
一种从关联文献中提取相关检测结果生成综合性能评价的智能语义算法
2019-02-09 08:16张银冰
探索科学(学术版) 2019年9期
张银冰
湖北大学化学工程与工艺 湖北 武汉 430062
当前,在文本分类模型中最被广泛认可的,也是最有效率的模型是由索尔顿及相关人员提出的向量空间模型VSM。而本文提出的FEDCSD算法,英文全称为FeatureExtractionbasedontheDetectionoftheChineseSimilar Documents,是一种在中文相似程度检测的基础上的提取特征的算法。[1]FEDCSD算法运算原理是将关键词进行分类形成聚类后,以关键词为标志,将语义特征进行数字语言化,以权重确定贡献因子。备选库中的词语以权重分类,将语义和数据特征与词汇关联起来。但是FEDCSD算法只能在有限的时间和空间内通过提取每篇文献中权重较重的词汇构建算法向量来利用向量间距判断文献的重复率。
1 SCAM特征词提取与TDF-IDF权重计算
使用将SCAM等待检验的中文文献数量设为k,从中提取的高权重词汇按1、2、3….m的方式从大到小编号排列。文献就被分类互相不影响的词汇分组。
(FW1,FW2,…FWj…,FWm)(i=1……k,j=1……m).若对每个FWj(j=1…m)
把第k篇文章按照词组关键程度基于权重WEkm,等待检验的中文文献就成为了向量抽象空间。每篇文献可用点面积和角度来对文章重复率进行计算,且每篇文章为向量空间中的一部分。TDF-IDF是词汇权重数据处理方法最传统的,计算过程如下:
WEij=FWFij×LOG(k/nj+0.
将特征词按1、2、3…..j的次序编号,将i设为词汇出现的次数。将相同次数的文章进行数据处理,设为nj,表示出现j个特征词的文献有n篇。
将SCAM用于提取词汇,TDF-IDF用于计算权重,是文献内部词汇分布状况与文献分组中的集中情况相结合的方法。不仅将高低频词汇区分了重要程度,还能对普通英文文献进行初步检测。但是只是将相同词汇分组,对近义词,相近语义等情况却无计可施,有时候特征词汇并不是一篇文献的中心主题。并且词汇出现的次数的多少并不能简单地用来确定其重要性,这是将SCAM用于提取词汇,TDF-IDF用于计算权重方法的缺点。
2 汉语文献的理解
2.1 语义特征
2.1.1 对结构层次的分析 文章的题目名称、摘要、关键词和正文,透露着文章的层次结构和逻辑关系。标题是包含着文章中心思想的短语或词组的组合,是对文献内容最精确简练的概括。摘要是对文献内容的简单描述和评价,比标题更具有描述性,比正文更加有概括性,是与正文一样包含了同样的信息量的文字段落。关键词是对论文主要思想的提炼,通常是来自文献本身的术语或词汇,能够直观地表达出文章的学术类别。最后是正文,正文是文章的主要部分,根据文章的逻辑关系,每段的中心思想通常为最首或最末一句。[2]
2.1.2 对词汇搭配的分析 词汇搭配是词汇与词汇形成的有意义的组合,词汇搭配的的分布是TDF-IDF难以把握的因素。因为词汇搭配在文中分布较少,且不同的数量分布和全文占比的差异使文章内容各有差异,而TDF-IDF往往抽取权重比重大的词汇,常常忽略词汇搭配。一句话中的词汇之间的距离又使得信息包含量有所差异,关键词距离进,包含的信息量越多。根据统计数据,名词,形容词,动词的最优观测度为[-2,+1],[-1,+2],[-3,+4]。
2.1.3 对指示语言的分析 一个句子是在交流中包含完整语言信息的最小单位。计算机想要完全理解句子的含义,需要了解语法结构、用语习惯、语言含义等。而汉语体系中总有一些提示性词汇表示接下来将是重要的总结性语句。比如:“综上所述”、“根据统计”、“总的来说”之类的词汇。这类词汇叫做指示词,其后的语句一般表示了论述过程的高度总结,或是文章的中心思想。[3]
2.1.4 对研究领域的分析 在一个学术研究领域中都有一些公认的理论,或是通用的方法。因此,一篇学术论文难免会出现该研究领域内的术语,这种语言的重复在文章中又是合理的,所以这类词汇的重复率在文章中又是必要的。
2.1.5 对词语含义的分析 在中文系统中,相同含义但形式不同语言比比皆是。一般来说,两篇同义词或者近义词分布相似的文章,其内容也是高度相似的。所以同义词和近义词也的辨析也是非常重要的,对文章的重复率检查具有重要的意义。
2.1.6 对词语性质的分析 汉语词汇中除了语法结构,词汇性质还有虚实之分。实词具有含义,虚词无实际含义。虚词通常不能作为句子成分运用在句子中。在汉语从古至今的演变体系中,实词是具有重要作用的,而虚词对语义无太大的帮助。所以在文章重复率检验中虚词并不是很重要。[4]
2.2 词语统计的特点 词汇出现的频率是文本特征的一个重点,因为重要的词汇在文中总是频繁出现。所以权重计算法也是具有其优势的。因为一篇文章中在标题或者摘要中出现的词汇,大多会在文本中被大量运用。出现频率较高的词汇是对文章主要思想的概括和提示,高频词汇的分布是文章检测的一个重要方面。[5]
3 特征词汇及其权重计算
3.1 分解与消除歧义
3.1.1 关键词分组 词汇分组在相似度高的文章中较为重要。因为关键词可以对其含义进行引申和外延,以近义或者同义词汇代替。本文采用[6]的方法完成关键词分组。计算中应当对近义和同义词进行分组,作好标记,用含义相似的词汇进行相互替代来解决语句产生歧义的问题,使文章检验较为容易一些。
3.1.2 词汇备选 本文运用文献[6]中提出的词汇分类与消歧算法,将文章用1、2、3….、i按顺序编号,而用CFWi代表第i篇文献的备选词汇组。将文章中的关键词相分隔和排序,将虚词从词汇序列中删除。将极低频率的词汇与极高频率的词汇按照文献库词汇进行删除,最后得到k个包含了已处理过的词汇分组序列。
3.2 语言含义属性 在2.1中我们知道了语言含义分为六个方面的特征。词意和词性是关键词集中分组和特征词汇组的建立的关键方面。剩下的四个方面可以进行数据量化处理,如下:
(1)层次结构的属性
将TOPWi、ABSWi、KWi、FTEWi、MTEWi、LTEWi分别代表第i篇汉语文献的标题词汇组、摘要词汇组、关键词组、正文中心词汇组、正文高频词汇组和末段词汇组。不同分组的词汇对文章含义及其中心论点的贡献比重不同。
则我们有
CFWi=TOPW1∪ABSWi∪KWi∪FTEWi∪MTEWi∪LTEWi
从语义分析的角度,本文方法作如下假设:当第i篇汉语文献的第j个词∈TOPWi时,则该词的层次属性LCFWij=5;当第i篇汉语文献的第j个词∈KW1时,LCFWij=4;当第i篇汉语文献的第j个词∈ABSWi时,LCFWij=3;当第i篇语文献的第j个词∈FTEWi∪LTEWi,LCFWij=2;当第i篇语文献的第j个词
∈MTEWi时,LCFWij=1.
(2)词汇搭配的属性
被标记词汇与词汇之间的距离也是一个重要方面,词汇之间距离越近,则对语义的贡献越大。所以需要将被标记词汇的观察范围定为[-2,+1]。将第i篇文章的第j个词汇在观察范围的设定内,那么它的词汇搭配权重为WCFWij=1。
(3)含义指示的属性
前面说过,指示语言也对文章中心思想的寻找提供了便利。因为提示词汇后面跟的很有可能就是文章中心含义。所以当第j个词处于第i篇的文章中,应该表示指示属性INDCFWij=1。
(4)学术领域的属性
将学术词汇与文章相关领域结合,第i篇文章的第j个词是第k篇文章中出现频率最高的1/3k个词汇,那么词汇学术领域属性IMPCFWij=1。
3.3 权重计算及特征词抽取 被抽取词汇对语言含义的贡献程度就是贡献因子,表示为CONij,代表第i篇第j个词的贡献程度。
令CONij=LCFWij+WCFWij+INDCFWij+IMPCFWij
第i篇文章中的第j个词在中出现的频率表示为FWPij,权重WEij的计算表达式为:
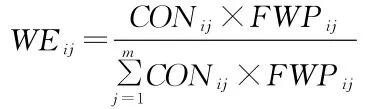
在第i篇文章中提取权重最高的词汇作为特征词,等待被检测的文献的特征词组
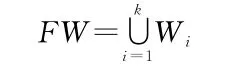
第i篇文章中提取的特征词表示为Wi,i表示按1、2、3…..、k排列的顺序。
3.4 汉语文献的向量表示
令FW=∪ki=1Wi={FWil,FWi2,……FWij……FWim},待检汉语文献集中文献Di将被抽象成为一个m维的特征向量,如下所示:
{(FWi1,WEi1),(FWi2,WEi2),…(FWij,WEij),(FWim,WEim)}(1≤j≤m).
4 相关联文献检测算法
(1)计算前的准备:将文章中的关键词出现频率及其相似程度进行计算,构建词组并将同义词和近义词进行替换。
(2)分解词汇和消除歧义:将全部的被标记词汇看作象征性标识,依据词汇组和排序,将预先准备好的替换过的文章进行语法分解,对不同性质的词汇进行数据化处理。已经经过处理后,对所有词汇进行消除歧义的处理,计算出词汇出现频率。
(3)对于词汇权重的计算:按照3.3的计算方法,对每篇文章的特征词汇进行贡献因子和权重的计算。
(5)提取特征词汇:按权重将词汇进行按1、2、3….i排列,选出权重较高的特征词组。
Wi(i=1……k),FW=
为等待检验的中文文献的特征词汇组。
(6)计算相似程度:将等待检验的文章Di抽象成一个维度为m维的空间向量。则两篇待检中文文献的相似度为:
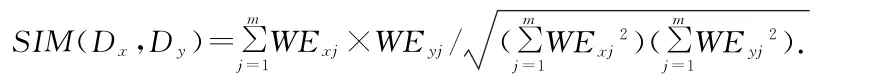
(7)相似程度的划分:相似程度等级参数可以划分为λ1,λ2,λ3。当SIM(Dx,Dy)≥λ1时,第x与y两篇文章相似程度极高;λ2≤SIM(Dx,Dy)≤λ1时两篇文章相似程度一般,λ3≤SIM(Dx,Dy)≤λ2时两篇文章相似程度较低;SIM(Dx,Dy)≤λ3时两篇文章不相似。
5 实验与结论
使用我们在[7]中方法进行实验,下面表1、表2、表3是实验结果:
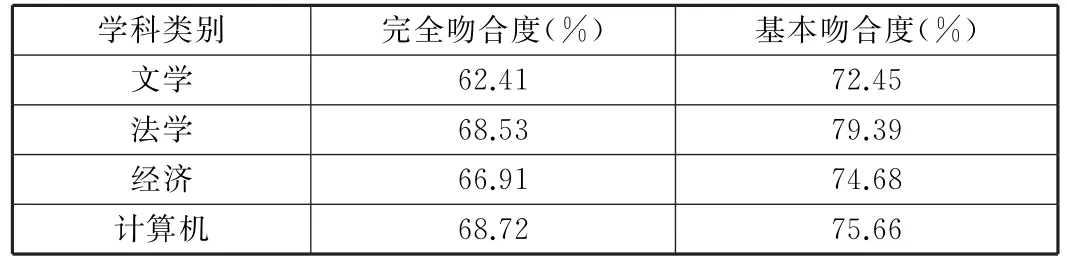
表1 完全吻合度与基本吻合度(k=10,m≤300)
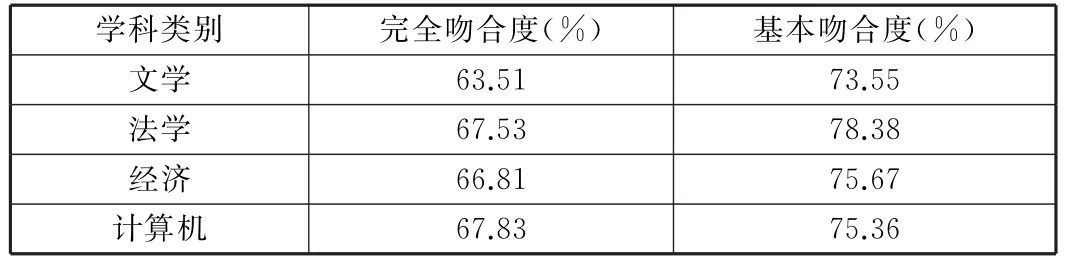
表2 完全吻合度与基本吻合度(k=10,m≤400)
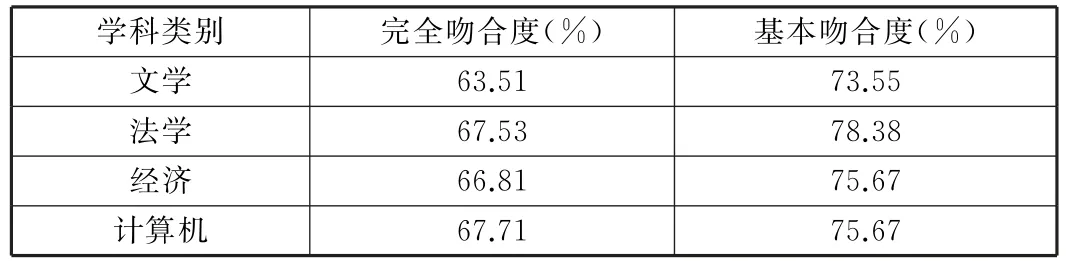
表3 完全吻合度与基本吻合度(k=10,m≤500)
从实验中我们可以看出当样本数量也就是特征词的数量大于300时,基本吻合度达到70%,完全吻合度可以达到60%。总实验结果看,这个方法既可以降低算法空间复杂度又可以提高运行效率和结果的准确度。
语言分解并抽取特征词来构建词汇检验体系和计算公式的方法能够有效地减少文章重复率检查算法的空间复杂度,提高运算效率和结果准确度,理想地达到了我们的目标。从实验过程中我们还可以看到,该方法的精确程度不会随着词汇数量的增大而提高,所以该方法对于精度的目标的要求不能很好地满足,还需更好的改善。在实验过程中,我们了解到了检验参数和消除歧义问题上的研究还能又更大的扩展,我们将对其进行更深入的研究,以提高算法的效率。
猜你喜欢
英语世界(2022年9期)2022-10-18
计算机系统应用(2021年9期)2021-10-11
现代信息科技(2020年18期)2020-02-22
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
计算机技术与发展(2018年8期)2018-08-21
计算机应用与软件(2018年1期)2018-02-27
小学生导刊(低年级)(2017年1期)2017-06-12
中国火炬(2011年10期)2011-07-24
