
教育信息化2.0背景下的教育资源治理:理念与路径
2019-01-16 09:13冯翔
中国远程教育 2019年12期

【摘 要】
构建教育大资源服务是我国教育信息化2.0中的一项重要任务。这项任务面临着方方面面的难题,其中核心的问题是教育资源的大规模共享和优质服务。解决这些难题需要以新的思维重新审视和设计教育资源的创作、描述、存储、发布、传播、应用和增值等环节。为了叙述方便,本文将这些环节用“教育资源治理”一词来概括。本文分析传统教育资源治理技术和模式的演化,指出在教育信息化2.0时代教育资源共享和服务所面临的问题,进而提出在教育信息化2.0背景下教育资源治理的新思路和新理念。基于此思路和理念,设计以Web为开放平台,整合Web浏览器插件、人工智能、网构软件思想、基于区块链的去中心化身份认证等核心技术的新型教育资源治理模式。文章最后给出了三个独立的原型实践,验证了相关技术思路,为未来整合形成完备的新型教育资源治理生态提供了基础。
【关键词】 教育资源治理;人工智能教育应用;Web开放平台;浏览器;区块链;网构软件;学习资源
【中圖分类号】 G420 【文献标识码】 A 【文章编号】 1009-458x(2019)12-0012-13
* 基金项目:上海市科委科技攻关重大项目“上海数字化教育装备工程技术研究中心能力提升项目”(项目编号:17DZ2281800);中央高校基本科研业务费华东师范大学青年预研究项目“课堂环境中基于面部表情识别的师生情感模式及应用研究”(项目编号:2017ECNU-YYJ039)。
一、引言
教育大资源服务在教育信息化2.0时代具有重要地位。教育部《教育信息化2.0行动计划》明确指出:“实施教育大资源共享计划……探索资源共享新机制,提升数字教育资源服务供给能力……,推进开放资源汇聚共享,打破教育资源开发利用的传统壁垒,利用大数据技术采集、汇聚互联网上丰富的教学、科研、文化资源,为各级各类学校和全体学习者提供海量、适切的教育资源服务,实现从‘专用资源服务向‘大资源服务的转变。”(教育部, 2018)
2.0时代的教育大资源服务将具有鲜明的时代特征。这些特征包括更以“体验”为依归,更以“数据”为基础,更以“连接”为要义,更以“开放”为策略,更以“智能”为目标(任友群, 2017)。这五大特征在教育资源服务中体现在:增强教育资源的使用体验;记录教育资源的使用数据以支持学习分析;实现资源之间的相互连接,实现资源使用者之间的相互连接;资源的开放共享;以智能技术增强的资源服务。事实上,这些特征背后的核心在于实现大规模共享和优质服务。
大规模共享是为了提升资源覆盖和应用广度,从而提升资源的利用率;优质服务是为了提升资源应用的体验和效度,以实现个性化的教学。无论是共享还是服务都与教育资源的创作、描述、存储、发布、传播、应用和增值等环节密不可分。本文采用教育资源治理这一术语来表述上述各环节。
教育资源和学习资源是教育技术领域文献中的常见词汇。到目前为止,关于这两个词汇并没有广泛而统一的定义。教育资源是广义的,可针对涉及教学过程的多种利益相关者,学习资源针对的是学习者。但是它们所指的内容实际上具有很大的共同点,而教育信息化2.0时代的教育大资源服务当然是针对教育情景中的多种相关者。因此,本文将学习资源和教育资源同等对待。回顾历史可以发现,教育资源治理在不同的时代具有不同的理念和相应的实现技术。在教育信息化2.0的大背景下,为了实现能具备上述五大特征的教育大资源服务,相关者需要考虑以何种思维重新审视和设计教育资源治理的各个环节,需要考虑采用何种技术路线开展实践。在此背景下,本文对教育资源治理各环节的历史和发展进行分析,指出当前面临的问题和挑战,提出教育资源治理的新理念和关键思路,最后设计基于Web平台的教育资源治理模式并介绍原型实现,以期为新时代大资源建设提供思路。
二、教育资源治理的发展概况
(一)教育资源治理的界定
本文所提的教育资源治理的思想来源于digital curation和governance。digital curation是指为了支持当前和未来对可信赖的数字信息的持续使用,而对其实施维护、增值的行为过程(Beagrie, 2006)。祝智庭等(2014)将digital curation翻译为数字治理。在智慧学习中,数字治理具有重要的意义,教育资源是一种可信赖的数字信息,为了在当前和未来更好地使用,相关利益者必须对其实施维护和增值。
governance也被翻译为治理。governance是指所有治理过程,无论是由政府、市场还是网络进行的,无论是通过家庭、部落、正式或非正式组织或者领土,还是通过法律、规范、权力或语言进行的(Bevir, 2012, p. 19)。格里·斯托克(Stoker, 1998)引用詹·库伊曼等人(Kooiman & van Vliet, 1993, p. 64)的观点:“治理所要创造的结构或秩序不能由外部强加,其发挥作用是要依靠多种利益和责任主体的参与以及互相发生影响的互动”,强调治理的本质是它专注于治理机制而不强调依赖于政府的权力和控制。
基于上述内容,本文如下定义教育资源治理:教育资源治理是以教育资源为对象,强调以技术为支撑构建自动化、自治化基础架构,广泛吸纳多方责任主体,包括政府机构、社会机构、公司、个人等,参与教育资源的创作、描述、存储、发布、传播、应用和增值过程,从而促进教育资源的大规模共享和优质服务。在本文中,我们认为技术体系将在教育资源治理机制中发挥重要作用。
(二)相关发展概况
1. OER
在20世纪90年代,随着以因特网和Web为代表的信息技术的快速发展,创作并在Web上发布内容变得越来越方便。许多大学在此背景下开发了各种各样的系统来实现知识的有效传播。其中,MIT的OpenCourseWare取得了成功。OpenCourseWare本质上是一个教育资源的发布系统,它后来被当作一种开放分享的典范模式于2002年被提交到UNISCO的会议上,该会议提出了Open Educational Resource这一词汇(D??Antoni, 2009)。Hewlett Foundation基金会是OER领域重要的支持和促进机构,其官方定义OER为:在公众领域被发布或者在某种知识产权授权策略下,允许人们自由再使用的教育、学习或者研究资料(Hewlett Foundation, 2016)。
OER不是一种技术体系,它是一种模式,其思想来源于开源软件模式。OER倡导在多种层面的授权下实现承载知识的教育资源在不同场景下的自由访问和重用。对于OER重用,Hilton提出了5R模式,即retain、reuse、redistribution、revise和remix(Hilton III, Wiley, Stein, & Johnson, 2010)。其中,remix指的是人们可以将两个或者多个教育资源进行合并以生成新的资源。事实上在Hilton所提出的五模式中,redistribution和remix对技术提出了新的要求。这种技术需求并没有特指性,可以采用学习对象技术体系。
2. 学习对象技术体系
我国学者黎加厚(1997)提出了积件的概念。积件是一种可组合的教育资源基本单元。积件平台是由教师和学生根据教学需要,自己组合运用的教学信息和教学处理策略库与工作平台。只是积件的概念没有最终发展成体系化、标准化、规模化的技术体系。几乎在相同的时期,学习对象技术发展起来,并最终形成了一套相对完备的有关教育资源描述、重用和组织的技术体系。与OER一样,学习对象相关技术的思想也来自于软件技术领域,它是受到了面向对象编程的启发。
学习对象(learning objective,LO)被定义为任何(不论是数字化的,还是非数字化的)可以用来支持学习、教育和培训的实体(entity),该标准定义一套描述规范来支持针对学习对象的搜索、评价、获取以及使用(IEEE, 2002)。高级分布式学习(advanced distribution learning,ADL)的共享内容对象参考模型(shareable content object reference model,SCORM)中的学习对象模型提供了学习管理系统之间交互的数据标准,用来支持学习对象在学习管理系统之间的共享(Bohl, Scheuhase, Sengler, et al., 2002)。教學和经济效用上的考虑是设计各种学习对象模型的重用和系统间互通等特性的主要动机,学习对象虽然有大量描述资源的标准元素,但却缺少有关资源之间相关性的语义描述(Ullrich, 2005)。因此,学习对象在提升教育资源本身的能力方面依然有限,导致面对海量教育资源时教学或者学习者必须人工搜索和聚合所需的学习对象,难以适应个性化和多样化的学习以及泛在学习,资源不可演化。因此,余胜泉等(2009)结合普适计算技术的发展以及泛在学习的实际需求,提出了学习元理念和架构。学习元是对现有的学习对象、学习设计模型的继承与发展,具有生成性、开放性、联通性、可进化发展、智能性、内聚性、自跟踪、微型化等基本特征,可以实现学习者群体智慧的共享和学习工具的共享。
3. 智能化教育资源服务方面的探索
OER提供了一种共享范式,但不关心底层技术;LO技术体系为资源的描述、复用和组装提供了技术基础,但是却无法支持优质的资源服务。为此,一些研究者开始在应用层面开发新的技术来实现教育资源的优质服务。
自适应技术受到广泛关注。翟雪松等(2017a)的研究表明,基于学习者的生理数据可设计算法来探究学习者的认知模式和能力,从而基于此设计各类满足学习需求的自适应技术。教育资源和学习路径自适应推送是面对海量教育资源的情况下优化学习和提高绩效的重要手段,其中的关键是由机器而不是人来根据学习情境自动挑选和组织。由于学习对象本身的限制,研究者将重点放到了学习对象所在的学习支持系统和学习对象库上(Black, Dawson, & Priem, 2008; Sabourin, Kosturko, & McQuiggan, 2015; Ullrich, 2005)。然而,由于学习支持系统的多样性,这样的智能化成果不能实现普适性。
本体和语义描述是计算机推理的重要基础,是一种推荐技术基础。在教育资源中采用语义技术有助于计算机自动进行资源关系之间的推理和发现(姜强, 等, 2010; 吴鹏飞, 等, 2015; 杨现民, 2014; 张吉先, 等, 2015)。这类研究的一个主要特点是针对学科知识建立语义本体,赋予每个资源语义描述,使用语义推理技术和相似度分析技术为用户推荐资源和资源组合。可见,本体和语义技术的应用增强了资源自身的能力。
标准规范方面也在适应智能服务的需求而寻求演进,如Common Cartridge使得更多的资源开发商和平台开发商能更方便地应用标准实现适应性的内容导航(Gonzalez-Barbone & Anido-Rifon, 2010)。
张吉先等(2015)提出了一种大数据环境下基于学习对象元数据(LOM)的资源封装模型,在资源库平台中建立一套既符合教育资源著录标准又具有可扩展性的元数据模型定义模式。基于大数据理念的网络教育资源组织策略(马秀麟, 等, 2015),通过构建以知识点为核心的知识元,把教育资源有机地组织起来,从而帮助学习者更加智能化、个性化地学习。
要实现智能化的服务,数据和基于数据的分析是关键。为此,ADL在SCORM之后推出了xAPI技术,用以实现泛在条件下学习行为的数据获取。这种模式能够使得学习经历数据的采集和存储与学习环境实现分离,有利于实现教育大数据的采集和分析(顾小清, 等, 2014)。xAPI的出现给出了一个信号:教育资源本身的能力有待加强,并且是可行的方向,故在提升学习服务智能化程度方面,可从提升教育资源本身的能力这样一个视角来进行全新的尝试。
三、教育资源治理面临的挑战以及理念转变
(一)大规模共享
无论是基于标准体系建立起来的发展模式还是OER模式,都在实现大规模的教育资源共享上遇到挑战。信息模型及系列标准为特定学习环境中的资源共享和系统演进提供了强有力的支持。然而,从我国的情况看,在教育资源治理过程中,标准在应用方面出现了业界不愿意见到但又不可回避的“陷阱”:一些新系统开发并没有遵循标准,导致信息孤岛不断产生;标准的应用必然对教育资源形成新的封装,这一封装又导致教育资源必须在特定的学习系统或者学习管理系统中,或者必须在特定的播放器(player)支持下才能被有效地使用。在新的学习形态不断兴起的时代,这大大限制了教育资源的可达性,也自然降低了其效用。同时,OER只是一种模式,其对教育资源共享的推动依赖于此模式的社会价值的体现。就当前的发展而言,OER实现资源共享的方式依赖于特定的系统平台或者存储机构。
(二)优质服务
教育大資源的服务对象是用户,为了实现优质服务必然需要对资源和用户都有更好的理解,需要让机器深入了解学习者、资源以及学习者与资源之间的交互。对于资源来说,元数据极为重要;对于交互来说,情境信息极为重要;对于用户来说,画像不可或缺。
1. 教育资源元数据的自动标注非常紧迫
开放教育资源的巨大前景在于实现高质量教育资源的访问,但是两个尚待解决的问题成为发挥该优势的阻碍,即资源的可发现性和为特定学习者定位合适的资源(许哲, 等, 2014)。这些挑战对于Web上的海量教育资源来说尤其显著,因此设计适合于Web上的教育资源的描述受到重视,学习资源元数据项目(learning resource metadata initiative, LRMI)就是其中一种成果。LRMI项目是由著名的比尔及梅琳达·盖茨基金会和威廉和弗洛拉休利特基金会资助的一个项目。谷歌、微软等搜索引擎公司也对这个计划起到很大的推动作用(Campbell & Barker, 2014)。LRMI的目标是使Web上的高质量教育资源治理环节中的创作、描述、发布、发现和交付等环节更加容易便捷。可以说,LRMI是对资源可发现性的一次大规模的探索,该计划推动的资源元数据的标准体系为搜索引擎提供了数据支持。
LRMI规范主要是对Web页面进行描述的词汇和相关操作,其初衷是提出一种新的面向Web页面内容的教育资源元数据规范,为数字教育资源出版商和发行商提供了一种面向Web搜索引擎的教育资源暴露机制,以方便Web搜索引擎很好地处理教育资源。尽管LRMI计划的努力引起了教育领域关于教育资源元数据标注的重视,却没有办法解决教育资源元数据标注的问题。
因此,Web上广泛存在的教育资源元数据标注的任务非常艰巨。传统的方式主要是基于人工对教育资源元数据进行处理。但是在当前的Web环境下,海量的教育资源不能依靠人工方式来进行元数据标注,基于人工智能的自动标注是未来发展的重要方向。事实上,有研究者(Steinacker, Ghavam, & Steinmetz, 2001)很早就指出未来的内容创作系统将能够自动生成许多元数据值,并提供用户友好的方式来提供信息,而无须直接处理元数据编码。
2. 学习者使用情境难以被构建
情境已经成为促进深度学习、个性化学习、差异化学习不可或缺的要素(许哲, 等, 2014)。冯翔等(2013)指出情境感知技术是入境学习的关键技术。翟雪松(2017b)认为情境性是培养学习者跨学科能力和创新能力的重要因素。
不妨设问:谁,在什么情况下,使用了什么教育资源?又有哪些互联网学习者正在使用这个资源?基本上,如果我们能回答上述问题,就可以说我们了解学习者学习的情境。一旦我们获得了这种情境,再结合教育资源元数据,就能够精准实现教育资源推荐以及学伴推荐。
然而,当前教育资源治理的典型实践模式——基于教育资源服务公共平台,或者基于应用了学习对象技术的学习系统,都无法有效地构建学习者情境。
(三)教育资源治理新理念
经过Web 2.0的发展,Web上可供学习的页面资源已经呈现海量之势,这为大规模共享提供了很好的基础,既包括Web基础设施,也包括Web上的数据基础。从学习者方面看,互联网在线学习蓬勃发展,优质教育资源被大量创作出来。此时,师生的认知习惯和学习风格已出现显著变化,他们对用户体验表现出了更高的要求。根据研究报告(马秀麟, 朱艳涛, 2013),随着互联网上开放式的教育资源和学习社区(如百度百科、百度文库、维基百科等)的快速发展,学生正在放弃传统的学习系统,倾向于直接通过浏览器使用Web上的资源。
学习习惯的改变以及Web上学习资源的就绪情况为人们提供了一种新的治理教育资源的可能。其核心思想是,将教育资源从具体组织机构平台和特定标准体系下的学习平台迁移到Web平台;充分利用 Web标准体系;继承传统的标准体系和规范的优势。
1. 教育资源的形态:从文件走向基于Web的智能体
当前,典型的教育资源服务是以文件服务的形式提供的。这些教育资源大多存在于各级各类教育资源服务中心。这种服务体系以一个Web网站的形式与用户实现交互。用户在网站上主动检索,然后下载文件或者在线查看文件。
从互联网、Web发展的视角审视这种服务模式可以发现,它是低效的和不“智慧”的,主要体现在:①教育资源元数据通常依赖人工标注。标注受制于上传者和其他相关者的意愿、时间和知识能力水平等因素。②主要依赖用户主动检索才能够找到相关资源。在当前的服务体系下,这一检索过程以及对检索结果的筛选是高认知负载的。③教育资源是纯粹的静态文件,其存在意义在于被动检索和查看。根据许哲等(2014)的观点,文件服务应从被动走向主动。这种以静态文件形式存在的资源难以实现主动服务。④教育资源的使用情况完全依赖于其被使用时所在的学习平台。离开了平台,这个资源的使用将无法被跟踪和记录,无法确定学习的情境,因此无法支持后续的智能分析。
本文认为,教育资源服务也可以以智能体的形式存在。其特点在于:①教育资源智能体作为一个独立的单元,基于HTTP协议运行于Web环境中,不依赖于任何特定Web应用。②作为一个智能体,它具有感知能力,能够感知用户的操作并不断调整反馈,从而为用户提供最佳服务。③在人工智能(AI)、Web浏览器、OpenAPI和集体智慧支持下完成元数据的标注工作。
2. 教育资源的能力:从一无所知到情境感知
当前的教育资源服务模式中,教育资源被使用的情况无法被很好地跟踪,特别是那些以文件形式表现的教育资源,在下载之后是完全无法追踪使用情况的,这就给提升教育资源服务造成了障碍。传统的思路是靠教育资源所在的平台来解决这一问题。但是,教育资源平台的多样性给学习者造成了困扰,学习者无法很好地实現流式学习。流式学习是一种新的学习形态(许哲, 等, 2014),它是一种不间断、不关心学习平台的学习体验过程。因此,本文提出赋予教育资源采集数据、感知环境的能力。在现代Web技术支持下,这是可行的。通过引用一组Web API,可以为当前页面赋予新的能力。比如,xAPI中可以通过页面中引用一个JavaScript语言库就能支持页面和学习记录数据库(learning record store,LRS)之间的数据通信,从而支持页面实现基于xAPI的学习经验数据采集。事实上,xAPI提供了一套独立于平台的学习经验数据描述和采集机制,这为赋予教育资源情境感知能力提供了很好的基础。
3. 教育资源的运行基础:从特定平台到Web平台
在基于学习对象等传统技术发展而来的服务模式中,由于教育资源的打包和分布是在特定标准体系或者规范下进行的,因此资源只能在特定的平台下运行。这种特定平台的限制制约了教育资源的大规模共享和服务,不能适应当代的学习形态。这也对教育资源创作提出了高要求,比如需要符合标准要求的创作工具、创作流程和分发流程。教育信息化2.0时代教育资源开放共享,一方面要汲取学习对象技术的优秀技术思想,如元数据;一方面又要能够摆脱对传统标准体系和环境的依赖。要达到这个目标,Web平台是一个非常好的选择。
Web上存在着海量的教育资源,这些教育资源的主要表现形式就是普通的Web网页,Web网页的内容制作标准相对于学习对象标准而言更容易,也具有更多的用户。这种Web上的教育资源的数量相对于严格组织和规范化的学习对象资源而言更加庞大,在Web上的泛化已成常态。有效利用这些资源对于教育大资源格局意义重大。
4. 从中心治理到基于Web平台的分布式自治
传统的学习对象库(learning objective repository)是采取中心化的治理方式。其典型的方式是由一个权威机构建立一个中心库,该库可存储学习对象及其元数据。这个库方便用户进行查询和组合构建新的学习对象,以满足教学用途。这种库存在的天然弊端是:①可形成垄断壁垒;②库的构建成本高,维护成本高,同时存在单点故障问题。
比特币的兴起使区块链走入了人们的视野。区块链技术是利用区块链式数据结构来验证与存储数据、利用分布式节点共识算法来生成和更新数据、利用密码学方式保证数据传输和访问安全、利用由自动化脚本代码组成的智能合约来编程和操作数据的一种全新的分布式基础架构与计算方式。尽管目前关于区块链如何应用于教育资源分布式存储领域还没有形成清晰的认识,但我们依然可以借鉴其分布式治理的思路:万维网(WWW)是天然的教育资源分布式治理平台,可结合用户的使用实现有效的分布式治理。
四、基于Web的教育资源治理
为了实践上述教育资源治理新理念,本文提出基于Web平台的教育资源治理(Web based learning resource curation,WBLRC)。
(一)Web平台的特征
随着Web的发展以及人们对Web深层次含义的不断挖掘,Web作为平台这一认识得到了各界认同。Web作为平台突破了传统的Web作为静态信息仓库这一根深蒂固的思想观念,随之而来的是Web上的资源和应用越来越多,并且这些Web资源和应用还直接继承了传统Web的几个重要特性——开放、动态、难以控制和用户驱动。
开放:体现在任何人都可以到Web平台上来创作;任何应用都可以被创作;任何信息都可以被发布(当然这里不考虑政策与法规因素);任何人都可以在Web上使用应用与信息(少数前端收费类服务除外)。
动态:任何应用可以在任何时刻被改变,任何信息也同样如此;只要符合一定的规则,任何人都可随时参与和撤出;应用和信息之间的超链接可以随时被更改。
难以控制:正是由于其开放、动态的特性,Web上的应用和信息实质上处于一种类似自然演化的状态,没有什么来限制和控制它。
用户驱动:在拥有相应权限的情况下,应用和信息可以被用户而非一定是开发者随意整合,以形成新型应用来满足特定需求。
简单规则下的以不变应万变:Web的三大核心是HTML、HTTP和hyperlink;信息的CRUD原则,即create、read、update和delete,他们由HTTP动词put、post、get、delete实现。
Web的核心在于相对独立的网页、网页到网页间的超链接、由网页和链接构成的信息网的自主“成长”以及基于HTTP的统一的操作接口(CRUD)。因此Web是演化式的,并且这样的特点使得即使出现某些“坏”的网页和链接,由于系统天然的冗余容错特性,用户依然能够使用,而且系统几乎永远都不会崩溃。归纳起来,万维网(WWW)系统结构的特征在于实体与链接的相对独立性与分离性以及面对开放环境的成长性与包容性。
Web平台的上述特征对于设计新型教育资源服务既有利又不利。一方面,Web平台的开放性、演化性、用户驱动性为用户提供了海量的、持续生成的、多样性的、适合学习的资源和服务,这是传统封闭资源服务所不能达到的;其简单规则支撑起来的技术体系和冗余性为资源的创作、描述、发布等治理环节提供了更好的保障。另一方面,由于其开放性和动态性,Web平台上也广泛存在着不适于学习的资源和服务,如何将教育资源和服务同非教育资源和服务分离开是关键的问题,人工智能在此方面将发挥重要作用。
(二)主要思想
1. 在线教育资源本身需要具备支持智能服务的能力
从传统在线教育资源本身的特点来看,教育资源的智能性不够,资源本身不够“聪明”,无法根据具体情境选择性地呈现出来,且资源与资源之间缺乏良好的按需自动组装机制,缺乏个性化、交互性。实现智能化的重担留给了学习环境。可是,为实现智能化服务等目的而开发的学习环境又给资源的利用设定了限制和高墙。将学习环境的“能力”和“权力”“下放”给教育资源能解决这样的两难问题。因此,教育资源必须是独立于学习环境的,并且是功能型的。目前以学习对象为代表的教育资源开发模式并没有赋予教育资源这样的能力。
2. Web上有大量以网页形式存在的教育资源
与学习对象相比,Web页面内容具有更好的共享能力和社会应用基础,应用潜力巨大。然而,这些资源却没有在有效的组织和使用模式下被优化利用。本研究中,教育资源是一种经过增强的基于互联网寻址的Web页面,本文称其为Pageware,即智能型在线教育资源。将Web页面作为本项目研究中的教育资源是因为:互联网和Web技术发展迅速,Web页面承载各种内容的能力已经足以支持大多数常见的数字化教育资源类型。
3. 充分利用浏览器作为教育资源应用平台
Web标准体系取得了巨大的成功,其最大的特点就在于开放性。相比各种学习环境,Web浏览器已广泛装机和普及,充分利用Web浏览器结合上述Pageware能实现不依赖于特定学习环境的智能化在线教育资源服务。
(三)WBLRC架构
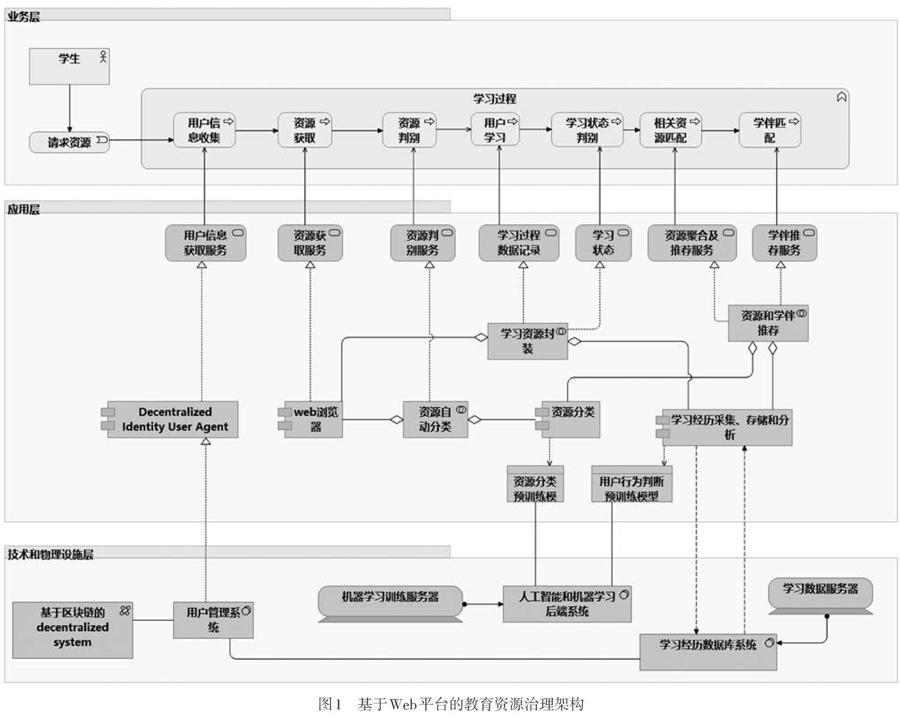
图2是以架构描述语言ArchiMate展示的WBLRC架构,包括业务层、应用层以及技术和物理设施层。在业务层,图1展示了一种常见的学习过程:学生首先请求教育资源,紧接着有一些列的过程和事件发生,比如收集学生信息、获取学生所请求的资源、对教育资源进行判别,然后学生开始学习。在学习过程中,关注学习状态,从而构建上文中的学习情境,据此可以完成相关教育资源匹配推荐以及学伴推荐。这一连串的事件是在应用层的支持下完成的。
应用层首先对业务层中的各事件提供了服务。这些服务是由一些应用组件所实现的,如用户管理、浏览器等。其中,浏览器应用组件和资源分类组件共同协作支持资源判别服务;浏览器应用组件还和学习经历采集、存储和分析组件协作完成教育资源封装以支持学习过程数据记录、学习状态服务;资源分类应用组件又和学习经历采集、存储和分析应用组件协作提供资源和学伴推荐。应用层中,除了浏览器应用组件,其他组件将作为浏览器扩展应用的形式存在。
技术和物理设施层是应用層赖以存在的基础,其中最为关键的是人工智能相关部分、区块链相关部分以及学习经历数据部分。人工智能部分提供机器学习训练用以支持教育资源自动分类和元数据自动标记;基于区块链的去中心化系统(decentralized system)是未来解决去中心化身份验证(decentralized identity,DID)的关键技术。
整个系统是一套整合多种技术的自治系统,该系统由群体智慧、人工智能支持的自动化教育资源元数据标注、基于区块链的去中心化身份验证、教育资源作为Agent自动聚合等技术综合完成基于Web的教育资源治理。该系统不依赖特定的学习机构和特定的学习环境,它只是遵循Web技术标准,依附于Web浏览器。
(四)关键技术
1. Web浏览器扩展:从Web page到Pageware的基础
现代浏览器(如Google的Chrome、Moziila的Firefox)已经演化成了一个面向Web的平台,在其上可以开发各种各样的应用。基于浏览器扩展能够在客户端修改页面内容,也能在客户端运行用户自定义的代码。如Feng等人基于浏览器grease monkey和imacro开发了一个实现自动化教育资源匹配和导览的开放式学习环境,该环境能够录制用户在互联网网上的学习路径,通过发布和重现实现教学目的(Feng, Wu, Wang, Zhou, & Wu, 2016)。在本项目中,浏览器扩展将负责在本地对教育资源进行抽取、净化、重新布局以及多来源资源的组装等。
2. 人工智能:自动化、认知增强的基础
张志祯等(2019)就人工智能使得教学自动化成为必然与可能进行了深入分析。该文指出在直接作用层次,人工智能能够助力教育实现教学自动化。潘云鹤院士(2018)指出,基于人工智能技术,未来智能图书馆将可以根据读者的问题需求,自动提供知识点的链接系列,这个系列是实时按需编排给读者的,从而完成智能图书的编排工作。魏雪峰(2017)使用人工智能模拟学生的认知过程,诊断学生的学习障碍,为揭示学生的认知过程提供了新的思路。可见,人工智能可以应用于学生识别、学生认知诊断、学生情感识别、教育资源学科知识点等分类、教育资源认知水平归类、个性化教育资源推荐、个性化教学设计自动规划、自适应测试、自动批改等服务(冯翔, 等, 2018)。
在WBLRC架构中,人工智能在用户打开一个Web地址后,对这个地址上的Web网页进行识别,判断其是否是合适的教育资源,与此同时还可以推荐其他的关联资源。
3. 网构软件:Pageware聚合的基础
网构软件是国家重点基础研究发展规划(973)项目成果(吕建, 等, 2006)。为了适应开放、动态、难控的网络环境的需求,软件系统开始呈现出一种可演化、连续反应式、多目标适应的新系统形态。从技术的角度看,在面向对象、软件服务构件、智能Agent等技术支持下的软件实体以类似Web应用和网页的自主主体化的软件服务形式存在于Internet的各个节点之上,各个软件实体相互间通过协同机制进行跨网络互连、互通、协作和联盟,而这种协同机制显然是类似但又超越当今的Web服务的,从而形成一种与Web相类似的软件系统,这样一种新的软件系统称之为网构软件(Internetware)。网构软件在Internet上展现为一种与当前的信息Web类似的software Web。以软件构件等技术支持的软件实体将以开放、自主的方式存在于Internet的各个节点之上,任何一个软件实体可在开放的环境下通过某种方式加以发布,并以各种协同方式与其他软件实体进行跨网络的互联、互通、协作和联盟。
基于网构软件思想,本文将Web页面作为一种“软件”,该“软件”可以具备采集数据、自动发起搜索、自行组装等能力,从而完成类似软件一样的功能。这样的功能将比传统的静态文件形式的教育资源更加强大。
4. 区块链及基于区块链的DID
WBLRC天然地要求一个去中心化的用户管理模式。基于区块链的DID是一种新兴的用户去中心化思路,它是用户密码鉴权认证形式的一种替代技术。去中心化身份信息(decentralized identifiers, DIDs)不同于上述账号密码形式的身份信息,DIDs是由用户生成、由用户自己持有、由区块链支持的去中心化系统所管理的全球统一身份信息(Microsoft, 2018)。
当前被广泛使用的身份信息主要由特定提供商提供,包括各种服务和应用提供商直接提供,如谷歌账号、微软账号、微信账号等。业界已经广泛认识到这种基于账号密码方式的中心化的身份认证模式具有很大的安全隐患,最关键的是它还阻碍了应用的创新。随着区块链技术的快速发展,人们意识到区块链天然地具有支持去中心化身份认证的能力。因此,包括IBM、微软等公司都相继推出了自己的DID 系统。
在本文所提出的思想中,教育资源的治理是发生在浏览器上的,不是发生在一个具体的机构当中。因此,一个去中心化的用户管理模式更加有利于新型教育资源治理的发展。
(五)WBLRC远期总体模型
WBLRC涉及较多的环节和组成部分,上文仅仅就其设计背景、主要思想、关键技术等进行阐述。图2显示了WBLRC总体模型,主要分为5个部分。
保障和激励机制。研究如何在治理过程中确保教育机构、教师、家长、学习者等各方相关者的利益,研究如何激励各方积极参与教育资源的生命周期全过程管理。
规范和标准。研究教育资源治理中的技术性和操作性的相关规范及标准,确保治理健康发展。
技术基础设施。研究教育资源治理赖以生存的基础性技术和前瞻性技术及其演进,包括互联网、区块链、公有云和私有云等。
AI驅动的资源应用分析。研究教育资源治理的核心动力:人工智能驱动的教育资源应用分析技术。
应用和管理基础环境。研究用户面基础技术。以什么样的方式同用户交互,提供什么样的教学环境和场景,等等。
五、概念验证原型开发
实现上文所提出的资源治理理念是一个庞大的工程。基于上文思路,本研究已设计和实现了四个独立的验证系统,可以实现以下功能:①通过浏览器插件来增强教育资源,对应图2中的“Web浏览器及学习支持扩展”部分;②教育资源按学科自动分类,对应图2中的“AI对资源的理解和加工”;③对教育资源的聚合进行可行性验证,对应图2中的“基于网构软件的资源赋能和聚合模型”。这几个原型在一定程度上证明本文所提出的教育资源治理理念具有较高的可行性。
(一)浏览器插件增强教育资源
本研究设计了一个基于iMacro宏录制以及grease monkey浏览器插件的基于浏览器的学习系统,具体成果可参见相关论文(Feng, Wu, Wang, Zhou, & Wu, 2016)。系统效果如图3所示。该系统主要验证了通过浏览器插件增强学习活动和教育资源的可行性。在图3中,针对图书馆学习场景(学习发生在一个Web of Science网站页面中),通过浏览器插件,使用自定义程序可以自动从Web上的另一个页面(维基百科)获取相关内容,从而对当前页面的教育资源形成增强和补充,完成一套教育资源的组合。
(二)基于深度学习的教育资源自动分类
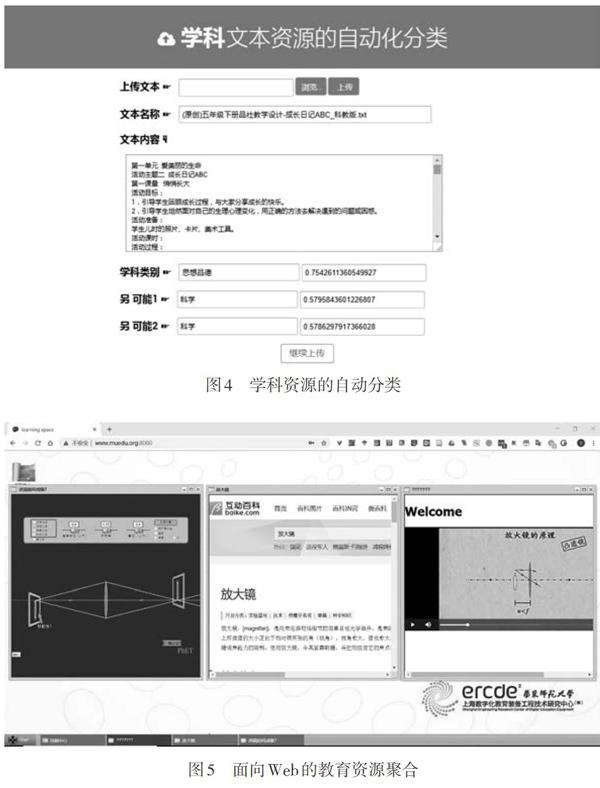
要实现更好的教育资源治理,首要问题是让计算机对教育资源有更好的理解。传统的依靠手工进行元数据标注的方法难以服务于Web上海量的资源。因此,首先需要解决的是教育资源的自动分类问题。基于深度学习的文本分类技术为此任务提供了技术基础。当前,在机器学习领域,基于深度学习技术的文本分类发展迅速(Conneau, Schwenk, Barrault, & Lecun, 2016; Zhang, Zhao, & LeCun, 2015; Lai, Xu, Liu, & Zhao, 2015)。本研究采用深度學习技术实现学科资源的自动分类,验证原型如图4所示,可以实现对上传的文本进行分类。理论上,当完成了一个网页资源的净化之后,获得相应的文本,就可以通过深度学习分类技术实现自动分类。本项研究成果经过进一步深化和扩展之后,可以实现多个分类的自动标注。
(三)基于网构软件思想的教育资源聚合平台
学习对象及相关标准技术的思想核心是对教育资源进行复用和组合。借鉴此思想,本研究设计的另一个原型通过一种intent技术实现来自不同地址的网页教育资源在客户端聚合,这种聚合技术既可以使用浏览器扩展实现,也可以使用Web App实现。在本验证原型中采取了Web App方式实现,如图5所示。
另一个概念验证是基于Web聚合的地理教学资源,如图6和图7所示。在这个验证系统中,用户采用一种实时创作的方式,系统中的资源库被设计为只记录Web上资源的地址(也就是浏览器地址栏上的地址)以及通过人工智能和手工添加的教育资源分类标签。教师可以直接从库中搜索需要的资源,然后通过拖拽方式在一个可视化编辑界面生成一个聚合了这些来自网络上的教育资源的新的教学案例。
六、结论与展望
教育资源治理具有重要的现实意义,它是在教育资源生命全周期内对教育资源进行有效管理,好的教育资源治理模式能够提高教育资源创作、共享和应用的效率。在教育信息化2.0时代,治理教育资源需要有“大资源”观,这要求教育资源治理更加开放、高效,适合新的学习形态,能够支持个性化学习。本文从分析传统的基于教育资源信息模型的标准技术入手,提出教育资源治理的新理念,以此为出发点构建基于Web平台的教育资源治理架构。该架构利用Web平台的天然属性,增强教育资源的开放性、复用聚合性;利用人工智能解决教育资源元数据自动标注问题;基于浏览器插件、人工智能、区块链、学习体验数据采集和分析技术等提供教育资源判别、推荐和学伴推荐服务。文章最后提供了几个独立的验证原型,从面向Pageware的教育资源增强、资源聚合、教育资源分类三个方面展示了本文思想的可行性。
本文认为,该架构的充分实施能够增强教育资源的使用体验,记录教育资源的使用数据以服务于分析,实现资源之间相互连接、资源使用者之间相互连接,实现资源的开放共享,提供以智能技术增强的资源服务。Pageware是以智能技术增强的教育资源,由于基础是Web页面,因此开放性是其本质属性。同时,Pageware也能够和其他Pageware形成聚合(也就是一种相互连接),基于学习情境还能建立资源使用者之间的连接,从用户角度来说,所有这些特性提供了更好的使用体验,即提升了服务质量。
然而,笔者认识到,完全实现文中所提出的理念和架构是一个复杂的工程,还需要诸多努力。未来,笔者将首先对所提出的几个独立验证案例进行集成,再逐步完善其他功能。
[参考文献]
冯翔,王亚飞,吴永和. 2018. 人工智能教育应用的新发展[J]. 现代教育技术(12):5-12.
冯翔,吴永和,祝智庭. 2013. 智慧学习体验设计[J]. 中国电化教育(12):14-19.
顾小清,郑隆威,简菁. 2014. 获取教育大数据:基于xAPI规范对学习经历数据的获取与共享[J]. 现代远程教育研究(5):13-23.
姜强,赵蔚,杜欣,等. 2010. 基于用户模型的个性化本体学习资源推荐研究[J]. 中国电化教育,280(5):106-111.
教育部. 2018-04-18. 教育信息化2.0行动计划[OL]. [2019-04-02]. http://www.moe.gov.cn/srcsite/A16/s3342/201804/t20180425_334188. html
黎加厚. 1997. 从课件到积件:我国学校课堂计算机辅助教学的新发展(中)[J]. 电化教育研究(4):50-53.
吕建,马晓星,陶先平,等. 2006. 网构软件的研究与进展[J]. 中国科学E辑:信息科学,36(10):1037-1080.
马秀麟,岳超群,蒋珊珊. 2015. 大数据时代网络学习资源组织策略的探索[J]. 现代教育技术(7):82-87.
潘云鹤. 2018. 人工智能2.0与教育的发展[J]. 中国远程教育(5):5-8,44.
任友群. 2017. 为教育信息化2.0时代打call[J]. 半月谈(24):62-63.
魏雪峰. 问题解决与认知模拟[M]. 第1版. 北京:中国社会科学出版社,2017.
吳鹏飞,余胜泉. 2015. 学习资源语义关联关系及其可视化研究[J]. 中国电化教育(12):97-104.
许哲,祝智庭. 2014. 面向价值发现的学习资源描述方案:以LRMI元数据为例[J]. 中国电化教育(11):59-68.
杨现民. 2014. 泛在学习资源动态语义聚合研究[J]. 电化教育研究(2):68-73.
余胜泉,杨现民,程罡. 2009. 泛在学习环境中的学习资源设计与共享:“学习元”的理念与结构[J]. 开放教育研究,15(1):47-53.
翟雪松,董艳,胡秋萍,等. 2017a. 基于眼动的刺激回忆法对认知分层的影响研究[J]. 电化教育研究,38(12):51-57.
翟雪松,董艳,詹巧巧. 2017b. 形塑学习(Solid Learning)教学环境下大学生创新能力影响机制研究[J]. 远程教育杂志,35(3):40-47.
张吉先,单永刚,虞江锋,等. 2015. 大数据环境下学习资源元模型的研究与应用[J]. 中国电化教育(9):71-76.
张志祯,张玲玲,李芒. 2019. 人工智能教育应用的应然分析:教学自动化的必然与可能[J]. 中国远程教育,528(1):23-35.
祝智庭,陈丹. 2014. 数字治理:智慧学习新素养[J]. 电化教育研究,35(9):9-17.
Beagrie, N. (2006). Digital Curation for Science, Digital Libraries, and Individuals. International Journal of Digital Curation, 1(1), 3-16.
Bevir, M. (2012). Governance: A very short introduction (1st ed.). Oxford: Oxford University Press.
Black, E.W., Dawson, K., & Priem, J. (2008). Data for free: Using LMS activity logs to measure community in online courses. The Internet and Higher Education, 11(2), 65-70.
Bohl, O., Scheuhase, J., Sengler, R., et al. (2002). The sharable centent object reference model (SCORM)-a critical review//Ed, K. International conference on computers in education. IEEE Comput. Soc, 2002: 950-951.
Campbell, L. M., & Barker, P. (2014). LRMI implementation: Overview, issues and experiences. Overview, Issues and Experiences. Cetis. Retrieved April 01, 2019, from http://publications.cetis.org.uk/wp-content/uploads/2014/12/lrmiImplementationSynthesis.pdf
Conneau, A., Schwenk, H., Barrault, L., & Lecun, Y. (2016). Very deep convolutional networks for text classification. arXiv preprint arXiv:1606.01781. Retrieved April 02, 2019, from https://arxiv.org/abs/1606.01781
D?? Antoni, S. (2009). Open educational resources: Reviewing initiatives and issues. Open Learning: The Journal of Open, Distance and e-Learning, 24(1), 3-10.
Feng, X., Wu, L., Wang, J., Zhou, H., & Wu, Y. Designing an Open and Flexible Tutorial Eco-System for Web Application & Services. In 2016 IEEE 16th International Conference on Advanced Learning Technologies (ICALT) (pp. 3-5).
Gonzalez-Barbone, & V., Anido-Rifon, L. (2010). From SCORM to Common Cartridge: A step forward. Computers & Education, 54(1), 88-102.
Hewlett Foundation, 2016. Open educational resources. Retrieved June 13, 2019, from https://hewlett.org/strategy/open-educational-resources/
Hilton III, J., Wiley, D., Stein, J., et al. (2010). The four ‘Rs of openness and ALMS analysis: Frameworks for open educational resources.Open Learning: The Journal of Open, Distance and e-Learning, 25(1), 37-44.
IEEE. IEEE Standard for Learning Object Metadata: 1484. 12. 1-2002. Piscataway, NJ, USA: IEEE. https://ieeexplore. ieee.org/stamp/stamp. jsp?tp = & amumber=1032843&tag=1
Kooiman, J., & van Vliet, M. (1993). Managing public organizations. In K. Eliassen & J. Kooiman (Eds.), Managing public organisations (2nd ed.). London: Sage.
Microsoft. (2018). Microsoft decentralized identity: Own and control your identity. Retrieved May 03, 2019, from https://query.prod.cms.rt.microsoft.com/cms/api/am/binary/RE2DjfY
Sabourin, J., Kosturko, L., & McQuiggan, S. (2015) Where to next? A comparison of recommendation strategies for navigating a learning object repository. In F. Ricci, K. Bontcheva, O. Conlan, S. Lawless (Eds), User modeling, adaptation and personalization. UMAP 2015. Lecture Notes in Computer Science (pp. 208-215). Cham: Springer
Lai, S., Xu, L., Liu, K., & Zhao, J. (2015). Recurrent convolutional neural networks for text classification. In Twenty-Ninth AAAI Conference on Artificial Intelligence (pp.?2267-2273). Austin Texas, USA: AAAI.
Steinacker, A., Ghavam, A., Steinmetz, R. (2001). Metadata standards for web-based resources. IEEE MultiMedia, 8(1), 70-76.
Stoker, G. (1998). Governance as theory: Five propositions. Internation
al Social Science Journal, 50(155), 17-28.
Ullrich, C. (2005). The learning-resource-type is dead, long live the learning-resource-type. Learning Objects and Learning Designs, 1(1), 7-15.
Zhang, X., Zhao, J., & LeCun, Y. Character-level convolutional networks for text classification. In Advances in Neural Information Processing Systems 28 (NIPS 2015). Retrieved May 03, 2019, from http://papers.nips.cc/paper/5782-character-level-convolutional-networks-for-text- classifica
收稿日期:2019-06-24
定稿日期:2019-07-29
作者簡介:冯翔,博士,副研究员,华东师范大学教育信息技术系,上海数字化教育装备工程技术研究中心(200062)。
猜你喜欢
电子制作(2019年10期)2019-06-17
中国教育信息化·高教职教(2016年11期)2017-01-03
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年31期)2016-12-07
商情(2016年40期)2016-11-28
现代国企研究(2016年10期)2016-11-18
企业导报(2016年19期)2016-11-05
环境与生活(2016年6期)2016-02-27
环球时报(2015-12-21)2015-12-21
