
基于数据挖掘的食品安全风险预测
2019-01-22 03:04
福建质量管理 2019年2期
(兰州财经大学 甘肃 兰州 730020)
引言
面对“一带一路”国际贸易迅猛发展的形势,中国与丝绸之路沿线国家和地区食品贸易趋于频繁,中国是最大的食品进出口贸易国,食品质量安全控制的需要更加迫切[1]。进口食品安全抽检每天都会产生大量的检验数据,从大数据视觉进行分析处理更为合适[2-3]。本文将从食品特性出发,运用数据挖掘理论来建立一个能够对食品安全风险准确评价的模型。
一、方法介绍
(一)BP神经网络
BP(Back Propagation)是一种按误差逆向传播算法训练的多层前馈网络。图1所示的是一个有3个输入节点,隐藏层包含4个节点,1个输出节点的三层BP神经网络。
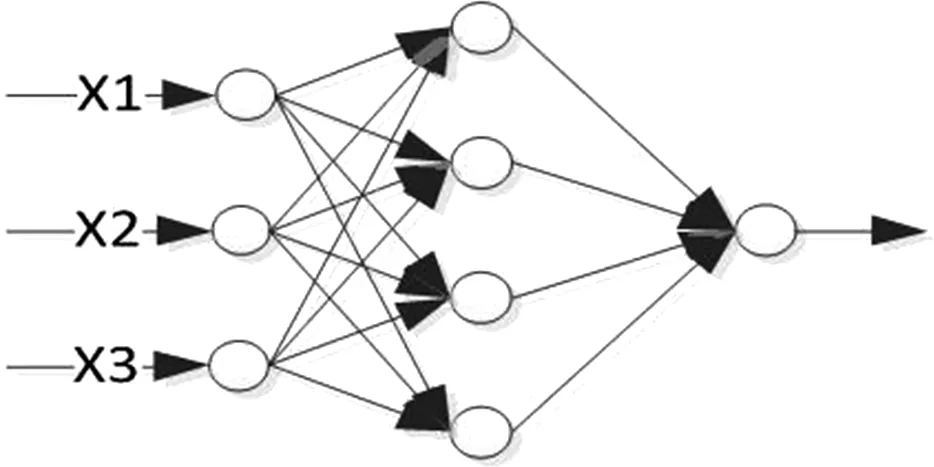
图1 三层BP神经网络结构
BP算法的学习过程由信号的正向传播与误差的逆向传播两个过程组成。正向传播时,输入信号经过隐藏层的处理后,传向输出层。若输出层节点未能得到期望的输出,则转入误差的逆向传播阶段,由隐藏层向输入层返回,并传递给每一个节点,从而获得各层单元的参考误差,作为修改各单元权重的依据,各层权矩阵的修改过程周而复始进行,也就是网络训练的过程。此过程一直进行到网络输出的误差逐渐减少到可接受的程度或达到设定的学习次数为止[4]。
(二)Logistic
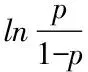
Logistic回归模型为:
(三)决策树
C4.5算法生成决策树模型具体过程
a)计算信息熵:按照目标属性对数据集进行划分,得到信息熵
b)按照数据集分类属性集中的每个属性进行划分,得到一组信息熵
其中,v表示某一个属性的取值个数。
c)计算信息增益
Gain(A)=Info(D)-InfoA(D)
d)计算信息增益率
其中,IV是一个用来考虑分裂信息的度量,计算如下:
其中,V表示属性集合中一个属性的全部取值。
e)选择决策树节点
选择信息增益率最大的属性作为决策树的当前结点。
二、实验设计
(一)描述。本文分析的主要目的是使用历史抽检数据所记录的样品属性数据训练BP神经网络模型,探索、挖掘食品属性和食品检验结论之间的关系,评估模型性能,并利用这种潜在的相关性进行预测和识别食品样品的安全状态。
(二)数据探索分析及预处理
1.特征分析。数据集包含15个属性,包含样品编码、检测项目结果、样品状态等信息,数据集呈现如下特点:(1)稀疏性:每一个样品检测记录和每一个检测项目属性值存在大量的空值。(2)离散性:不同检测项目的国家标准限量呈现差异,每个项目的实测值也是无序的。并且部分检测项目检测单位不一致。(3)不平衡性:分类属性列取值包括合格、不合格和缺失,占比一次为0.03:0.77:0.20。
(三)数据预处理。针对数据集的上述特点,数据处理方式如下:统一检测数据单位,将数据集标准化。检测项目下空值和NA,替换为该项目下实验室检测低限中非零值的最小值;将样品状态列存在的空值替换为合格。
三、模型构建
(一)建模算法选择
进口食品安全风险预测其本质就是预测该类食品存在质量问题的倾向性即预测进口食品是否合格,属于二元分类预测模型。对二元分类预测模型而言,最常用的有神经网络、决策树、逻辑回归和支持向量机等算法。本文中进口茶叶类食品风险预测模型,输入变量是连续型变量,输出变量是分类变量。因此选择神经网络.逻辑回归、决策树3种模型建模,并对这些模型预测结果进行评估。
(二)建模参数设置
1.样品合格状态作为输出变量。其他变量设为输入变量。
2.将数据集分成训练集和测试集,评估检验模型的精度和泛化能力。本文模型设置训练集和测试集大小各占0.7,0.3。
3.数据集中进口茶叶安全风险预测样本中不合格样品大约占到4%,合格样品占比为96%,样品合格状态呈现不均衡分布,采用十折交叉验证模型。
四、模型评估
(一)不同模型的误差分析
将训练数据集导入WEKA,选择分类方法下的Multilayer Percerptron算法,进行BP神经网络训练,训练过程分为构建网络模型和模型交叉验证2步[6]。
在数据集有较多特征属性时,BP神经网络模型的构建过程耗时长,训练好的模型确定了各个节点的内部阈值以及节点之间的权值,表示在这些确定的取值下,模型的输出结果最为准确。模型建立后采取十折交叉运算进行准确性检验,模型评估指标如下表2。
综合来看,茶叶风险预测模型的预测还不够理想,错误还有提升的空间,需要进一步优化。
五、模型优化
(一)优化思路
鉴于茶叶风险预测3个模型性能表现较好,并且性能表现相差不多。3个模型均利用项目检测值进行训练,某个样品的某项目检测值表示当前该项目状态,预测某个样品的风险需要综合考查各个待测项目发生风险的概率,考虑到实际因素,因待检样品数量大,且每一类样品有包含众多待测项目,并不可能对待测样品所有检测项目进行检验,因此综合利用项目实际检测值和项目被测的频数优化风险预测模型。具体方法如下:
1.计算待测项目不合格率P1i;
2.计算项目i权重Wi;
3.计算输出值Yj;
原来模型输入变量保持不变,上述计算结果作为优化模型训练的分类预测结果。这样,不仅充分利用项目实际检测值信息,而且综合考虑项目检验次数不平衡性以及样品分类结果不平衡性特征,旨在增强模型的预测性能[7-9]。
(二)优化后模型比较
优化后模型评估结果如下表2:
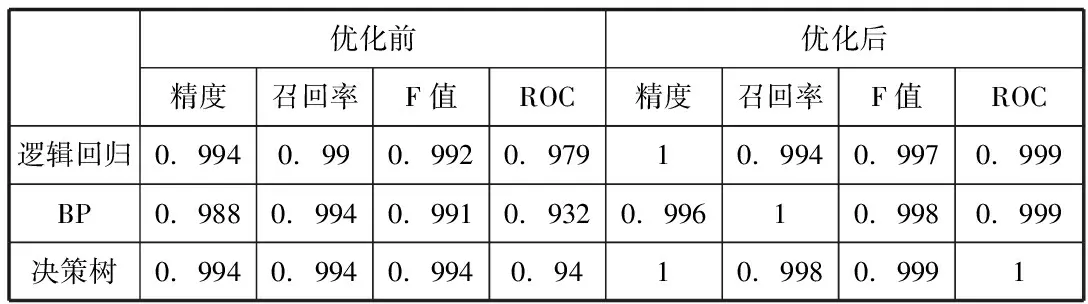
表2 优化前后模型评价指标结果
六、结论
以数据挖掘理论为基础,选用决策树、逻辑回归和神经网络算法作为初始算法构建了风险预测模型,发现仅利用检测信息训练模型有改进的可能。最后,从检测数据分布角度入手,优化模型,将三种模型进行比较,各个模型性能相差不大,但模型泛化能力较弱,优化后模型表现较好可为食品安全风险监管提供参考。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
电子制作(2019年19期)2019-11-23
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
