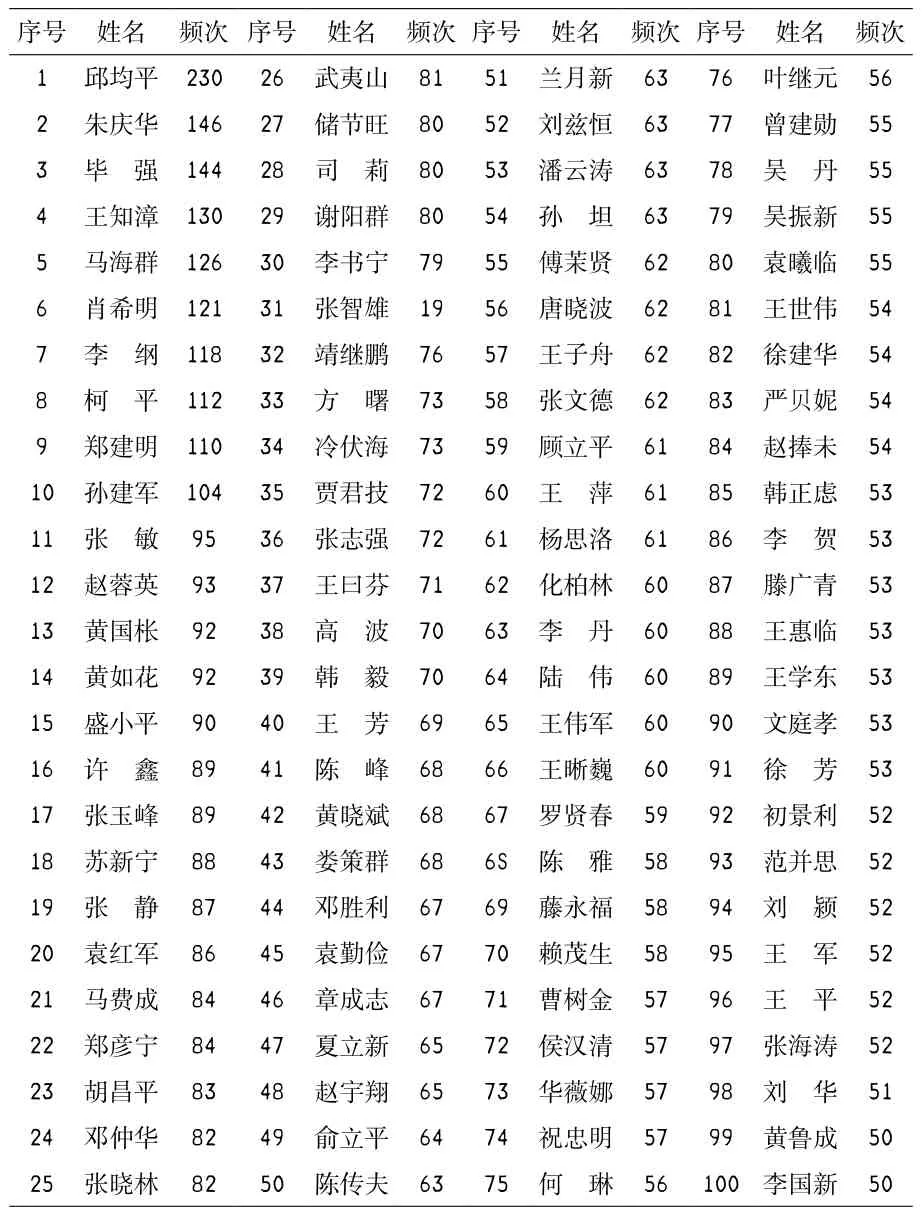
表1 作者发表论文情况统计表(TOP100)
3 作者关键词集的词频分析
关键词词频分析是文献计量的一种重要方法。本文以作者、论文总量、关键词种数、关键词总量、低频词占比、中频词占比、高频词占比、Top5关键词等指标进行分析。
统计发现,作者关键词中超过80%的关键词词频为1,本文称这类关键词为低频词,将词频为2~5的关键词称为中频词,将词频大于等于6的关键词称为高频词。将作者关键词词频从高到低排序,排在前5的称为Top5关键词。论文总量排序前10的作者关键词统计情况如表2所示。表2中KF1表示词频等于1的关键词占比,KF6表示词频大于等于6的关键词占比。
以邱均平教授为例,在2007~2016这10年当中,他在图情学科的18种CSSCI期刊中总计发表论230篇,这些论文包含关键词总量(有重复)为1 041个,篇均4.5个,关键词种数(不重复)587个。该作者关键词的低频词占其全部关键词的71.72%,表明有71.72%的关键词只出现过一次。中频词占关键词集的23.85%,高频词占关键词集的4.43%。
为了直观地揭示作者关键词词频分布,绘制了从KF1~KF6的作者关键词词频占比箱线图,如图1所示。
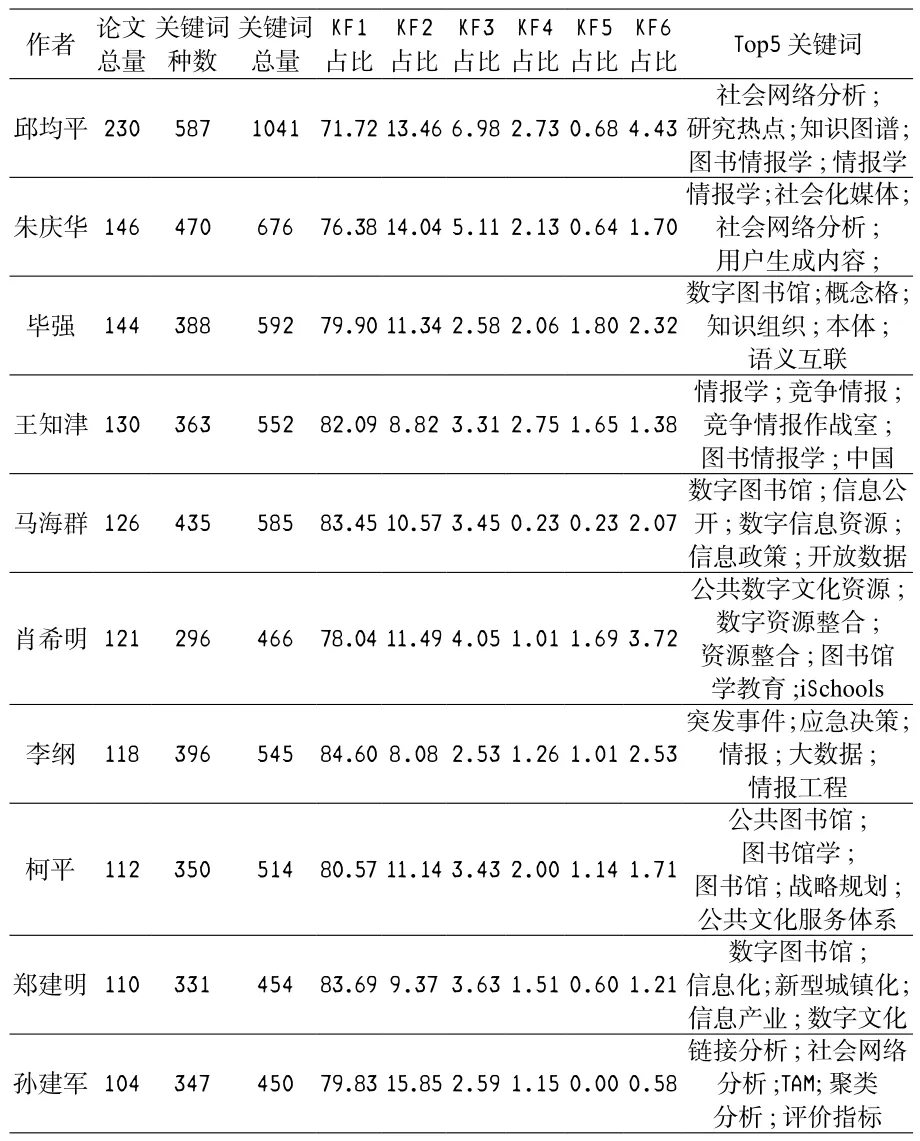
表2 作者关键词集统计表(TOP10)
图1表示作者关键词词频占比的分布情况。总体而言,低频词占比偏高,高频词占比较低,表明作者关键词分布具有较大的分散性,既反映了作者在技术革新、知识创新的实践中,善于使用新的词汇表达新理论、新技术、新成果,也反映了作者在发表论文时选择关键词的随意性或者不规范性。这一点也反映了论文作者的学术规范意识不强,对关键词标准化的重要性认识不足。此外,期刊编辑也没有能够从学术规范的角度对投稿论文的关键词进行审查把关,导致关键词标引比较混乱。
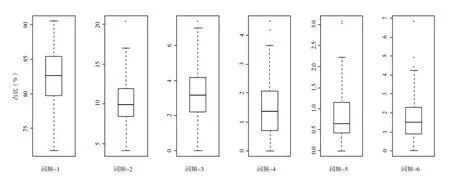
图1 作者关键词词频分布
选择规范的关键词有利于文献检索,从而有利于文献传播。学术论文撰写的规范化和标准化有利于准确表达科学研究的内容和结果,同时,也能够培养学者严谨的治学态度,有利于文献信息的储存、检索、传播和利用,更有利于学术交流[3]。学术论文一经刊载,就表明其内容被同行认可,就会成为专业人员和其他研究者引用和效仿的范例,因此,必须加强对学术论文中关键词的规范化建设[4],最好能够对照《汉语主题词表》或其他词表,找出相对应的主题词,将这个主题词用作关键词来标引[5]。
4 作者关键词集的相似性比较
罗式胜[13]提出了科学文献关键词链的概念,认为如果两篇(或多篇)科学文献有一个(或多个)相同的关键词,则这两篇(或多篇)文献或其相应著者之间则必然存在一种潜在的关系。刘志辉[12]等认为作者-关键词耦合分析是利用作者作品的关键词耦合强度建立作者之间的关联关系,以两个作者拥有相同关键词的数量可以测度作者研究领域相似度的文献计量方法。李纲[14]等尝试从作者合著网络中的微观个体角度出发,提出利用作者关联关键词集来衡量作者研究兴趣的相似性。陈卫静[15]等采用TF-IDF的关键词加权方式,对现有关键词耦合强度的计算方法进行改进,以求更加准确地挖掘科研人员之间潜在的合作关系。
目前,较多的研究者利用关键词、引文等文献计量单元,借助信息计量学的相关方法来研究学者的研究兴趣,这为本文的研究提供了理论支持。因此,本文做出以下假设:作者关键词集可以表征作者的研究兴趣。如果一个作者的关键词集代表该作者的学术研究兴趣,那么若干作者关键词集之间重合的部分,一定程度上反映其共同的研究兴趣,代表研究的相似性。反之,除去这一部分就是作者各有的关键词集,代表研究兴趣的差异性。将不同作者关键词构建成一个作者关键词集,通过作者关键词集来量化和表征作者研究兴趣,利用Jaccard公式进行相似性的计算挖掘出作者间的间接关联关系。
Jaccard系数又叫Jaccard相似性系数,是用来比较评价对象特征集合的相似性和分散性的一个指标,它等于两个评价对象的特征集交集与特征集并集的比值。计算作者关键词集的Jaccard系数,取值范围为[0, 1],用于度量两者的相似性,取值越大相似性越高。计算Jaccard相似度需要两两对比,结果是一个对称矩阵。图情学科高产作者之间的关键词集相似度如表3所示,绝大多数作者之间的相似性较低。
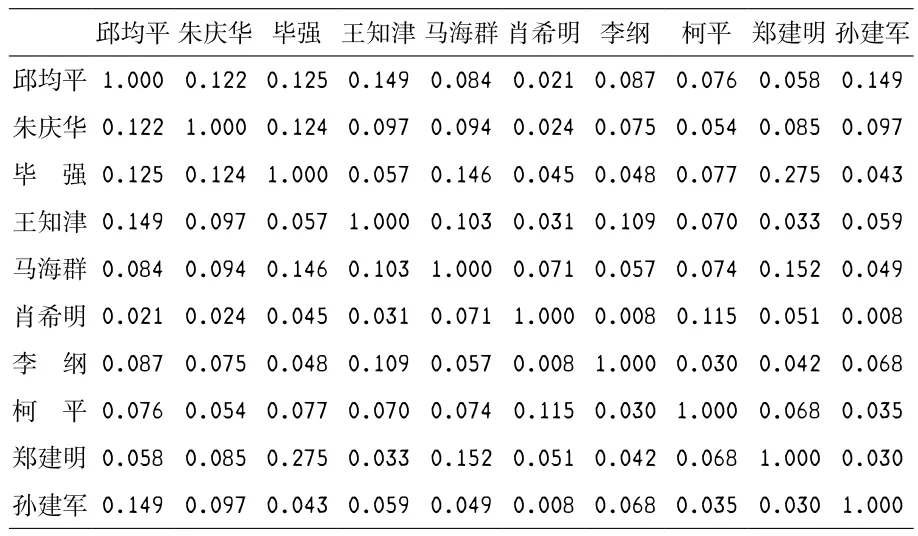
表3 作者关键词集的相似性(TOP10)
表3的网络结构如图2所示。将作者视为网络节点,作者关键词的相似度视为节点之间的关系,相似度越大线条越粗。
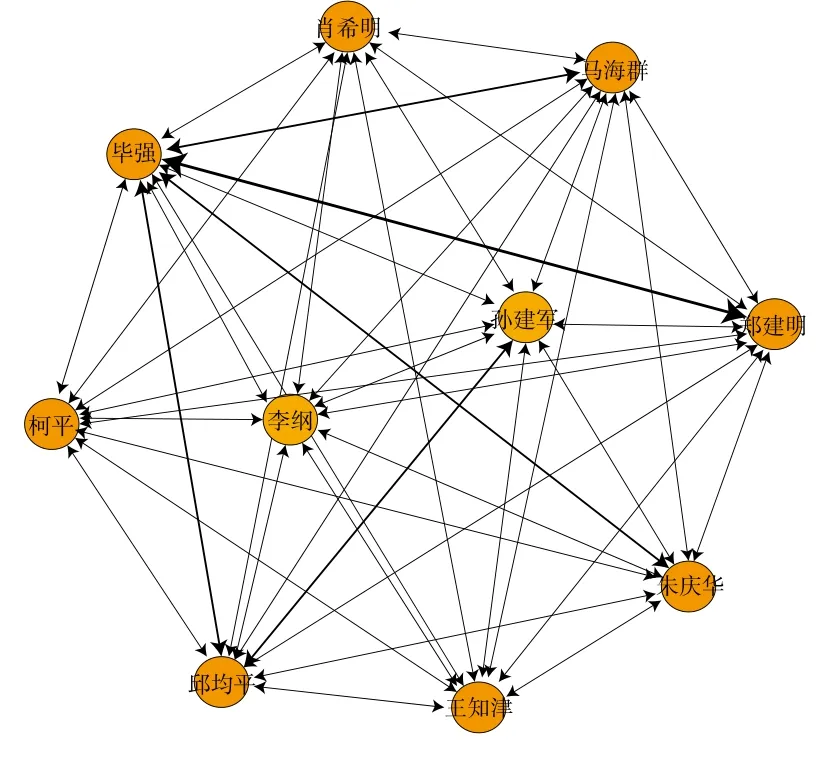
图2 基于关键词相似度的作者共现网络
由图2可知,毕强和郑建明两者的关键词集相似性程度远高于其他。分析表明两个作者Top5关键词使用最多的是“数字图书馆”,结合作者所在机构,两个作者均毕业于武汉大学,具有相似的学术渊源,所以这个结论在情理之中。关键词可以反映作者的研究热点和研究兴趣,因此两位作者研究内容的相似性也相对较高。孙建军和肖希明的关键词相似度仅有0.008。查看两位作者,孙建军主要研究方向为信息资源管理与网络计量,肖希明主要研究方向是信息资源建设与图书馆管理。这一点似乎表明高产作者的研究方向具有多样性。
事实上,随机地抽取若干个作者,其关键词集的相似度并不大。也就是说,作者关键词集的相似度较高的现象主要出现在高产作者群体当中。分析原因,主要是两个方面:第一,由于作者用词方法和习惯的不同,一定程度上也会影响作者关键词集的差异,主要体现在同义词、近义词、缩写词、中英文词等的利用上,如:“英特网”“互联网”“网络” “My library” “My library系统”“个性化数字服务系统”“个性化信息服务系统”等。第二,高产作者具有比较鲜明的研究方向,这是导致他们的关键词集相似度高的主要因素。
5 作者关键词集的共现分析
作者关键词共现分析的理论基础是社会网络分析理论(SNA)。本文将关键词视为节点,词频为节点的属性,同一篇文献中的关键词视为共现关系。这样,同一篇论文的一组关键词将构成一个无向的全网络,若干篇论文将通过相同的关键词互相关联起来构成无向含权的关键词集网络。通过计算网络参数,分析网络特征,借此表征作者关键词集的文献计量指标。
igraph是一个特别有用的网络分析的R语言扩展包(package),包含了一系列数据类型和函数,能够方便地创建网络,执行各种算法并实现网络数据可视化。在igraph中,可以用邻接列表、边列表、邻接矩阵等3种方法创建网络。边列表(edge list)是一个简单的两列列表,给出了所有的边连接的节点对。
网络中心性度量主要有点度中心度(dc)、接近中心度(cc)、中间中心度(bc)。点度中心度大的关键词的外延较大,例如数字图书馆、信息管理等,通常反映作者的主要研究领域。中介中心度大的关键词的内涵丰富,例如信息政策、信息公开、开放数据等,一般能够反映作者的主要研究方向或主题。
本文以马海群教授为例,绘制了“马海群-学术论文关键词集共现网络”如图3所示。马海群教授长期从事图情学科的教授和研究工作,成果丰硕。在2007~2016年之间共计发表论文126篇,CNKI中显示,其被引量和下载量都较高,具有较大的学术影响力。
图3 作者关键词集共现网络
图3中的信息分为以下7个部分:①图名信息,位于图的中间顶部;②以不同大小和颜色表示节点及其聚类分布的网络关系图,位于图的中央;③带有标号的节点信息位于图的左边;④节点中心性参数位于图的右边;⑤节点缩放比例、网络密度和网络聚集系数位于图的左上角;⑥R语言版本、硬件环境和计算时间等信息位于图的右上角;⑦关键词聚类信息位于图的底部。
从图3可见,网络密度和网络连通性都比较高,表明马海群教授研究主题突出,研究方向鲜明。图中有三个较大的社群,反映了马海群教授的主要研究领域有数字信息资源、开放数据、信息政策等。此外,点度中心度、接近中心度和中介中心度较大的节点有数字图书馆、数字信息资源、情报学等,表明马海群教授近10年的研究重点在“数字图书馆”领域。
6 结语
本文提出作者关键词集的概念,通过R语言创建了作者关键词集,并进行了文献计量分析,以作者、论文总量、关键词种数、关键词总量、低频词占比、中频词占比、高频词占比、top5关键词等指标,展示图情学科作者关键词集的特征:低频关键词占比较高,高频关键词占比较低,相对分散。同时指出作者关键词集能够表征作者研究主题和兴趣,借助作者关键词集相似度指标,可以构建作者共现网络,而作者关键词共现网络中心性指标可以揭示作者研究领域、研究主题或研究方向。基于作者关键词的文献计量分析能够揭示作者关键词集的分布、聚类和关系特征,量化的网络特征参数,对进一步的数据挖掘和知识发现具有一定的参考价值,对发展文献计量分析理论和方法具有一定的学术意义。
本文研究仍存在一些不足,例如,没有考虑词间语义关系,从语义的角度进行分析是今后研究的一个方向。有些语义相近的关键词如“信息需求”“用户需求”“用户信息需求”等,被视为是不同的关键词,这有可能会影响结果的准确性。另外,文献中往往会出现一些指示性较弱的词汇[16],例如,“论述”“研究”“分析”“性质 ”“策 略 ”“ 特 色 ”“ 原 则 ”“ 特 征 ”“ 价 值 ”“ 行 为”等,这些关键词含义宽泛,不仅不能解释说明主题研究内容,还会给后续数据分析带来干扰[17],缺乏专指性,这就失去了关键词的价值,在计量分析时可以做必要的清洗处理。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
天然气与石油(2021年5期)2021-11-06
内江科技(2021年8期)2021-09-13
河北画报(2020年8期)2020-10-27
亚太教育(2018年5期)2018-12-01
消费导刊(2017年24期)2018-01-31
照明工程学报(2017年2期)2017-05-02
环球市场信息导报(2017年1期)2017-04-08
读者·校园版(2015年7期)2015-05-14
现代企业(2015年2期)2015-02-28
