
基于改进型MobileNet网络的车型识别方法
2019-01-30 07:48黄跃珍王乃洲梁添才金晓峰
电子技术与软件工程 2019年1期
文/黄跃珍 王乃洲 梁添才 金晓峰
车辆结构化主要研究基于车辆视频、图像数据的车辆结构化信息,如:车型、年款、车身颜色、年检标、车牌等,的提取技术,是智慧城市大脑平台、智慧警务平台重要功能。在机动车辆管理、刑侦应用场景中,车型相对于机动车辆其他属性更基础、更直观,也更重要。车型识别受光照、遮挡、角度等因素影响,依然面临很大挑战,长期以来收到国内外研究人员广泛关注。
自从深度神经网络AlexNet赢得2012 ILSVRC竞赛以来,卷积神经网络(CNN)广泛用于视觉图像分类任务中,并取得较传统手工选取特征方法更加准确的分类效果。为追求越来越高的分类精度,CNN网络被设计的越来越深,参数规模也越来也大,以AlexNet网络为例,其在Imagenet-1000上训练的网络模型大小已达200MB,参数量已超过60M。一方面,更深的网络通常需要更大规模的高质量数据集用于训练,这将显著增加人力成本;另一方面,参数规模过大会显著影响识别系统实时性与并发性能。因而,在不影响精度的前提下,减小网络参数规模,成为CNN网络重要的研究方向。计算表明,CNN网络的绝大部分参数集中在全连接层与卷积层,减小全连接层与卷积层参数成为轻量级网络模型研究的重要方向之一。为获得轻量级网络模型,通常尽量避免出现全连接层,同时,研究含有较少参数的网络模块替代原卷积层。在AlexNet网络中首先提出了分组卷积(group convolution)思想。分组卷积虽然减少了参数,但同时带来计算效率低下,丢失不同组的feature map之间的关联信息。Inceptionv2/v3提出采用1x1与3x3卷积核替代5x5卷积核,获得了不错的效果。之后,1x1卷积、分组卷积以及后来的深度分离卷积(Depthwise Convolution)被广泛用于轻量级网络设计,如:SqueezeNet, MobileNet, Shuff leNet等。SqueeseNet网络主要由九个Fire Module组成,Fire Module作为核心组件由squeeze层与expand层组成。Squeeze层与expand层分别由1x1卷积核、1x1与3x3卷积核组成。通过1x1卷积核替代3x3卷积核可以将网络参数缩小9倍。MobileNet-v1利用3x3Depthwise Convolution结合1x1卷积核替代3x3卷积核,极大减小了网络参数。MobileNet-v2则很大程度上参考了ResNet的“1x1卷积+卷积+1x1卷积”的结构,所不同的是,为丰富可提取的特征,MobileNet-v2采取“先扩张,后压缩”的策略。MobileNet-v2较v1版本,不但精度获得很大提升,参数规模也较后者小很多。Shuff leNet网络为减小分组卷积带来的精度下降,提出了组间混洗学习策略,以提高通道组间信息流通,从而达到提升网络整体学习能力的目的。
本文基于轻量级网络MobileNet研究机动车车型识别问题。基于Squeeze-and-Excitation网络的SE模块,提出两种MobileNet改进策略,提高车型识别精度。最后,通过实际应用场景下的检测实验,证明所提出的策略的有效性。
1 改进型MobileNet分类网络
1.1 MobileNet网络
MobileNet分类网络是由Google针对嵌入式设备提出的一种轻量级的深度神经网络。目前,先后已有MobileNet-v1及MobileNet-v2两个版本,其主要模块如图1(a)和图1(b)所示。在MobileNet-v1网络中,采用Depthwise卷积(depthwise separable convolution)+1x1卷积减小传统卷积层参数,达到减小网络参数规模,提升网络前向计算速度的目的。与MobileNet-v1不同,MobileNet-v2网络提出了Inverted residual模块,该模块借鉴了resNet网络的residual模块。与后者先“压缩”再“扩张”不同,Inverted residual模块采用“1x1卷积(扩张)+Depthwise卷积+1x1卷积(压缩)”策略。如图1(b)所示,MobileNet-v2采用两种构造模块,当设置Stride=2时,利用shortcut连接减小随着网络梯度加深而出现的“梯度弥散”问题,使得MobileNe-v2网络能够设计的更深,因而能够获得更加好的训练效果。
用“Depthwise卷积+1x1卷积”替代传统的卷积层可以极大减小网络参数规模及卷积运算的计算量,然而,其缺点也相当明显:Depthwise卷积忽略了各通道上feature map的相关性,虽然后接1x1卷积进行修复,精度损失无法完全弥补。
1.2 Squeeze-and-Excitation 网络
Squeeze-and-Excitation Networks[8](SENet)是 Momenta 胡杰团队(WMW)提出的新的网络结构。SENet在ImageNet 2017 竞赛中的Image Classif ication任务冠军,在ImageNet数据集上将top-5 error从以前最好成绩2.991%降低到2.251%。
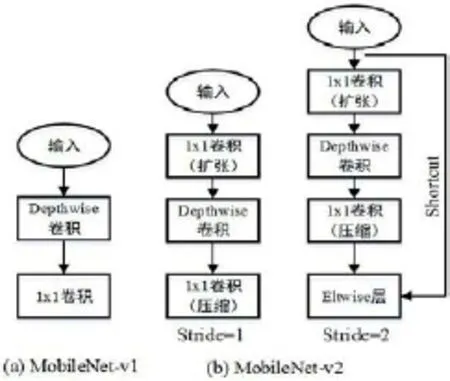
图1:MobileNet-v1与MobileNet-v2结构模块
SENet的核心思想在于学习feature map权重,使得有效的feature map权重增大,无效或效果小的feature map权重减小,从而达到提高网络训练精度的目的。SENet提出了SE模块,该模块包括Squeeze模块与Excitation模块,如图2所示。Squeeze模块通过global average pooling生成feature map的C维 embedding,其中C表示feature map 通道数:
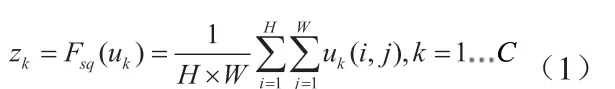
其中,uk表示第k通道的feature map。Excitation模块通过“FC压缩+FC拉伸+Sigmod归一化”得到最终feature map重要性描述子s:

1.3 改进型MobileNet分类网络
SE模块并不属于网络模型,而是独立于具体网络结构的子模块,因而可以嵌到其他分类或检测模型中。本文结合MobileNet网络与SE模块,提出两类新的分类网络:SEMobileNet-v1网络与SE-MobileNet-v2网络,并用于车辆类型分类问题当中,具体网络模块结构如下:
对于MobileNet-v1和v2不同的网路结构,我们将SE模块放置在不同的位置,这主要考虑了SE模块的“压缩-恢复”特性,为保护更多的feature map重要性权重被学习出来,对于Mobilenet-v2网络,将SE模块放在1x1卷积“扩张”层后面。

表1:车辆类型数据集样本数量分布

表2:各种算法识别准确率对比
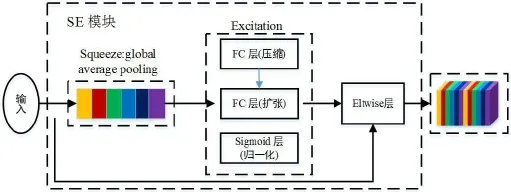
图2:SE网络模块
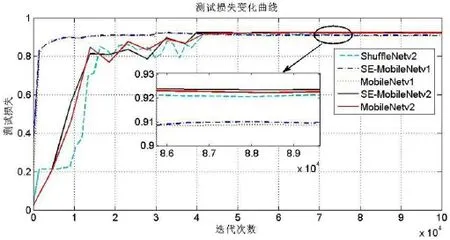
图5:测试损失变化曲线

图6:基于SE-MobileNetv2的机动车检测与车型识
2 实验结果与分析
2.1 实验数据集简介
实验数据来源于路边、岔口等摄像机采集的视频数据。将视频数据按帧抽取,并剔除遮挡严重、模糊、光线昏暗、车头朝后(由于车头向后的数据过少,为避免其影响分类精度,将其剔除)的车辆图片,进行手工标注,共获得57338张前向车辆类型图像,如图4所示,其中47738张图像作为训练集,其他9600图像作为测试集,测试集与训练集图像数量之比约为1:5。各类车型数量分布如表1所示。
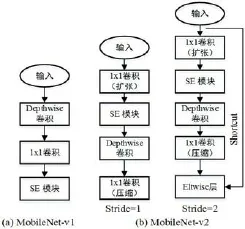
图3:SE-MobileNet-v1与SE-MobileNet-v2网络模块

图4:车辆类型数据集
不同型号的摄像机采集的视频图像可能会导致像素不一致的情况,为了满足深度卷积神经网络的输入要求,将所有的车型图像都归一化为 256×256 的大小。由于图像总体数量不多,将图片输入网络前进行了镜像处理,并采用crop size将图片随机裁剪为 224×224 像素大小,并且减去所有训练集图片的平均值。
2.2 实验结果与分析
本文所有实验均在Ubuntu16.0.4环境下进行,所使用的服务器安装有4块NVIDIA GeForce GTX 1080Ti显卡,采用Caffe框架进行实验。网络的训练参数设置如下:采用Multistep学习策略,初始学习率为 0.001,每20个epoch,学习率缩小10倍,权重衰减为0.0005,训练时Batchsize为32,测试时Batchsize为16,采用均方根反向传播(RMSProp)学习策略提高收敛速度,rms_decay设置为0.98。实验比较了五种网络模型,分别为:MobileNet-v1,MobileNetv2,SE-Mobilenet-v1和SE-MobileNet-v2和Shuff leNet-v2基础网络结构可参考文献[4][5][7],实验结果如图5及表2所示。
从图5可以看出,MobileNet-v2与SEMobileNet-v2网络在迭代4万次之后才开始收敛,因此,对这两个模型,我们设置了更大的最大迭代次数。通过表2可以看出,SE-MobileNet-v1与SE-MobileNet-v2分 别较MobileNet-v1、MobileNet-v2提 高 了0.13与0.22%。SE-MobileNet-v2甚至明显优于Shuff leNet-v2。
图6是将训练好的SE-MobileNet-v2模型嵌入到SSD网络中获得的车型检测结果。可以看出,除了部分车辆漏检外,对检出的目标,车型识别精度效果较好。
3 结束语
本文研究了基于轻量级网络MobileNet的车型识别方法。该方法可以实现对交通视频监控场景下9类车型(轿车、SUV、小客车、客车、货车、小货车、皮卡、面包车、MPV)进行识别。结合SE模块提出两种MobileNet改进型网络,并与传统MobileNet网络进行了比较,分别获得了0.13与0.22%Top1精度提升。最后,通过SSD车型检测实验验证了车型识别模型的有效性。
参考文献
[1]Krizhevsky A,Sutskever I,Hinton G E.ImageNet classification with deep convolutional neural networks International Conference on Neural Information Processing Systems[C].Curran Associates Inc.2012:1097-1105.
[2]Szegedy C,Vanhoucke V,Ioffe S,et al.Rethinking the inception architecture for computer vision 2016 IEEE Conference on Computer Vision and Pattern Recognition,USA,2016[C].Las Vegas,2016.
[3]Landola F N,Han Song,Moskewicz M W,et al.SqueezeNet:AlexNet-level accuracy with 50x fewer parameters and <0.5MB modelsize.2016:https://arxiv.org/abs/1602.07360.
[4]Howard A G,Zhu Menglong,Chen Bo,et al.MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications.2017:http://arxiv.org/abs/1704.04861.
[5]Sandler M,Howard A,Zhu Menglong,et al.MobileNetV2:Inverted Residuals and Linear Bottlenecks.2018:http://arxiv.org/abs/1801.04381.
[6]Zhang Xiangyu,Zhou Xinyu,Lin Mengxiao,et al.ShuffleNet:An Extremely Efficient Convolutional Neural Network for Mobile Devices.2017:https://arxiv.org/abs/1707.01083.
[7]Ma Ningning,Zhang Xiangyu,Zheng Haitao,et al.ShuffleNet V2:Practical Guidelines for Efficient CNN Architecture Design.2018:https://arxiv.org/abs/1807.11164.
[8]Hu Jie,Shen Li,Sun Gang.Squeezeand-Excitation Networks.2018:https://arxiv.org/abs/1709.01507
[9]Jia Yangqing,Shelhamer E,Donahue J,et al.Caffe:convolutional architecture for fast feature embedding.2018:https://arxiv.org/abs/1408.5093.
[10]Liu W,Anguelov D,Erhan D,etal.SSD:single shot multibox detector.2018:https://arxiv.org/abs/1512.02325.
猜你喜欢
车迷(2022年1期)2022-03-29
北京航空航天大学学报(2021年9期)2021-11-02
中国交通信息化(2020年11期)2021-01-14
电子制作(2019年11期)2019-07-04
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
测绘科学与工程(2016年5期)2016-04-17
汽车与安全(2015年12期)2015-09-10
车迷(2015年12期)2015-08-23
电子设计工程(2015年3期)2015-02-27
