
Spark环境下基于综合权重的不平衡数据集成分类方法
2019-02-15 09:27丁家满王思晨贾连印游进国
小型微型计算机系统 2019年2期
丁家满,王思晨,贾连印,游进国,姜 瑛
(昆明理工大学 信息工程与自动化学院, 昆明 650500)
1 引 言
随着大数据时代的到来,数据正以前所未有的速度在不断地增长和积累.数据在各个领域的应用价值比以往任何时候都重要.如何高效、准确地从数据信息中挖掘有价值的信息引起了学者们的广泛关注.然而现有的这些数据具有多样性和复杂性以及数据分布严重不平衡等特点, 经常会遇到许多大规模的多类别不平衡数据分类问题,如文本分类[1]、疾病诊断[2]以及图像分类[3]等.然而传统分类算法在处理不平衡数据时少数类样本分类准确率过低从而导致分类器的整体性能下降[4].因此选择合适的技术提高少数类样本的占比,提高对少数类的分类准确率以及分类器的整体性能显得尤为重要.目前有诸如改变数据的分布和改进已有分类算法等方式试图从不同的角度解决上述问题,也取得了较好的成效[ 5-7].其中改变数据的分布来达到数据平衡最常见的策略有随机过采样(over-sampling)、随机欠采样(under-sampling).随机过采样是对少数类的样本进行复制使数据集的样本数达到平衡,随机欠采样则以一定的策略选取多数类样本中的一个子集达到同样的目的. 李克文等人[8]提出基于RSBoost算法的不平衡数据分类方法,该方法采用 SMOTE 算法对少数类进行过采样处理,然后对整个数据集进行随机欠采样处理来改善整个数据集的不平衡性,提高少数类的分类准确性. 李雄飞等人[9]提出一种新的不平衡数据学习算法 PCBoost,该算法用数据合成方法添加合成的少数类样本,平衡训练样本.虽然以上方式能够在特定环境下一定程度的解决数据不平衡问题,但是为了达到数据平衡按比例机械地抽样将破坏原始数据的分布特点、而对多数类样本进行简单抽样则可能移除潜在有用的分类信息,这将导 致分类效率低、分类精度低等问题.另外,随着数据规模增大、加之算法为不平衡数据的预处理带来运算代价,不平衡数据分类效率成为了瓶颈问题.
云平台和并行化技术的出现为我们提供了解决分类效率问题的环境,并取得了有效的成果[10-15].其中Wang Z等人[13]针对不平衡数据提出一种基于MapReduce框架的分布式加权极限学习机,实验结果表明该方法具有较好的可扩展性以及较高处理不平衡大数据的效率.然而MapReduce计算框架不适合迭代算法,它计算的得到的中间结果写入到磁盘,使用时再从磁盘加载读取,其网络和I/O开销代价高.Apache Spark[注]http://spark.apache.org是一个基于内存的快速处理大数据框架,解决了机器学习算法的迭代计算和交互式数据挖掘等问题. 王雯等人[14]提出一种在Spark平台上的基于关联规则挖掘的短文本特征扩展及分类方法,其实验结果显示相较于传统分类方法平均得到15%的效率提升. Chen J等人[15]提出了Spark平台大数据的并行随机森林算法,大量实验结果表明了其在分类精度和效率的优势.在Spark平台下这些分类方法在效率方面获得较好的成效.因此,如何最大限度地利用Spark框架的计算优势来解决不平衡数据分类效率问题显得尤为重要.
针对上述问题,本文提出了一种在Spark环境下基于综合权重的不平衡数据集成分类方法.该方法首先提出基于综合权重的采样方法得到平衡训练数据集,其次为了提高分类精度,优化并改进了随机森林算法;最后,在Spark环境下进行算法实现及实验验证.
2 随机森林的优化
随机森林[16](Random Forest,RF)是一种集成分类器,它基于随机化的思想构建了一群相互独立且互不相同的决策树.它通过自助法(bootstrap)重采样技术,首先从原始训练样本集 中有放回地重复随机抽取 个新的自助样本集,并由此构建 棵分类树(通常采用决策树),每次未被抽到的样本组成了 个袋外数据;然后将生成的多棵分类树组成随机森林;最后用随机森林分类器对新的数据进行判别与分类,分类结果按各分类器的投票结果而定.在训练的时候,每一棵树的输入样本都不是全部的样本,这既保证了训练的子本分类器之间差异性又不容易出现过拟合现象.但是随机森林算法也存在着不足,例如训练数据的严重不平衡以及通过随机的方式进行选择特征引起的分类效果不佳,所以本文主要从两个方面对随机森林算法进行改进.一方面提出基于综合权重的数据平衡方法使样本达到平衡;另外一方面是从特征选择上,改变传统的随机选择的方式.
2.1 基于综合权重的数据平衡方法
为了达到数据平衡并保留原始数据的分布特点,以及挖掘多数类样本中更具有价值的数据,本文提出基于综合权重的数据平衡方法.首先按照少数类样本的数量和多数类样本中每个类别样本数量占多数类样本数量的比重来计算综合权重,并依据综合权重从多数类样本中抽取每一类别的样本数量,再将少数类样本与抽取的样本组合,使少数类样本在训练样本中所占比例升高.采样次数与少数类样本和多数类样本相关.最后将获得的经处理后的训练样本子集作为随机森林的输入样本数据.其中相关定义如下:
定义1.将具有M个特征的N个样本组成的样本集合表示X={a1,a2,…,aN},样本的类别集合表示Y={y1,y2,…,yN},则训练样本用矩阵Z表示如下:

(1)
其中ai={xi1,xi2,…,xij,…,xiM}表示样本ai的M个特征值,其中xij表示样本ai的第j个特征值.
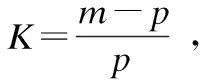
定义3.设多数类类别分布T1,T2,…,Tr,每个类别包含样本数量为{Count(T1),Count(T2),…,Count(Tr)},则T1,T2,…,Tr的抽样权重为:
(2)
样本数量越小,则抽样权重越大.记少数类样本数目为p,则从多数类类别Ti中采样的样本综合权重:
(3)
2.2 特征选择
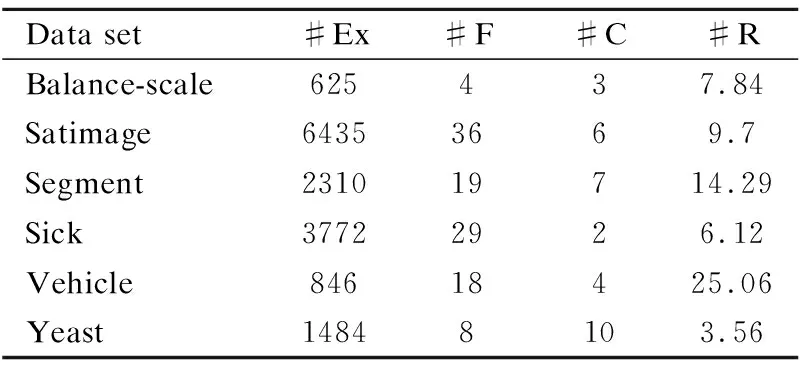
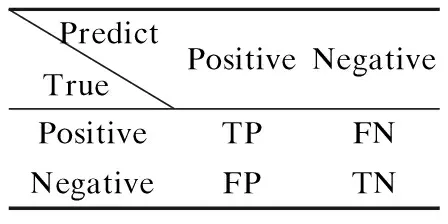
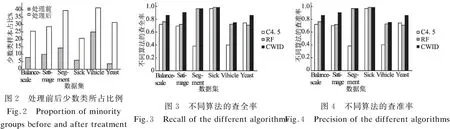
传统的特征子集通过随机的方式进行选择,所以在面对噪声特征和冗余特征的数据集,分类的准确性会受到影响,错误率也会提高.这些噪声特征和冗余特征对于分类的准确性没有贡献,特征的重要性很低.因此本文在谢娟英等人[17]研究的基础上提出基于相关性的特征选择方法进行特征选择,删除噪声特征和冗余特征.特征选择从空集开始,依次选择类别间区分能力强的特征,选择最优的u个特征,且需要满足u 定义4.设训练样本集规模为N,类别数为l,即{(ak,yk)|yk∈{1,2,…,l},k=1,2,…,N}.其中第j类的样本数为nj,则特征i的类别间区分度Fi的计算公式如下: (4) Spark是UC Berkeley AMP Lab 开源的类Hadoop通用的并行计算框架,它基于Hadoop MapReduce算法实现分布式计算,其中间输出和结果不同于Hadoop保存在HDFS中,而是直接保存在内存中.Spark提出了弹性分布式数据集RDD(Resilient Distributed Dataset)的概念,RDD是分布在集群中的只读对象集合,在集群中的多个节点上进行分区,它支持用户在执行计算时选择缓存数据集在内存中,便于下次计算时重用数据集,提供了更快速的数据访问,减少了不必要的磁盘重复读写操作.它不仅支持基于数据集的应用,还具有容错、局部计算调度和可扩展等特性.因此Spark能更好地适用于机器学习与数据挖掘等领域. 为了挖掘大规模不平衡数据集中有价值信息、降低数据通信I/O的开销提高分类效率,本文提出了Spark环境下基于综合权重的不平衡数据集成分类方法.本文方法包括基于综合权重采样的训练数获取和子分类器学习以及并行化实现,主要包括3个阶段: 1) 将原始数据集转换为Spark能处理的数据RDD形式,并转换成少数类RDDmin和多数类RRDmaj两种形式; 2) 设计综合权重采样方法以获得平衡规模的训练集; 3) 采用改进的随机森林算法训练子分类器,并在Spark环境下实现,最后通过加权投票的方式获得测试数据的最终分类结果. 图1 第一阶段RDDs的谱系图Fig.1 Hierarchical graph of RDDs in phase 1 第1阶段.将数据集转换为Spark能处理的RDD格式,RDDs之间的转换如图1所示.首先使用sparkContext.textFile函数从HDFS分布式件系统中读取训练集数据并将其转换为RDD的形式,用map()函数将每一条数据记录映射成(key,value)这样的元组形式.其中的key为样本类别,value值则是样本一条记录.通过调用collect()函数计算每类的样本量并调用sortBy()函数使得按照升序排序,最后获得RDDmin和RDDmaj,将用于下一阶段的采样阶段.其算法过程如算法1所示. 算法1.RDDmin和RDDmaj生成算法 Input:D,raw data Output:RDDmin,RDDmaj 1.for each sample x inD 2.instance←x.map(class,x) 3.totalInstance←instance.combineByKey().map(num+1).collect() 4.sortInstance←totalInstance.sortBy(num,false) 5.RDDmin←sortInstance(0) 6.RDDmaj←sortInstance(1) 第2阶段. 基于综合权重进行采样.为了达到数据平衡并保留原始数据的分布特点以及挖掘多数类样本中更具有价值的数据,本文提出基于综合权重的采样方法获得平衡规模的训练集.算法具体过程如算法2所示. 算法2.基于综合权重的采样方法 Input:RDDmin,RDDmaj,C,numbers of classes Output:RDDi,a balanced train set 1.C1,C2,…,Cn←n classes 2.sum←numbers ofRDDmajsample 3.p←numbers ofRDDminsample 4.M←numbers of train subsets 5.for each classCi 6. if key==Cithen 7.num++ 8.Ration(Ci),Weight(Ci)←according the definitions calculate it 9.RDDi←select samples intoRDDi 10.RDDj←RDDi∪RDDmin(i∈[1,M]) 第3阶段.训练分类器并加权投票决策.本文采用改进的随机森林训练分类器.运用前两个阶段处理过的训练集与特征子集进行训练各个子分类器,并获得分类模型.传统的随机森林算法采用简单投票原则,对每个决策树赋予相同的权重,忽略了强分类器与弱分类器的差异,影响了随机森林分类器的整体分类性能,本文采用加权投票法进行选择最终的类别的结果.利用在未被抽样的数据作为袋外(OOB)数据,计算各个决策树分类器对其的分类准确率,并将其作为对应决策树的投票权重. 实验环境基于Spark集群,包括1个master,7个slave节点,所有节点的配置如下:操作系统为Centos 7,CPU为Intel Core i7-6700 cpu @2.60Ghz 2.59Ghz,8GB内存,使用Scala 2.10.4开发,集群环境建立在Hadoop2.6.0之上的Spark1.6.0. 为评价本文方法对不平衡数据集分类问题的有效性,本文选择6个少数类和多数类样本比例不平衡的数据集进行实验,数据集来源于 UCI 机器学习数据库的数据集,见表1,其中UCI数据集样本数用#Ex表示,#F代表特征数,#C代表数据集类别数,#R代表少数类样本占数据集的比重.为了验证本文算法在spark平台上的有效性,采用KDD Cup 99数据集[19],其整个训练数据有500000条记录,以及URL Reputation数据集,其训练数据有2396130条记录,数据容量2.05GB.为了评估本文算法的性能,实验部分选择了决策树C4.5算法以及随机森林RF算法进行对比,对比算法都在Spark平台下的运行,以保证实验运行环境的一致性.本文训练的基分类器采用C4.5算法迭代20次;其中对照算法C4.5决策树算法以及随机森林RF算法直接对不平衡数据集进行分类,实验中选择的特征数一致以及随机森林算法训练每棵决策树时使用C4.5算法. 表1 UCI数据集信息说明Table 1 Summary description of the used datasets 表2 混淆矩阵Table 2 Confusion matrix for a two-class problem 本文采用查全率、查准率和 F-measure 作为评价分类器性能的指标.这3个指标在机器学习、数据挖掘等领域中应用广泛.传统的二分类评价指标基于混淆矩阵,其中在不平衡数据集中正类和负类分别代表少数类和多数类.TP和TN分别表示正确分类的正类和负类样本的个数;FP表示为误分为正类的样本个数;FN表示为误分为负类的样本个数,见表2. 评价指标计算公式如下: 实验1. 数据处理前后少数类样本占比. 在不平衡数据集中,多数类样本个数远远多于少数类,传统分类算法往往会倾向于多数类,如即使把所有样本分为多数类,依然会获得很高的分类精度,但是却不能识别少数类.因此在处理不平衡数据时,提高少数类样本在训练样本中所占比重能够有效的提高少数类样本的分类性能.图2表明经过基于综合权重的数据平衡对不平衡数据经处理后,每个数据集训练样本中少数类样本的比例明显提高了. 实验2.不同分类算法准确率的比较. 在分类过程中分别设计采用C4.5算法、随机森林算法以及本文方法3组实验,每一组实验针对上述的数据集分别测试.实验结果如图3-图5所示.根据图3和图4可以看出,C4.5算法在Segment、Vehicle数据集上的查准率偏低,而RF算法在Segment、Sick数据集上有较高的查全率和查准率.同 RF和C4.5算法相比较,本文算法分别在Balance-scale、Satimage以及Yeast数据集上的查准率具有显著的优势.在这6个数据集上本文算法显著优于C4.5算法,在Segment 、Sick数据集上与RF算法水平相当.图5是几种不同的方法在不平衡数据分类性能的评估指标F-measure的比较.只有当查全率和查准率都较大时,F-measure才会相应地较大.因此F-measure可以合理地评价分类器对于少数类的分类性能.本文提出采用基于综合权重采样和集成学习相结合的方法来处理不平衡数据的分类问题,相比其他两种方法,分类性能得到大幅度提升,在数据集Balance-scale、Satimage以及Yeast上,本文算法在准确率指标上比其他两种算法提高了10%以上. 实验3.决策树数量对分类准确率的影响. 为验证决策树数量对分类准确率的影响,测试设置不同的决策树棵数{5,10,15,20,25,30},通过实验统计表明决策树的棵数对分类准确率的提高发挥中重要的作用.当决策树的数目等于5时,Random Forest算法的平均分类准确率没有本文算法CWID的高.随着决策树的数量的增加,这些算法的平均分类准确率提升幅度相对下降,这意味着决策树数量达到最佳.CWID算法在决策树的数目等于20的时候,平均分类准确率达到顶峰.CWID的分类准确率高于另外两种算法,并具有优越性和显著的优势. 实验4.CWID在不同数据集上的执行效率. 为验证本文提出的在Spark环境下基于综合权重的不平衡数据集成分类方法的效率,将本文提出的算法与传统单机上分类算法进行对比,并测试在KDD Cup 1999实验数据集以及UCI数据集上的URL Reputation数据集,本文算法加速比随集群节点数量的变化情况,节点数量取{1,2,3,4,5,6,7}.通过对比试验,分析本文提出的分类方法的分类效率.算法加速比,是算法在单机环境下和分布式环境下运行消耗时间的比率值,用来评价程序并行化后的效果.图6是CWID算法的加速比实验结果. 由上述实验结果可知,随着spark集群计算节点的增加而逐渐上升,并在数据集上加速比的变化从线性增长到平稳,在数据集kddnormal_VS_U2R和kddnormal_VS_R2L上较为明显.这个主要是由于数据集容量太小,以及算法的分布式处理能力没有得到充分的利用;与此同时,在相同节点的情况下,数据集规模较大时,曲线增长更为明显,且算法的速度性能较好.因此,在Spark环境下训练的分类器具有较好的并行化性能.所以在训练海量数据时,完全可以通过增加spark集群中计算节点的数量,来大大减少训练模型所需要的时间. 为了保持原始数据的分布特点、更好的利用潜在有用的分类信息,以及保证集成学习中的各分类器之间的差异性,本文采用在Spark环境下基于综合权重的不平衡数据集成分类方法处理不平衡数据分类问题.通过UCI数据集实验,与C4.5算法、RF算法进行比较,并将查全率、查准率、F-measure 以及算法加速比作为度量对算法进行评价,实验结果表明本文算法提高了整体分类精度,并较好地利用了Spark分布式平台高效的计算能力,提高整体分类效率.由于数据集本身的多样性和复杂性,噪声样本和冗余样本等均会影响不平衡数据分类性能,如果进行有针对性的数据预处理工作,将会使得基于综合权重采样的样本更具有分类价值,后期针对该问题,进一步提高该方法的泛化性能.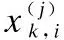
3 方法在Spark上实现
3.1 内存分布式计算框架--Spark
3.2 方法描述

4 实验结果与分析
4.1 实验数据和对比算法
4.2 评估指标

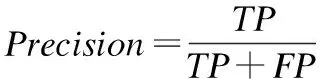
4.3 实验结果分析

5 总 结
猜你喜欢
心理学报(2022年5期)2022-05-16
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
当代陕西(2020年17期)2020-10-28
数码世界(2020年4期)2020-06-18
科学与信息化(2019年28期)2019-10-21
计算机测量与控制(2019年4期)2019-05-08
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
科学与财富(2016年32期)2017-03-04
