
ARPDF:基于对话流的学习者成绩等级预测算法
2019-02-15 09:27罗达雄叶俊民郭霄宇王志锋
小型微型计算机系统 2019年2期
罗达雄,叶俊民,郭霄宇,王志锋,陈 曙
1(华中师范大学 计算机学院,武汉 430079) 2(华中师范大学 教育信息技术学院,武汉 430079)
1 引 言
随着互联网和学习技术的发展,在线学习社区环境出现并扮演越来越重要的角色.目前,中国在线教育用户规模达到1.44亿人,占网民比重的19.2%.面对如此大规模的学习用户及其所产生的数据,如何对在线学习者的学业成绩进行预测,依据预测结果实施学业预警,并为教学决策提供依据,是在线教育需要解决的一个问题.当前学习成绩预测的研究主要基于学生的学习行为数据建立成绩预测模型,而没有充分使利用学生在学习过程产生的对话流数据,其所隐含的信息包括了学习者对所学课程内容的掌握程度和关注点,对成绩预测有重要意义[1].
所谓学习者成绩(或者成绩等级)的预测,是指研究者基于系统观点,希望通过诸如性别、社会经济地位、考试焦虑、自尊、动机、语言能力以及数学能力等一系列变量来解释或预测一个学生的学习成绩[2].研究者们针对学习者成绩预测的研究与实践已经有较长历史,这几乎伴随了教育本身的历史,并已经在教育、社会学、体育、心理和信息技术等角度加以了研究与探索,涉及的对象从小学生到研究生各层面,课程背景涉及到个课表或各专业的方方面面,具体如下:第一,出现了多角度研究格局.在英语或语文等语言类课程学习中,研究发现词汇深度对阅读成绩的预测能力强于词汇量对阅读的预测能力[3],而不同难度等级的具体短语对作文成绩的预测力不同[4];而从社会学角度,社会分层的效应取决于学校所在位置的社会环境、学生的社会阶层混合程度、学校所处国家的社会公平程度等,这将决定基于社会分层变量的测量方法在多大程度上能够解释学生成绩差异[5];站在技术角度,大数据分析技术能帮助人们通过网络中产生的数据发现相关规律,进而为网络学历教育教学和管理流程的优化提供有益的决策依据[6],而基于技术角度的成绩预测研究则更多,如近年来EDM会议所涉及的研究与应用工作.第二,出现了丰富多彩的研究方法.在可计量的运动项目的运动成绩预测方面,采用了时间序列预测技术,如最小二乘法、指数曲线法、移动平均数法、指数平滑法.趋势外推法、最大近似法、最高水平线预测法等,这是以运动成绩的增长总是在时间序列上发展变化为依据而采用的预测技术[7],而通过回归分析计算出的描述词汇成绩和阅读成绩的回归方程,可以预测学生的词汇成绩及阅读成绩[8].第三,成绩预测对应用领域产生的显著影响.通过成绩的预测效度,将对学校招生和专业课教学产生一定的指导作用[9],而基于学习过程数据挖掘的在线学习自动评价模式与构建学生学习成绩预测模型将帮助教师提前发现可能不及格的学生[10],而通过对申请者的各种材料来做成绩预测,以决定是否发放相关学校所在专业的入学通知书,则更彰显出成绩预测的效应[11].
教育数据数据的快速增长,能够用于分析的数据类型也呈现多样性.机器学习与数据挖掘技术的不断发展也推动了教育数据研究的深入.已有的学习成绩预测研究大致可以分成两类:第一,学习成绩预测的理论模型,如Ohia等提出了采集学业成绩相关数据并进行评价的六步模型—FAMOUS[12];蔚莹等对质量功能模型进行适当的调整,提出基于QFD的学生学习能力评估理论模型[13];武法提等基于学习行为分析模型和学习结果分类理论设计了学业成绩预测框架[14];金义富基于学业预警系统设计框架提出了课程、课堂、课外“三位一体”预警信息发现与生成模型LAOMA[15]等.第二,学习成绩预测的数学建模,如LC Duque等采用问卷收集数据,利用象限分析和结构方程模型等组成的多重方法研究学业成绩和满意度的建模[16];Arsad等使用人工神经网络方法建模,预测工程学专业学生的学业成绩[17].陆柳生等提出基于离群点检测的学生学习状态分析方法,判定学生学习状态是否异常[18];施佺等建立以关联规则挖掘和聚类分析为核心的监管数据挖掘模型,可以判定学生网络学习效果[19];Hallinen N R等人提出了使用共同代表学生知识和策略的概率模型,发现探索策略是学习成果的重要预测因素[20].Crossley S等人使用自然语言处理工具来提取文本凝聚力、词汇复杂性和情感相关的语言信息来预测学生的数学成绩[21];Lang C对学生进行贝叶斯建模,可以刻画学生在课程材料中的先验知识并预测学生的成绩(表现)[22].
因此,对于学习者成绩预测的研究基本上涵盖了现代教育体系下的各个层面,研究方法从传统的统计理论(如线性回归)到近年来兴起的大数据技术(如数据挖掘、机器学习和深度学习等).相关的研究表明,现有研究工作主要还是以传统统计理论为指导展开的,随着大数据、云计算和人工智能的兴趣,新的技术与方法开始与传统理论相互结合与促进,在这一领域将进一步呈现出百花齐放的态势.在这一态势下,通过对相关文献的分析,我们认为基于对话流数据研究学习者成绩等级预测将是一个很好的抓手,为此本文提出了一种基于对话流的学习者成绩预测方法ARPDF(Achievement Rank Prediction based on Dialogue Flow),在理解对话流的基础上建立成绩等级预测模型,对学生所属的成绩等级及其出现的概率进行预测,并在基于真实数据构造的模拟数据集上实现对该模型有效性的评估与分析.
2 研究基础
基于对话流的学习者成绩预测方法ARPDF将涉及LDA[23]模型和LSTM[24]模型.
2.1 LDA模型
LDA 是一个3 层的贝叶斯概率图模型,包括文档、主题和词三个层面.LDA是一个逆向的由文档建立模型的过程,具体的文档生成过程叙述如下.
1)对主题k采样主题-词分布:
jk~Dir(β),k∈[1,K]
2)对文档d采样文档-主题分布:
θd~Dir(α),d∈[1,D]
3)对文档d中的每一个词Wd,i:
3.1)采样Wd,i属于的主题:
zd,i~Multionmial(θd),i∈[1,|Nd|]
3.2)依据主题生成词:
wd,i~Multionmial(jZd,i),i∈[1,|Nd|]
其中,D表示所有文档的集合;Nd表示文档d 中的词数;K 代表主题个数;Wd,i为文档d 中的第i个词;θd为文档d 的主题概率分布;jk为主题k下的词分布,两者均为多项式分布;α、β分别是θd、jk的超参数.jk,i表示第i个词在主题k下出现的概率,θd,i是第i个主题在文档d下出现的概率,其二者也是模型主要估计的参数.
2.2 LSTM模型
LSTM是RNN模型的一种变种,与基础的RNN模型不同,LSTM通过特别设计的门控机制来避免尝试长时依赖问题.LSTM在传统RNN的基础上新增了输入门(input gates)、遗忘门(forget gates)和输出门(output gates)3 种门结构,以保持和更新节点状态.LSTM具体计算过程如公式1-6所示.
Ct′=tanh(Wc[ht-1,xt]+bc)
(1)
2)遗忘门决定将被保留的前一时间步的状态信息,计算公式如公式(2)所示.ft∈Rn是当前时间步遗忘门的计算结果,σ是激活函数,Wf∈Rn×(n+m)是转换矩阵,bf∈Rn是偏置向量.
ft=σ(Wf[ht-1,xt]+bf)
(2)
3)输入门决定将被保留的当前步时间步的临时状态信息,计算公式如公式(3)所示.it∈Rn是当前时间步输入门的计算结果,Wt∈Rn×(n+m)是转换矩阵,bt∈Rn是偏置向量.
it=σ(Wt[ht-1,xt]+bt)
(3)
4)结合公式(1)-公式(3)得到当前时间步的状态,计算公式如公式(4)所示.Ct∈Rn是当前时间步的状态,Ct-1∈Rn是前一时间步的状态.
Ct=ft∘Ct-1+it∘Ct′
(4)
5)输出门决定当前时间步的输出信息(隐含状态).计算公式如公式(5)所示.Ot∈Rn是当前时间步的输出门的计算结果,Wo∈Rn×(n+m)是转换矩阵,bo∈Rn是偏置向量.
Ot=σ(Wo[ht-1,xt]+bo)
(5)
6)当前时间步的输出状态(隐含状态)计算公式如公式(6)所示.
ht=ot*tanh(Ct)
(6)
LSTM 通过记忆单元来学习从细胞状态中忘记信息,更新细胞状态的信息,使得其能有效利用序列数据中长距离依赖信息,因而被主要应用于处理与时间序列有关问题.
3 问题定义与求解框架
本节描述本文所要解决的问题及其解决框架.
3.1 问题定义
定义1. 学习小组. 针对课程C,将课堂中的M个学生分成N个学习小组G={gi},i∈[1,N],每个学习小组D人,D=M/N.
定义2. 对话流.针对每个学习小组G={gi},i∈[1,N],构建线上学习交流平台S={si} ,i∈[1,N].收集一段学习过程之后产生的学习小组对话数据,并按照时间顺序排列形成对话流DF={dfi},i∈[1,N].
定义3. 成绩等级预测.针对课程C,划分形成的学习小组G,线上交流平台S以及对话流DF,构建成绩等级预测模型M(C,G,S,DF),预测学习小组的成绩等级R={ri},i∈[1,N],ri={(r,p)}为一个二元组集合,r为预测得到的成绩等级,p为此等级出现的概率.
3.2 问题求解框架
为了解决这个问题,本文的基本思路是:首先,对对话流文本进行预处理,去除对话流中不规范表达对语义的影响.其次,将对话流中讨论相同课程主题的连续对话划分成文本段,有利于对文本语义的分析.接着,将已经划分成文本段形式的对话流转换成能够描述学生交流语义的对话状态矩阵.最后,使用已经被证明在处理时序数据上有优秀能力的LSTM对成绩等级及其出现的概率进行预测.基于以上的思路,本文提出一种针对对话流的学习者成绩等级预测方法ARPDF(Achievement Rank Prediction based on Dialogue Flow),具体过程如图1所示.
ARPDF方法分为训练和预测两个阶段.训练阶段得到成绩等级预测模型,预测阶段应用此模型进行成绩等级预测.下面对两个阶段的具体步骤进行简单说明.
在图1的训练阶段,将课程C的历史对话流DFtrain及每个对话流对应学习小组的课程结业成绩等级R作为训练阶段的输入数据.在此基础上,首先,通过预处理得到标准对话流集合SDFtrain;其次,通过对话流划分,得到词嵌入模WEM和对话流文本段集合PDFtrain;接着,通过对话状态矩阵生成,得到主题词表TWT、对话状态矩阵集合MDFtrain和成绩等级向量集合RVtrain;最后,利用MDFtrain和RVtrain训练基于LSTM的预测模型.在图1的预测阶段,将课程C需要进行成绩预测的学习小组对话流作为输入,通过和训练一致的处理步骤,使用预测模型得到学习小组的成绩等级R.使用表1说明本节提到的各类符号的定义及形式.

图1 ARPDF算法框架Fig.1 ARPDF algorithm framework
4 基于ARPDF的预测方法
基于ARPDF的预测方法主要包含预处理、对话流划分、对话状态矩阵生成和成绩等级预测模型生成4个子算法,以下4节对相应的算法进行介绍.
4.1 对话流的预处理方法
预处理方法的输入为对话流,对话流中的对话包含两行内容,第一行为对话的时间戳和发言人,第二行为对话内容.
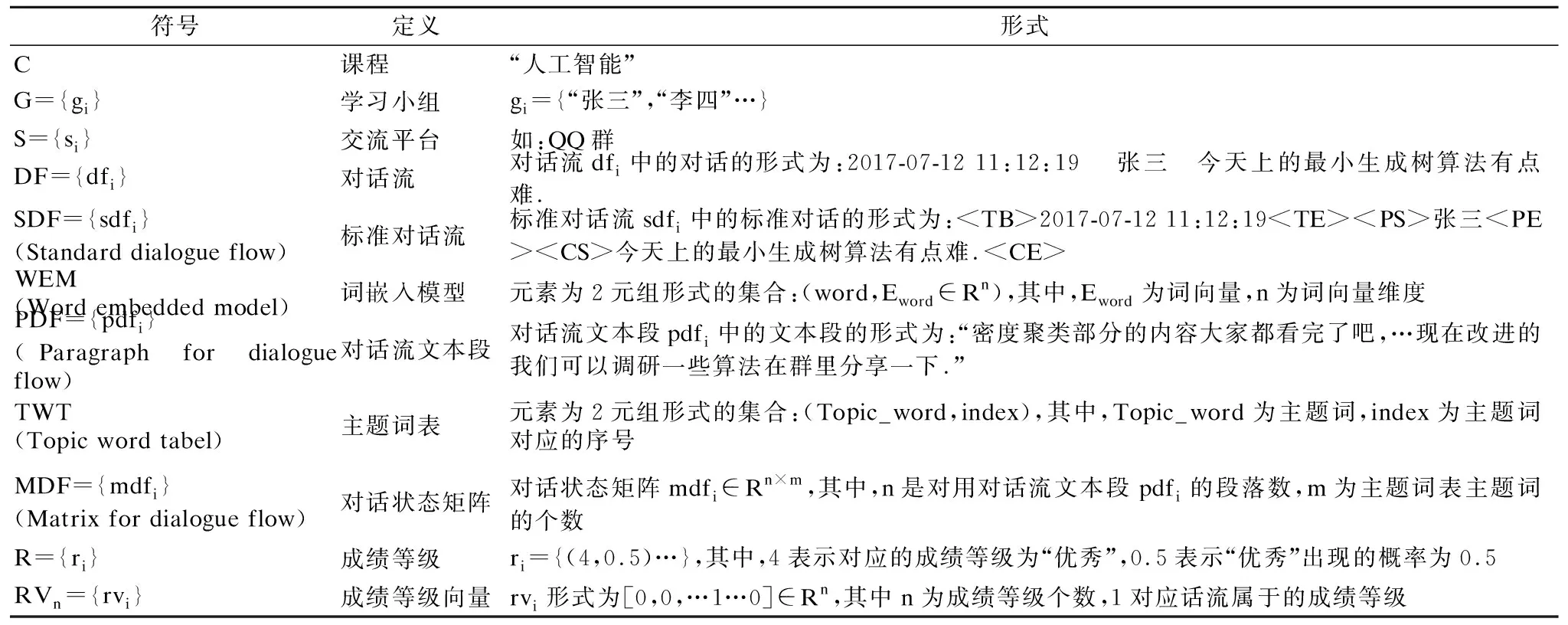
表1 符号说明Table 1 Symbol description
预处理方法具体如下:第一,提取对话中的时间戳、发言人和发言内容,生成形如格式“
4.2 对话流划分算法
预处理步骤主要实现了两个功能:1)将短时间内多次分开发送的单个对话进行了合并;2)剔除了对语义没有影响的短对话.
通过预处理步骤,得到标准对话流,然而目前的标准对话流只是零散的个人观点的集合,没有形成能够表达小组学习交流情况的语义片段.为了将对话流划分成不同交流主题下的语义片段,提出了对话流划分算法.
考虑时间和句子内容相似度两个因素来对标准对话流进行划分.其中,在计算内容相似度时候,引入目前流行的词嵌入模型CBOW.此模型将单词映射到相同的向量空间中,越相似的词对应的向量在向量空间中离得越近.现有的计算句子内容相似度方法常使用句编码的策略,然而,考虑到对话流中常存在语义表达不规范的问题对句编码效果的影响,本文只在单词层面引入向量模型,采用公式(7)计算两个句子的内容相似度.
(7)
其中,si是两个对话分词后长度较短的对话,sj是两个对话分词后长度较长的对话,n是si的词个数,MAX是最大值函数,WEM.sim()计算两个词向量相似度的函数,wi是si中的词,wj是sj中的词.按照公式(7)计算两个句子内容相似度的复杂度为O(N*M*(O(WEM.Sim))),其中,N和M是si和sj分词后的长度,乘上词向量相似度计算函数的复杂度.
表2为对话流划分算法,以下对算法进行详细说明.
遍历标准对话流SDFi,将SDFi中标准对话的发言内容进行分词处理后写入词嵌入语料文件(行1-2);行1-2的算法复杂度为O(N*M*O(Word segmentation)),其中,N为标准对话流的个数,M为N个标准对话流中b标准对话个数的最大值,乘上使用分词算法的复杂度.利用词嵌入语料文件训练CBOW模型(行3);行3的复杂度为O(N*D+D*|V|),其中,N 为输入层窗口长度,D 为发射层维度,|V|为训练语料的词典大小.依次处理每一个标准对话流文件(行4-13);申明文本段序号ID及文本段字典PDFi(行5);依次遍历SDFi每一个标准对话,如果此标准对话与当前文本段中最后一个标准对话的时间差值小于T且存在此标准对话的发言内容与当前文本段中某一标准对话的发言内容相似度大于S,将此标准对话加入当前ID对应的文本段.否则,文本段序号ID计数加一,将此对话加入ID对应的文本段(行6-11);行6-11的算法复杂度为O(N2*(O(Content_Sim))),其中,N为SDFi中的标准对话个数,乘上内容相似度函数的复杂度.Content_Sim函数的算法复杂度为O(N*O(Sim)),其中,当前文本段中的标准对话个数,乘上sim函数的算法复杂度.将PDFi中每个key对应标准对话的发言内容拼接成文本段并按key的顺序排列形成新的PDFi(行12),将PDFi加入PDF.
4.3 对话状态矩阵生成算法
通过对话流划分算法,得到的对话流文本段集合PDF中的文本段包含了能够表示一次学习小组交流的语义片段.但是这样的表示存在以下几个问题:1)这种表示形式是冗余的,不能很好的刻画学习交流的核心语义;2)这种表示形式直接用于现有预测模型时的计算复杂度过高.

表2 对话流划分算法Table 2 Dialog flow partitioning algorithm
为了解决以上两个问题,提出了对话状态矩阵生成算法,此算法主要使用LDA算法来提取对话流文本段的主题信息,利用公式(8)和公式(9)形成对话状态矩阵和成绩等级向量.
MDFij=[0,0,…,1TWT.fIND(wjk),…,0,0]∈Rnum(TWT),
wjk∈LDA.Topic_words(paragraphj,N,M)
paragraphj∈PDFi
(8)
其中,paragraphj是对话流文本段PDFi中的文本段,LDA.Topic_words(paragraphj,m,n)通过LDA得到paragraphj所属前N个主题下前M个高频词wjk,TWT.find(wjk)在主题词表中找到词wjk的序号,1TWT.find(wjk)表示将向量中序号对应位置的0置为1,MDFij是针对PDFi中的文本段paragraphj的对话状态向量,num(TWT)为主题词表中主题词的个数.
RVi=[0,0,…,1max p_rank(Ri),…,0,0]∈Rnum(Ri)
(9)
其中,num(Ri)为集合Ri的大小,既是成绩等级个数,1maxp_rank(Ri)表示找到Ri集合的二元组中概率最大的成绩等级,将向量对应位置的0置为1.
表3为对话状态矩阵生成算法,以下对算法进行详细解释.
利用对话流文本段集合PDF生成文本段词链表(行1-3);行1-3的算法复杂度为O(N*M*O(Word segmentation)),其中,N为对话流文本段个数,M为对话流文本段中文本段个数最大值,乘上使用分词算法的复杂度.利用文本段词链表训练LDA模型(行4);行4的算法复杂度为O(N*M*K*L),其中,N为迭代数,M为文档个数,K为主题数,L为文档中词个数的均值.申明主题词集合,并将K个主题下的前M个高频词加入主题词集合,按顺序编号后形成主题词表TWT(行5-9);申明对话流状态矩阵集合 MDF和成绩等级向量集合RV(行10-11);遍历对话流文本段PDFi生成对话流状态矩阵MDFi和成绩等级向量RVi并加入对应的集合(行12-16);

表3 对话状态矩阵生成算法Table 3 Dialogue state matrix generation algorithm
4.4 成绩等级预测模型生成算法
通过对话状态矩阵生成算法,得到能够反映学习者对话状态的MDF和成绩等级向量集合RV.本文基于LSTM设计了成绩等级预测模型,此模型能够捕捉到不同学习层次的学习小组的对话流特征并对成绩等级做出准确预测,具体如图7所示.
图2是本文设计的基于深度循环神经网络的预测模型,该预测模型的每一次输入为一个对话状态矩阵.每个时间步的输入为对话状态矩阵对应时间步位置的文本段向量,描述了文本段的核心语义内容.
LSTM隐藏节点的个数为课程核心知识点个数(主题个数)K,记录对话流中包含的课程主题的语义信息.隐藏层H的激活函数选择sigmod,其个数为学习者成绩等级个数,记录对话流中的成绩等级信息.模型的深度为3层,记录课程前3个月对话流的语义信息.
Softmax层输出下标位置对应成绩等级的概率,其中出现概率最大为最终成绩预测等级.损失函数选择交叉熵,并使用随机梯度下降方法进行优化.模型训练时,使用MDF和RV进行训练.
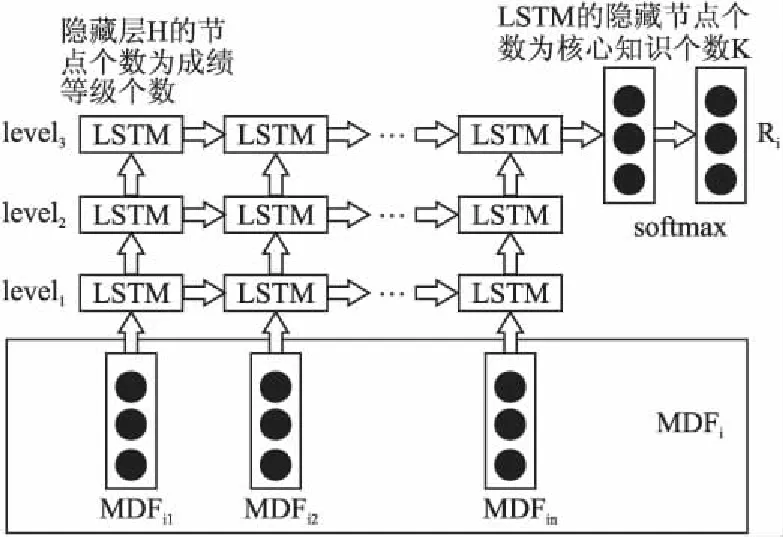
图2 预测模型Fig.2 Prediction model
实际训练过程可能会出现对话流数据不足的情况,采取以下增量算法扩展训练数据.实际采集的对话流数据通过预处理、对话流划分和对话状态矩阵生成三个步骤得到对应的N个对话状态矩阵及其成绩等级向量,每一个对话状态矩阵及其对应的成绩等级向量称为一个数据对,利用这N个初始数据对生成生成增量数据,具体步骤如下:1)申明空的模拟数据对集合;2)对以下操作迭代M次:2.1)从N个初始数据对中随机抽取一个数据对;2.2)随机选取数据对中对话状态矩阵1%的元素做取反操作;2.3)将新生成的对话状态矩阵和原数据对中的成绩等级向量构成新的数据对,将新数据对放入模拟数据对集合.3)生成大小为M的模拟数据对集合.
5 实证研究
实验环境在操作系统Ubuntu16上进行,使用python2.7编码环境,使用了jieba、gensim和keras等工具作为支持库.
5.1 数据集
实验采用某大学2016年大三上学期“数据结构”课程一个年纪的400名学生的学习小组对话流数据实验.将4个学生作为一个学习小组,分成100组,课程开始前,要求学生以QQ讨论的形式对在课程中遇到问题进行交流.采集课程前3个月学习小组对话流,记为DFi,i[1,100].经过统计,平均每个小组的对话数据达到8040条.成绩等级依据其课程结业考试的成绩确定,具体的划分标准为差(0-50)/中下(50-60)/中(60-75)/中上(75-90)/优秀(90-100).
依据4.1节的预处理方法对DFi,i[1,100]进行处理,其中设置时间阈值T为2min,长度阈值L为5个单词长度,得到标准对话流SDFi,i[1,100].
5.2 评测指标
本文采取多种方式评价模型的有效性.第一个指标是如公式(10)所示的准确率,准确率越高则说明模型有效性越效.
准确率=成绩等级预测正确的个数/总个数
(10)
第二个指标是如公式(11)所示的错误率,在此采用字典V将五个成绩等级映射到5个自然数上:V(‘差’)=1,V(‘中下’)=2,V(‘中’)=3,V(‘中上’)=4,V(‘优秀’)=5.错误率越低,则说明模型越有效.

(11)
最后,将使用F1值处理成绩等级预测中的好生和差生问题,具体思路是将差生与中下等学生的成绩等级视作为负例,其余学生的成绩等级视为正例子.
5.3 参数选取的启发式准则
ARPDF算法中存在需要确定的超参数,本文采用实验比较的方式选取超参数的值,同时也给出选取超参数的启发式准则.
准则1.对话流划分算法中的内容相似度阈值S:选取使得PDF中的文本段均值最接近课程C核心知识点个数的S.
准则2.对话状态矩阵生成算法中的LDA算法的主题个数K、文本段选择的主题个数N和每个主题下选取的高频词个数M:K选取课程C的核心知识点个数;N通常选取为3;M选取为使得从K个主题下选取的主题词个数尽量接近于课程核心知识点*核心知识点的平均子知识点个数.
5.4 对话流划分
首先,利用标准对话流SDFi中对话内容形成词嵌入训练语料文件,由于本文使用的原始训练数据集较小,采用复制词嵌入训练语料文件的方式扩展对话数据数量以达到词嵌入训练的要求,并且此种扩展不会对后续步骤造成影响.使用gensim中的Word2Vec模型进行词嵌入的训练得到WEM.
其次,根据对话流划分算法,选取时间阈值T值为10min.假设不同小组的对话流划分后的文本段个数呈正态分布,选取不同相似度阈值对对话流进行划分的实验结果如图3所示(如S取0.5时,文本段均值为39).
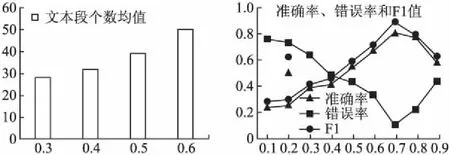

最后,设置不同的相似度阈值S,依据准则2设置对话状态矩阵生成算法的各个参数.将SDFi,i[1,100]转换成MDFi,i[1,100]和RVi,i[1,100],使用4.4节的增量算法得到MDFi,i[1,10000]和RVi,i[1,10000],将7000个作为训练数据,3000个作为测试数据.利用训练数据训练预测模型并使用预测数据进行预测,实验结果如图4所示.
依据图4,准确率和F1值在[0.1,0.7]持续上升,[0.7,0.9]呈下降趋势,同时错误率的变化呈现相反趋势.所以,选取相似度阈值S为0.7能使得模型达到最佳预测效果.
5.5 对话状态矩阵生成
首先,设置相似度阈值S为0.7将SDFi,i[1,100]转化成PDFi,i[1,100],利用PDF训练LDA模型,并得到主题词表TWT.主题个数K依据准则2取值为C课程C核心知识点数目,不同M值下得到的主题词表大小如图5所示(如M值取5时候主题词表的大小为84).

图5 选取不同高频词个数下的主题词表大小Fig.5 Sizes of topic words table under different numbers of high frequency words
其次,设置相似度阈值S为0.7,设置文本段选取的主题个数N和选取高频词个数M的不同搭配.将SDFi,i[1,100]转换成MDFi,i[1,100]和RVi,i[1,100],使用4.4节的增量算法得到MDFi,i[1,10000]和RVi,i[1,10000],将7000个作为训练数据,3000个作为测试数据.利用训练数据训练预测模型并使用预测数据进行预测,实验结果如图6所示.
依据图6,准确率和F1值在某些点呈现微小回落(如:N=3,M=5),整体呈现上升趋势.错误率在某些点呈现微小回升(如:N=2,M=5),整体呈现下降趋势.所以,选取N=3,M=20时能使模型达到最佳预测效果.

图6 不同M和N搭配下的测评指标变化Fig.6 Measurement indicators changes under different M and N collocations
5.6 预测结果分析
本节设置各类超参数为5.4和5.5节选取的结果,将SDFi,i[1,100]转化成MDFi,i[1,100]和RVi,i[1,100],使用4.4节的增量算法得到MDFi,i[1,10000]和RVi,i[1,10000],训练得到预测模型.
应用训练得到的预测模型对“数据结构”课程下的某一个班级的成绩等级进行预测,产生的相关的实验结果如表4所示.

表4 预测结果Table 4 Predicted results
如表4所示,对此课堂的10个学习小组的结业成绩等级进行预测.正确预测其中8个学习小组的结业成绩等级,对组3和组6的结业成绩等级预测有程度上的偏差.实验证明,预测模型有良好的效果.教师可以根据模型的预测结果,在结业考试之前对预测结果为差或是中下的小组,即组5、8和9,做出相应的干预.
5.7 与相关方法比较
本文将回归分析、SVM和神经网络算法与RPDF算法进行比较.其中,由于对话状态矩阵的维度比较大,首先采用PCA算法进行降维处理.相关实验情况说明如下:
1)PCA+回归分析.将对话状态矩阵按行拼接成向量,使用PCA算法将其降到K维(K为主题数目).再使用回归分析算法计算权重,权重估计时按5.2中错误率中的方法将等级映射到自然数作为回归值.模型测试时,对输出数值进行小数点后一位的四舍五入操作得到自然数并映射到相应的等级.
2)PCA+SVM.将对话状态矩阵按行拼接成向量,使用PCA算法将其降到K维(K为主题数目).使用多分类SVM算法对其进行分类,具体实现采用层次SVM.
3)PCA+神经网络.将对话状态矩阵按行拼接成向量,使用PCA算法将其降到K维(K为主题数目).设计三层神经网络模型,隐藏层个数为5,输出层个数为1,激活函数采用sigmod,使用均方误差计算损失值.训练时,将成绩等级映射为自然数的方式为:“差”=0.1,“中下”=0.3,“中”=0.5,“中上”=0.7,“优秀”=0.9.测试时,将输出值映射为成绩等级的方式为:[0,0.2)=“差”,[0.2,0.4)=“中下”,[0.4,0.6)=“中”,[0.6,0.8)=“中上”,[0.8,1]=“优秀”.
本节设置各类超参数为5.4和5.5节选取的结果,将SDFi,i[1,100]转化成MDFi,i[1,100]和RVi,i[1,100],使用4.4节的增量算法得到MDFi,i[1,10000]和RVi,i[1,10000],训练得到预测模型.实验结果如表5所示.

表5 相关工作对比Table 5 Related works comparison
从表5中可以看出:
1)在准确率指标上,由于初始变量较多(K个),回归分析的准确率较差,SVM准确率稍微高一些,神经网络和ARPDF采用了相似的原理准确率较高,其中ARPDF算法由于考虑了时间的因素准确率最高;
2)在错误率指标上,各种方法的情况大致与和准确率一致,ARPDF算法在本文错误率计算方式下比传统神经网络模型预测的偏离程度会低一些;
3)在F1值指标上,ARPDF达到了最好效果,同时注意到SVM方法的效果在类似二分类问题下有了明显的提升.
对比实验结果说明,ARPDF算法在基于学生对话流数据对学生成绩等级进行预测这一问题上有比传统机器学习算法更高的准确率和更低的错误率,并能够有效的识别出比表现较差的学生.
6 结 语
本文提出了一种基于对话流的成绩等级预测算法,通过应用词嵌入、主题模型和深度循环神经网络等技术,在对话流分析的基础上实现了对学习者成绩等级的预测,从而支持教师在课程结束之前就能对可能存在学业问题的学生进行及时的干预.本文实验表明了我们所提出的算法可有效预测出学习者的成绩等级.研究中还存在如下问题,如在实施的过程中许多参数的选取的方式采用实验选取,还可以尝试使用学习的方式得到;在实验中,数据是通过真实数据异动而生成的模拟数据,这需要进一步加大真实场景下数据的获取.这些不足之处将作为我们进一步研究的内容.
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生作文(低年级适用)(2019年5期)2019-07-26
学生导报·东方少年(2019年27期)2019-01-14
小学生学习指导(低年级)(2018年9期)2018-09-26
读友·少年文学(清雅版)(2018年12期)2018-04-04
读与写·教育教学版(2017年10期)2017-11-10
山东青年(2016年3期)2016-02-28
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
