
面向问题智能处理的基元-因素空间模型研究
2019-01-10 00:56李兴森许立波刘海涛
广东工业大学学报 2019年1期
李兴森,许立波,刘海涛
(1. 广东工业大学 可拓学与创新方法研究所,广东 广州 510006;2. 浙江大学宁波理工学院 计算机与数据工程学院中澳智能计算与数据管理研究中心,浙江 宁波 315100;3. 辽宁工程技术大学 理学院,辽宁 阜新 125105)
互联网搜索引擎已成为人类获取信息的重要途径. 现有搜索引擎的核心技术是采集主题相关的web信息,通过关键词匹配从海量网页中快速、被动地提供信息[1],并以各类算法排序展示给用户. 但现有搜索引擎提供的是堆砌的信息,用户难以从数以百万计的网页中(以“客户流失”为关键词,百度中查出319万条信息)提取有价值的信息进而获取知识,更难以整理和综合知识智能化解决问题. 如前微软亚洲研究院常务副院长马维英所言:“目前的搜索引擎,提供的主要是链接而不是信息,其实并不能真正理解用户的搜索需求,智能搜索是未来的大势所趋.”以智能化为用户提供问题解决方案将是下一代搜索引擎的主要特征. 然而,目前互联网信息的智能化应用还面临如下挑战.
(1) 现有技术难以解决多源数据、信息、知识的智能融合问题. 网页文本、图片、声音、视频等多种类型的异构数据堆砌成动态、粗糙的海量信息(截至2016年底,中国网页数量为2 360亿个),且以11.2%以上的速度逐年加速增长(中国互联网络信息中心第39次《中国互联网络发展状况统计报告》). 现有的局部数据挖掘手段仅能产生碎片化知识,而信息整合面临事物的分类不具唯一性,海量信息和知识在不同领域有不同的概念连接结构及知识图谱,不同的目标需要不同的分类和图谱方式等. 如何自动融合、匹配这些数据与信息并为后续大规模、高效地挖掘应用搭建新型的知识库,是一件极具挑战性的任务.
(2) 现有技术难以解决web信息的知识智能挖掘与策略生成问题. 互联网的信息处于动态增长和不断更新的过程中,如何能够在保证获取知识的质量不变的前提下,增量地实时挖掘不断涌现的新数据是知识智能化挖掘的难题[2]. 此外,现有基于静态数据挖掘的算法仅能从网页中获取多源碎片化知识,难以满足用户使用搜索引擎的真正需求. 例如,查询房源信息背后的真正目标可能是为解决资金不足又必须买高价学区房的矛盾问题,获取互联网上的房源信息只是解决问题的前期准备.
要解决上述2个主要问题,使新一代互联网实现智能化解决问题,其关键是必须研究面向问题处理的互联网信息的智能重构模型,为智能搜索与知识挖掘准备信息条件. 从动态快速变化的海量web信息中,面向特定领域的问题,对多源异构信息进行智能化的过滤、提取、融合、挖掘及重组等,建立web网页信息层上一层的结构化领域信息知识库(类似整合各管理信息系统构建数据仓库、数据集市). 并将这作为问题智能处理的信息输入,为web大数据环境下矛盾问题智能处理等基础性科学问题研究提供结构化信息基础. 面向问题处理的互联网信息的智能重构模型研究极为迫切.
1 因素空间理论与可拓学理论在问题智能化处理方面的作用
1.1 因素空间理论
(1) 因素. 1982年产生了3个直接以认知为描述对象的数学理论:形式概念分析、粗糙集和因素空间[3]. 因素是指确定事物产生的原因的要素. 如降雨量是粮食丰收的一个因素,遗传基因是健康的一个因素. 随机性是由于掌控因素的不充分而导致因果律的破缺,概率是不充分条件下的广义因果律,问题处理要从不确定性和随机性向必然性转化. 同样,模糊性是描述因素的不充分而导致的排中律的破缺,因素的增加会降低认识的模糊性. 互联网的海量信息对特定问题是模糊的,有可能通过因素的系统挖掘逐步聚类而清晰化[4].
(2) 因素空间. 投掷一枚硬币落地后会得到硬币状态的基本空间Ω={正,反},把硬币图案形状、硬币材质均匀度、手投掷的动作、落地的地面条件和其他环境等影响硬币正反面朝向的因素映射到不同的坐标轴上进行综合,将这些轴交叉起来,形成一个以因素为轴的坐标空间,叫做因素空间. 每个因素对应一个状态变化的维度,所有因素张成一个高维空间X(F),F是因素的集合,F的充分性便确定了从X(F) 到Ω的一个映射,使偶然现象得到必然性的结果. 任何事物都可以被相应的因素空间所描述. 因素空间被认为是事物描述的普适性框架[5].
(3) 因素库. 因素空间存储形成的数据库叫做因素库. 因素库具有4个特色:①明确了数据挖掘的目标是用数据样本逼近背景分布. 背景分布决定概念生成、因果归纳和逻辑推理以及知识结构. ②明确了数据维度化大为小的关键. 在很宽泛的条件下,背景分布具有凸性,凸集可以由其顶点决定.R的顶点所构成的集合叫做背景基B,它的数量比R要少得多. 从R到B,是信息压缩的关键. 相比网页信息,因素数据库保持着非大的数据. ③对于非结构化数据,可在关系数据库的右端留下影像资料作备份,按目标需求询问这些资料的参考价值,随时调用. ④背景样本是去掉对象而留下的性状分布,不存在隐私泄露的问题,样本求并可以并行计算.
以上特点显示了因素库处理互联网大数据的明显优势. 因素库以影响结果状态的关键因素为单元,在互联网上收集处理数据,逐步培养出以问题背景关系为核心的知识基. 通过对大数据的因素化处理,始终保持较低的维度,在不侵犯隐私的前提下与同类知识包并行合作,以上下关系与异类包进行连接,形成融合监测、组织、管理、控制的人机认知体这一软硬件系统[6]. 用因素空间研究事物状态的确定性与不确定性的转化,已经在概念生成、知识表示、模糊控制、模糊推理等领域形成理论及应用体系[7].
因素神经网络[8]、决策科学[9-11]、分类[12]等应用成果表明,因素空间作为海量信息低维度描述的数学框架,不但简明清晰地叙述信息与智能科学的一些基本问题,而且算法简单,涉及的N-hard问题在因素空间中都可以化为复杂度不高于O(m2n)的算法(m,n分别表示对象和因素个数). 另外,因素库能处理的数据除了结构化数据以外还有非结构化数据和异构数据. 近年来,因素空间在数据科学领域显示出新的生命力,如为粗糙集提供了样本分析的坐标系统和母体理论等[5].
根据以上分析,因素空间理论不但把非结构化大数据转化为小数据,而且将为信息和智能科学提供统一的数学语言和普适的描述框架. 从web海量信息中抽取解决领域问题的要素子集是策略生成的必要准备. 因素空间理论将为基元-因素空间模型研究提供必要的数学方法.
1.2 可拓学理论与方法回顾
1.2.1 可拓学理论概述
可拓学是一门以矛盾问题为研究对象的原创性横断学科,它用基元等形式化模型研究事物拓展的可能性以及矛盾问题处理的规律与方法,根本目标在于借助计算机等智能化解决矛盾问题[13-16]. 可拓学是哲学、数学和工程学交叉而成的学科,对数学和逻辑做了较大拓展,构建了解决矛盾问题的方法论体系[17],成为连接自然科学和社会科学的桥梁[18]. 可拓学理论和方法已应用到数据挖掘、知识管理、策略生成及多个人工智能领域[19-20]. 罗马尼亚科学院及美国学者将可拓学拓展到多维空间[21-22]并用于机器人控制[23],部分成果获得日内瓦国际发明专利金奖.
1.2.2 可拓学与知识智能化管理
可拓数据挖掘理论与方法立足于挖掘“变换”的知识[24],近年来提出了可拓转化知识的挖掘方法[25],基于基元理论的内容推荐算法[26]等. 李兴森等[27]聚焦数据挖掘与知识管理的交叉融合,提出了智能知识管理理论框架以及知识培育孵化的方法,并与可拓集合结合提出可拓创新模型[28]和大数据环境下的协同创新模型[29].
1.2.3 基元理论与矛盾问题处理
通过基元理论建立可拓模型,利用基元库与可拓推理和可拓变换、传导变换等方法结合,研究创意生成和解决矛盾问题的理论与方法[30-33]. 借助Agent的智能引导,建立了基于可拓学和HowNet的策略生成系统的基本流程和系统框架结构,并在矛盾问题信息的形式化基元模型及主要矛盾识别方法、基元问题的相关度计算、自适应软件形式化方法、解析用户自然语言需求语句并自动建立可拓模型的方法[20]、基于知网的可拓领域信息元库的构建方法[34]等方面取得系列进展.
另外,可拓学在互联网信息处理[35]和可拓距与关联函数[36]为多维信息融合及矛盾问题处理的研究打下了很好的基元建模和因素完备性、有效性科学评价的方法基础.
2 问题智能化处理的现状与趋势
国内外学者针对基于互联网信息的问题智能处理这一方向,主要有如下3类研究方案.
2.1 语义元数据分析与搜索引擎优化
主要研究集中在如下3个方面.
(1) 元数据分析与搜索算法优化. 该领域的研究主要集中在检索效率、检索结果的排序、扩大信息搜集的范围等[37-39]. 对语义元数据的分析是提高web服务和搜索引擎智能性的重要方面. 如利用语义元数据服务弥补信息搜索的质量差距,构建理解问题的语境等[40-41],基于Agent的智能元搜索引擎等相关算法研究对知识的搜索有一定的参考价值,但需要提升推理和信息知识智能衔接等的智能性.
(2) 研究智能性更强的新搜索引擎. 如提高对用户检索提问的理解,研究语义搜索引擎[42]、模糊语义搜索引擎[43-44]和可拓展标记语言(XML)内容驱动的搜索引擎[45]. 很多研究者开发了本体搜索引擎和原型系统,提供本体搜索与排序服务[46],或结合情景和本体知识的搜索[47-49]等,但搜索内容仍然是信息为主,很少涉及深层知识的搜索.
(3) 开发新一代面向特定领域应用的专业化垂直搜索引擎[50]. 如商业搜索引擎[51],基于本体的云服务检索系统[52],搜索云平台上的各类云计算服务基元-因素空间模型.
上述大部分研究聚焦在搜索引擎技术层面,如关键词搜索算法、信息的呈现方式等[53],对用户的特定情景和动机及如何智能化解决问题等缺乏系统全面的研究.
2.2 知识搜索引擎
一些学者已经认识到,互联网知识的智能化应用是一大趋势[54],未来应研究智能性更高的知识搜索引擎,挑战在于如何从粗糙的海量的web网页中自动抽取结构化的知识.
较早着手尝试基于自然语言理解的知识搜索系统是WolframAlpha. 由沃尔夫勒姆研究公司开发的新一代的搜索引擎网站,2013年5月上线,能根据用户的问题进行后台运算后直接给出答案,而不是返回一大堆信息及网页链接. 它从公开的和获得授权的信息资源中,重新组织信息建立一个庞大的新数据库,再利用高级的自然语言算法进行处理后,构造出一个计算知识引擎. 例如,在被问到“婶婶的女儿的儿子”之类的问题时,WolframAlpha能告诉你正确的称谓、亲缘关系度,还绘制一张类似家谱的系列图表. 但其智能性还不够高,目前比较好的应用是一些常识的运算,缺乏行业知识库支撑,难以提供全面的行业知识来解决实际问题.
2.3 互联网架构的升级换代
认识到现有互联网信息爆炸难以高效利用等问题,国内外一些学者提出了信息中心网络(ICN)的新构想,为构建以内容为中心的下一代网络提供方法[55],让现在以IP为核心的架构能在将来演进成以内容为核心的架构. 但架构的升级换代是一件复杂的事情,需要达成共识并完成一系列准备工作. 而在升级换代过程中,现有互联网的信息仍在持续增加中.
认识问题和系统性解决问题需要从子集到全集,逐步实现对问题要素的智能识别和处理即策略生成. 而问题求解和模式识别等都依赖信息加工的特殊形式. 缺乏突破性的新的信息组织结构支撑新一代搜索引擎的研发,在以文本挖掘和智能知识发现为主要技术的策略生成等方面,系统性融合的信息基础架构仍相对缺乏. 近年来,基于互联网解决问题的研究逐渐增加,但西方学者擅长以微观思维研究特定边界条件下数量化问题的优化和求解[56-57],缺乏基于web信息融合的开放性创新策略生成的研究.
互联网信息爆炸的背景下,如何借助大数据处理的最新理论和方法,研究互联网信息在智能化生成解决问题的策略方面的应用基础科学问题,特别是非结构化信息面向问题的重新组织问题. 大数据使web数据的常态从存储变为流动. 新阶段信息革命的核心是网络和智能的结合. 而中国学者创立的因素空间理论和可拓学理论将为面向新一代策略搜索引擎构建的信息重构提供理论和方法基础.
利用可拓学的基元理论,将网络信息和知识进行属性抽取和量值融合,进而构建因素空间,设计面向行业问题处理的策略搜索引擎,其搜索的主要内容是互联网上解决矛盾问题相关的深层知识(在web信息抽取基础上的二次抽取),这将是新一代搜索引擎技术研发的重要方向之一. 动态基元库与因素库融合的智能构建方法,是为未来的知识搜索和策略搜索提供信息基础的关键步骤之一.
3 基元-因素空间模型构建
3.1 模型框架及主要内容
面向特定领域,将互联网信息分为物、事、关系三类,分别抽取属性和量值构建基元库. 基于内部数据库以数据挖掘方法挖掘关键因素,构建因素空间,因素空间和基元库融合生成面向特定问题的因素库,因素库以树结构组织,多个因素库构成因素仓库,成为支撑未来知识搜索引擎和策略搜索引擎构建的理论基础.
模型针对面向问题处理的策略智能化生成的目标,研究多类、动态web信息的因素化重构方法,为新一代知识搜索提供理论基础. 模型的主要模块之间的逻辑关系如图1所示. 各模块的内容说明如下.
(1) 从web信息中提取基元对象、属性和量值的算法. 该模块研究领域本体与基元的互补性及属性词典的生成方法,研究从web提取的关键词中识别对象和属性关联的算法,设计领域信息与知识的基元表达结构与云存储方案;研究属性聚类与量值的区间化集合智能生成算法,提出自动构建行业领域基元的理论方法及动态更新机制,该内容提供策略生成的结构化宏观基础信息.
(2) 面向特定问题的因素挖掘及因素空间构建方法. 研究量值分析获取属性权重的算法、面向特定领域挖掘关键因素的组合算法及因素挖掘效果的评价方法;研究结合管理信息系统构建领域因素空间的理论与算法;研究面向问题处理的因素运算、因素组态的概率分布以及多个因素空间的交叉维护方法,实现因素词典的自动生成及更新等.
(3) 动态基元信息、专家经验知识与因素空间融合的模式与算法. 研究面向特定问题的动态基元信息、专家经验知识与因素空间的融合算法、管理模式和统一表达,设计云存储方案,形成基元-因素耦合结构. 研究基元-因素结构信息的聚类与关联算法,构建因素与目标结果之间的函数方程以及可拓距为主的三元融合完备性评价函数等.
(4) 基元-因素结构在面向问题处理的动态关键知识链生成中的模拟与检验. 建立描述矛盾问题的人机交互基元模型,优化面向矛盾问题处理的基元-因素结构信息的复杂网络. 研究问题的基元表达与策略可信度和相容度评价方法,利用基于基元-因素结构的关键知识链构建挖掘算法,采用因素空间建立简明统一的数学模式并编制快捷的算法. 模拟人机交互的关键知识的识别及智能补充方法,完成信息与知识基元化融合生成解决问题策略的动态网络结构在策略搜索中试用与检验.
基于信息智能采集与云存储技术,将集成结构化数据与非结构化数据利用可拓学基元理论构建统一结构的信息基元,实现异质数据的离散化及增量集成. 信息基元的基本结构以三元组(对象,属性,量值)表示,多个属性形成矩阵结构:
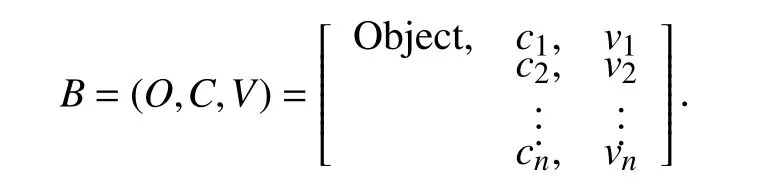
其中,O(Object) 表示某对象(物、动作或关系词),c1,c2,…,cn表示对象O的n个特征,v1,v2,…,vn表示对象O关于上述特征的相应量值.
多个信息基元通过特征或量值相互联系,形成复杂网络. 在复杂信息基元网络基础上,研究问题处理的可拓变换知识的挖掘算法. 例如从客户注册、日常业务使用等数据中挖掘客户流失的规则,然后通过可拓数据挖掘得到引导冻结客户(即将流失客户)向正常客户转化的规则知识. 以互联网基元库信息为基础,针对数据的动态性、多态性和时效性,综合运用数理统计、可拓数据挖掘和智能知识管理技术,研究面向矛盾处理的因素知识挖掘算法.
3.2 实现方案
基于领域问题的因素空间构建因素知识图谱,运用智能知识二阶挖掘方法,得到高阶智能知识,发现问题产生的根本原因和求解的方向. 智能知识是引入心理学、复杂系统、机器学习等理论,对数据挖掘获取的知识进行存储、评价、筛选、审计,对有价值的知识进行标记和基元化处理,孵化出自身具有智能的知识元并进行组织重构、自我更新和智能应用等过程的管理,使知识能识别情境,在合适的时间自动提供给需要的人,从而提高数据挖掘获取的知识的智能性和实用性. 以规则表达的智能知识示例如下.
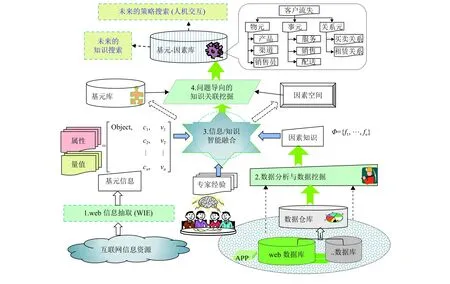
图1 模型的逻辑关系框架图Fig.1 Logic framework of the model

将可搜索因素知识分为企业内部因素、合作商共享知识与互联网外部知识三类,统一用基元建立云知识仓库. 在此基础上,设计基于信息基元的知识爬虫算法和知识搜索算法,以多维关联函数评价矛盾相容度,根据多维分层情境模型结合语义技术研究矛盾情境的关联技术.
知识层采用可拓数据挖掘和智能知识发现方法提取规则和知识,以基元支持多源信息与知识的集成应用. 通过因素知识图谱,形成多源碎片化知识的相互印证、组合和衔接,最终发现面向问题处理的针对性的知识链策略,如图2所示.

图2 基元隐含知识链生成的路径图Fig.2 Implicit knowledge chain generated path from basic elements
设定义在U上的因素集为,即0,1)是一个布尔代数,记X(F))为U上的一个因素空间,如果满足条件:
(1)X(0)={φ};
(2) 对任意T⊆F及s,t∈T,若s∧t=0(s与t叫做不可约),则X(∨{f|f∈T})= Πf∈TX(f)(Π是笛卡尔乘积)其中,F={f1,···,fn}={f1∨···∨fn}=1 叫做全因素,0叫做空因素. 记号∨和∧分别叫做因素的合成和分解运算.
合成与分解运算使得因素相空间的维度随着因素繁简交变,因素空间在数学上被定义成一个以因素为参数的集合族,而参数域可以按这两种运算形成偏序集或格,甚至强化为一个布尔代数.
问题的因果归纳可化为这样的数学问题:将所有因素分为条件与结果两类,要通过背景分布R来提取从条件到结果的因果推理句,并且要在因素约简的前提下来获取这些推理句. 一个认知单元就是对一个给定概念团粒的细化,由一个因素空间来承担.新的子概念又可根据新的要求再生成一个因素空间,形成因素空间藤(简称因素藤). 一个实际系统可以在不同节点上生成多个因素空间,也可被视为另一种形式的因素藤. 因素藤实现信息与知识的融合,形成更大的认知网络.
针对利用互联网大数据处理矛盾问题的应用,基于期望的目标状态及影响因素选定合适的树结构,用目标驱动知识分类和知识图谱的构建,建立以目标为主导的信息和知识的动态联接模式. 对因素库的每个认知包都设立标志符号,标明论域的概念名称和任务目标的相关性. 然后从目标出发逆向搜寻实现目标的充分条件因素,递推到现有条件因素成立时得到一条解决问题的路径.
问题解决程度可用矛盾相容度评价的多维关联函数实现:
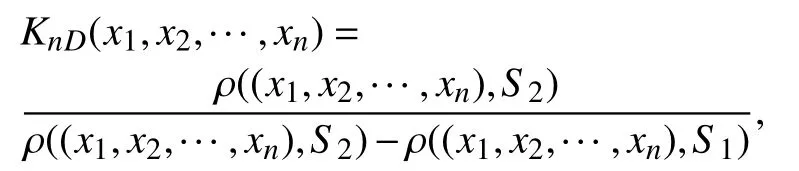
具体含义参考文献[21]. 在此不再详述.
4 结论
从互联网信息深度利用的角度提出一种基于东方系统思维的系统组织模型与策略知识链的模型构建方法,研究互联网海量信息背景下因素空间的智能构建,可以丰富因素空间理论,促进因素空间在信息科学领域的交叉应用. 基元库与因素空间的交叉研究使两大理论实现互补,构建一种新的非结构化数据处理的基础理论.
本模型的深入研究将进一步提升互联网的问题处理资源库作用. 因素库积累到一定程度,将有助于解读深度学习的黑箱要素,有助于实现创新过程科学管理理论的突破. 对提升企业自主创新能力,实现中小型企业的产业转型升级都具有重要的实践意义. 在利用大数据构建国家战略因素库和行业、企业管理因素库等方面也有广阔的应用前景. 从动态快速变化的海量web信息中,面向特定领域的问题,对多源异构信息进行智能化的过滤、提取、融合、挖掘及重组等,建立web网页信息上一层的结构化领域信息知识库(类似整合各管理信息系统构建数据仓库、数据集市),将为web大数据环境下矛盾问题智能处理等基础性科学问题提供新的视角.
深入研究的方向包括以下几个方面,如探讨互联网信息和领域知识的基元-因素化融合的动态结构,提出基元库与因素库互补的耦合方法;建立领域因素空间的基元库模型;开发原型系统,进一步探索互联网海量信息在问题处理方面的深度利用及基础理论与方法等.
(本文部分内容曾在ITQOM2017国际会议上交流)
猜你喜欢
计算机工程与应用(2023年1期)2023-01-13
兵工学报(2021年4期)2021-06-19
大科技·百科新说(2021年1期)2021-03-29
动漫界·幼教365(中班)(2020年8期)2020-06-29
科学导报(2018年30期)2018-05-14
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
科学导报·学术论坛(2013年5期)2013-06-26
中国土地科学(2011年7期)2011-03-20
微型计算机·Geek(2009年1期)2009-12-15
