
基于Hadoop的校园一卡通在贫困生评定的应用研究
2019-02-11 13:05:34李楠
张家口职业技术学院学报 2019年4期
李 楠
(福州软件职业技术学院 软件工程系,福建 福州 350003)
目前我校的贫困生等级依然是通过传统方式——辅导员人工评估产生。在学生将贫困的相关证明材料及申请书提交给辅导员后,辅导员对候选贫困生的日常消费情况进行初步评定。学生通过审核后,提交材料申请让学工处再审。通过复审后在网站进行公示,公示期满再依据等级发放助学金。这样的流程导致候选贫困生申请材料所体现的家庭情况、消费状况等,成为主要评判依据,这样,内向的贫困生可能得不到贫困资助,表现积极活跃的学生却容易获得申请。另外,繁琐的过程,导致评定周期较长,助学金不能及时发放至贫困学生手中。为此,如果能根据采集到的学生一卡通中的消费数据,挖掘出有价值数据成果,能使得学生助贫扶贫工作更加高效、精准。
1 相关技术理论
下图展示了本文研究的一卡通贫困生评定系统的系统架构图。

图1一卡通贫困生评定系统的系统架构图
1.1 Hadoop分布式平台
Hadoop 是由Apache 组织研发的一个支持数据集进行分布式处理的框架,它将应用程序分布在多硬件群运行,此种结合的并行分布式系统性能高、扩展性高、成本低、可靠性高等性能。它由 HDFS( Hadoop分布式文件系统) 和 MapReduce(分布式计算框架)、HBase(分布式数据库)等核心组件构成。
1.1.1 HDFS
HDFS政区域,全称为Hadoop Distributed FileSystem,它负责存储并管理海量数据,使得 Hadoop 可以很容易地在低成本的设备上安装,访问模式是以流式数据形式来访问、存储超大系统文件。
各服务器上分散有HDFS,抽象存储资源出来,形成一虚拟统一的目录文件格式。此做法使数据容量存储扩展,具体文件存储地址用户无需管理,以抽象的目录可用本地系统对HDFS 中文件进行操作。
1.1.2 MapReduce
MapReduce 是谷歌提出的用于分布式并行数据处理的编程模型,充分利用强大的海量数据计算支持,应用集群能力实施高速运算。采用思想是分解数据处理为函数reduce 与map两阶段。封装map和reduce两接口核心于 MapReduce 中,程序员实现此两接口可实现数据并行处理。Hadoop 把输入数据MapReduce分划为相等小数据块(input split)输入分片。适合的分片大小和 HDFS 的块的一样,map 运作只对输入分片处理。在任务 MapReduce中往往会分较大数据为多种分片,将分片在多个 map 进程中封装, N个计算机中并行运行map进程有N个,处理数据得以加速。用户输入于map 中,对(key-value)映射成主键值,此多键值经shffule处理后,变成有序的若干组键值对,键值对排好即成为输入值reduce。,数据会在reduce阶段被归纳、合并总结加以输出。可由Yarn(Yet Anther Resource Negotiator)对reduce和Map进程实施调度。
1.1.3 HBase
HBase是Hadoop的一个分布式、面向列存储的开源数据库,它能为大数据提供随机、实时的读写访问功能,它非常适合于非结构化的数据存储,同时又运用 MapReduce计算模型来并行处理大规模数据,实现高大的数据存储与计算能力。所以,HBase能够实现对高校学生的大量多类数据进行存储、分析和高效处理。
1.2 数据挖掘及关联规则的概念
数据挖掘是整个应用研究的核心。我们需要从大量的数据信息中,通过特定的算法提取出隐藏的有价值的信息,采用分析、统计、机器学习、模式匹配等手段,发掘不同数据之间的关联关系,实现总结规律、预测未来趋势的目的。
关联规则作用是主要找寻不一样事物的关联性,如扶贫任务中贫困程度与交通、医疗、教育等领域间关联性,能挖掘出其中的关联规则对扶贫精准任务的具体实施有十分重要的意义。再如分析购物篮的商品间关系,找出顾客购物习性,可对商业策略高效制定。
2 基于Hadoop的贫困生评定系统层次结构和技术架构
测评贫困生的相关领域发现,分析Hadoop架构体系, 贫困生Hadoop的系统评定设计原则选用结构为层次化,依次从下到上为基础、数据资源、支撑、应用和服务这几层,形成完整的系统框架,各层次功能如下表。

表1基于Hadoop的贫困生评定系统层次结构表
基于Hadoop的贫困生评定系统的技术架构采用 MVC 三层结构,如图2 所示,其分别为视图层、控制层和模型层,使用 Java 语言编写后台代码,前台使用 B/S 模式采用JSP语言开发。各层间不同的负责作业,以相应的接口通信交换数据,同时还预留多个扩展接口,方便后期添加新的校园大数据功能。

图2基于Hadoop的贫困生评定系统的技术架构图
3 基于消费数据实现贫困生助学金评定核心算法
3.1 FP-Growth 算法
我们采用算法为FP-Growth,频繁通过( FPTree)模式树树形结构数据,集压频繁项缩于频繁模式树里,将数据库压缩后划分为条件数据库,再对所有条件数据库挖掘。具体算法如下:
第一步:从基础数据中选取学生的一卡通消费数据
第二步:统计学生各类消费数据,形成事务数据集
第三步:输入最小支持度阈值
第四步:以支持度最小阈值找到各1项频繁集,计数按其支持度降序排列
第五步:创建FPTree的根节点,将支持度计数降序排列的频繁项递归插入到树中,从而生成频繁模式树。
第六步:划分条件数据库。
第七步:挖掘每个条件数据库。
3.2 C4.5决策树算法
叶节点、N个内部节点和一个根节点合成决策树一颗。叶节点其中,表决策结果,每个测试属性由每个内部节点相对应。一个节点含的集合样本以测试属性结果划分于子节点里。于每个根节点至叶节点路径对应每个测试判定序列。
建构决策树的泛化能力强,我们选择了C4.5 算法。它采用增益率来选择划分属性。在C4.5的算法中通常选择增益信息高出平均水平属性从候选划分中,再选出最高增益率。
当前集合样本假设为A,有n个离散属性r的值{r1,r2,r3, ... ,rn},如对样本集A用r属性来划分,会有n个节点分支产生,节点分支中第i个包含了所有A中取值在属性r上为ri的样本Ai。求增益率的公式如下所示:
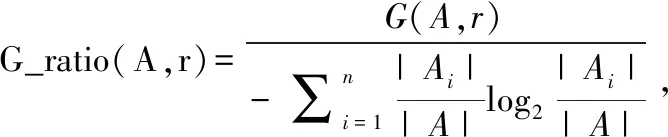
4 结语
根据以上设计思想,我们采集福州软件职业技术学院2018年度软件工程系在校生615名的一卡通刷卡数据(因走读生在校刷卡次数较少,走读生另做评定)进行实践。辅导员可以通过系统实时查看学生贫困状态评测信息,还可以根据查看贫困学生的档案资料等。
本次研究为进一步基于Hadoop技术,为高职校园建成系统大数据做好基础奠定,变废为宝重要的被忽视数据,以合理科学的大数据挖掘和管理,为高职管理教学人员关注学生生活和学业提供依据分析数据,也为高职管理教学方针制定提供数据支撑。
猜你喜欢
词学(2022年1期)2022-10-27 08:06:12
数学物理学报(2020年5期)2020-11-26 06:06:48
广东通信技术(2020年10期)2020-10-26 06:36:52
电脑爱好者(2020年18期)2020-09-26 14:53:01
火控雷达技术(2018年4期)2019-01-15 05:07:22
电脑爱好者(2017年9期)2017-06-01 21:38:08
电子制作(2016年19期)2016-08-24 07:49:44
中学生数理化·高一版(2016年2期)2016-05-30 10:48:04
新高考·高一物理(2015年5期)2015-08-18 18:52:01
中国卫生(2014年2期)2014-11-12 13:00:18
