
移动云环境中数据流应用的Cloudlet选择策略研究
2019-02-25 01:27刘伟熊曙杜薇王伟
通信学报 2019年1期
刘伟,熊曙,杜薇,王伟
(1. 武汉理工大学计算机科学与技术学院,湖北 武汉 430070;2. 交通物联网技术湖北省重点实验室,湖北 武汉 430070;3. 同济大学计算机科学与技术系,上海 200092)
1 引言
随着移动互联网技术的迅猛发展,以智能手机为代表的移动设备越来越普及,据国际电信联盟数据显示,在 2017年全球智能手机拥有量预计达到43亿[1]。利用种类繁多的传感器,移动设备上产生了诸多如手势识别[2]、人脸识别[3]等移动数据流应用程序,这类应用对延迟比较敏感,运行时需要大量的计算资源,且会导致移动设备大量消耗电量。然而移动设备的电池容量、计算能力、存储空间等资源比较有限,在运行此类应用时,移动设备的电量面临着严峻的考验。移动云计算(MCC,mobile cloud computing)的出现为突破移动设备资源限制提供了可能[4],将应用的部分计算密集型任务通过计算卸载技术[5]卸载到远程的云计算中心上执行,有效地降低了移动设备的电量消耗,如 MAUI(mobile assistance using infrastructure)[6]、CloneCloud[7]、Odessa[8]等。
然而,远程云计算中心距离移动用户较远,通过广域网连接将会带来较高的网络延迟[9],很难保证移动数据流应用的服务质量要求。为此,美国卡内基梅隆大学 Satayanarayanan教授[10]首次提出Cloudlet(微云)这一概念,它是距离移动设备较近且资源丰富的一台或多台机器组成的计算机集群。移动设备可以通过局域网与Cloudlet直接相连,拥有带宽大和延迟低的优势[11]。因此,这种计算模式将移动数据流应用卸载到Cloudlet上执行,能够获得良好的用户体验。
随着移动云计算的发展和普及,各商家或单位部署有不同计算、存储和网络等资源的 Cloudlet,可以同时为区域内的用户提供服务。用户在运行诸如人脸识别等移动数据流应用时,如何依据周围Cloudlet收集的移动设备、应用特征和网络状况等信息,为应用选择合适的Cloudlet进行网络连接和计算卸载,以延长移动设备的续航时间和提高应用程序的性能成为亟待解决的问题。
针对这一问题,研究者们从不同的角度展开了工作。然而,这些工作大多只为移动设备上的应用选择单个Cloudlet进行计算卸载,对于拥有较多并行组件的移动数据流应用,如光学字符识别、QR二维码应用[12]、对象识别[13]等,性能提升有限。为此,本文提出了一种可以充分利用多个Cloudlet资源来最大化移动数据流应用并行执行效率的Cloudlet选择策略,为用户带来更短的应用完成时间和更低的移动设备能量消耗。本文主要贡献如下。
1) 建立了移动数据流应用的 Cloudlet选择问题的系统模型,旨在最小化应用完成时间和移动设备能耗,同时将问题定义为双目标的组合优化问题,并证明该问题是NP-hard问题。
2) 设计了一个动态调整的适应度函数,根据移动设备的剩余电量调整应用完成时间与移动设备能耗的权值,进而采用线性加权法将该双目标问题归一成单目标问题。
3) 提出了一种基于化学反应优化算法的Cloudlet选择策略CROCS(chemical reaction optimization Cloudlet selection strategy)。该策略能够在满足组件间依赖关系的前提下,充分利用移动数据流应用中可以并行执行的组件,提高了应用性能。
2 研究动机
本文所提出的移动数据流应用的Cloudlet选择策略的主要思想是将移动数据流应用的并行组件分散到多个Cloudlet上执行,以提高应用的执行效率,减少完成时间。然后,将通过一个具有一般拓扑结构的移动数据流应用程序——光学字符识别(OCR,optical character recognition)在多Cloudlet环境中运行的例子验证本文思想的正确性。
光学字符识别应用程序通过检查输入图片中的手写体或者印刷体字符,经过明暗处理后确定文字的形状,然后采用字符识别方法将其翻译成计算机文字。其应用程序结构如图1所示,其中组件v0为开始组件,表示获取输入图片;组件v1表示一维最大熵法计算阈值;组件v2表示最大类间方差法计算阈值;组件v3表示迭代法计算阈值;组件v4表示选择二值化;组件v5表示识别过程组件v6为结束组件,表示输出结果。组件v1、v2和v3为可以同时在不同 Cloudlet或者移动设备上执行的并行组件。其中各个组件的计算量分别为0、3 600、3 800、3 400、1 800、14 200和0(单位为百万条指令),边的权值表示组件之间的数据传输量大小,单位是KB。

图1 光学字符识别应用程序结构
如图2所示,当用户运行该应用程序时,周围有3个具有相同计算能力的Cloudlet(用C1、C2和C3表示)可作为计算节点,其中C1作为距离用户最近的代理 Cloudlet,用户会向其发送计算卸载请求,同时将移动设备的硬件信息发送给C1以备其做出选择策略。然后代理Cloudlet依据周围Cloudlet之间的带宽与距离、移动设备与各Cloudlet的计算能力与最早开始时间、代理Cloudlet与移动设备之间的距离和带宽等信息做出合适的选择策略[14],Cloudlet端和移动设备依据选择策略协同执行计算任务,最后将应用程序的结果返回到移动设备。设置移动设备与Cloudlet的计算能力分别为40 000和80 000,单位是每秒钟执行百万指令数,与不同Cloudlet之间的带宽为8 Mbit/s,Cloudlet之间的带宽为240 Mbit/s。采用不同选择方案对应的应用完成时间如表1所示。
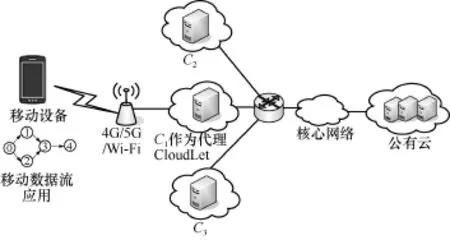
图2 移动数据流应用Cloudlet选择场景
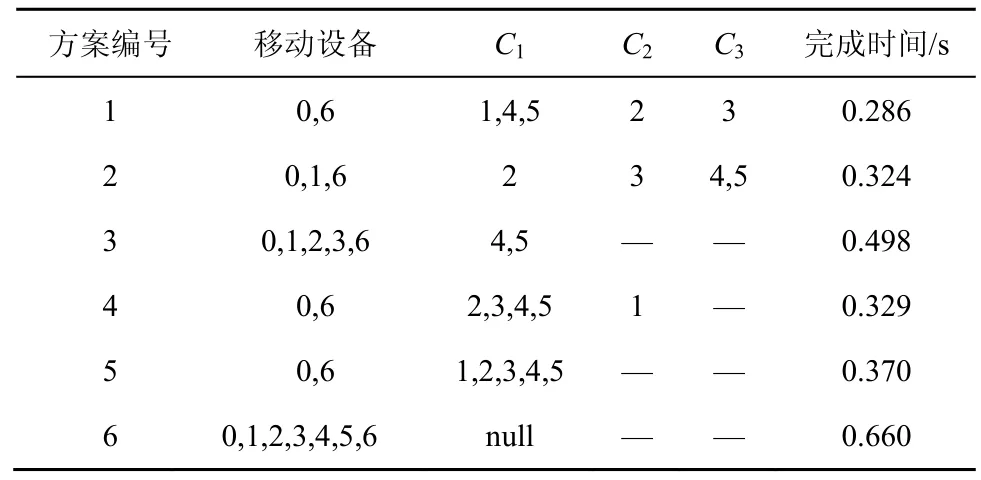
表1 不同选择方案对应的应用完成时间
通过以上例子表明,应用的完成时间随着不同的选择方案而不同,并且其中并行组件较为分散的方案(如方案1、2和4)相较于其他并行组件集中的方案(如方案3、5和6)对应的完成时间较低。因此可以通过选取合适的选择方案加快应用执行速度。下面基于这一思想建立相应模型、设计相应算法,找出合适的选择策略,并通过实验验证本文思想的正确性。
3 相关工作
随着人脸识别等移动数据流应用越来越流行和移动云计算的普及,用户在运行移动数据流应用时将常处于多Cloudlet环境中,如何选择Cloudlet为用户提供良好的服务是一个亟需解决的问题。在已有的工作中,文献[15]针对非集中式部署的多Cloudlet环境,提出了一种应用资源限制的选择策略,选择满足应用对资源需求的Cloudlet进行计算卸载。文献[16]依据距离进行选择,为应用优先选择距离用户最近的Cloudlet卸载应用。文献[17]考虑到离用户最近的Cloudlet未必能提供最好的计算能力和良好的网络质量,提出选择2个Cloudlet,其中一个拥有较好的网络连接,另一个拥有较好的计算能力来保证执行应用的性能。文献[18]则基于不同应用对资源需求具有差异化的特点,对已发现的Cloudlet按照满足应用特点的服务质量属性进行排名,依据该排名选择合适的Cloudlet进行卸载应用。文献[19]则考虑应用卸载过程中移动设备的能量消耗,选择移动设备能量消耗最低的Cloudlet。Mukherjee等[14]为了避免文献[16]中某些任务可能需要卸载到远程云带来较高延迟的情况,提出将最近的Cloudlet作为代理服务器,代理服务器通过广播请求获得周围Cloudlet的信息,依据获得的信息选择最低移动设备能耗或最低完成时间的Cloudlet 。文献[20]则将不同的应用部署到不同的Cloudlet上,而后依据应用种类选择 Cloudlet,系统中的应用性能得到了进一步的提升。
以上这些工作都没有考虑具有一般拓扑结构的移动数据流应用有许多并行部分,可以在多个计算节点上执行。文献[21]利用这些并行部分,使应用的部分组件在移动设备上执行,部分组件在 Cloudlet上执行,提升了应用执行效率,进而减小了应用的完成时间。中国科学技术大学的刘炜清等[22]针对单个 Cloudlet与移动设备的带宽有限从而限制了移动数据流应用吞吐量的问题,提出利用将部分组件的实例放置到其他 Cloudlet上执行,提高了应用的吞吐量。与之对比,本文工作主要是充分利用多个Cloudlet的资源使移动数据流应用的并行组件同时执行,提升了应用执行效率,使移动数据流应用的完成时间最小化,降低移动设备能耗。
4 系统模型
本文的目标是寻找一种适合移动数据流应用的Cloudlet选择策略以最小化应用的完成时间和移动设备能量消耗。为解决这一问题,首先需要对相关概念和移动数据流应用进行建模,进而建立相应的完成时间和移动设备能耗建立模型。
4.1 相关概念模型
1) 移动设备
移动设备可以用一个八元组表示,mobile={power, capacity,Pidle,Pcomp,Pts,Ptr,J,DJ},其中,power表示移动设备的剩余电量,capacity表示移动设备的计算能力(单位是MIPS),Pidle表示移动设备CPU处于空闲状态时的功率,Pcomp表示移动设备CPU处于计算状态时的功率,Pts表示移动设备发送数据的功率,Ptr表示移动设备接收数据的功率,J表示代理Cloudlet编号,DJ表示移动设备与代理Cloudlet的距离。
2) Cloudlet
系统中的Cloudlet可以通过Cloudlets=(C,D)表示,C表示Cloudlet的集合,D表示Cloudlet之间的关系。C={Cloudlet1, Cloudlet2,…, Cloudletm},|C|=m。对于C中每一个 Cloudlet可以使用一个三元组表示,Cloudletj={j, capacityj,Qj},其中j表示编号,capacityj表示计算能力大小(单位是MIPS),Qj表示最早开始执行时间。
由于系统中存在多个 Cloudlet,它们之间的关系主要通过距离体现,所以采用一个矩阵D表示其距离关系,其中,di,j表示Cloudleti与 Cloudletj之间的距离(单位是 m),有di,j=dj,i,且当i=j时,di,j=0。
3) 网络连接
网络连接主要由2个部分组成,分别是移动设备与代理Cloudlet之间的网络,以及Cloudlet之间的网络。移动设备与代理Cloudlet之间的上传和下载带宽分别为Bu和Bd;Cloudlet之间通过带宽相同的有线网络连接,带宽单位是B。
4) Cloudlet选择策略
移动数据流应用中的每一个组件可以在Cloudlet或移动设备上执行,对于一个由n个组件组成的移动数据流应用,其Cloudlet选择策略可以使用一个n维向量表示,X={x1,x2, … ,xn},xi∈[0,m],其中xi表示第i个组件的执行位置。当xi=0时,表示该组件在移动设备上执行,当xi∈[1,m]时,表示该组件在Cloudletxi上执行。
4.2 移动数据流应用模型
移动数据流应用可以建模成有向无环图G(V,E),其中V={v1,v2, … ,vn}表示组件的集合,E表示组件之间的依赖关系。对于V中每一个组件vi可以用一个三元组表示,vi={i,xi, Ii},其中i为组件编号,xi为组件vi选择的 Cloudlet位置,Ii为组件vi的指令数。E中每条边的权重dataj,k表示组件vj和vk之间传输的数据量大小。如图1所示,入口组件v0和出口组件v6表示虚拟组件,且这2个组件必须在移动设备上执行。
4.3 应用完成时间模型
完成时间[8]是移动数据流应用一个重要的性能指标,表示应用程序从数据输入到结果输出的时间。完成时间越低表示应用的响应速度越快,用户体验越好。
对于Cloudlet选择策略X,因为应用的组件可以在不同的位置执行,执行时组件之间会产生数据传输时间和传播时间,其中包含并行组件在多个Cloudlet或移动设备上并行执行产生的额外通信时间开销。对于组件vk和vi之间的数据传输时间transk,i可以由式(1)计算。

其中,当xk=0且xi≠0,J时,表示组件vk在移动端执行,vi在除代理 CloudletJ之外的其他CloudLetxi上执行,其数据传输时间由 2个部分组成:1) 数据从移动设备传输到代理 CloudletJ的时间,2) 数据由代理CloudletJ传输到Cloudletxi上的时间。当xk=0且xi=J时,即组件vk在移动设备上执行,组件vi在代理CloudletJ上执行,其数据传输时间为组件间的数据量 datak,i与移动设备上传数据带宽Bu的比值。当xk,xi∈[1,m]且xi≠xk时,即组件vk和组件vi在不同的Cloudlet上执行,其数据传输时间为组件间的数据量 datak,i与Cloudlet之间的带宽 B的比值。当xk≠0,J且xi=0时,即组件 vk在除了代理 CloudletJ之外的CloudLetxk上执行,组件 vi在移动设备上执行,其数据传输时间包括数据从Cloudletxk传输到代理CloudletJ的时间和数据从代理CloudletJ传输到移动设备的时间。当xk=J且xi=0时,表示组件vk在代理CloudletJ上执行,组件vi在移动设备上执行,其数据传输时间为组件间的数据传输量datak,i与移动设备下载数据的带宽的比值。当xi=xk时,表示组件vk和组件vi在同一位置执行,其数据传输时间为0。
组件vk和vi之间的传播时间tpropk,i可以由式(2)得出。

其中,S为传播速度,大小为2×108m/s[23]。当xk=0,xi∈[1,m]时,其数据传播时间包括2个部分:1) 组件vk所在的移动设备与代理CloudletJ之间的传播时间;2) 代理CloudletJ与组件 vi所在Cloudletxi之间的传播时间。当 xk, xi∈[1,m]且 xi≠ xk,即组件 vk和vi在不同Cloudlet上执行,其传播时间为两组件所选择执行位置的距离与传播速度比值。当xk∈[1,m],xi=0时,其数据传播时间包括组件 vk所选择的Cloudletxk与代理 CloudletJ之间的传播时间和代理CloudletJ与组件vi所在移动设备的传播时间。当xk=xi时,即组件vk和vi在同一个位置执行,其传播时间为0。
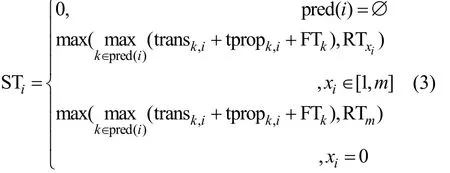
由此可以得到组件vi的开始执行时间STi和完成时间 FTi的计算式,如式(3)和式(4)所示。其中,使用pred(i)表示vi的前驱组件的集合。transk,i和tpropk,i分别表示组件vk和vi之间的数据传输时间和数据传播时间。RTxi表示Cloudletxi的最早开始执行时间,初始为Qxi,在组件选择执行位置后对RTxi进行更新。RTm表示移动设备的最早开始执行时间,初值为 0,在组件选择执行位置后对 RTm进行更新。当组件vi的前驱组件集合为空时,即vi为开始组件,其开始执行时间为0;当xi∈[1,m],即组件vi的执行位置在Cloudletxi,其开始执行时间为前驱组件中最晚将数据传输到Cloudletxi的时间与其最早开始执行时间RTxi的最大值;当xi=0时,即组件vi的执行位置为移动设备,其开始执行时间为前驱组件中最晚将数据传输到移动设备的时间与移动设备最早能开始执行时间 RTm的最大值。
组件vi的完成时间可以由式(4)计算。
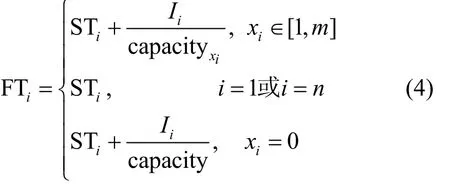
当i=1或i=n时,即组件vi为开始组件和结束组件时,其完成时间为其开始执行时间;当组件vi不是开始组件或者结束组件时,完成时间为其开始执行时间加上其所在执行位置上的执行时间。
由此,可以得到应用的完成时间为

4.4 移动设备能耗模型
移动设备能耗主要由无线网络接口、屏幕、CPU、GPS等部件产生的能耗[24]组成,本文主要考虑无线网络接口数据传输和CPU能耗。
4.4.1 数据传输能耗
本文中数据传输能耗包括数据发送和接收时移动设备能量消耗。
1) 数据发送能耗

其 中 ,succ(i)表示组 件 vi后继组 件 的集 合,表示移动设备无线网络发送数据所用时间的总和。
2) 数据接收能耗
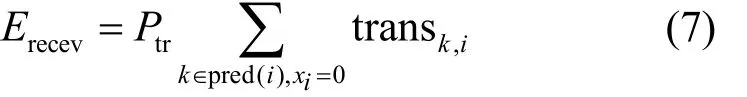
4.4.2 CPU能耗
CPU能耗包括计算能耗和空闲能耗。计算能耗表示有组件在移动设备上执行时CPU的能量消耗,空闲能耗为没有组件在移动设备上执行时 CPU处于空闲状态的能量消耗。
1) 计算能耗
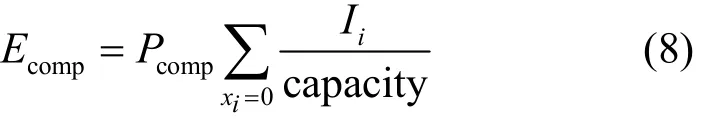
2) 空闲能耗
空闲时间可以通过完成时间减去数据发送时间、数据接收时间和计算时间计算。

由此可以计算出空闲能耗

则移动设备能耗可以表示为

4.5 问题定义
在4.3节和4.4节分别介绍了移动数据流应用的完成时间模型和移动设备能耗模型。对于给定的应用、移动设备和Cloudlets等信息,可以得到任意Cloudlet选择策略X对应的应用完成时间FT和移动设备能耗Etotal。本文的Cloudlet选择问题是寻找合适的Cloudlet选择策略X,最小化应用的完成时间和移动设备能耗,可以由式(12)定义。

约束条件如下。
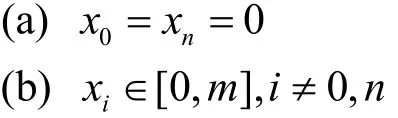
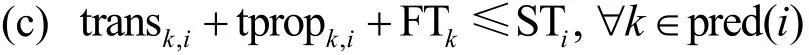
限制条件(a)表示入口组件 v0和出口组件 vn必须在移动设备上执行,限制条件(b)表示中间组件的执行位置为移动设备或者 Cloudlet;限制条件(c)表示组件之间的依赖关系,即组件vi开始执行之前必须等待其前驱组件执行完成并将所需数据传输到该组件vi所在执行位置。
命题1式(12)是一个NP-hard问题。
证明假设不考虑移动设备能耗,该问题就变成了最小化应用完成时间的单目标组合优化问题,并且认为开始组件和结束组件可以在任何计算节点上执行,则该问题可规约成式(13)形式。

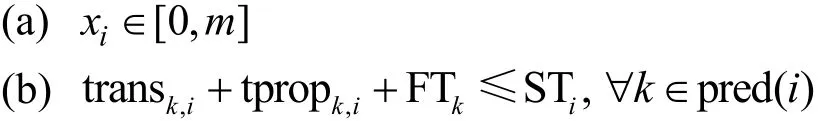
约束条件如下。
而式(13)与并行程序在并行计算机系统最小化完成时间的调度问题[25]等价。依据文献[26],该问题的特殊情况是 NP-hard问题,所以式(12)的问题也是NP-hard问题。证毕。
5 算法设计
由4.5节可知该Cloudlet选择问题是一个双目标的组合优化问题[27],且属于NP-hard问题。而化学反应优化算法是通过模拟分子运动这一自然现象得到的一种通用元启发式算法[28],可以用于求解此类组合优化问题,并且该Cloudlet选择问题与网格计算中多目标任务调度和人工神经网络中参数优化问题相似,在文献[29-30]中已经用实验表明了化学反应优化算法相较于其他启发式搜索算法在求解该类问题上的性能优势。因此,本文采用基于化学反应优化的启发式算法求解。在化学反应优化算法中包括分子和基本化学反应两大因素,其中每个分子包含3个重要组成部分:分子结构、势能和动能。本文中分子结构对应着Cloudlet选择问题的解,势能决定分子结构的稳定程度,其在本文为Cloudlet选择策略的目标函数值,动能是系统中判断是否发生反应的量化值。基本化学反应包括单分子碰撞、单分子分解、分子间碰撞和分子合成4种,通过这4种化学反应操作使分子结构不断变得稳定的过程,同样对应着在问题求解空间内不断寻求更优Cloudlet选择策略的过程。
5.1 问题编码
针对本文移动数据流应用的Cloudlet选择问题,采用十进制编码方式对分子结构进行编码,分子中的原子对应于组件的选择位置,则其整个的分子结构对应于一个Cloudlet选择策略。例如对于图1中光学字符识别应用对应的一种分子结构X={0,1,2,3,1,1,0},表示组件v0和v6在移动设备上执行,组件v1、v4和v5在Cloudlet1上执行,组件v2在Cloudlet2上执行,组件v3在Cloudlet3上执行。
5.2 适应度函数
本文Cloudlet选择策略的目标是最小化移动数据流应用的完成时间和移动设备能耗。这里通过简单的线性加权将2个目标归一为单目标,所以对于该问题的适应度函数f(X)可以使用式(14)表示。
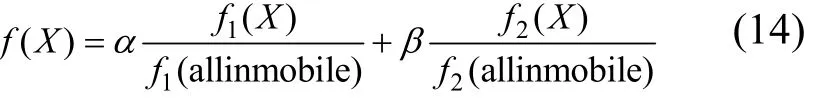
其中,函数f1(X)和f2(X)分别表示 Cloudlet选择策略X对应的应用完成时间和移动设备能耗。f1(allinmobile)表示应用程序的所有组件都在移动设备上执行的能耗,f2(allinmobile)表示应用程序的所有组件都在移动设备上执行的完成时间。α和β分别表示用户依据移动设备剩余电量对完成时间和移动设备能耗的权重要求,其中α,β∈(0,1)且满足α+β=1。当移动设备剩余电量较为充足时,应用的完成时间作为主要优化目标,可以设置α>β;当剩余电量不足时,移动设备能耗作为主要优化目标,可以设置α<β。
5.3 分子操作设计
1) 单分子碰撞
单分子碰撞ineff_coll(X,x1):是指单个分子碰撞容器壁改变其势能和动能的过程。分子的结构X发生轻微变化,产生新的分子结构x1,利用这一特点进行问题求解空间的领域搜索。
本文具体设计采用在原分子(原Cloudlet选择策略)X中,随机选择一个原子,随机变换其值(组件的选择位置),产生新的分子(新 Cloudlet选择策略)x1。
2) 单分子分解
单分子分解 decompose(X,x1,x2):是指动能较大的分子与容器壁发生碰撞后,分解成2个分子的过程。分子X发生单分子分解后,将产生2个新的分子x1和x2,单分子分解反应过程中对分子结构的改变较大,用于提高算法的全局搜索能力。
本文具体设计采用原分子(原Cloudlet选择策略)X随机产生一个分解点,新分子(新 Cloudlet选择策略)x1获得原分子X分解点之前的所有原子(组件的选择位置),新分子(新Cloudlet选择策略)x2获得原分子X分解点之后的所有原子,其余部分随机产生。
3) 分子间碰撞
分子间碰撞 iter_ineff_cole(X1,X2,x1,x2):是指2个分子发生碰撞后产生2个新分子的过程,即原分子X1和X2发生分子间碰撞之后产生新分子x1和x2。分子间碰撞与单分子碰撞类似,反应剧烈程度都不大,对分子结构的改变较小,用于在邻域空间搜索问题的解。
本文具体设计采用类似遗传算法中单点交叉的方式,随机选择一个位置作为碰撞点,新分子(新Cloudlet选择策略)x1获得原分子(原 Cloudlet选择策略)X1碰撞点之前的原子(组件的选择位置)和(原 Cloudlet选择策略)X2碰撞点之后的原子,新分子(新 Cloudlet选择策略)x2获得原分子X1碰撞点之后的原子和原分子X2碰撞点之前的原子。
4) 分子合成
分子合成反应synthesis(X1,X2,x):是指2个分子碰撞后合成一个新分子的过程,即原分子X1和X2发生分子合成碰撞后产生x。由于分子合成反应对分子结构的改变很大,提高分子搜索新区域能力,用于增强算法全局搜索能力。
本文具体设计采用随机生成一个划分点,碰撞后的新分子(新Cloudlet选择策略)x获得原分子(原 Cloudlet选择策略)X1的划分点之前原子(组件的选择位置)和获得原分子(原Cloudlet选择策略)X2的划分点之后原子。
5.4 算法描述
算法 1给出了基于化学反应优化算法的Cloudlet选择策略(CROCS),其对应的流程图如图3所示。对于给定的移动设备mobile、Cloudlets、应用程序G(V,E)等信息,CROCS算法会得到一个近似最优的选择策略X。
该算法分为3个阶段:初始阶段、迭代过程和最后阶段。在初始阶段(算法1中1)~11)),初始化系统参数并随机产生PopSize个选择策略分子组成的分子群,计算每一个分子的适应度值,初始化其势能和动能。随后进入迭代阶段(算法 1中12) ~27)),迭代阶段结束条件由初始设置的迭代次数MaxIter决定。在每一次迭代过程中,首先由在[0,1]之间的随机数t与系统参数MoleColl值的大小关系决定发生单分子反应还是发生分子间的反应。当随机数t大于系统参数MoleColl,随机从分子群中选择一个分子,如果分解反应条件满足,则发生单分子分解反应,否则发生单分子碰撞反应。当随机数t小于系统参数MoleColl,随机从分子群中选择2个分子,如果合成反应条件满足,则发生分子合成反应,否则发生分子间碰撞反应。在最后阶段(算法1中 28)~29)),从分子群中得到所含势能最小的分子作为最终的Cloudlet选择策略。
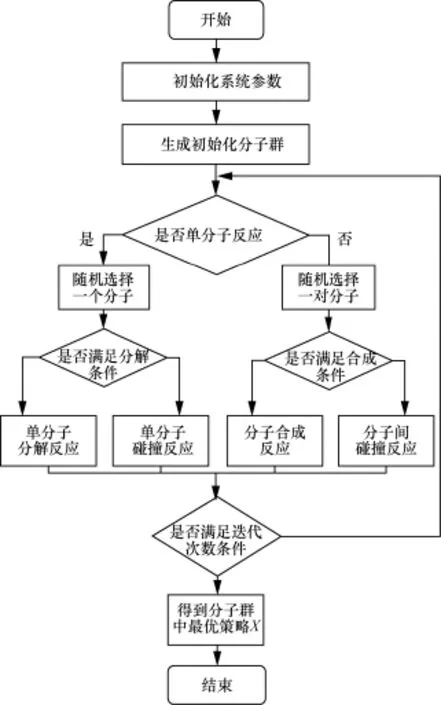
图3 CROCS算法流程
算法1基于化学反应优化算法的Cloudlet选择策略(CROCS)
输入Mobile,Cloudlet,G(V,E),迭代次数MaxIter,权重参数α和β
输出选择策略X
1) 初 始 化 PopSize,Molecules,MoleColl,InitialKE/*PopSize为分子群初始规模,Molecules为分子群,MoleColl为分子反应决定类型因子,InitialKE为初始动能*/
2)i←1
3) whilei≤PopSize
4) 随机生成一个Cloudlet选择策略分子X
5)f2(X)←computfinishtime(X)/*依据式(5)计算选择策略分子X对应的应用完成时间*/
6)f1(X)←computtotalenergy(X)/*依 据式(11)计算选择策略分子X对应的移动设备能耗*/
7) PE[X]←computeFitness(X)/*依据式(14)计算选择策略分子X的适应度并初始化势能*/
8) KE[X]←InitialKE /*初始化策略分子X的动能*/
9) 将分子X加入到分子群Molecules中
10)i←i+1
11) end while
12)j←1
13) whilej≤MaxIter /*迭代 MaxIter次*/
14)t=random(0,1)
15) if (t> MoleColl)
16) 随机从分子群Molecules中选择一个分子X
17) if (decomposition criterion met)then
18) decompose(X,x1,x2)/*发生单分子分解反应*/
19) else
20) ineff_coll(X,x1) /*发生单分子碰撞反应*/
21) else
22) 随机从分子群Molecules中选择2个分子X1和X2
23) if (synthesis criterion met) then synthesis(X1,X2,x)/*发生分子合成反应*/
25) else
26) iter_ineff_cole(X1,X2,x1,x2)/*发生分子间碰撞反应*/
27) end while
28)X←findthebest(Molecules)/*从分子群中找到最优的策略*/
returnX
5.5 解空间分析
本节将分析问题的解空间,并给出选择化学反应算法求解该问题的原因。
1) 解空间大小
如上文模型所述,对于一个拥有n个组件的应用。除开始和结束组件外,其每一个组件的选择位置为m个Cloudlet或移动设备,即可选择位置个数为m+1,故解空间的大小为(m+1)n-2。
2) 可选算法分析
求解这类组合优化问题的算法可以分为确定性算法(如线性规划等)和启发式算法(如化学反应优化算法、模拟退火算法和遗传算法[31]等)。然而确定性算法在这种指数级的解空间大小下,将面临组合爆炸问题。在启发式算法中,化学反应优化算法能够通过 4种基本化学反应实现启发式搜索。其中单分子碰撞和分子间碰撞反应作用于邻域搜索;分子合成和单分子分解反应作用于全局搜索。因而化学反应算法相较于其他启发式算法,能够避免过早地陷入局部最优。因此,在本文中采用化学反应优化算法求解该问题。
5.6 时间复杂度分析
假设初始分子群的规模为 PopSize,应用的组件个数为n,迭代次数为MaxIter。在初始阶段生成PopSize个分子的分子群,并初始化每一个分子的动能和势能,计算势能时需要计算一次适应度,而计算适应度函数的时间复杂度为O(n),故在初始阶段的时间复杂度为O(PopSize×n)。在迭代阶段,单分子分解反应的时间复杂度为O(n),单分子碰撞反应的时间复杂度为O(1),分子合成反应的时间复杂度为O(n),分子间碰撞反应的时间复杂度为O(1),所以在4种分子操作过程中的平均复杂度为O(n),同时还需要计算新分子的适应度函数。迭代次数为 MaxIter,所以迭代过程中的时间复杂度为O(MaxIter×n×n)。综上所述,整 个 算 法 的 时 间 复 杂 度 为O((MaxIter×n+PopSize)×n)。
5.7 算法收敛性分析
化学反应算法收敛性主要取决于化学反应操作算子[32],经过基本的化学反应之后,令选择策略X1到选择策略X2的转换概率 P(X1→X2)>0, 选择策略X1和X2属于选择策略任意元素。由于每一次迭代的独立性,经过MaxIter次迭代过程后,算法不能从次优解达到全局最优解的概率是1- (1-p)MaxIter。因此算法经过 MaxIter次迭代后能够达到最优解的概率是1-(1-p)MaxIter,当MaxIter→∞时,可以得到最优解的概率为所以当迭代次数足够多时,算法总会收敛于全局最优解。
6 仿真实验与结果分析
6.1 仿真实验环境配置
1) Cloudlet和移动设备配置
实验中的Cloudlet由以下3台服务器模拟,配置信息如表2所示。使用Cloudlet1作为代理Cloudlet,Cloudlet2、Cloudlet3作为其他计算服务器。其中Cloudlet2计算能力最强,Cloudlet3其次,作为代理的Cloudlet1计算能力最弱。

表2 Cloudlet配置
实验采用的移动设备为智能手机,其配置、CPU和无线接口在不同状态下功率(单位是 mw)信息如表3所示,其中CPU功率和无线网络接口功率等信息是依据Android操作系统应用程序框架提供的能耗分析配置文件(PowerProfile.xml)获得。

表3 移动设备配置
2) 网络配置
实验中的网络配置分为2个方面:Cloudlet与移动设备之间的网络,移动设备的默认上传带宽Bu和下载带宽Bd设置为8 Mbit/s;Cloudlet之间的网络,本文Cloudlet之间的带宽B大小相同,同时Cloudlet选择策略的结果与Cloudlet之间的带宽大小有关,所以采用4种不同的Cloudlet之间的带宽,分别是10 Mbit/s、30 Mbit/s、50 Mbit/s和210 Mbit/s。
3) 移动数据流应用配置
为了不失一般性,实验采用应用模型如图1所示的光学字符识别移动数据流应用程序进行实验。
6.2 实验结果分析
在本节中,将CROCS策略与已有的2种策略:H-PSP(heuristic based on partial stochastic path)[21]和 POCSS(power and latency aware optimum Cloudlet selection strategy)[14]进行对比,其中 H-PSP策略联合利用移动设备和单个Cloudlet的计算能力,并以最小化应用的完成时间为目标,其中单个Cloudlet选取计算能力最强的Cloudlet作为组件候选的执行位置;POCSS策略是选择一个应用的完成时间最小或移动设备能耗最低的 Cloudlet,并将应用的所有可卸载的组件全都卸载到一个Cloudlet上进行执行。
为了验证本文算法有效性,首先,以应用的完成时间和移动设备能量消耗作为性能指标,采用控制变量法,分别改变Cloudlet之间的带宽、Cloudlet个数、应用程序并行组件指令数在总指令数中的占比和参数α等影响因素,然后统计分析应用的完成时间和移动设备能耗随这些因素的变化规律。其次,通过引入已经广泛应用的遗传算法进行对比,考察其收敛特性。
1) Cloudlet之间的带宽的影响
本组实验研究Cloudlet之间的带宽对应用的完成时间和移动设备能耗的影响,实验参数的配置如表4所示。

表4 实验1环境配置
本实验中设置 Cloudlet个数为 3个,分别为Cloudlet1、Cloudlet2和 Cloudlet3,移动设备与Cloudlet之间的带宽为8 Mbit/s,并行组件指令数在总指令数中占比为初始的40%,Cloudlet之间的带宽分别取10 Mbit/s、30 Mbit/s、50 Mbit/s。具体实验结果如图4所示。
如图4(a)所示,随着Cloudlet之间带宽的增大,CROCS策略和POCSS策略的应用完成时间随之减小,而H-PSP策略没有变化。CROCS策略和POCSS策略都需要通过代理Cloudlet与其他Cloudlet进行交互,所以Cloudlet之间的带宽增加降低了组件间数据传输成本,减小了应用的完成时间。在Cloudlet之间的带宽较低的情况下,较高的数据传输时间成本使得CROCS策略没有发挥其充分利用应用的组件间并行性优势,使得CROCS策略在Cloudlet之间的带宽较小的条件下并没有优势。随着 Cloudlet之间的带宽的增加,组件之间的传输时间成本降低,CROCS策略可以充分利用应用的并行性,进而与其他 2种策略相比在完成时间上有明显的优势,相较于H-PSP策略和POCSS策略在完成时间上平均有3%和14.8%的性能提升。
如图 4(b)所示,随着 Cloudlet之间带宽的增大,CROCS策略和POCSS策略的移动设备能耗都越来越小,且都处于较低的水平。由于两者都没有任何组件在移动设备上执行,移动设备能耗主要由数据传输能耗和空闲能耗组成,Cloudlet之间的带宽增加使这两者策略的应用完成时间都有所降低(如图 4(a)所示),由此降低了一定的空闲能耗,但空闲能耗在总能耗中占比太低,对于移动设备能耗的降低并不明显。而H-PSP策略的移动设备能耗相较于其他2种策略较高,其原因是H-PSP策略会使用移动设备资源执行一定的并行组件以减小应用的完成时间,从而带来了较高的计算能耗。综合来看,相较于H-PSP策略和POCSS策略在移动设备的能耗上平均有70.5%和6%的能耗降低。

图4 Cloudlet之间的带宽对应用完成时间和移动设备能耗的影响
2) Cloudlet个数的影响
本组实验研究Cloudlet个数对应用完成时间和移动设备能耗的影响,实验参数的配置如表5所示。

表5 实验2环境配置
本实验中,为了减小Cloudlet之间的带宽对本实验的影响,将其设置为210 Mbit/s,移动设备与Cloudlet之间的带宽为8 Mbit/s,并行组件指令数在总指令数中占比为40%,Cloudlet个数依次为1个、2个、3个和4个,当Cloudlet个数为超过3个时,超过部分采用Cloudlet3模拟。具体实验结果如图5所示。
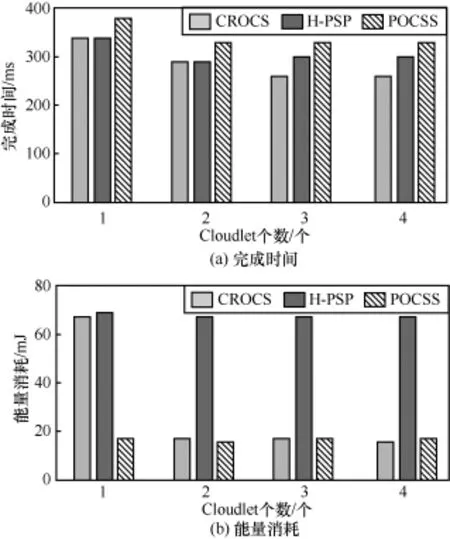
图5 Cloudlet个数对应用完成时间和移动设备能耗的影响
如图 5(a)所示,随着 Cloudlet个数的增加,CROCS策略的应用完成时间逐渐减小。当Cloudlet个数从一个增长到3个时,主要是由于CROCS策略会使应用中更多的并行组件能够分散到多个Cloudlet上并行执行,从而降低了应用的完成时间,而当Cloudlet个数与光学字符识别并行组件达到相同的3个时,应用的并行程度达到最大,此时进一步增加Cloudlet规模,应用完成时间的降低是通过引入了计算能力较强的Cloudlet加快应用效率实现的。对于H-PSP策略和POCSS策略,Cloudlet个数从一个增加到 2个的时候,完成时间有所降低,其后则保持不变。原因是引入了计算能力更强的Cloudlet2,H-PSP策略和POCSS策略会主要使用计算能力更强的Cloudlet2进行计算卸载,从而降低了应用的完成时间,当Cloudlet个数进一步增加,这2种策略仍然只使用该计算能力较强的Cloudlet2,所以并不会影响应用的完成时间。综合来看,相较于H-PSP策略和POCSS策略,CROCS策略在完成时间上平均有4.5%和12%的性能提升,最好情况下分别能达到12.1%和22.3%。
如图 5(b)所示,随着 Cloudlet个数的增加,CROCS策略的移动设备能耗也随着降低。当Cloudlet个数从一个增加到2个的时候,CROCS策略的移动设备能耗显著降低,这是由于当 Cloudlet个数只有一个 Cloudlet时,CROCS策略会利用移动设备的计算能力,将部分组件留在移动设备上执行,会产生较高的移动设备计算能耗。随着Cloudlet个数进一步增加,应用的并行组件能够分散到其他Cloudlet上执行,从而显著降低了移动设备的能耗。H-PSP策略在Cloudlet个数较多的时候依然需要利用移动设备的计算能力,从而会一直产生较高的移动设备能耗。相比之下,CROCS策略的移动设备能耗在 Cloudlet个数足够多时相较于 H-PSP和POCSS策略分别减小了77.1%和5.9%。
3) 应用程序并行组件指令数在总指令数中占比的影响
本组实验为了进一步验证CROCS策略对于组件之间可并行部分充分利用的特性,在保持应用的总指令数不变前提下,将光学字符识别中的3个并行组件指令数与全部组件的指令数的比例逐步提高,探究应用的并行性对选择策略的影响。具体实验配置如表6所示。

表6 实验3环境配置
本组实验中,Cloudlet之间带宽设置为210 Mbit/s,移动设备与Cloudlet之间的带宽为8 Mbit/s,Cloudlet个数为3个,应用中并行组件指令数占比为40%、60%、80%。具体实验结果如图 6(a)和图 6(b)所示。

图6 并行组件指令数占比对应用完成时间和移动设备能耗的影响
如图6(a)所示,随着并行组件指令数占比越来越高,CROCS策略和H-PSP策略的应用完成时间会相应减小,而 POCSS策略没有变化。主要是因为在CROCS策略和H-PSP策略中,可以并行执行组件的指令数增多,同时执行的效率更高,加快了应用的执行速度,从而降低了应用的完成时间。但CROCS策略相较于H-PSP策略,其应用完成时间减小的幅度更为明显,这是由于CROCS策略对于并行组件的并行程度利用得更加充分。而 POCSS策略中应用程序的所有组件都只在同一个 Cloudlet上执行,并没有考虑到组件间的并行性,所以并行组件指令数占比对其没有影响。综合来看,随着并行组件的指令数占比的增加,CROCS策略的应用完成时间相较于其他2种策略优势更加明显。具体来说,相较于H-PSP策略和POCSS策略在完成时间上有19.3%和28.2%的性能提升。
如图6(b)所示,随着并行组件指令数占比越来越高,CROCS策略的移动设备能耗相较于 H-PSP策略优势越来越明显。由于H-PSP策略中需要在移动设备上执行的指令数的增加,导致移动设备CPU处于计算状态的时间相应增长,且 CPU计算功率相较于网络接口的数据传输功率和 CPU空闲功率较高,从而显著增加了移动设备能耗,所以相较于H-PSP策略,CROCS策略在移动设备能耗上有较大优势。其次,CROCS策略和POCSS策略的所有组件都是在Cloudlet上执行,其移动设备能耗主要只由两部分组成,网络接口的数据传输能耗和CPU空闲能耗。虽然CROCS策略的应用完成时间降低了不少(如图6(a)所示),但是CPU空闲功率太小,并没有大幅降低移动设备能耗。所以CROCS策略和 POCSS策略相比,移动设备能耗相差不大。综合来看,相较于H-PSP策略和POCSS策略在移动设备的能耗上平均有83.7%和4%的能耗减小。
4) 移动设备与Cloudlet之间带宽的影响
本组实验为了验证移动设备与Cloudlet之间的带宽对应用完成时间和移动设备能耗的影响,实验参数配置如表7所示。

表7 实验4环境配置
本实验中设置Cloudlet之间的带宽为210 Mbit/s,Cloudlet个数为3,参数α为0.5,并行组件指令数占比为40%,移动设备与Cloudlet之间的带宽分别设置为4 Mbit/s、8 Mbit/ss和12 Mbit/s。具体实验结果如图7所示。
如图7(a)所示,随着移动设备与Cloudlet之间的带宽增大,CROCS、H-PSP和POCSS策略的应用完成时间都随之降低,这是由于随着移动设备与Cloudlet之间带宽的增大提高了移动设备与Cloudlet端的数据传输效率,从而减小了应用完成时间。与此同时,CROCS策略的应用完成时间相较于H-PSP和CROCS策略在完成时间相对较小,这是因为 CROCS策略能够更加充分的利用多个Cloudlet计算能力加快应用执行效率,进而CROCS策略相较于其他2种策略在完成时间较优。
图7(b)展示了不同移动设备与Cloudlet之间的带宽对移动能耗的影响。从中可以看出随着移动设备与Cloudlet之间带宽的增大,3种选择策略的移动设备能耗都相应降低。这是由于移动设备与Cloudlet之间的带宽的增加导致移动设备的网络接口处于数据传输时间降低,从而移动设备的数据传输能耗随之降低,并最终降低了移动设备能量消耗。同时还可以看出 CROCS和 POCSS策略相较于H-PSP策略,移动设备能耗处于较低水平,这是由于H-PSP策略优化目标主要是应用的完成时间,其对移动设备计算能力的使用产生了较多能耗。
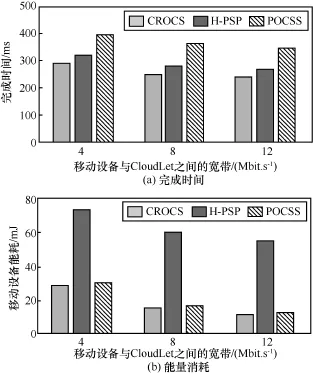
图7 移动设备与Cloudlet之间的距离对应用完成时间和移动设备能耗的影响
5) 参数α的影响
本组实验为了探究参数α对应用完成时间和移动设备能耗的影响,实验参数的配置如表8所示。

表8 实验5环境配置
本组实验中,Cloudlet之间带宽设置为210 Mbit/s,移动设备与Cloudlet之间的带宽为8 Mbit/s,Cloudlet个数设置为2个,应用中并行组件指令数占比为40%,参数α分别设置为0.1、0.5和0.9。具体实验结果如图8所示。
图8(a)表示参数α对应用的完成时间的影响。随着参数α的增大,本文提出的CROCS策略的应用完成时间相应变小。这是由于参数α的增大表示主要优化目标越来越偏向于应用的完成时间,从而导致CROCS策略会选择使用移动设备的计算资源执行部分并行组件,减小了应用的完成时间。而H-PSP和POCSS策略不受参数α的影响,所以其应用的完成时间没有变化。
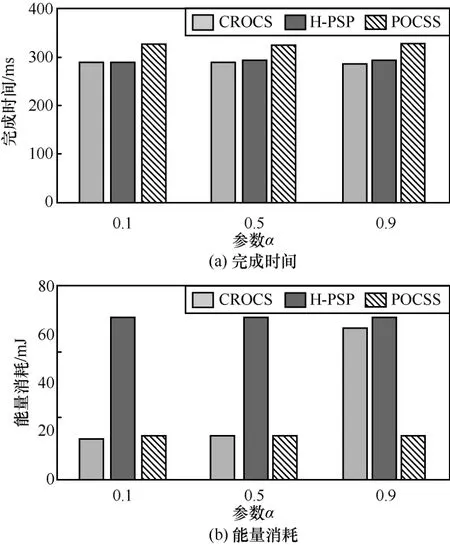
图8 参数α对应用完成时间和移动设备能耗的影响
图8(b)表示参数α对移动设备能耗的影响。随着参数α的增大, CROCS策略的移动设备能耗随之增大。这是由于参数α的增大导致CROCS策略会选择使用移动设备的计算资源执行部分并行组件减小应用完成时间,从而移动设备将产生较大的计算能耗,因此移动设备的能耗相应增加。同样地,参数α对POCSS和H-PSP策略没有影响,所以其移动设备能耗没有变化。综上所述,实验结果表明CROCS策略可以通过调整应用的完成时间和移动设备能耗的权重参数α动态地给出选择策略,达到了预期的效果。
6) 收敛特性
为了考察化学反应优化算法在求解此类组合优化问题时的收敛特性,选取已经被广泛应用的遗传算法(GA,genetic algorithm)和离散粒子群优化算法(DPSO,discrete particle swarm optimization)[33]与之进行对比。
其中CROCS参数设置为:分子群规模PopSize为40,分子反应决定因子MoleColl为0.2,初始动能InitialKE为500,迭代次数MaxIter为500。GA参数设置为:种群规模为40,变异概率为0.02,交叉概率为0.8,迭代次数为500。DPSO的参数设置为:粒子群规模为40,惯性常数为0.8,加速度系数为0.5,迭代次数为500。分别独立运行30次,CROCS与GA、DPSO算法运行的结果如表9所示,收敛曲线如图9所示。

表9 CROCS与GA、DPSO运行结果

图9 收敛曲线
如表9所示,CROCS相较于GA和DPSO策略得到全局最优解的概率更高。其次,对应的平均适应度和最大适应度值也相对于GA和DPSO策略更优,并且从标准差看CROCS策略有更高的求解稳定性。因此,CROCS相较于GA和DPSO策略有更好的全局收敛性。
图9为CROCS与GA、DPSO策略的收敛曲线。CROCS的收敛曲线相较于GA策略更接近与底线,并且收敛的速度相对较快;而DPSO虽然在计算初期收敛速度较快,但很快陷入局部最优解,无法跳出。因此,CORCS策略可以更快地跳出局部最优解,而GA和DPSO更易于陷入局部最优,无法找到全局最优解。主要因为化学反应优化算法中单分子分解和分子合成的分子操作对分子结构改变较大,具有很强的全局搜索能力。综上所述,CROCS相较于 GA策略的收敛速度更快且全局收敛性更好,相较于DPSO策略的全局收敛性更好。
综合以上6组实验,本文提出的CROCS策略与H-PSP策略和POCSS策略在应用性能上平均分别提升了8.9%和18.2%,在移动设备能耗方面则平均分别减少了77.1%和5.3%,并且在收敛特性上也有较优的效果。
7 结束语
本文针对在多Cloudlet环境中移动数据流应用的Cloudlet选择问题,提出了一种基于化学反应优化算法的 Cloudlet选择策略 CROCS,该策略通过充分利用多个Cloudlet资源最大化移动数据流应用的并行执行效率,在提升移动数据流应用性能的同时兼顾移动设备的能量消耗。仿真实验表明,本文提出的选择策略相较于其他没有充分考虑移动数据流应用中拥有大量可以并行执行的组件的策略,在应用的完成时间和移动设备的能量消耗上有较为明显的优势。在未来工作方面,考虑从用户的移动性方面展开研究。用户的移动会导致用户周围的网络和可用的Cloudlet资源发生变化,需要实时基于周围环境选择合适的Cloudlet才能满足应用的服务质量需求。另外,本文仿真实验环境设置与实际环境还有一定的差距,未来考虑更加贴近实际运行环境的因素,探究其对算法性能的影响。
猜你喜欢
昆钢科技(2022年2期)2022-07-08
能源工程(2022年2期)2022-05-23
当代水产(2021年10期)2022-01-12
数据与计算发展前沿(2021年5期)2021-11-30
建材发展导向(2021年23期)2021-03-08
汽车维修与保养(2020年10期)2021-01-22
无线互联科技(2020年10期)2020-08-14
汽车维修与保养(2020年11期)2020-06-09
装备制造技术(2019年12期)2019-12-25
华人时刊(2018年15期)2018-11-10
