
遗漏负样本挖掘的行人检测方法∗
2019-02-27 08:32:10刘芷含李旻先赵春霞
计算机与数字工程 2019年2期
刘芷含 李旻先 赵春霞
(南京理工大学计算机科学与工程学院 南京 210094)
行人检测[1~3]作为自动驾驶、智能监控等实际应用的主要部分,吸引了不少学者的关注。近年来,卷积神经网络(CNN)在计算机视觉和模式识别方面表现出了强大的能力。许多基于CNN的物体检测方法已经被提出,这促进了行人检测的学术研究和应用进展。
基于CNN的物体检测方法可分为两大类。第一类是两个阶段的R-CNN型。这些方法在第一阶段提出合理的区域候选框,然后在第二阶段进行细化。另一类方法旨在消除候选区域阶段,直接训练一个端到端的分类器[4]。第二种方法通常更容易训练,计算效率更高,但第一类方法在性能上往往更有利。
Faster R-CNN[5]框架属于第一类方法。它主要由两个模块组成:RPN和Fast R-CNN[6]。其中,RPN是用于提取候选框的模块,它改善了过去提取候选框的方法,大幅度减少候选框的数量、提高了整体物体检测的准确性。Fast R-CNN检测并识别RPN提出的候选框。同时,该框架依靠4步交替训练算法,将独立存在的RPN网络和Fast R-CNN网络通过共享卷积层实现了端到端。端到端可训练的Faster R-CNN网络更快更强大。
视频条件下的应用场景与自然图像差异很大,照明条件、目标大小、尺度、拍摄角度等因素导致检测结果差。可靠地检测出视频帧中的行人需要各种信息,包括行人的细粒度细节及其周围的上下文[7]。每一张视频帧中除了目标,大多数区域是背景,并且背景中极有可能存在卷积特征与正样本相似的难分负样本。Faster R-CNN仅使用真值候选框(Ground Truth,GT)周围的信息。因此,视频条件下分类器效果不好,这更有可能产生误检。我们将产生误检的原因分为两类,第一类是将非行人的物体检测为行人,第二类是由于检测框不准确,不满足正检设定的条件。
行人检测结果不仅受到行人特征[8]和分类器的影响,训练样本也会产生影响。第一种误检产生的原因主要是负样本不充分,没有考虑到背景中有代表性的负样本,我们称这种样本为被遗漏的负样本。利用候选框的置信度,在丢弃的候选框中找到被遗漏的负样本,来改进Faster R-CNN的样本生成算法。这种方法不仅充实了负样本,而且利用被忽略的背景信息。进行检测时,发现第一类误检明显减少。
2 相关工作
挖掘难负示例的方法是为分类器挖掘更具代表性的样品。我们的方法是它的一个分支,是利用置信度挖掘对分类器有影响的被遗漏的负样本,从而增加其“判断力”。
2.1 Bootstrapping
物体检测和图像分类是计算机视觉的两个基本任务[9]。检测器通常通过将物体检测转换为分类问题来简化训练[10]。这种转换为图像分类任务引入了新的挑战:训练集正样本数量和负样本数量不平衡[11]。训练分类器时,负样本中通常含有一些简单的样本,因此整体的复杂性难以保证,并且整体已知的信息也不能被有效地利用。这就迫切需要新方法来去除一些容易区分的样品类,并添加一些现有模型不能判断的样品类,进行新的训练使得训练过程更高效。
Bootstrapping方法的关键思想是将误检的示例加入到背景示例中,来逐渐增加背景示例。该策略导致迭代训练算法。该算法开始于一组初始训练集,不断更新检测模型以找到新的误检样本添加到训练集中。该过程的初始训练集包含所有被标记的正样本和随机生成的负样本。
Bootstrapping方法已被广泛应用于物体检测。Dalal等[12]将这种方法用于训练行人检测的支持向量机(Support Vector Machine,SVM)。Felzenszwalb和Girshick[13]提出了一种间隔敏感方法来挖掘难负样本,并证明该方法收敛于整个数据集的全局最优解。他们的算法通常被称为挖掘难负示例方法。物体检测[14~16]经常使用该算法来训练SVM,从而解决了训练样本过多的问题。Bootstrapping在现代检测方法中也很受欢迎,如R-CNN[14]和SPP-NET[15]。
一些现代方法将生成负样本时较低的阈值作为挖掘难负示例方法的启发式,其认为与GT有一些重叠的候选框更可能是难分样本[6]。这种启发式有助于收敛和检测精度,且实现简单。由于使用端到端的训练策略而没有使用挖掘难负示例方法,Fast R-CNN和Faster R-CNN需要这种启发式来改进检测效果。因此,这些方法引入了一些新的问题,即一些难分样本被忽略,影响分类器的分类效果。
2.2 在线难样本挖掘(Online Hard Example Mining,OHEM)
当采用挖掘难负示例方法训练分类器时,选择负样本的阈值范围太小或太大将产生不同的问题。另外,生成正负样本时要控制正负样本的比例,例如Fast RCNN正负样本的比例设置为1∶3。Abhinav Shrivastava等[11]基于Fast R-CNN针对上述问题,提出了在线挖掘难负示例方法(Online Hard Example Mining,OHEM)方法。该方法对随机梯度下降(Stochastic Gradient Descent,SGD)算法进行了简单的修改,即在Fast RCNN使用SDG算法在线训练时将交替的步骤与其结合。每个SGD迭代包含的样本虽然比较少,但每个样本图包含数以千个感兴趣区域(Regions of Interest,ROI),可以从中筛选难分负样本来更新后向传播中模型的权重。这个过程仅仅将模型固定在一个小批量中,训练过程没有延迟。
这是Bootstrapping算法在深度学习中的完美“嵌入”。使用全部ROI更新权重会带来时间消耗,并且在使用全部ROI时,权重的更新仍然集中在难分样本上。其关键思想是使用网络训练损失来找到那些代表性的负样本,使分类器训练效果更好。该方法还表明,将产生负样本的阈值限制在某个阈值范围内并不是最优的。
Minne Li和Zhaoning Zhang等[17]发现OHEM在所有类型任务的损失中使用相同权重来设置多任务损失,并忽略训练期间不同损失分布的影响,因此他们提出了分层在线挖掘难负示例(Stratified Online Hard Example Mining,S-OHEM)算法,该方法根据损失分布对训练数据进行采样提供给反向传播过程。
3 改进的样本生成算法
Faster R-CNN不仅使用非极大值抑制方法,而且在执行检测时使用分类得分来去掉冗余框。例如,Faster R-CNN定义了一个阈值为0.6,以去除得分小于0.6的冗余框。我们发现,当产生第一种误检时,不管目标周围有多少个候选框,非极大值抑制方法最终会留下至少一个具有较高分数的候选框,该候选框的分数可能高于阈值。然后将作为最终结果输出。如果增加阈值,则会导致许多正确的检测框被抑制,特别是远处或被遮挡严重的小目标。这将减少召回,因此更改阈值不是最佳的。
我们知道候选框的分类得分表示该候选框是行人的概率。当生成第一种误检时,分类器“认为”该候选框中的目标是行人。分类器基于现有的学习经验来判断,并没有在学习过程中学习到这种情况。所以我们认为当为分类器生成样本时,遗漏了一些具有代表性的负样本。为了解决这个问题,我们重新审视了Fast R-CNN的样本生成算法。Fast R-CNN优化图像的所有锚点,并使用非极大值抑制方法来移除重叠区域。这样可以去除类似的样本并减少样本数量,剩下的样本更可能是难分样本。选择前2000个候选框以生成Fast R-CNN的正负样本。具体过程如下:对每个GT,与其重叠比例最大的候选框记为前景样本;剩下的候选框中,如果其与某个GT的重叠比例大于T1,记为前景样本;如果其与任意一个GT的重叠比例大于T2并小于T1,记为背景样本;其余的候选框,弃去不用。
Faster R-CNN在GT周围产生样本。对于图像而言,局部区域包含有限的信息,这往往会导致分类错误。鉴于上述问题,我们提出了第一个假设,即在负样本中随机加入少量不重叠或重叠率小的背景信息。定义Faster R-CNN丢弃的候选框为B={b1,…,bN},N是候选框的数量,random(⋅)是随机采样函数,n是随机选择的样本数。对于第i个候选框,我们使用以下规则来定义:

其中,Label(i)∈{-1,0},Label()i=-1表示标记的候选框将被丢弃,Label(i)=0表示标记的候选框将被添加到负样本中。在Faster R-CNN的训练过程中,对于每个图像,总样本数和比例是固定的。所以这可以充分利用目标周围的背景信息,也不会增加计算量。但这违反了挖掘难负示例方法的本质,也找不到最好的n。

图1 样本生成算法的体系结构
样本生成算法不仅要充分利用目标的背景信息,还要满足挖掘难负示例方法的要求。我们定义的负样本符合上述要求,不仅是背景信息,又是有代表性的负样本。根据Faster R-CNN样本生成算法,发现丢弃的候选框中存在大量的背景信息,需要从中找出遗漏的负样本,因此提出了一种新的样本生成算法。使用预训练模型来判断弃去不用的候选框以找到可能被分类器“识别”为目标的候选框,并让分类器“知道”这些候选框不是目标。定义规则如下:

其中,bi是Faster R-CNN丢弃的第i个候选框,Score()·表示候选框的分类得分,T是阈值。设置阈值T来筛选遗漏的负样本,这不仅确保了筛选出的负样本数量,而且确保所选区域是难分样本。图1是我们方法的正式描述,箭头的方向表示执行的顺序,虚线框中的步骤是我们的方法。RPN网络的输出用于预分类器生成分类得分,并根据分类得分(如虚线框所示)为Faster R-CNN选择遗漏的负样本。其中,绿色框表示正样本,红色框表示负样本,橙色框表示遗漏的负样本,蓝色框表示GT。从图1可以看出,原始方法仅考虑每个候选框与GT的最大重叠率,即位置信息。我们的方法不仅考虑了位置信息,还考虑了分类器的分类效应,发现分类器的不足,改变它的不足。
我们的方法产生效果的条件有三个:首先,Faster R-CNN有一个具有一定分类能力的预训练模型,我们使用预训练模型来获得候选框的分数。这并不需要多次迭代。文献[18]中的做法是首先在原始训练集上学习得到新的误检样本,然后将误检样本添加到训练集中以重新训练,不停迭代以满足要求。其次,在对模型进行训练的同时,加入了有代表性的难分负面样本,前景样本与背景样本的比例依然保持1∶3。迭代训练时可以确保背景样本中的难分样本被选中用于训练。最后,由于Faster R-CNN网络的4步交替算法,第二步中的优化结果将在第三步中产生优化,并作用于第四步。而第四步再次利用我们的方法来进一步提高分类器的能力。
4 实验
4.1 数据集
我们对三个数据集进行了全面评估:INRIA[11],PKU-SVD-B和Caltech行人数据库[19]。默认情况下,交并比阈值(Intersection-over-Union,IoU)为0.5,用于确定这些数据库中的正检。对于ImageNet预先训练的网络,我们在PKU-SVD-B,INRIA数据库上使用具有五个卷积层和三个全连接层的ZF网络[20],在Caltech数据库上使用具有十三个卷积层和三个全连接层的VGG网络[21]。
INRIA该数据库的原始图片来自GRAZ-01数据库和网络上的一些图片。这些照片中的行人姿态和照明条件比较全面,适合做行人检测。我们的方法使用INRIA训练集的614个正样本来对INRIA测试集进行训练和测试,其中包括743个测试图像。
PKU-SVD-B该数据库由北京大学视频编解码技术国家工程实验室联合北京大学保卫部建立并整理,主要用于全国研究生智慧城市技术与创意设计大赛“视频分析技术挑战赛”。其来自北京大学校园内20个摄像头的监控视频,分辨率为1080p。选用PKU-SVD-B数据库中的行人数据,包括3200个训练图像和5711个测试图像。
Caltech-USA该数据库是目前应用较广泛的行人数据库,其采用车载摄像头拍摄,大约10h,视频的分辨率为640×480,30帧/秒。训练集有42782张图像,测试集中的4024张图像用于评估“合理”设置(行人至少高50像素,至少65%可见)下的原始标注。
4.2 实验结果及分析
在本文中,使用召回率,精度率和F1测度作为评估指标。F1测度综合考虑召回率和精确率,是两者的调和均值,以对测试算法的分类性能进行更合理的评估[22]。为了进一步评估我们的方法,绘制MR-FPPI曲线(Miss Rate-False Positives per Image),以获得获取每幅图像误检数在[10-2,100]范围内的对数平均误差率。
首先在公共静态数据库上使用我们的方法来展示其优越性。在实际应用中,行人检测主要检测视频中的非静态行人。在视频条件下,行人很容易与背景混合;行人会有各种各样的姿势,如行走,站立或不可预测的改变运动方向;天气等外部因素将对行人的背景也会产生不同的影响。为了进一步验证我们的方法,在更复杂的视频条件下进行了实验。
分别对INRIA,PKU-SVD-B和Caltech数据库进行训练,分别对其测试集进行测试。设置阈值T为0.7以选择难分样本。召回率,精确率和F1测度3个评价指标上的对比结果如表1所示。

表1 不同测试集上的检测结果
INRIA结果从表1可以看出,INRIA数据集中的误检率很高,这导致其精度不高,只有79.7%。我们的方法提高了分类器的效率,将精度提高到91.2%。虽然召回率略有下降,但召回率和准确率更为均衡。图2是其对应的MR-FPPI曲线,我们的方法将性能下降了2.2%(从10.3%MR到8.1%MR)。
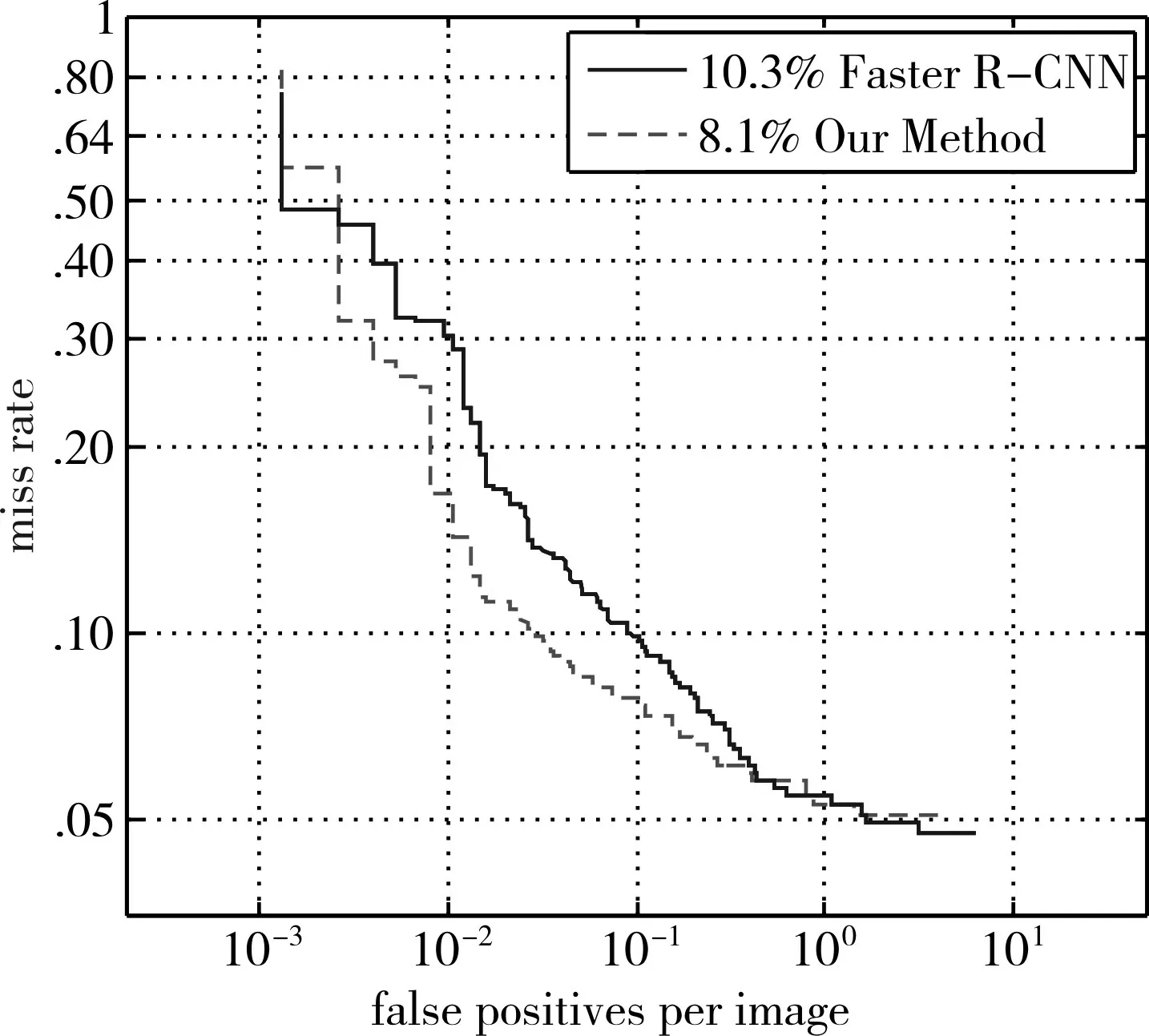
图2 INRIA测试集的MR-FPPI曲线
PKU_SVD_B结果为了进一步验证我们方法的优越性,在视频条件下进行实验。PKU_SVD_B数据中的目标相对较大,背景复杂度较Caltech数据集偏低。召回率,精确率和F1测度结果如表1所示。在PKU-SVD-B数据集上的召回率没有变化,精度提高了9.7%,F1测度提高了4.9%。MR-FPPI曲线如图3所示,MR值降低1.2%。

图3 PKU_SVD_B测试集的MR-FPPI曲线
Caltech结果Caltech数据集的行人更小更复杂,导致误检的可能性很高。从表1可以看出,其精确率非常低(24.5%),但是召回率较高,这主要是因为有很多误检。我们的方法大大减少了误检,将精度提高到37.2%。图4中,MR值下降了20.8%(从42.65%MR到21.85%MR),这表明我们的方法提高了分类器的性能。
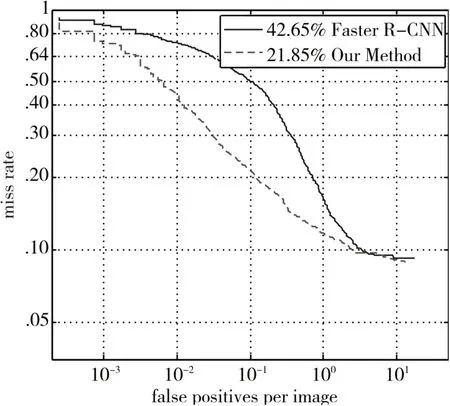
图4 Caltech测试集的MR-FPPI曲线
我们认为,如果图像的目标区域相对较大,导致第一种误检的概率较低。但在视频条件下,背景区域远远大于目标,并且背景更复杂,这就产生了大量的误检,降低了检测效率。我们的方法可以选择少量遗漏的负样本来减少误检。因此,在视频条件下的数据集上产生的影响比静态数据集上更为明显。
4.3 阈值T的分析
我们的方法涉及一个参数T,其用于在弃之不用的候选框中选择遗漏的负样本。阈值T的选择决定了分类效果。阈值T太小,将增加无用的候选框并增加计算成本;阈值T太大,无法挖掘出足够有代表性的负样本。我们在0.4~0.8的范围内改变阈值T,并检测分类器的性能。为了使我们的结果更有说服力,我们训练PKU-SVD-B数据库的训练集,并对测试集进行测试。如图5所示,分别对召回率,精确率和F1测度进行分析。
从图5可以看出,当阈值T增大时,精确率升高(忽略第一个精确率的值),到达0.7时达到一个较高的范围,然后降低。随着阈值T增加时,召回率几乎是恒定的。综合考虑到召回率和精确率,我们发现随着T的增加,F1测量值增加然后减小。当T=0.7时,F1测量最大,同时精度也在较高的范围内。因此,我们将T设置为0.7来为Faster R-CNN选择难分负样本。
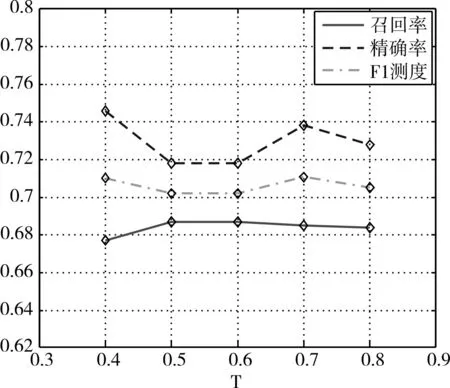
图5 不同阈值T的性能分析
5 结语
我们提出一种新的方法为行人检测生成样本,该方法利用候选框的周围信息和置信度。我们不仅对静态数据集进行了实验,还在视频条件下进行了实验,以进一步验证我们方法的有效性。实验说明我们的方法更适合于复杂的背景视频条件。未来的工作可以通过网络模型的自学习产生有代表性的负样本。通过使用候选框之间的重叠来判断正负样本并不是最理想的方案。
猜你喜欢
作文周刊·小学一年级版(2023年40期)2023-10-18 08:07:57
光学精密工程(2022年13期)2022-08-02 08:53:30
计算机工程与应用(2022年1期)2022-01-22 07:46:48
计算机工程与科学(2021年4期)2021-05-11 01:59:36
意林(2021年5期)2021-04-18 12:21:17
新世纪智能(语文备考)(2019年10期)2019-12-18 02:46:14
山东冶金(2019年5期)2019-11-16 09:09:22
扬子江(2019年1期)2019-03-08 02:52:34
中学生数理化·七年级数学人教版(2018年9期)2018-11-09 01:24:56
火力与指挥控制(2018年3期)2018-04-19 11:43:39
