
基于程序频谱的缺陷定位方法①
2019-01-18 08:30余晓菲蒋建民
计算机系统应用 2019年1期
蔡 蕊, 张 仕,2, 余晓菲, 蒋建民,2
1(福建师范大学 数学与信息学院, 福建 350117)
2(福建师范大学 数字福建环境监测物联网实验室, 福建 350117)
随着软件项目的规模不断变大, 软件的可靠性也越来越难以保障. 精准、有效的软件缺陷定位技术则有利于发现软件中潜在的问题, 从而提高软件的可靠性. 为修改测试中发现的问题, 需要进行程序的调试,其过程又可以分为缺陷定位和缺陷改正两个步骤[1]. 早期的缺陷定位以人工为主, 通过在程序中设置断点分析程序, 从而逐步找到缺陷发生的源头. 人工定位缺陷的方法不仅难度大, 而且非常耗时, 对于大型、复杂的软件则更是如此. 因此, 研究人员提出多种缺陷定位方法, 根据是否需要执行测试用例, 又可分为静态缺陷定位技术[2-4]和动态缺陷定位方法[5-7]. 其中, 动态缺陷定位方法则需要执行被测程序, 搜集程序执行过程的行为和执行结果来定位缺陷. 在动态缺陷定位方法中, 基于程序频谱的动态缺陷定位(SFL)具有很好的定位效果, 是目前软件缺陷定位问题的研究热点.
目前, 已经提出很多基于频谱的缺陷定位方法[8]:其中, Jone等人首先提出Tarantula[9]方法, 取得不错的缺陷定位效果; Abreu等人提出Jaccard[10]方法和Ochiai[11]方法, 其中Ochiai方法效果相比Tarantula方法有了一定的提高; Gonzalez增加了排除正确语句的优化, 提出了Zoltar方法[12]; Naish等人使用自组装映射中计算相似度计算相似度的方法来寻找缺陷语句,引入Kulczynski1方法和Kulczynski2方法[13]; Wong 等人[14]进一步分析了成功测试用例数对缺陷定位的影响.他们认为, 语句被成功测试用例覆盖的次数越多, 该语句的覆盖次数对可疑值的贡献度越小[15], 因此提出了Wong1(s)、Wong2(s)和Wong3(s)三个公式, 但当成功执行的用例数量较多时, 利用分段函数降低成功用例的影响这些是不够的, 将对缺陷定位效果的提高不会很明显. 随后为了突出失败用例的影响, 又提出D*方法[16]. 通过实证研究发现D*方法要优于其他缺陷定位方法.
针对Wong1(s)、Wong2(s)和Wong3(s)分段函数不能自主适应用例数量这一缺点, 本文从成功执行用例数量调节出发, 提出EP*缺陷定位方法, 该方法具备自主调节成功测试用例覆盖比重的能力, 以提高方法的适用性范围和有效性. 本文把该方法与其他缺陷定位方法进行对比, 实验结果表明该方法的缺陷定位效果优于现有缺陷定位方法.
本文的第1节介绍了基于频谱的缺陷定位方法的基本概念, 并通过一个简单的引例说明了本文方法的基本原理和公式; 第2节中详细说明了本文实验所使用的测试程序集及评测指标; 第3节中则通过对比分析, 详细说明了EP*的有效性; 最后1节总结全文.
1 基于频谱的缺陷定位方法
1.1 基本概念
Reps 等人[17]首次提出程序谱概念, 后面的研究者们将程序频谱[18-20]用于程序分析. 程序频谱主要是指程序执行过程中产生的关于程序语句的覆盖信息(被覆盖为1, 未覆盖为0), 以及执行是否通过信息.
在利用测试用例集进行程序的测试过程中, 收集程序语句的覆盖情况和测试通过与否等相关信息, 将每一程序实体s相关的统计数据用一个四元组T(s)=<Tep(s),Tef(s),Tnp(s),Tnf(s)>来表示, 其中Tep(s)和Tef(s)分别表示覆盖程序实体s的成功测试用例数和失败测试用例数,Tnp(s)和Tnf(s)分别表示未覆盖程序实体s的成功测试用例数和失败测试用例数. 测试套件T中所有成功测试用例数Tp=Tep(s)+Tnp(s), 所有失败测试用例数Tf=Tef(s)+Tnf(s), 所有测试用例数T=Tp+Tf.
Tep(s)的数值越大, 说明语句s执行且用例成功的次数多,s是缺陷语句的可能性越小;Tef(s)的数值越大,说明语句s执行且用例错误的次数多,s是缺陷语句的可能性越大;Tnf(s)的数值越大, 则说明语句s没有被执行到的情况下错误越多, 这间接说明s是缺陷语句的可能性越小.
1.2 EP*的缺陷定位方法
Wong等人[14]总结的假设5-7说明了:可疑值与Tef(s)大小成正比, 与Tep(s)大小和Tnf(s)大小成反比,可以设Kulczynski系数为1来表示Tef/(Tnf+Tep). 基于假设8对Tef设置更高的权重, 可以设置Kulczynski系数为2来表示2*Tef/(Tnf+Tep). 但Kulczynski系数在缺陷定位的准确性上不够. 考虑到这一点, Wong等人提出采用*系数, 取值范围从2~50增量为0.5. 提出D*方法, 通过实验验证该方法在缺陷定位上效果很好.
此外, 在文献[21]中, 其通过预处理的方式去除部分测试用例, 也是希望减少成功执行数量对可疑值的过度影响, 以提高定位精度. 由预处理目的[21]和Wong等人D*公式启发, 为了有效降低Tep(s)对整体数值的影响, 本文提出EP*方法, 如公式 (1)所示. 公式采用*系数, 取值范围与D*一样. 在具体的应用中,Tef数量要比Tep小很多, 在降低Tep的权重时对缺陷定位的影响会更加明显.本文实验也验证了这个猜想, 说明了EP*方法的缺陷定位要比D*方法更优.
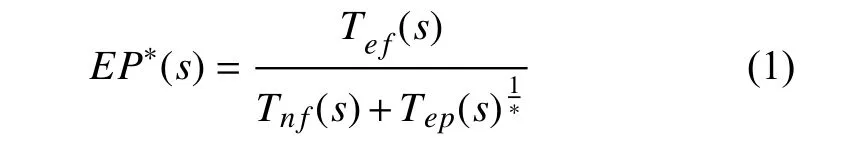
1.3 引例
为了更好的理解, 我们通过一个实例[16]来说明EP*缺陷定位方法. 在表1中, S表示待测程序的语句集, S={s1,s2,s3,s4,s5,s6,s7,s8,s9}, si表示具体的程序语句;P表示被测程序实体, 其中缺陷语句是s3;ti表示第i个测试用例执行对程序的覆盖向量, 其中黑点代表该语句被执行, 反之未执行; 表1中最后一行的P/F表示执行成功与否, 0表示测试用例执行成功, 反之失败;susp1表示测试用例基于Ochiai技术计算的可疑值;rank1表示程序中可疑值大于等于该语句的数量(含该语句本身). 从表1中可以看出, 缺陷语句s3的排名与语句s4并列第3, 表示为确保测试人员找到缺陷语句,最多需要检查3条程序语句.

表1 示例程序表
表2对比了D*方法和EP*方法中的Kulczynski系数取为1、2、3时的示例程序排名情况. 结合表1, 可以发现, 当Kulczynski系数取 1时, 缺陷语句排名rank2=4;Ochiai方法的缺陷语句排名rank1=3, 则Kulczynski1方法的定位效果不如Ochiai方法. 当Kulczynski系数取2时,D*方法的缺陷语句排名rank3=3;EP*方法的缺陷语句排名rank5=2, 提升两名,则EP*方法的定位效果比D*方法和Ochiai方法好. 当Kulczynski系数取3时,D*方法的缺陷语句排名rank4=2, 提升一名;EP*方法的缺陷语句排名rank6=2保持不变. 从该例中可以看出,EP*方法在取相同系数时, 能够更快逼近最优值. 同时也可以发现, 由于s3和s4具有相同的覆盖情况, 任何可疑度计算都无法区分二者, 即当Kulczynski系数取2和3时,rank5=2、rank6=2已经达到最佳缺陷定位效果.
在表2中, 语句s1、s3和s6的执行通过语句数分别是Tep=8、Tep=7和Tep=2.在Kulczynski1方法中不同的语句的覆盖次数对怀疑率的贡献度是一样的, 但语句s1和s3的Tep值要比s6大很多, 所以s1和s3的排名都在s6后面, 而s1和s3的排名很接近. 在EP2方法中, 不同的语句的覆盖次数对怀疑率的贡献度不同, 其中Tep值越大, 贡献度越低. 这样就减弱了执行通过语句数Tep对语句s1、s3与s6的影响. 但s3中的Tef比s1和s6大, 所以s3的排名都在s1和s6前面. 因此EP*方法能够减弱执行通过语句数Tep对可疑值的过度影响.

表2 可疑值计算对比表
基于上述分析, 简要说明了本文提出的EP*方法在缺陷定位中的应用, 在该实例中,EP*方法显著减弱了执行通过语句数Tep对可疑值的过度影响, 使其缺陷定位效果比Ochiai和D*方法好. 当系数取2时,EP*方法中的缺陷语句排名已经达到D3方法的缺陷语句排名,从中可以看出,EP*方法比D*方法收敛更快. 在下一节中将通过实验对比分析EP*缺陷定位方法与其他缺陷定位方法的实验结果.
2 实验
本节首先介绍目标程序信息, 再通过实验说明EP*方法的缺陷定位效果.
2.1 测试程序集
实验使用了SIR中的Siemens suite测试套件和space 程序[22], Siemens suite 包含 7 个程序, 它是由实现不同功能的C 程序组成, 每组程序通过人工注入的方式植入缺陷. space程序测试包含的多个版本都是实际的缺陷, 其详细信息如表3所示. 表3中各列分别表示程序名、每个程序缺陷版本数、程序代码行数、测试用例个数、程序功能的简要描述. 该测试集涉及各种缺陷类型, 以模拟实际可能存在的缺陷. 本实验用到了Siemens suite测试套件中的121个版本和space程序的20个版本. 其中, 去除某些缺陷版本的原因有:“Core dumped”错误无法生成覆盖文件、宏定义错误和头文件缺陷等.

表3 实验程序信息
2.2 缺陷定位评测指标
基于语句排名的评测采用了Score评测指标. 按照可疑值Suspiciousness的取值从高到低进行排序, 值越高代表该语句为缺陷语句的可能性越大, 反之, 则代表该语句是缺陷语句的可能性越小. 假设排查程序P={s1,s2,…,sn}, 其中 sf为缺陷语句,n为程序 P 的语句数.衡量缺陷定位方法优劣的指标是看在该方法中, 按可疑率排序缺陷语句被检查到的位序(Rank). 当存在m(m>0)个语句与缺陷语句sf的可疑值取值相等时, 目前有两种方法计算Rank值. 假设可疑值高于sf的程序语句个数为t, 则方法一: 考虑最坏情况, 即设缺陷语句的Rank=m+t, 本实验采用该方法计算Rank值; 方法二:考虑平均情况, 即设缺陷语句的Rank=t+m/2. 基于缺陷语句的Rank值, 常用的评测指标为Score如公式(2)所示, 其表示不用检查的语句占所有语句的百分比.Score值越高, 则说明程序员在缺陷定位时不用检查的语句越多, 需要检查的代码行数越少, 也就说明了缺陷定位的效果越好, 反之, 则说明缺陷定位方法效果差.

3 实验分析
为了能够清晰对比本文所提出的缺陷定位方法EP*对缺陷定位的影响, 本节通过实验对比Tarantula方法、Jaccard方法、Ochiai方法和D*方法的Score评价指标来说明该方法的有效性, 实验设置系数(*)分别为3、5和10. 表4是基于西门子套件的每个分数范围运行百分比, 而表5是基于space程序的每个分数范围运行百分比.

表4 西门子套件中的每个分数范围运行百分比
从表 4 中可以看出,D3、D5、D10、EP3、EP5和EP10的所有缺陷语句均能在不用检查的语句占所有语句的 65% 内被发现, 但Tarantula、Jaccard、Ochiai和Kulczynski1在检查35%代码后还有少部分缺陷语句是无法排查到. 查看Score在99-100%区间内, 即, 检查代码数量在1%内便可确定缺陷代码位置的情况. 其中EP3、EP5和EP10在检查代码数量的1% 内可排查缺陷占 10%, 分别比Kulczynski1、Jaccard、Tarantula、D10、D5、D3、Ochiai的准确率提升了 4.55、4.55、4.55、1.82、2.73、2.73、3.64 个百分点. 图1(a)对应于表4数据, 表示基于西门子套件的Score值的缺陷定位效果对比图. 从图中可以发现EP3、EP5和EP10曲线均在其它方法的曲线上面, 然后是D10、D5和D3曲线, 最下面的曲线是Tarantula. 由此可知: 在缺陷定位效果上, 基于西门子套件中EP*方法只需检查更少量的代码行就可以找出缺陷位置, 即,EP3、EP5和EP10比其它方法好, 其中Tarantula方法最差.
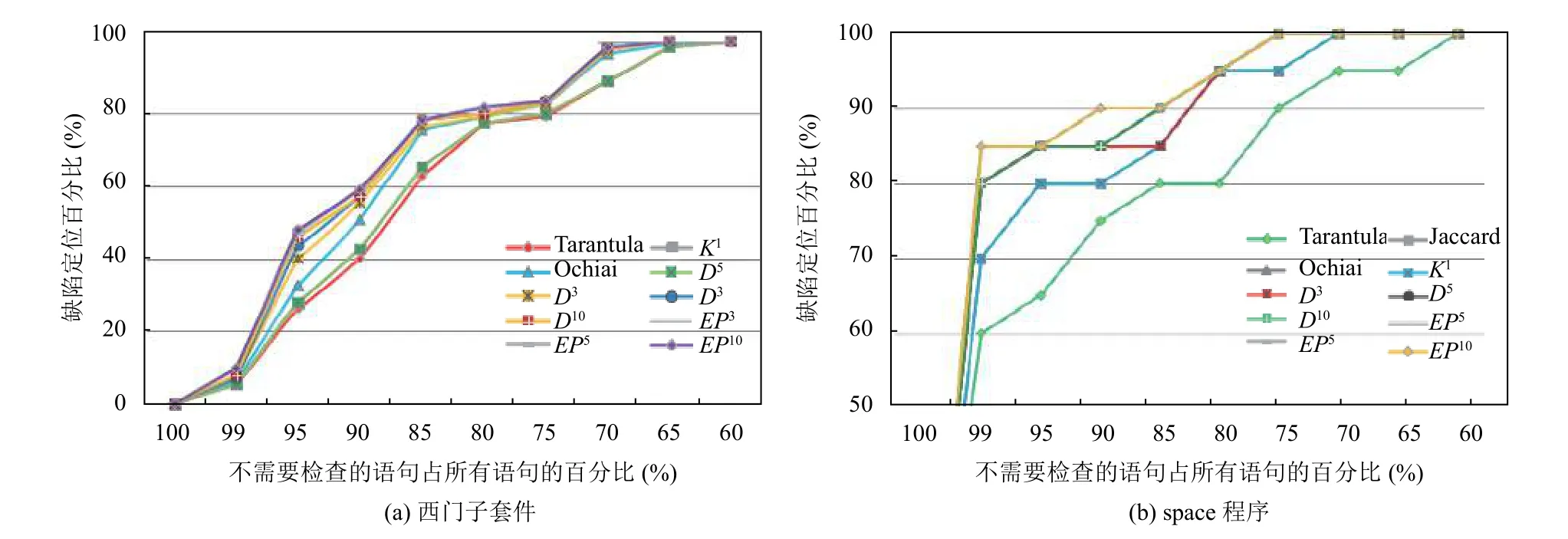
图1 基于Score值的缺陷定位效果对比图
从表 5 中可以看出,D3、D5、D10、EP3、EP5、EP10和Ochiai的所有缺陷语句均能在不用检查的语句占所有语句的90%内被发现, 但Tarantula、Jaccard和Kulczynski1在检查10%代码后还有部分缺陷语句是无法排查到.其中EP3、EP5和EP10在检查代码数量的 1% 内可排查缺陷占 85%, 比D10、D5、D3和Ochiai提升了5个百分点; 比Kulczynski1和Jaccard准确率提升了15个百分点; 比Tarantula准确率提升了25个百分点. 图1(b)对应于表5数据, 表示基于space程序的Score值的缺陷定位效果对比图. 从图中可以发现EP3、EP5和EP10曲线均在其它方法的曲线上面, 然后是D10、D5和D3曲线, 最下面的曲线是Tarantula. 由此可知: 在缺陷定位效果上, 对space程序,EP*方法只需检查更少量的代码行就可以找出缺陷位置, 即,EP3、EP5和EP10比其它方法好, 其中Tarantula方法最差.
从收敛性上分析表4数据, 分数范围运行百分比为99%时EP3、EP5和EP10已经收敛达到最佳定位效果Score值为 10, 但D3、D5和D10的Score值分别为7.27、7.27 和 8.18, 显然比EP*低. 再查看Score值在90~100%之间的情况(即发现缺陷需检查代码在10% 范围内),EP3、EP5和EP10值均达到 59.09, 而D3、D5和D10的值分别为55.45、57.27和57.27. 从中可以明显看出, 随着系数增大,EP*比.D*更快接近最佳定位效果. 所以EP*方法的收敛性比D*方法好.
通过上述实验及分析可以发现, 在目标测试程序中,EP*方法表现出很好的缺陷定位效果, 比现有的缺陷定位方法都要好很多.
4 结果与展望
通过实验发现, 基于EP*的缺陷定位方法有利于提高缺陷定位效果, 实验结果表明,EP*方法的缺陷定位效果比现有的方法好, 而且能够有效调整成功执行用例数, 以避免成功用例数量对缺陷定位效果的影响.
猜你喜欢
舰船电子工程(2021年2期)2021-03-16
智能计算机与应用(2020年10期)2020-03-18
中国新技术新产品(2018年4期)2018-02-23
决策与信息(2016年29期)2016-12-02
科技资讯(2015年8期)2015-07-02
电脑知识与技术(2014年29期)2014-11-07
数学教学通讯·初中版(2014年6期)2014-08-11
小学生·多元智能大王(2014年6期)2014-07-09
小雪花·初中高分作文(2009年8期)2009-11-16
