
一种新型有向加权协同过滤算法的推荐技术研究∗
2019-03-01 02:52:00彭康华姚江梅黄裕锋
计算机与数字工程 2019年1期
彭康华 姚江梅 黄裕锋
(广东工程职业技术学院信息工程学院 广州 510520)
1 引言
在大数据和“互联网+”时代,某些用户数据仍然以指数级的不断飚升,也更加多样化、复杂化,面对海量的网络资源和学习资源,评分矩阵更加稀疏,使得误差偏大,可信度较差[1~3]。因此,协同过滤算法仍需大力发展和不断改进、完善,基于传统的协同过滤算法,修正创新为有向加权协同过滤算法的网络资源个性化推荐技术[4~5]。在目前的协同过滤算法中,一方面是先建立已知评分矩阵,通过已知矩阵去对填充或计算未知评分项,达到增大数据密度,降低矩阵稀疏性的目的,以提升推荐算法的可信度。其二是从另一个不同的角度出发,基于非填充的训练集,使评分矩阵的原始数据不予改变,对结果的相似度给予修正,从而降低数据稀疏性,增加准确性[6~8]。研究方案专注于第二种方法来进行有向加权相似度协同过滤算法修正改进和研究。
2 基于重合因子相似度校正法
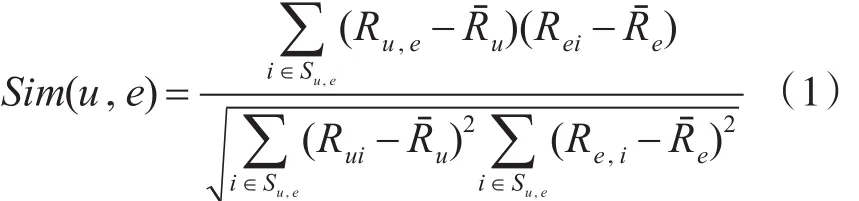
相关系数皮尔逊(Pearson Correlation)建立在相关性方法计算上,能够用于分析几个方向用户评价趋势一致性问题。以用户(u)与评价(e)为例,分析Pearson Correlation系数计算公式,见式(1)。其中,Su,e为 u、e的交集,Rui、Rei为 u、e对评价 i的分值,Rˉu、Rˉe为平均值。由式(1)计算的用户相似度评分,取决于它们评分的相似度。如果为稀疏集,不同用户间有一致评分的概率不大。最终得到的数据更是随意或偶然的,能得到感兴趣的个性化推荐结果不可靠。这时,须对上述的相似度问题实行修正,以期应对评价的稀疏情况[9~11]。
一些研究者认为,个性化推荐重要的是重合因子(Overlap Factor),简称OF,其描述的是不同用户评价数量二次方,再除以不同用户所评价项目数。见式(2)。

式(2)中,| Su|、| Se|描述的是不同用户评价项目数;|Su∩Se|描述的是不同用户共同评价项目数。
利用上述Overlap Factor对相似度进行修正,即是对个性化推荐系统的全部用户的相似度修正。通过上述修正后,可以得到加权相似度,称为Weighted Similarity,见式(3)。
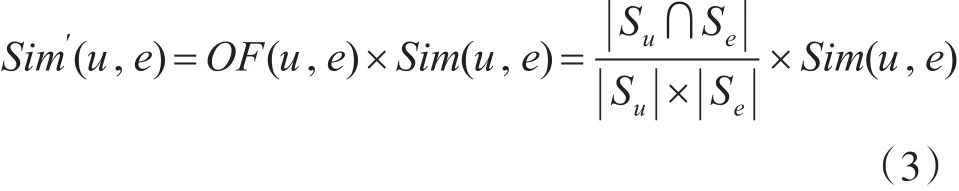
从式(3)得知,Overlap Factor与不同用户共同评价项目数的二次方有正相关关系,与用户各自评分项目数有反比相关性。由上述修正的相似度为基础,使得Overlap Factor的适应性大大增强,可以应用于不同范围、不同稀疏集和不同分类系统分配的个性化推荐系统[12~13]。
个性化推荐算法输入主要是用户-项目的评价矩阵R(u,e):
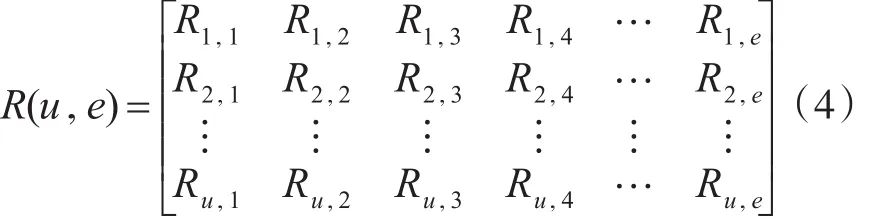
式(4)中,行为用户有u位,列为需评价项目e,构成u×e矩阵,第u行、e列R(u,e)取值是u在e上的评价等级。等级常用0~5的整数来计数,表达的是推荐程度。这样的评价结果虽然直观易懂,但有一些问题。见表1用户-项目评价矩阵。

表1 用户-项目R(u,e)评价矩阵表
通过上述式(3)的计算,可以计算得到用户u1及 u2的 Overlap Factor。

接下来是计算u1及u3的Overlap Factor。
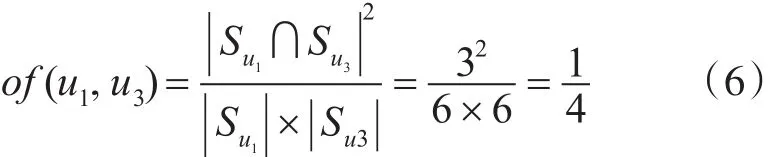
上述公式通过Overlap Factor对相似度进行修正,可以计算得到u1、u2间的Sim(u1,u2)重新计算后的值是1/3,u1、u3的Sim(u1,u3)计算后得到1/4。结合我们的现实生活来看,这有悖于常理,原因主要是u1、u2的Sim值是在2个共同评分项目计算的,u1、u3的Sim值是在3个共同评分项目计算的结果,可以看出Sim(u1,u3)比Sim(u1,u2)可信度更高,所以Sim(u1,u3)的修正强度应不大于Sim(u1,u2)的修正力度。为什么会有这一现象,通过分析发现,Overlap Factor与用户各自评分项目数有反比例的关系,用户u之间非重合的评分数据对相关因子的影响非常重要。因此,本文阐述了对相关因子进行再修正和改进,以期使用降低用户u间的非重合评分数据的响应,获得更为准确的Overlap Factor。
3 基于有向加权重合因子的相似度修正方法
3.1 有向重合因子
根据上述提出的基于重合因子的相似度修正方法描述,重合因子修正有一定的缺陷和不足,因此,本文分析研究出重合因子的改进方法。以减少用户u间非重合推荐值于重合因子的影响,文中对重合因子进行了概念更新,定义为两用户u间共同推荐值的数目正相关,与目标用户u推荐值的数量反向相关。假设用户u、e的推荐值的集是Su、Se,这样,u、e间以改进形式表现重合因子见式(7)(式中用户u是目标用户):

可以推导出重合因子改进方式中,用户u、e间的重合因子取值有2个,分别为 OF(u,e)、OF(e,u),重合因子的值并非对等。原因在于通过改进后,重合因子既与推荐值交集有相关性,也与目标用户的选择有相关性。选择的目标用户有异,结果也会不一致。所以,重合因子的改进方式定义为有向重合因子(Directional Overlap Factor,DOF),见式(8)。

有向重合因子和用户u间一起推荐值的数目有正相关性,与目标用户u推荐值的数目有反相关性,这里讨论某一指定目标用户u,它的推荐值数目不变,其余用户u与目标用户u间的有向重合因子的值,依赖于该用户u与目标用户u推荐值的交集结果,以此来减少非重合推荐值的影响,这样,有向重合因子的改正方法更趋于完善。
所以,按式(8),对R(u,e)矩阵进行更新和计算,得出用户u1与用户u2间有向重合因子,见式(9)。(其中u1是目标用户)

在相同的方式下,计算用户u1、u3间有向重合因子,见式(10)。(其中 u1是目标用户)
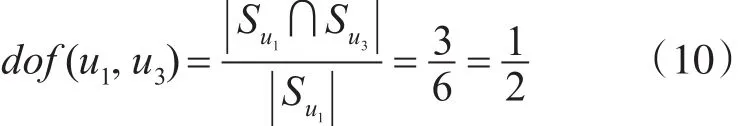
假设以有向重合因子为基础,对相似度进行修正,得到用户u1、u2间的相似度sim(u1,u2),其值改变为原值的33.33%,用户u1、u3间的相似度sim(u1,u3)改变为原值的50%。用户u1、u2间相似度sim在两个共同推荐值的基础上计算得到,以此类推,用户u1、u3间相似度sim为三个共同推荐值的基础上计算得到,以此,可以得出结论,sim(u1,u3)的可信度大于sim(u1,u2),也正是如此,对sim(u1,u3)的修正值要小于sim(u1,u2)。由以上描述可知,有向重合因子改进方式比重合因子修正方式对推荐值的计算更为客观和接近实际。
3.2 有向加权相似度
由上述计算可知,有向重合因子计算方法与选择的用户u有相关性,选择的用户u有异,计算得到的结论也相异。以有向重合因子来对相似度sim实行改进后,相似度sim同时也成了有向值,也就是说,2用户u间的相似度sim值也与目标用户u的取值相关。利用有向重合因子改进后的相似度sim为有向加权相似度(Directional Weighted Similarity),以任一用户u、v,用户间的有向加权相似度见式(11)。(其中用户u为目标用户)

有向加权相似度Sim执行见图1。
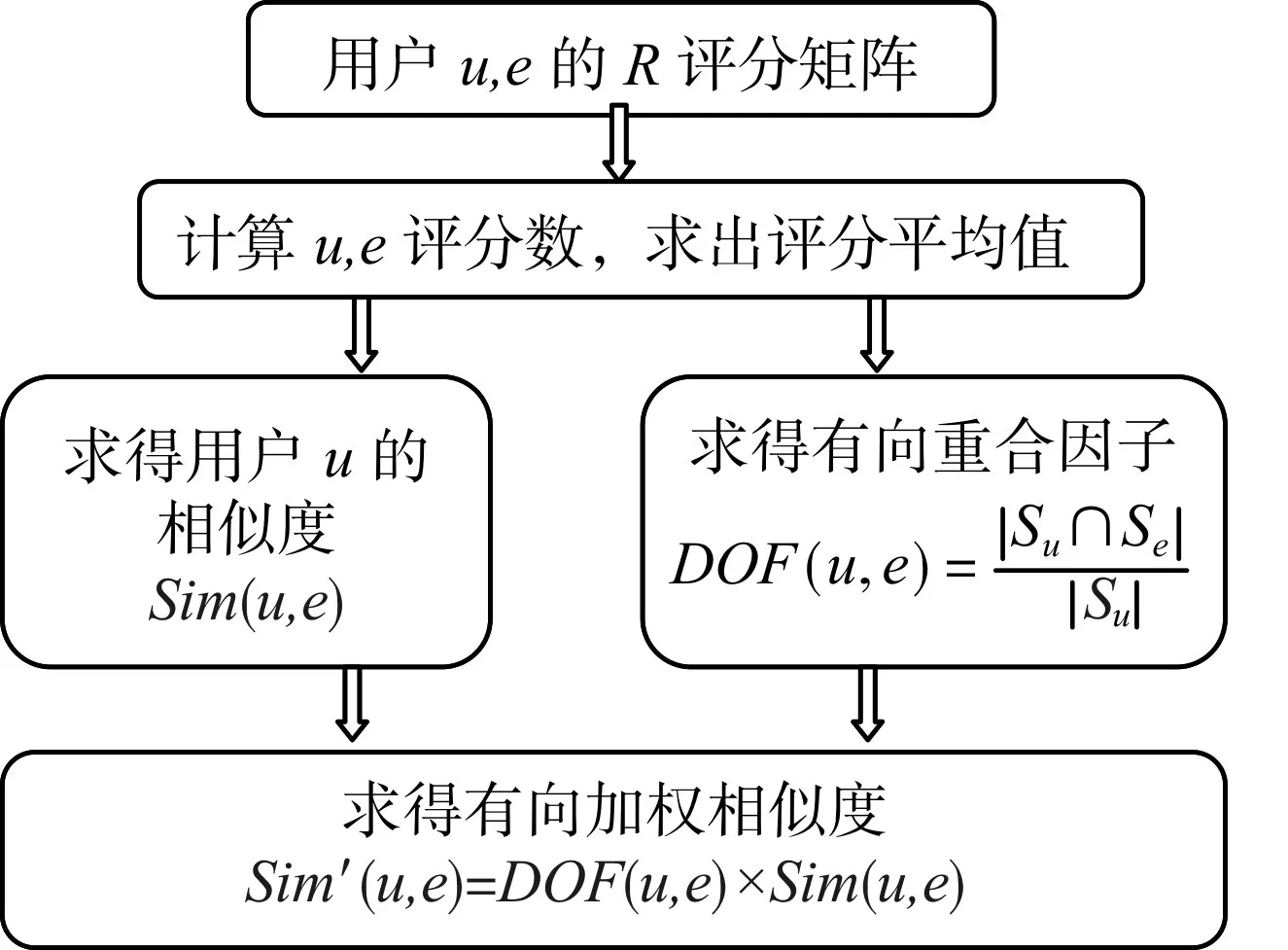
图1 有向加权相似度执行示意图
从有向加权相似度执行示意图可知,Sim′(u,e)和Sim′(e,u)的值可能相异,也可能等于,但都能被正确计算,既不会有歧义,也没有对后面的计算产生不利因素。当要求得当前u及其它用户间的有向加权相似度的时候,由公式sim'(u,x):{x∈[1,m]且x≠u}可计算结果,u的近邻集求解可使用sim'(u,x)来比较求得,无须再求sim'(u,x)、sim'(x,u)取值。
4 引入创新的有向加权相似度的协同过滤算法
这一节将讨论稀疏数据集,稀疏数据集推荐数量往往缺乏必要数据,得到的相似度不是很准确,并往往有随机性,不一定能精确反映用户的实际兴趣爱好[14~15]。为了使推荐结果更精确,利用上述得到的基于有向重合因子的相似度改进方法,对皮尔逊相关系数做一定的修正,生成有创新性质的有向加权相似度,进而构建创新的网络资源个性化推荐技术,见图2。

图2 新型的有向加权相似度的协同过滤算法示意图
基于创新的有向加权相似度的协同过滤改进算法执行步骤如下:
第一步,预处理数据
大数据中,数据集往往是巨大的,这样需选取一部分用户和用户推荐值,形成数据集的子集,以该子集为样本来进行选取和计算,达到简化目的和使计算速度得到提升的目的。对选取的数据子集进行用户和推荐值编码,用户标识(user identification,uid)定义为 1~m,项目标识(item identification,iid)定义为1~n。具体做法是将数据集以一定的概率分成训练集和测试集,其中,训练集代表已知数据存储R(u,e)评价矩阵,用于试验分析、对比和计算。测试集数据则作为未知数据来进行测试、预测,与实际值来对比研究,计算误差值和评价推荐算法的利弊等。
第二步,统计用户评价量及平均值
以R(u,e)评价矩阵为基础计算,某用户u对各项目评价值作为行向量,对R(u,e)的行进行分析、统计,得到每个用户u评分项目数,并计算u的平均值。
第三步,计算用户间相似度
基于皮尔逊相关系数,可以计算随机2个用户间u的相似度,存贮在二维数组Sim[][]的对应处。以用户ui、uj间的相似度为例,将其存贮在Sim[i][j]、Sim[j][i]中,其值的计算依据是皮尔逊相关系数计算公式(3)~(5)。其实,在对皮尔逊相关系数修正前,用户ui、uj间的相似度是没有方向的,换言之,Sim[i][j]=Sim[j][i],在无向数组中,这两者可以是相等的。
第四步,有向加权相似度的计算
根据式(3)~(5),可以对任一用户间有向重合因子进行计算,对上述的有向重合因子相似度改进,得到有向加权相似度,其结论存贮进二维数组Sim[j][i]。改进后变为有向相似度,就用户ui、uj而言,因为有向性,Sim[i][j]与Sim[j][i]因为有向,故并不是对等的,因此,其存储位置等不可变换。
第五步,最近邻的选择
按照数组Sim[][]存储的用户u间有向加权相似度,对目标用户u的最近邻居进行选择。如果用户 ui为目标用户,即 Sim[i][j](1≤j≤m ,m为总数,且 j≠i)可作为目标用户u与其他用户u的有向加权相似度。根据有向加权相似度值来取出k个与目标u附近的用户实现编码。
第六步,预测安排
若u对某项目尚未评分,可通过近邻的已评分用户来推算,推算方法见式(12)所示。
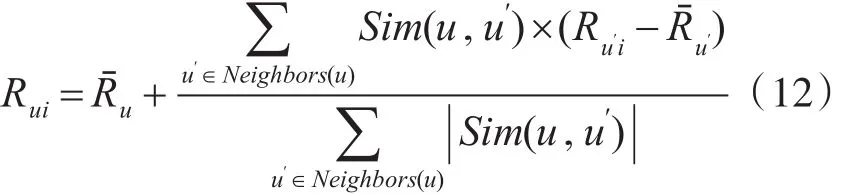
其中,Neighbors(u)描述的是最近邻集,sim(u,u')描述的是u与近邻u′的之间相似度。
第七步,误差统计
按照每个测试数据得分,可以依据前述步骤1~7来预测,以实际值对照预期值来进行误差计算,对个性化资源推荐评分结果进行优劣比较。
5 实验设计与论证
5.1 实验数据集说明
对上述的创新有向加权相似度协同过滤算法展开试验与论证,设计4种相异稀疏度的数据集,包括MovieLens数据集、EachMovie数据集、Epinions数据集及Jester Joke数据集,进行试验实证,并分析算法的可靠性。4个数据集的详细介绍及预处理方式请参阅相关文献。
5.2 算法比较
本次实验使用了3种各异的协同过滤算法,与前文阐述的基于有向加权相似度的协同过滤修正方法(Directional Weighted Similarity Based Collaborative Filtering,DWSCF)进行比较,从而验证上述的修正算法是否具备更好的优越性。用于比较的算法选择:
1)传统方法的协同过滤推荐算法(Collaborative Filtering,CF);
2)基于Jaccard系数修正相似度的协同过滤算法(Jaccard Similarity Based Collaborative Filtering,JSCF);
3)基于加权相似度的协同过滤算法(Weighted Similarity Based Collaborative Filtering,WSCF)。
其中,Jaccard系数计算方法见式(13)。
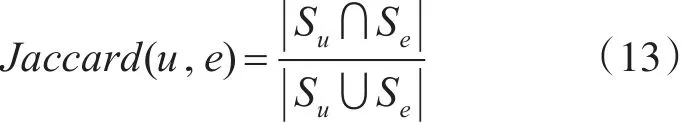
5.3 选择评分指标
本试验引入了平均绝对误差来计算上面3种各异协同过滤算法的精度,计算方法如式(14)所示。
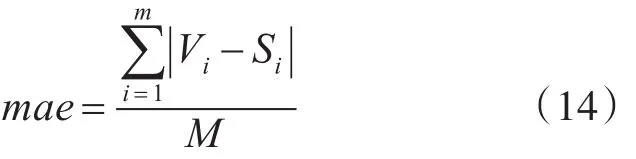
式中,M表达的是预测评价数,Vi是第i条预测评价值,Si是第i条预测评价值对应的实际值。mae描述的是精度,代表用户真实评分与期望值的差值,是一个定量的指标。
5.4 实验结果
通过一系列的实验,各个数据集的实验结果将以系列表格显示。表格中,最近邻数量在第一行进行标识,各种算法的种类标识在第一列,表中的数据为平均绝对误差,它的值是各个算法在指定的最近邻居中得到。为了使数据更见直观简明,图3~6展示了各个数据集的数据。为了方便比较,将以上数值以折线图形式进行直观展示,最近邻居的数量以横坐标标识,平均绝对误差值以纵坐标标识。
MovieLens数据集实验结果如图3所示。
其中,mae(mean absolute error)表示绝对平均误差,nearest neighbors number表示近邻取样数,下同。
EachMovie数据集实验结果如图4所示。

图4 EachMovie数据集图
Epinions数据集实验结果如图5所示。
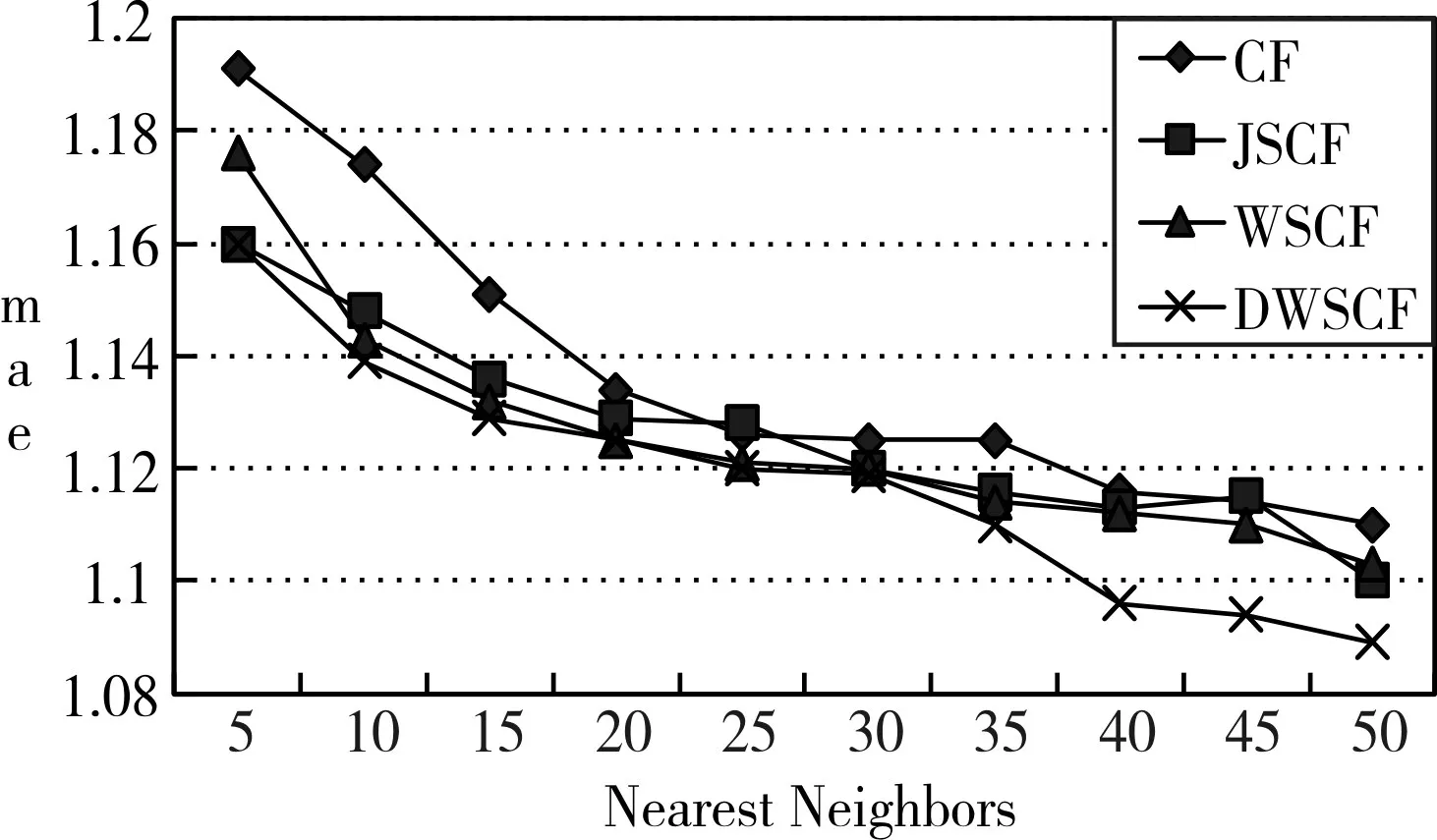
图5 Epinions数据集图
Jester Joke数据集实验结果如图6所示。

图6 Jester Joke数据集图
5.5 实验结果分析
折线图展示了四种数据集的实验结果,描述的是协同过滤算法,由图可以看出,各个数据集的折线图趋势均为从左上到右下,表明最近邻居用户量足够大,其误差才会足够小,结果也才会越精确。与传统协调过滤算法比较,该修正算法误差值更小,实验结果更加可信。在各个数据集的实验结果中,JSCF、WSCF两种算法图相对吻合,其中,在Epinions数据集的实验结果中,两种算法图出现交叉,表明在基于Jaccard系数及基于重合因子相似度改进法对比中,对传统协同过滤算法的影响结果几乎相同。而DWSCF算法的平均绝对误差比JSCF、WSCF都要低,从这里可以得到结论,基于有向重合因子相似度改进法比重合因子修正法、Jaccard系数修正法均要好,结果更准确。
各种算法在数据集中的性能对比如图7所示。
图7 实验结果对照图
根据图7,通过分析对比,MovieLens数据集中的算法比较,DWSCF>JSCF≈WSCF>CF;EachMovie数据集中的算法比较,DWSCF>JSCF≈WSCF>CF;Epinions数 据 集 中 算 法 比 较 ,DWSCF>JSCF≈WSCF>CF;Jester Joke数 据 集中的算 法 比 较,DWSCF≈JSCF≈WSCF≈CF。其中,Jester Joke数据集,DWSCF对比JSCF、WSCF这两种算法,效果大概相当,这可能是因为Jester Joke数据集的数据规模和密度比其它数据集都高,而基于有向重合因子相似度改进法更侧重于稀疏数据集,在越稀疏的数据集中,获得更优越的性能,表现更好的效果。
在现实生活和实际中,用户评价数据往往是非常稀疏的,用户-项目评价矩阵表现很强的稀疏性,其稀疏度可能都在97%以上,所以,本文研究的基于有向重合因子相似度改进法在现实生活和实际中,可用性非常强,能充分发挥大数据下数据稀疏的适用性和实用性,从而获得很好的个性化推荐质量,有较好的实际意义。
6 结语
网络资源个性化推荐以各个用户共同评价项目为依据,但在大数据和“互联网+”时代,网络资源及其丰富,数据集非常稀疏,再加上传统推荐系统的不确定性,其精度往往得不到保证。作为改进方法,本文研究了创新的有向加权协调过滤推荐技术算法,利用有向重合因子加权后改进相似度算法,实验证明该方法在极度稀疏的数据集里效果明显。基于创新有向加权相似度协同过滤算法在解决互联网+大数据的网络资源个性化推荐稀疏度问题上,确实起到缓解及优化作用,极大地减少了网络资源个性化推荐中不利的因素,提高了预测和计算的准确度,因此,网络资源个性化推荐质量得到很大程度的提高。
猜你喜欢
Journal of Palaeogeography(2022年1期)2022-03-25 04:17:00
快乐语文(2021年35期)2022-01-18 06:05:30
法律方法(2019年4期)2019-11-16 01:07:28
科技资讯(2019年19期)2019-09-17 11:20:50
摄影之友(影像视觉)(2017年1期)2017-07-18 11:12:16
同学少年(2017年3期)2017-06-24 11:59:38
同学少年(2017年2期)2017-06-24 11:59:22
同学少年(2017年1期)2017-06-24 11:58:45
电子制作(2017年10期)2017-04-18 07:23:07
电测与仪表(2015年10期)2015-04-09 11:48:32
