
基于数据挖掘方法的空间大气模型修正
2019-01-14 06:46:32廖川白雪徐明
北京航空航天大学学报 2018年12期
廖川, 白雪, 徐明
(北京航空航天大学宇航学院, 北京 100083)
数据挖掘(又称从数据中发现知识)起源于20世纪80年代后期,在20世纪90年代有了突飞猛进的发展,数据挖掘提供了发现隐藏在大型数据集中的模式的技术,关注可行性、有用性、有效性和可伸缩性问题[1]。大数据指的是以不同形式存在于数据库、网络等媒介上蕴含丰富信息的规模巨大的数据。大数据是一个宽泛的概念,其基本特征可以用4个V(Volume、Variety、Value和Velocity)来总结,随着大数据的发展,也有演变成5个甚至6个V(Volume、Variety、Value、Velocity、Veracity和Variability)的趋势[2]。
近年来,随着各行业从业人员和产品的开发应用,数据挖掘技术得到了长足的发展。例如:金融证券行业利用大数据预测股票价格的波动和走势,分析用户投资习惯;电力行业利用大数据进行电力负载情况的统计,加强分时分流管理;互联网行业利用大数据挖掘上网用户的使用习惯,为用户推荐相应优质内容。而在航天领域,国内外也有相当多的学者进行了深入研究。
Chen等[3]站在数据库研究人员的角度,对数据挖掘技术做出了综合性阐述,调查各类数据挖掘新技术,包括挖掘关联规则的Apriori算法、数据立方体方法、基于决策树(Decision Tree,DT)的数据分类方法等内容。Tanner等[4]提出了星上数据挖掘的概念,将传感器数据进行星上处理,可以提升网络通信能力,并降低成本,可适用于无人自主航天器、火星表面测绘卫星、生物识别系统等。Sánchez-Sánchez等[5]通过大数据和神经网络(Neural Network,NN)学习连续确定非线性系统的状态反馈最优控制问题,利用深度神经网络对最优控制问题生成的轨道进行有监督学习。最终利用得到的神经网络求解Hamilton-Jacobi-Belman方程,借此直接在星上实时生成近优控制行为。Hennes等[6]考虑航天器在主带小行星间的小推力最优转移问题,针对相位值、最大初始质量和最大最终质量,采用计算智能技术(包括分解框架的多目标进化算法、超体积指标和机器学习回归),分别对3个目标函数进行最优设计。
李德仁等[7]分析了空间数据挖掘和知识发现(Spatial Data Mining and Knowledge Discovery,SDMKD)的内涵和外延,利用SDMKD从空间数据库中自动或半自动地挖掘事先未知却潜在有用的空间模式。宫辉力等[8]针对国内缺乏对海量卫星遥感数据的有效数据挖掘和知识发现技术,设计了一种面向地学应用的卫星多源遥感图像数据挖掘系统框架和原型。Peng和Bai[9]针对空间目标编录中通常缺失的面质比信息,利用随机森林(Random Forest,RF)方法学习一致性误差和面质比间的关系,从而确定空间目标的面质比类型。
异常检测与模式挖掘作为数据挖掘的一个重要分支,也逐渐成为研究热点方向。胡小平等[10]分析了液体火箭发动机的工作和故障特点,提出利用数据挖掘方法从数据仓库的角度对液体火箭发动机进行故障检测和诊断的策略。徐宇航和皮德常[11]为了及时发现卫星故障情况并提取异常模式,提出一种基于PrefixSpan算法,对卫星异常数据集进行模式挖掘。肇刚和李言俊[12]研究时间序列数据挖掘技术现状,提出一种基于时间序列数据挖掘的航天器故障诊断方法,包括7个步骤:确定诊断对象、遥测数据选取、数据再处理、时间序列特征表示、数据挖掘方法执行、挖掘结果的解释与评估、软件系统开发。对促进航天器故障诊断技术的发展和完善有重要意义。
某型号卫星是一颗典型的低轨卫星,在其轨道预报和实际运行中,大气阻力是最主要的非保守力。本文基于以上现状,将利用基于决策树的随机森林方法、神经网络、支持向量机(Support Vector Machine,SVM)这3类数据挖掘的方法,学习大气阻力在不同误差情况下导致的轨道预报的偏差,借此对所使用的大气模型进行修正,并评估3种方法的修正性能,以及给出方法间的对比。本文的创新点如下:1)针对有监督学习方法需要先验类标签的问题,利用2种不同精度的轨道预报模型作为仿真环境,产生训练数据和测试数据。2)采用了大数据处理技巧中的3种数据挖掘方法与传统数理统计方法相比,具有快速处理大数据集(本文中数据点达到18万左右,甚至更多)、能够挖掘隐藏在轨道预报微小误差中的潜在信息等优势,验证了数据挖掘方法的应用可行性,为未来在实际运行环境下进一步修正大气模型提供参考。
1 轨道动力学模型
高精度轨道预报需要对空间环境进行精确建模,轨道预报的主要摄动因素包括地球引力、太阳引力、太阳光压和大气阻力。首先,对各摄动因素进行了精确的数学建模;然后,提出2种轨道动力学模型,作为轨道预报和产生训练数据的基础。
1.1 高阶地球引力场
根据参考文献[13]给出的相关内容,地球引力势可以写成
(1)
式中:
(2)
GMe为地球引力常数,G为万有引力常数,Me为地球质量;r为地心固连坐标系中的航天器位置矢量;φ和λ分别为航天器的地心纬度和地心经度;Re为地球的赤道半径;Pnm为n阶m次缔合勒让德多项式;Cnm和Snm分别为相应的重力势系数。
这种形式的引力场模型可以扩展至任意阶次,而不仅仅限制在带谐项,因此可以用以精确描述地球引力场。
(3)
式中:
(4)
式(1)~式(4)得到的是地心固连坐标系中的加速度,为统一各摄动加速度,后文所有其他加速度也将转换到地心固连坐标系下,如式(5)所示:
(5)
式中:U(t)为坐标转换矩阵,用以刻画地球自转,实际计算中还需考虑岁差和章动效应;r为航天器位置矢量,下标e和s分别表示地心固连坐标系和空间固定坐标系。
1.2 非地球引力摄动
太阳引力引起的摄动加速度可在地心惯性坐标系下表示为
(6)
式中:ri和s分别为航天器和太阳的地心坐标;MS为太阳的质量。
由于太阳辐射光压导致的摄动加速度可以表示为
(7)
式中:PS为太阳辐射压;1 AU为一个天文单位,1 AU=1.496×108km;rS为太阳地心矢量;n为航天器表面的单位法线矢量,A为航天器的迎风面积;eS为太阳方向单位矢量;θ为矢量n和矢量eS间的夹角;ε为航天器所用材料的反射率。卫星在运行过程中,由于存在太阳光遮挡的问题,本文在进行轨道预报的过程中,将采用参考文献[14]中的地影预报算法,计算卫星当前是否处于地影区,从而判断当前状态是否存在太阳光压摄动。
对于低轨卫星而言,大气阻力是最主要的非保守力。大气阻力引起的摄动加速度可表示为
(8)
式中:CD为阻力系数;m为航天器质量;ρ为航天器所处位置的大气密度,本文采用MSISE86大气密度模型[15];vr为航天器相对于大气的速度;ev为相对速度的单位矢量,即ev=vr/vr。
1.3 精确模型和误差简化模型
1.1节和1.2节已经给出了航天器轨道动力学模型,该模型可以用于航天器轨道预报。为产生分类器的训练数据和测试数据,本节将给出2种模型,精确模型将作为航天器轨道预报的基准,模拟航天器在轨“真实”情况;不同的误差模型将人为对大气模型施加误差,从工程实践角度出发,CD(A/m)ρ可以被视作一个阻力系数CS,因此本文实际上是对CS进行修正,因此式(8)在误差简化模型中可写成如下形式:
(9)
通过精确模型产生的轨道,与误差简化模型产生的轨道的各项数据差值,即可作为分类器的训练数据和测试数据。2种模型具体的参数设置由表1所示。

表1 精确模型与误差简化模型参数Table 1 Parameters of accurate model and error simplified model
2 数据挖掘方法
数据挖掘能够从大量杂乱的数据中挖掘出有价值的信息,但是其过程是相当复杂的。针对本文的研究内容及数据的特性,本节将介绍3种分类方法,利用这3种分类方法就能够学习第1节得到的训练数据,并通过测试数据对3种分类方法进行准确度检验。
2.1 决策树与随机森林
决策树又称分类树,是应用最为广泛的分类方法之一。如图1所示,决策树是一种监督学习方法,通过不断地划分数据,使依赖变量的差别最大,最终目的是将数据分类到不同的组织或不同的分枝,在依赖变量的基础上建立最强的归类,其训练结果是类似流程图的树结构。
但是决策树是一种“贪心算法”,在应用过程中,每一步的判断,仅是针对当前测试做出最优选择,并不考虑全局结果。如果将多棵树以某种关系结合起来,对数据进行分类,以解决单一决策树泛化能力弱的缺点,这就是随机森林。
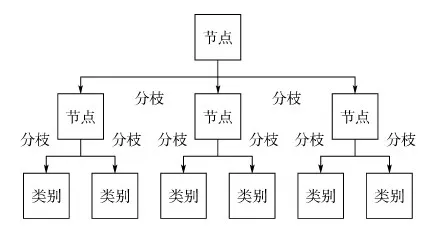
图1 决策树Fig.1 Decision tree
随机森林实际上是套袋法与决策树的结合,如图2所示,随机森林的随机性体现在:
1) 从样本中随机选择n个样本。
2) 从所有属性中随机选择k个属性。
3) 选择最佳分割属性作为节点建立决策树;
4) 以上步骤重复j次,即得到j棵决策树,进而完成随机森林训练。
5) 分类问题中,通过投票决定数据的类别。回归问题中,由j棵决策树预测结果的均值作为最后的预测结果。
随机森林的优点很多,对于多种数据,随机森林可以产生高精度的分类器;建造森林时,随机森林可以在内部对于一般化后的误差产生不偏差的估计;在决定类别时,可以评估变数的重要性等等。当然随机森林的缺点也是显而易见的,因为要训练m棵决策树,其训练过程会是训练单棵决策树的数倍。
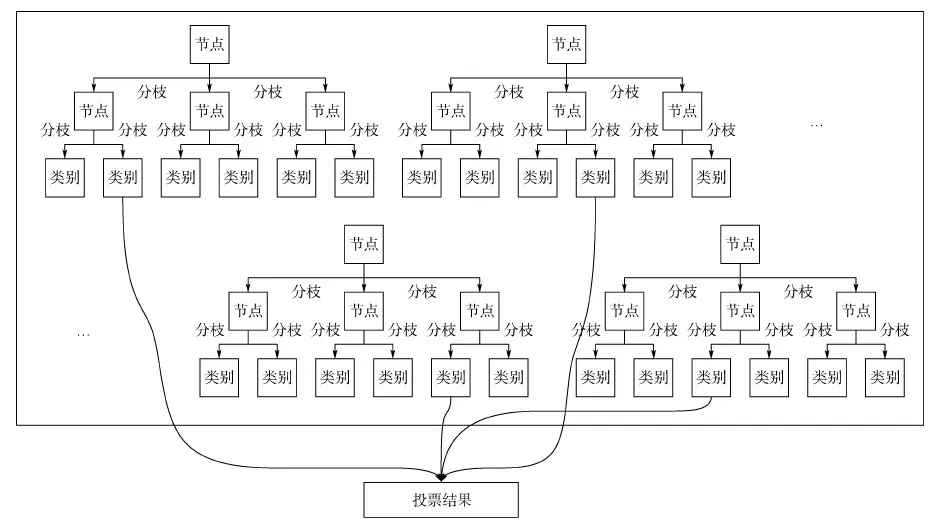
图2 随机森林Fig.2 Random forest
2.2 神经网络
神经网络是应用类似于人脑神经突触连接的结构进行信息处理的数学模型。在早期对人脑的理解中,人脑主要由称为神经元的神经细胞组成,神经元通过轴突的纤维丝连接在一起,当一个神经元受到刺激时,神经脉冲通过轴突从一个神经元传递到另一个神经元。一个神经元通过树突连接到其他神经元的轴突,树突是神经元的延伸物。树突与轴突之间的连接点叫做神经键。人脑通过在同一脉冲反复刺激下改变神经元之间的神经键连接强度来进行学习。类似于人脑的结构,神经网络也是由一组相互连接的节点和有向链构成。
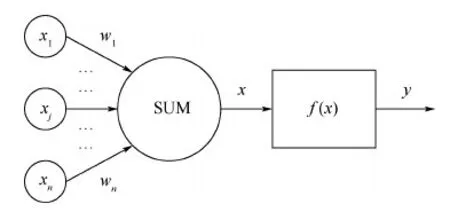
图3 神经网络感知器Fig.3 Neural network perceptron
图3为神经网络最简单的模型——感知器,包含多个输入节点、一个输出节点,节点即是神经元。在感知器中,每个输入节点通过一个加权的链连接到输出节点,该加权链用以模拟神经元之间神经键的连接强度,如人脑一样,训练一个感知器就是不断调整链的权值,直到能拟合出输入输出间的关系为止。
本文将采用前馈负向传播神经网络,前馈是指:每一层的神经元仅与前一层连接,且输出给下一层,各层之间没有反馈,不对网络的参数进行调整。负向传播是指:误差会进行方向传播,用以调整权值和阈值。至少含有一个隐藏层的多层神经网络可以用来拟合任何目标函数,且可以处理冗余特征,但是神经网络对于噪声十分敏感,训练过程也很耗时。
2.3 支持向量机
支持向量机是建立在统计学习理论基础上的机器学习方法。支持向量机通过构建分割多类的超平面,在构建过程中,会试图将多类之间的分割达到最大化(如图4所示)。
支持向量机的理论包括3个要点:最大化间距、对偶理论和核函数。“最大化间距”实际上是一个优化问题,该优化问题,可以利用拉格朗日对偶理论变换到对偶变量的优化问题。然而在输入空间中,数据可能是不可分的,支持向量机就需要通过非线性映射,将数据映射到某个其他点积空间。本文所使用的支持向量机将采用高斯核函数:
(10)
式中:X为空间中任一点;Y为核函数中心;σ为函数的宽度参数。高斯核函数对于噪声有着较好的抗干扰能力,但是其参数决定了函数作用范围,超过了这个范围,数据的作用就“基本消失”。

图4 支持向量机分类方法示意图Fig.4 Schematic diagram of classification method of SVM
3 分类器训练与评估
首先,将利用第1节提出的2种轨道动力学模型进行轨道预报,并生成训练数据;然后,将训练数据导入第2节中介绍的各分类方法,进行适当参数调整后完成训练。
某型号卫星是中国第一代传输型立体测绘卫星,于2010年8月24日发射成功,其轨道高度为500 km左右,运行过程中,大气阻力对其造成较大的轨道衰减。因此本节将以该卫星在轨实际状态作为轨道预报起点,从而生成一系列训练数据。
3.1 训练数据生成
仿真起始时刻为2016年5月31日21:07:05,卫星真实在轨状态如表2所示,其中:a为半长轴;e为偏心率;i为轨道倾角;Ω为升交点赤经;ω为近地点幅角;M为平近点角;rx、ry、rz为卫星在惯性系下的位置三轴分量;vx、vy、vz为卫星在惯性系下的速度三轴分量。
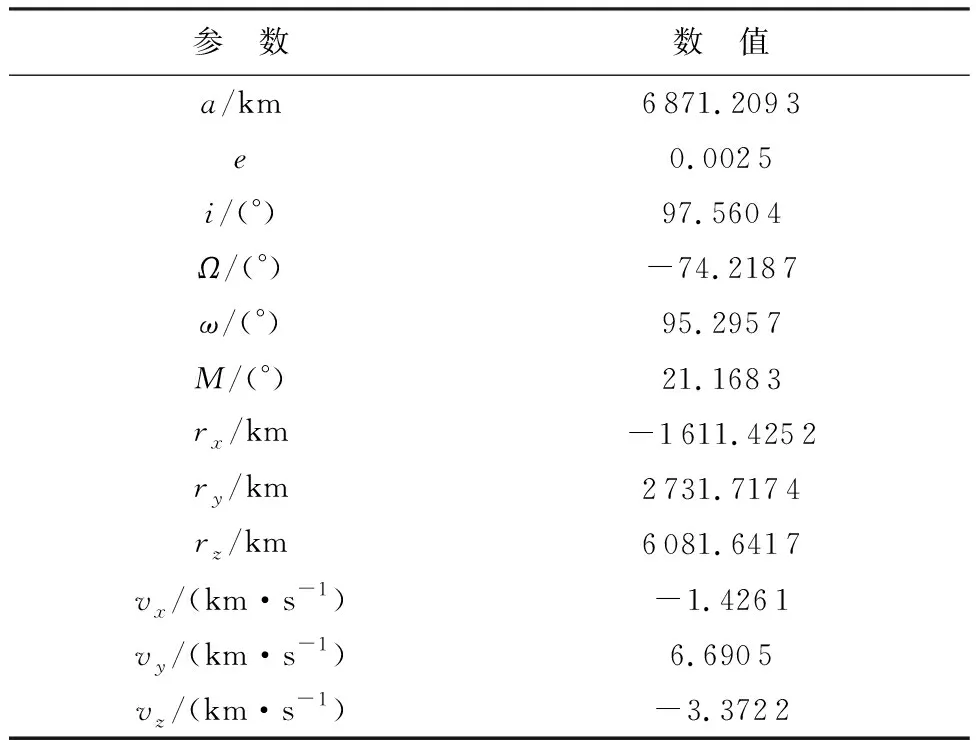
表2 仿真初始状态Table 2 Initial state of simulation
向后进行1 d轨道预报可以得到多条卫星轨道,预报间隔为10 s,每一个点都对应一定时间后由25个变量组成的卫星在轨状态Xi:
(11)
式中:Δt为该点的预报时长;前标Δ表示误差简化模型与精确模型间的差值;下标i表示该组状态的编号。
因此可以得到181 440组卫星的在轨状态,且每一组状态都对应一个人为施加在大气模型上的误差值εi,即可以得到181440个样本数据及其类别属性的组合[Xiεi]作为训练数据,训练数据的如表3所示。
由表3可以看出,不同误差值的模型进行轨道预报,得到的在轨状态数据相差很小,无法用传统方法得到这些值与误差值间的关系,更无法通过这些值准确得到误差值大小,因此本文采用数据挖掘的技巧,对以上数据进行处理、分类,这也是本文的创新点之一。
3.2 分类器训练
将3.1节得到的训练数据导入各分类模型,并适当设置参数,即可完成分类器训练的初始化。各分类模型的训练参数设置如表4~表6所示。
3.3 训练结果与评估
随机森林方法分类结果如图5所示,横坐标为181 440组状态的编号,纵坐标为该组状态对应的大气模型误差值。因为随机森林的训练和预测中采用投票机制决定最终结果,所以图5(b)的结果是通过选择图5(a)的最大概率取值得到的。
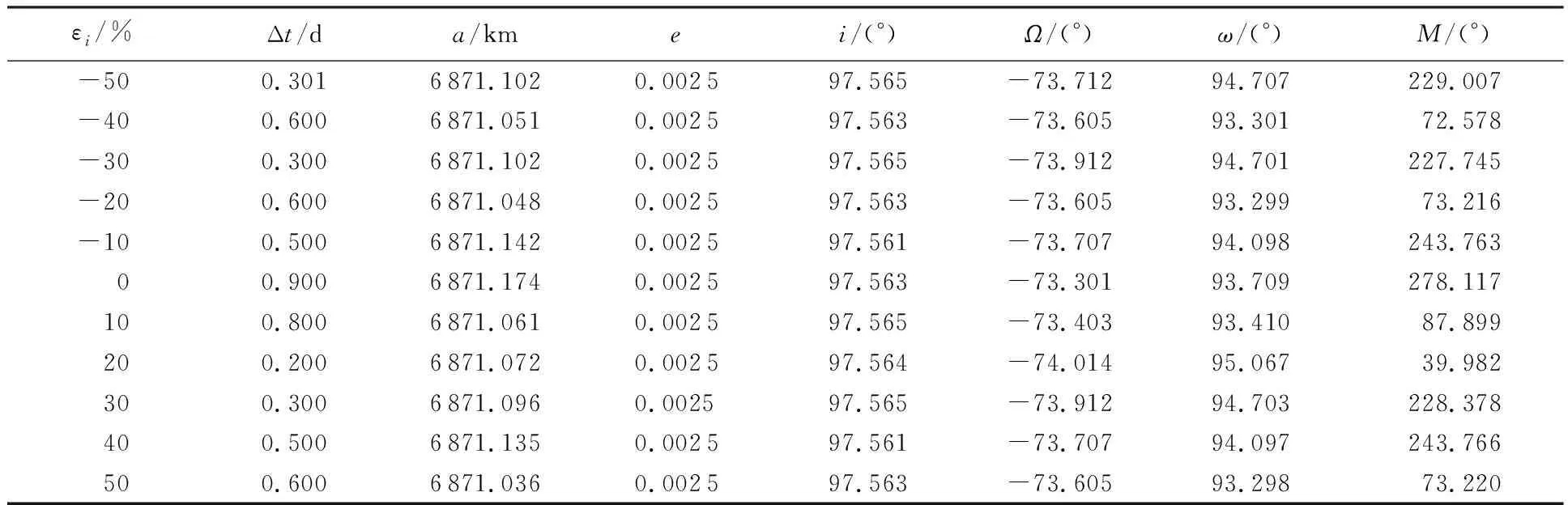
表3 部分训练数据Table 3 Partial training data

表4 随机森林训练参数设置Table 4 Training parameter setting of random forest

表5 神经网络训练参数设置

表6 支持向量机训练参数设置Table 6 Training parameter setting of SVM
可以看到,5(a)中颜色越接近红色,表示概率越大,因为随机性和投票机制,最终的精确度高达99.99%。
神经网络训练结果如图6所示,图6(a)为在5 461次循环中,神经网络通过不断调整神经键上的权值,逐步减小性能函数的取值,于5 451次循环时达到最小值0.014 55,并在第5 461次循环后达到最大验证数据失败的次数,停止循环;图6(b)为在5 461次循环中,性能梯度、动量和验证数据失败次数的变化,性能梯度于5461次循环时达到最小值0.022 783,动量于5 461次循环时达到最小值1×10-7,验证数据失败次数于5 461次循环时达到最大值10次。
图7横坐标为181 440组状态的编号,纵坐标为该组状态对应的大气模型误差值,可以看到训练结果相比随机森林已经有了较大的降幅,精确率仅有0.011 6%。而且通过图8可以看出,在预报时长较小时,因为不同模型得到的在轨状态差值很小,这一段内的结果误差尤其剧烈,甚至超过了100%,随着预报时长的增加,误差将会逐步减小。支持向量机分类结果如图9所示,结果误差较大,其精确度仅为50.7%。对比图7,神经网络分类结果仅在一定范围内波动,而支持向量机的结果可能在全域内离散波动。
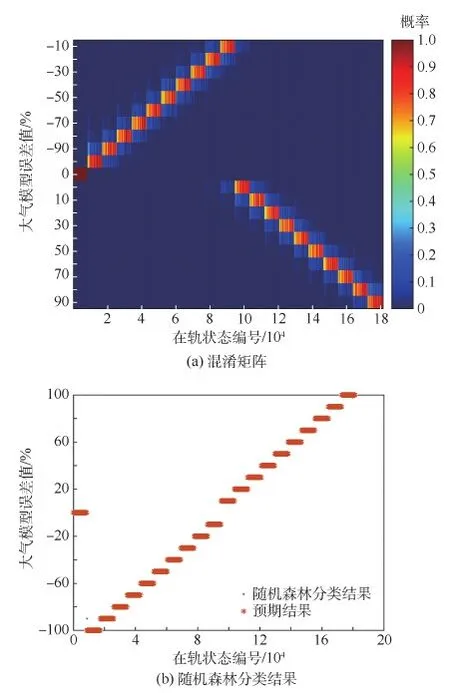
图5 混淆矩阵和随机森林分类结果Fig.5 Classification results of confusion matrix and random forest
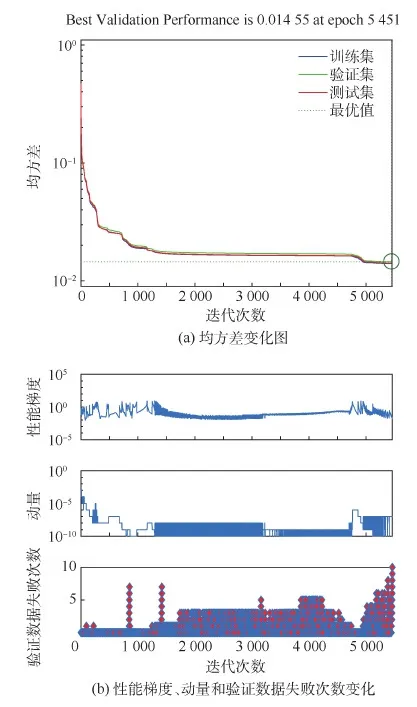
图6 神经网络训练过程Fig.6 Training process of neural network

图7 神经网络分类结果Fig.7 Classification results of neural network
对比3种方法的性能(见表7),随机森林训练时长最短,精确度最高,因此该方法的性能最佳,考虑到森林中包含决策树的数量为50棵,减少决策树的数会进一步缩短训练时长。而神经网络和支持向量机的应用结果都不理想,原因在于本文中使用的在轨状态和大气模型误差值的训练数据,对于这2种方法来说学习较为困难,尤其是神经网络,容易出现过拟合以及不学习,即过早达到最大验证失败次数的情况。
图8 神经网络分类误差变化Fig.8 Classification error variation of neural network
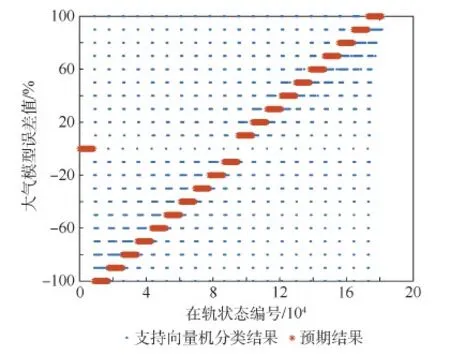
图9 支持向量机分类结果Fig.9 Classification results of SVM
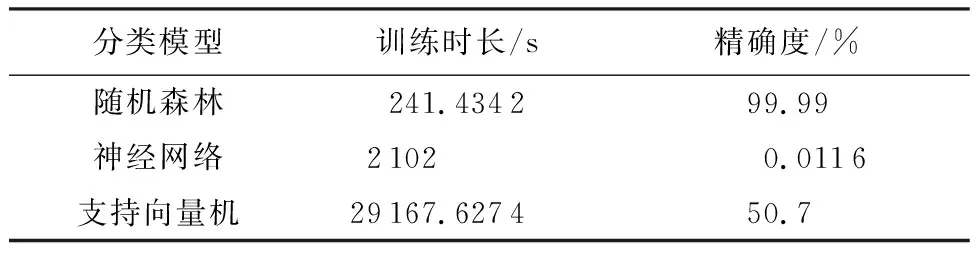
表7 3种分类方法性能对比Table 7 Performance comparison of three classification methods
4 结 论
本文以某型号卫星的轨道预报及数据挖掘方法作为切入点,完成了以下内容的研究分析:
1) 对卫星在轨的空间环境进行数学建模,基于各个摄动力因素,提出了2种轨道动力学模型,精确模型用于模拟卫星在轨真实情况,误差简化模型通过人为对大气模型施加-100%~100%的误差,作为生成训练数据的基础。
2) 对本文利用到的支持向量机、神经网络、随机森林3种分类方法进行了概述和总结,阐明了3种方法的原理及特点。
3) 利用2种模型向后进行1 d的轨道预报,预报结果作差,由此产生181 440组训练数据,并导入3种分类模型训练。
4) 从训练结果可以看出,数据挖掘方法能够对大气模型的误差进行较好的反演,尤其是随机森林的方法,反演的结果高达99.99%。
本文的结果为卫星轨道预报以及大气模型的建立提供了新思路,结合时下热门的大数据概念,将数据挖掘方法应用至传统的航天领域,具有良好的参考意义,为航天领域应用人工智能、大数据等技术奠定了基础。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
空间科学学报(2020年6期)2020-07-21 05:37:04
空间科学学报(2020年6期)2020-01-08 16:50:22
环球时报(2019-12-05)2019-12-05 05:13:15
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
电力与能源(2017年6期)2017-05-14 06:19:37
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
信息通信技术(2015年6期)2015-12-26 01:16:46
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
