
基于改进信息增益特征选择法的SVM中文情感分类算法
2019-01-24 03:10王根生黄学坚吴小芳胡向亮
成都理工大学学报(自然科学版) 2019年1期
王根生, 黄学坚, 吴小芳, 胡向亮
(江西财经大学 计算机实践教学中心,南昌 330013)
随着开放性、交互性互联网的发展,网络成为人们发表观点、信息、情感的新平台[1]。如何对这些传播的信息进行情感分析是网络舆情监测的一个重要部分。国内外的学者也已经开展了相关研究,国外学者主要专注于英文文本情感分类的研究,而由于中文表达的多样性,对中文情感分类的研究更具复杂性[2]。
目前文本情感分类算法主要分为基于语义理解和基于机器学习2类[3-4]。基于机器学习的文本情感分类思想是:通过事先标注好了情感标签的文本作为训练集,选择相关的机器学习算法进行训练,得到分类器,最后使用这个分类器对后续的文本进行情感分类[5]。Bo Pang等使用最大熵(Maximum Entropy)、支持向量机(SVM)、朴素贝叶斯(Native Bayes)等不同机器学习算法对文本的情感倾向性进行分类实验,发现SVM算法的效果最好[6]。
基于机器学习的文本情感分类算法的第一步是对文本进行分词处理,然后进行特征词筛选。如果直接使用分词后的词组作为特征空间会产生高维的数据,在高维数据空间进行训练会导致计算时间过长且得到的分类器效果不佳等问题[7-8]。针对此问题,唐慧丰等人[9]提出了基于信息增益特征选择的机器学习文本情感分类算法。本文在该方法之上引入词频和特征词情感表现程度的改进策略,对文本特征降维处理,采用SVM算法进行训练,实验结果显示该算法具有更好的分类效果。
1 相关理论
使用SVM算法进行文本情感分类时,主要涉及文本的特征表示、文本特征选择、训练器构建等[10]。
算法Ⅰ:基于SVM算法的文本情感分类算法
Step1:Select training set;//来源于事先标注好了情感标签的文本。
Step2:Preprocessing Text;//分词处理,排除停用词。
Step3:Text representation;//根据预处理后的结果进行特征选择与提取,构造特征表示。
Step4:Training classifier;//对训练集中的每个文本进行统一表示,采用SVM算法进行训练,得出分类器。
Step5:Test classifier;//选择测试集测试分类器的准确率等相关指标。
1.1 文本特征表示
对文本进行特征表示是机器学习中一个重要的步骤,一个好的特征表示不仅反映了文本的基本内容,并且对不同的文本特征也能很好地区分[11]。常见的表示模型有布尔模型(Boolean Model)、向量空间模型(VSM)、概率模型(Probabilistic Model)和潜在语义索引模型(LSI)等[12]。向量空间模型(VSM)是目前文本特征表示中运用最广泛的模型[13],它包含3个基本概念:①文本(document),由一定数量的特征词组成。②特征项(feature term),文本特征词组成了特征项原始空间,向量空间模型使用这些特征项表示为di(ti1,ti2, …,tin),di表示第i个文本,tik表示第i个文本的第k个特征项。③特征项权重(term weight),在特征向量中,对每个特征项都要进行相应的权重计算,权重的大小作为区分文本类别的贡献程度[14]。文本di表示为di(ti1=wi1,ti2=wi2,…,tin=win),简记为di(wi1,wi2,…,win),其中wik就是第i个文档中第k个特征项的权重。权重计算目前用的较多的是TF-IDF算法[15]。
1.2 文本特征选择
文本经过分词和去停用词后,会产生一个较大的原始特征空间。特征空间中每个特征对分类贡献的大小不同,选择贡献大的特征词,降低特征空间复杂度,以提高机器学习算法的效率[16-17]。目前,特征选取的方式有3种:①采用变换或映射等方法将最原始的特征进行转换,从而减少特征的数目;②依据相关领域专家的先验知识选取;③使用数学方法计算每个特征对分类判别贡献的大小,从而进行特征选择。
使用数学方法进行特性选取是比较精确的,因为人为干扰因素较少,在选择准则上都是基于特征词的频率或出现特征词的文档频率,常用的方法有:文档频率(document frequency)、互信息(mutual information)、期望交叉熵(expected cross entropy)、χ2统计法和信息增益(information gain)等[18]。信息增益方法在文本情感分类中表现得比较优秀,其计算方法为
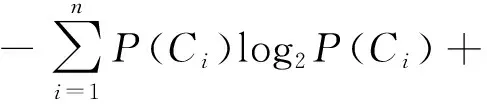
(1)

1.3 SVM分类器
支持向量机(SVM)算法通过核函数把低维特征空间不可线性分割问题转换到高维特征空间,使得问题求解在高维特征空间线性可分[19]。其以良好的性能在模式识别、图像分析、自然语言处理等相关领域得到广泛运用。
SVM的核函数有多种类型选择,常用的核函数有4种:①线性核函数;②多项式核函数;③径向核函数;④sigmoid核函数。
2 基于改进信息增益特征选择法的SVM算法
传统的信息增益方法在计算过程中只考虑了特征出现与不出现2种情况和特征对全体样本的贡献,而没有考虑到单个局部样本,所以该算法在全局效果较好,而在某些局部样本空间的表现不佳。
2.1 融合词频与情感程度的信息增益特征选择方法
针对传统信息增益方法的局限性,本文提出融合词频和特征词情感程度的改进思路。
a.引入词频
词频指词语在文本中出现的次数,频率越高的词语越能代表文本的特性。设文本的特征集合为T={t1,t2,t3,…,tn},训练集文本di1,di2, …,diNi属于类别Ci(1≤i≤2),其中Ci类的文档总数为Ni,tfik(tj)代表特征tj(1≤j≤n)在文本dik(1≤k≤Ni)中出现的频率。再对每个词频进行归一化处理,特征项tj在类别Ci中出现的频率表示为tfik′(tj),令Aj=tfik′(tj),计算公式为
(2)
b.引入词语情感表现程度
本文使用知网语义相似度公式进行词语情感表现程度计算,将语义相似度融入到特征选择过程中。为了计算方便,对计算公式进行归一化处理
(3)
式中:Bi为特征i的情感表现程度;O(wi)为特征i的情感权值;n为所有特征的个数。其中O(wi)参考知网语义相似度计算公式
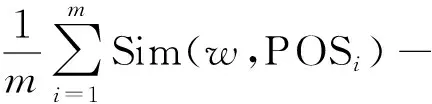
(4)
式中:POS代表褒义词集合;NEG代表贬义词集合;m为褒义词集合的大小;n为贬义词集合大小;Sim(w,POSi)为词语w与POS中第i个词语的相似度;Sim(w,NEGj)为词语w与NEG中第j个词语的相似度。
c.改进的信息增益
综上所述,根据词频公式(2)和词语情感程度公式(3),对信息增益计算公式(1)重新定义,计算式为

(5)
2.2 改进信息增益特征的SVM算法
使用改进后的信息增益计算公式(5)对算法Ⅰ中Step3进行优化,并且为了降低算法的复杂度,进行了2次特征选择,第一次使用传统的信息增益方法进行粗略降维,再使用本文改进的信息增益方法进行第二次降维。
算法Ⅱ:基于改进信息增益特征SVM算法的文本情感分类算法
Step1: Select training set;//对训练文本进行情感标注。
Step2: Preprocessing Text;//对文本进行分词和去除停用词处理,构成原始特征集合。
Step3:First feature reduction;//使用传统的信息增益方法对原始特征集合进行特征选择,构成第一次降维后的特征集合。
Step4:Secondary feature reduction;//通过词频与情感程度融合的信息增益方法对Step3筛选后的结果再降维,构成最终的特征子集合。
Step5: Training classifier;//使用最终的特征子集合构成文本特征表示,作为SVM算法的输入数据进行训练。
Step6: Test classifier。//对最后得出的分类器进行测试。
3 实验与分析
本实验主要比较不同的特征选择方法下SVM算法在文本情感分类中的表现。训练样本来源于各大网站的评论性文章,涉及财经、房地产、汽车、娱乐、体育等领域,共2 000篇文章,并对文章表达的褒贬情感进行人为标注。在实验过程中,分别使用文档频率(DF)、χ2统计法、信息增益(IG)以及本文改进的信息增益法进行特征选择,使用归一化后的向量空间模型(VSM)作为文本特征表示,借助SVM的开源库LIBSVM和sigmoid核函数进行SVM算法试验,使用交叉验证的方式进行验证,使用查全率(recall)与查准率(precision)对算法进行衡量。实验对训练样本进行了3次随机选择训练,具体结果如表1所示。
从实验结果数据能够看出,基于本文改进的信息增益特征选择的SVM算法在查准率、查全率上都有提高,因为它在特征选择时从全局和局部2个方面进行了衡量。在得到基于改进信息增益特性选择的SVM分类器后,再重新选择测试数据集进行测试,测试数据集依然来自财经、房地产、汽车、娱乐、体育5个领域,每个领域各300篇已标注了褒贬情感类别的文本,测试结果如表2所示。

表1 不同的特征选择方法下SVM文本情感分类算法性能比较Table 1 Algorithm performance comparison of SVM text sentiment classification under different feature selection

表2 分类器在不同领域的性能表现Table 2 Performance of classifier in different fields
从测试结果看,娱乐领域的评论性文章的查全率和查准率的结果值最高,因为该领域的评论性文章的褒贬情感最为明显;其他几个领域虽然比训练时交叉验证的结果低一点,但分类器依然保持了较好的泛化能力。为了进一步证明该算法的性能,再选取不同数目特征集的情况下对传统信息增益特征选择的SVM算法和基于本文改进的信息增益特征选择的SVM算法进行对比实验,特征集的大小从100递增到1 000,每次递增100,使用F-measure来衡量算法的性能。F-measure是查全率与查准率加权平均值,也同样进行3组实验,以3组结果的平均F-measure来衡量性能(图1)。

图1 不同特征集个数下2种算法性能比较Fig.1 Performance comparison of two algorithms with different feature numbers
由图1可以看出,开始阶段随着特征集数目的增加2种算法的性能都有提高,但超过一定数目后性能反而随着特征集数目的增加而降低,这是由于特征数目较少时SVM算法处于欠学习(underfitting)状态,而超过一定特征数目后处于过学习(overfitting)状态。而且在不同特征集数目下,本文改进的算法分类性能一直优于基于传统的信息增益SVM算法,在特征集数目较少的情况下优势更为明显。因为传统的信息增益方法是根据特征对整个系统分类贡献的大小选取的,没有考虑特征词在某个特定类别下的贡献,选取特征集数目较少时,这些对全局分类贡献不大,但对特定类别下分类贡献较好的特征很难被选中。本文引入词频和词语情感表现程度的改进的特征选择方法综合考虑了特征在全局和局部的贡献大小,改善了整个算法分类的效果。
4 结 论
本文介绍了文本情感分类的主要方法,针对传统的信息增益特性选择法的局限性,提出引入词频和特征词情感表现程度的信息增益特性选择算法,提高了特征选择的准确性,再通过选择后的特征构造文本向量,使用SVM算法进行训练。通过实验对比,本算法比传统的算法具有更好的分类效果。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20
电子制作(2019年19期)2019-11-23
电子制作(2018年19期)2018-11-14
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
中国修辞(2017年0期)2017-01-31
电子制作(2016年1期)2016-11-07
智能系统学报(2015年4期)2015-12-27
读者·校园版(2015年7期)2015-05-14
图书馆论坛(2014年8期)2014-03-11
