
基于MobileNetV3的结构性剪枝优化
2019-02-26 03:10:16宋非洋吴黎明郑耿哲何欣颖
自动化与信息工程 2019年6期
宋非洋 吴黎明 郑耿哲 何欣颖
基于MobileNetV3的结构性剪枝优化
宋非洋1吴黎明2郑耿哲2何欣颖2
(1.广东工业大学信息工程学院 2.广东工业大学机电工程学院)
针对深度神经网络参数过多以及计算量巨大,使其较难部署在移动设备和APP上的问题,提出采用高效轻量化的MobileNetV3模型与结构性剪枝相融合的方法,对深度神经网络进行重构和压缩。最终生成的精简模型体积比原始模型缩小5.8倍,大幅度减少计算量和内存的消耗。经过微调后的精简网络模型相比于稀疏化训练的网络,准确度更高、泛化性能更好,能够直接运行在成熟框架(Pytorch,MXnet或TensorFlow等)或硬件平台上(GPU,FPGA等),无需特殊算法库的支持。
深度神经网络压缩;MobileNet;结构性剪枝
0 引言
近年来,深度神经网络在计算机视觉、语音识别等方面取得较大成就[1-3]。深度神经网络的发展一方面得益于基础理论的完善,另一方面也得益于近几年GPU计算能力的爆发性增长。随着深度神经网络的不断发展,为完成更复杂的任务,深度神经网络变得越来越深,计算量也越来越大。Hinton和Alex Krizhevsky等人[4]在2012年的国际计算机视觉挑战赛(ImageNet Large Scale Visual Recognition Competition,ILSVRC)上提出AlexNet,以16.4%的Top 5错误率夺得冠军,其包含6亿3000万个链接,6000万个参数和65万个神经元。一张图片从输入到输出需要经过15亿次的浮点数计算。后来提出的高性能网络结构,如VGGNet[5],DenseNet[6]和ResNet[7]等,则需要更多的储存空间和更高的计算能力。
由于嵌入式设备和移动设备的硬件条件受限,无法支撑这种计算密集型和存储密集型的深度神经网络。但与此同时,手机、汽车等移动场景对深度学习的需求越来越多。因此,对深度神经网络进行压缩、加速,使其能够部署在移动设备上变得至关重要[8]。针对上述问题,主流的解决方法有模型压缩和轻量化模型设计2种。
本文采用高效轻量化的MobileNetV3模型与结构性剪枝相融合的方法,进一步压缩轻量化的深度神经网络,并测试了压缩后的模型性能以及深度神经压缩[9]中结构性剪枝的压缩方式对网络模型的影响。
1 MobileNetV3
2019年,Google公布了MobileNet系列的最新成果MobileNetV3。MobileNetV3作为新一代轻量级深度卷积神经网络,既继承于原有的MobileNetV1和MobileNetV2,又拥有许多新特性。
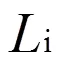
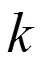

表1 MobileNetV2的基本网络单元
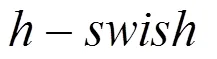
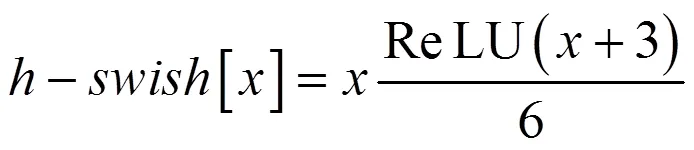
由于采用会引入延迟,因此网络前半部分的激活函数仍采用ReLU,后半部分则采用。另外,针对MobileNetV2网络末端计算量大的问题,使用Avg-Pooling代替计算量大的部分,在降低计算量的同时不会造成精度损失。MobileNetV3的基本网络单元如图1所示。
2 结构性剪枝
2.1 剪枝算法
神经网络剪枝算法最初用于解决模型过拟合问题,现在主要用于网络的稀疏化,以降低网络复杂度。目前主流的剪枝算法可分为非结构性剪枝和结构性剪枝2种。大多数情况下,非结构性剪枝是按照人为制定的标准对权重进行修剪。Han Song[14]等人提出阈值剪枝算法,通过设定阈值对网络中冗余的权重进行裁剪。由于深度神经网络中存在大量的冗余连接,阈值剪枝算法可有效减小模型复杂度,并通过稀疏数据格式储存模型,减小模型的存储空间。然而,这种稀疏数据计算时,采用传统的计算方式效率较低,只能通过调用专用的稀疏矩阵运算库,如CUDA的cuSPARSE库或专业硬件进行计算。另外,尽管阈值剪枝可以压缩模型的存储空间,但由于其仅仅使相应的权重置零,而未将冗余的连接从网络中彻底剔除,模型运行时产生的中间变量仍会消耗大量的内存。Srinivas[15]等人提出使用额外的门变量,对每一个权重都进行稀疏约束,并通过对门变量为零的连接进行剪枝来实现模型压缩,该方法拥有更高的压缩率,但内存消耗仍然较大。
Liu Z[16]等人提出一种有效的结构性剪枝方法,通过利用Batch Normalization(BN)层的尺度因子作为深度神经网络通道的重要性因子,即由值决定是否对通道进行剪枝。


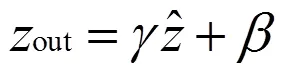
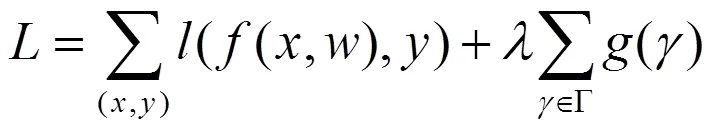
2.2 剪枝步骤
本文采用典型的迭代过程作为结构化剪枝的基本流程,具体步骤:
1)根据数据集制定相应的网络模型并初始化;
2)对模型进行稀疏化训练;
3)找到尺度因子较小的通道并进行剪枝;
4)对剪枝后的网络模型进行微调;
5)重复步骤1)~步骤4);
6)完成剪枝。
剪枝流程图如图2所示,其中虚线为迭代过程。

图2 剪枝流程图
剪枝后的网络模型以python通用的pth格式保存,其内部包含优化器(optimizer)参数、迭代数(epochs)以及网络参数(state_dict)等信息。
2.3 模型重构引导方法
一般来说,深度神经网络层与层之间以串联的方式相连接,连接处的通道数相对固定,只有在需要调整或修改模型网络结构时才进行通道数变更。本文使用的结构化剪枝将冗余通道的输入输出连接以及相关的权重全部进行裁剪,导致模型各层的通道数发生改变,且MobileNetV3结构复杂特殊,既包含膨胀层和反向残差层,又加入了注意力模型。若此时对模型进行测试,由于各层通道数不匹配,会产生模型无法运行的错误。因此在完成模型的稀疏化训练之后,本文提出一种模型重构引导方法。该方法能根据此前训练好的结构化稀疏模型重新构建一个更紧凑的网络结构,并载入剪枝后的模型参数,使重构后的模型在网络大小、卷积计算和运行内存消耗等方面更加轻量化。
本文在pytorch中创建1个_guide类,作为模型重构引导方法的基类;定义guide方法和rebuild方法,将完成训练的模型保存为稀疏格式并引导模型进行重构。在模型重构引导方法中,主要采用掩膜(mask)方式对模型进行处理,thre表示全局阈值;cfg表示重构引导参数。mask由BN层的权重参数矩阵和torch的内部类方法gt(thre)联立给出,并以四维tensor形式储存;每个通道对应的mask值由0或1组成,其中0表示需要进行剪枝的通道,1表示保留的通道。cfg以一维数组的形式储存,其内部包含每一层网络需要保留的通道数,即mask非零项的和。此时mask已包含所有的剪枝信息,与重构引导参数cfg相结合即可完成模型重构。
2.4 超参数的选择
超参数的选择与调整对模型效果有着显著的影响,如何找出一个对模型贡献度最高的超参数,是一项十分重要的工作。本文使用剪枝算法对模型进行稀疏化训练时,引入了新的损失函数以及超参数。为找出对模型稀疏化效果最优的超参数,本文利用Cifar-10数据集对MobileNetV3进行结构性稀疏化训练,并同时设定多个超参数,评估不同的超参数对模型稀疏化的影响,结果如图3所示。

图3 不同的值下γ重要性因子的分布
3 实验
3.1 实验环境
为了保证实验的准确性和客观性,本文采用经典的Cifar-10作为实验数据集。Cifar-10是一个10分类数据集,图片尺寸为32像素×32像素,每一类包含6000张图片,共有60000张图片,其中50000张为训练集,10000张为测试集。
本文的实验环境为搭载有NVDIA Tesla T4显卡的高性能工作站,采用Pytorch深度学习框架对模型进行搭建、训练和测试。训练周期为30个epoch;mini-batch为100;优化器为Adam;初始学习率为0.002,采用可变学习率方法,学习策略为

其中为测试集准确率。当<80时,保持学习率为0.002;当8≤87时,学习率为0.001;当87≤学习率为0.0002;当90时,学习率为0.00002。
3.2 实验结果及分析
3.2.1 剪枝率
为更好地了解结构化剪枝中不同剪枝率对MobileNetV3的影响,本文设定9个不同剪枝率对模型进行实验测试,结果如图4所示。

图4 剪枝率对模型的影响
由图4可知:模型稀疏化训练下的准确率比原始模型高3%,且模型在剪枝率为40%时效果最好;说明结构性稀疏化训练能有效增加模型的泛化性能,减少神经元之间错综复杂的依赖关系,提高模型的鲁棒性。
3.2.2 模型压缩率
每经过一个训练周期后,对相应的模型数据进行保存。在完成全部的训练周期后,从中筛选出表现最优的结构性稀疏化模型,采用40%的剪枝率进行剪枝微调处理,结果如表2所示。

表2 剪枝微调处理结果
由表2可知:剪枝后模型的体积为16 M,相比原始模型体积减少了77 M;top-1准确率提高了1.6%;模型整体体积压缩了5.8倍,压缩率达到17.21%;这表明经过结构化剪枝的模型能够在保证准确率的情况下,减少模型载入时的内存消耗,提高模型载入的速度。
4 结论
本文基于深度神经网络压缩理论,通过结构化剪枝算法简化网络结构,提出MobileNetV3模型的改进方案。鉴于原始网络结构复杂特殊,为了最大程度保留网络的强连接,本文采取稀疏化训练和模型重构引导方法,对网络进行训练、剪枝、重建和调优等操作,以达到压缩但不影响性能的效果。Cifar-10数据集的研究结果表明:对MobileNetV3进行不同程度的结构化剪枝,经过微调后的网络模型相比于稀疏化训练的网络,准确度更高、泛化性能更好;同时大幅度减少计算量和内存的消耗。下一步应研究分析模型中各单元模块对整个MobileNetV3的影响,对各单元模块分别进行剪枝处理,以理解各模块层级之间的共适应和依赖关系。
[1] Szegedy Christian, Liu Wei, Jia Yangqing, et al. Going deeper with convolutions[C]//IEEE Conference on Computer Vision and Pattern Recognition. Boston, 2015:1-9.
[2] Hinton G, Deng L, Yu D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012,29(6):82-97.
[3] Huang Zhen, Siniscalchi Sabato Marco, Lee Chin-Hui. A unified approach to transfer learning of deep neural networks with applications to speaker adaptation in automatic speech recognition[J]. Neurocomputing, 2016,218:448-459.
[4] Krizhevsky Alex, Sutskever Ilya, Hinton Geoffrey E. ImageNet Classification with Deep Convolutional Neural Networks[J]. Communications of the ACM,2017,60(6):84-90.
[5] Ioffe Sergey, Szegedy Christian. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift[C]//InternationalConference on Machine Learning.Lille, 2015:448-456.
[6] Huang Gao, Liu Zhuang, Weinberger Kilian Q. Densely Connected Convolutional Networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, 2017:4700-4708.
[7] He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, 2016:770-778.
[8] 纪荣嵘,林绍辉,晁飞, 等.深度神经网络压缩与加速综述[J].计算机研究与发展,2018,55(9):1871-1888.
[9] Han S, Mao H, Dally W J. Deep Compression:Compressing Deep Neural Networks with Pruning,Trained Quantization and Huffman Coding[EB/OL].http//arxiv.org/abs/1510.00149,(2016-02-15).
[10] Howard A G , Zhu M , Chen B , et al. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[EB/OL].http//arxiv.org/abs/1409.1556,(2017-04-17).
[11] Sandler M , Howard A , Zhu M , et al. Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018:4510-4520.
[12] Tan M , Chen B , Pang R , et al. MnasNet:Platform-Aware Neural Architecture Search for Mobile[C]//IEEE Conference on Computer Vision and Pattern Recognition. Long Beach, 2019: 2820-2828.
[13] Jie H, Li S, Albanie S, et al. Squeeze-and-Excitation Networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, 2018:7132-7141.
[14] Han S , Pool J , Tran J , et al. Learning both Weights and Connections for Efficient Neural Networks[C]//Neural Information Processing Systems Conference. Barcelona, 2016:1135-1143.
[15] Srinivas S, Subramanya A, Babu R V. Training Sparse Neural Networks[C]//IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu, 2017:138-145.
[16] Liu Z , Li J , Shen Z , et al. Learning Efficient Convolutional Networks through Network Slimming[C]//IEEE International Conference on Computer Vision. Venice, 2017: 2736-2744.
Optimization of Structural Pruning Based on MobileNetV3
Song Feiyang1Wu Liming2Zheng Gengzhe2He Xinying2
(1.College of Information Engineering , Guangdong University of Technology 2.College of Mechanical and Electrical Engineering , Guangdong University of Technology)
With the continuous development and landing of artificial intelligence, deep neural networks have made great achievements in target detection and image recognition, but the excessive parameters and huge calculations of deep neural networks make it difficult to deploy on mobile devices and apps. In order to solve this problem, a high efficiency and light weight MobileNetV3 model combined with structural pruning is proposed to reconstruct and compress the deep neural network. The resulting streamlined model is 3.2 times smaller than the original model, which greatly reduces the amount of computation and memory consumption. The fine-tuned streamlined network model has higher accuracy and better generalization performance than the sparse training network and can run directly on mature frameworks (Pytorch, MXnet or TensorFlow, etc.) or hardware platforms(GPU, FPGA, etc.). No support for special algorithms is required.
Deep Neural Network Compression; MobileNet; Structural Pruning
宋非洋,男,1995年生,硕士研究生,主要研究方向:计算机视觉与深度学习。E-mail:458852863@qq.com
吴黎明,男,1962年生,教授,主要研究方向:人工智能与深度学习。E-mail:jkyjs@gdut.edu.cn
郑耿哲,男,1996年生,硕士研究生,主要研究方向:计算机视觉与深度学习。E-mail:zhenggengzhe@mail2.gdut.edu.cn
何欣颖,女,1996年生,硕士研究生,主要研究方向:机器视觉、深度学习。E-mail:756594764@qq.com
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
广州文博(2020年0期)2020-06-09 05:15:44
经济技术协作信息(2018年20期)2019-01-19 02:56:40
天津诗人(2017年2期)2017-03-16 03:09:39
中国工程咨询(2017年4期)2017-01-31 03:05:22
上海市经济管理干部学院学报(2016年4期)2016-06-15 20:29:07
兽医导刊(2016年6期)2016-05-17 03:50:15
中国民族医药杂志(2016年2期)2016-05-14 07:12:00
中国民族医药杂志(2016年4期)2016-05-09 07:41:15
