
数据挖掘技术综述浅析
2019-01-08 08:37马琳董智鹤夏嵩贾孺
数字技术与应用 2019年10期
马琳 董智鹤 夏嵩 贾孺
摘要:数据挖掘,是利用机器对样本数据进行分析和发掘形成知识的过程。本文结合作者的实践,浅述了数据挖掘技术在各领域的应用情况,详细阐述了几种主要的数据挖掘技术,并对此进行了分类比较,给今后广大研究者提供一定的借鉴意义。
关键词:数据挖掘;应用;网络
中图分类号:TP311.13 文献标识码:A 文章编号:1007-9416(2019)10-0230-02
0 引言
数据挖掘(Data Mining),又被称为知识发现、资料探勘、数据采矿等,是利用机器对样本数据进行分析和发掘形成知识的过程[1]。该技术是自动从大量的数据样本中寻找数据间隐藏的特殊关系。数据挖掘技术是统计学、人工智能技术和数据库技术等理论的结晶,为寻找数据间的隐藏关系提供了很好的技术支持[2]。自上世纪80年代末,数据挖掘的技术思想在底特律召开的第十一届国际人工智能会议第一次展开专题讨论,当时会议的主题是数据库的知识发现。随后每年举办一次关于知识发现的专题讨论,直至1995年在蒙特利尔召开了第一届数据挖掘国际会议[3]。在此之后,每年召开的有关于数据挖掘的国际会议越来越多,期刊的数量也在不断增加。
1 数据挖掘的应用现状
数据挖掘广泛应用于市场销售、金融、互联网、医疗、交通等各个领域。
在市场销售领域,可以完成消费群体分析、市场定位、销售情况趋势预测、仓库进出库分析、优化市场策略、判别用户购买行为、优化促销活动等。诸多分析人员也在此领域做出了研究。王旺[4]利用SAS软件,对便利店购买交易数据进行关联性分析,提出在商品布局、促销推广等方面的优化应用;黄玉佳将生命周期理论与Bass模型相结合,进行消费者购买模式偏好计算,为企业创造利润的方向提供了借鉴;耿晓中设计了超市管理系统,并基于该系统实现FP-growth算法,找出了消费者购买行为模式。
在金融领域,通过对金融交易活动的监督,发现交易规则,或通过对客户收入水平、偿还收入比、受教育程度等主导因素分析,可以完成对客户信用等级评价,以预测客户贷款还款能力,降低银行放贷风险。许江峰对P2P网络金融平台数据进行关联分析和logistic回归,在解决国内P2P网络金融平台面临的借贷双方信息不对等、借款业务操作无参考等问题方面进行了探索研究。
在互联网领域,通过对网页Links信息的挖掘,以实现对网络信息的分类、聚类、浏览和检索,通过对用户的检索记录分析,有效的进行提问扩展,提高引擎的检索效率。曾珂对新浪微博用户数据进行聚类分析,研究了微博用户兴趣、偏好、习惯,对于日后微博功能开发、产品研发等具有一定的应用价值。
2 数据挖掘分类
数据挖掘的方法和所涉及到的学科领域、分类分支有很多,其中,按照数据挖掘的任务划分,常用于数据预警预测的主要有分类、聚类、关联规则、时间序列等。
分类挖掘算法的核心是制定某种规则模型,机器按照规则模型将大量的有效样本数据进行区分;在分类过程中,可以将样本数据分成两类或多类。进行分类挖掘运算,需要建立一个可以描述数据类集或者概念集的一个模型。这个建立的模型是依据属性描述的数据元组属性构成的,每个元组作为数据训练集中的训练样本,根据类的不同划分不同标号,标号确定样本的属性,这些数据元组形成训练数据集合。常用分类规则、数学公式或者判定的树形结构来确定学习模型;然后使用该模型分类,通过评估判断预测模型的准确性,如果预测模型准确程度可以接受,就用该模型对未知的数据队形完成分类;如果准确度不能达到要求,就需要重新做第一步的工作,重新构建分类预测模型。
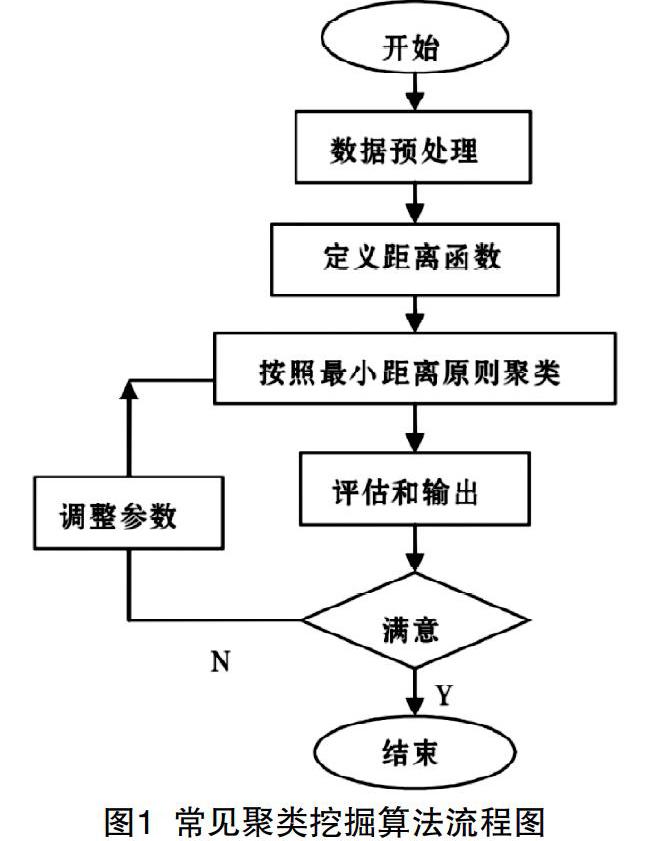
聚类挖掘算法是数据挖掘技术中另一个非常重要的技术手段和方法,它是将样本数据按照特定的属性聚集在一起,根据样本与模型的相似度进行匹配,也就是把一个体按照相似性划分成若干个类别,以实现对数据样本的聚集归类,可以理解為人们常说的“物以类聚”。在经过归类后,得到一组一组数据对象的集合。这些集合内的元素彼此之间有较强的相似性,集合之间的元素之间有较大的差异性。在应用过程中常把一个集合中的全部元素作为一个整体看待。常见的聚类挖掘算法流程如图1所示。
关联规则挖掘算法是用来寻找数据样本中潜在的对用户有用的联系。在大量的数据样本中,找到所有的高频项,再在这些项中找到相互联系的规则,即A事件的发生将触发与之关联的B事件发生,挖掘策略主要是寻找最小支持度阈值的频繁项和频繁项中的高置信度。关联规则首次提出是为了解决商家关于库存量、进货量的安排等问题。Agrawal等提出的Apriori算法,通过挖掘顾客交易数据中商品关联关系,得到了客户购物的一般购物模式结果。
时间序列挖掘算法是一种应用广泛的分析方法,已在股指预测、生产过程监测、电气系统监测、销售额预测等领域发挥了重要作用。它是对在不同时间下取得的样本数据进行挖掘,用于分析样本数据之间的变化趋势,这些数据是要按照一定的时间间隔排列的。从数据的时间特性入手,获取数据知识,其主要手段是要对时间特性进行分析,找寻事物演变的过程。换言之,即为从众多时间序列样本中挖掘隐藏的、与时间关系联系紧密的规则,并对时间数据的发展趋势进行预测。时间序列挖掘主要用于对数据进行可视化描述;分析给定时间序列的产生原理,寻找两个或两个以上变量间的关系;根据现有数据通过模型进行拟合,预测未来时间的数据;通过改变时间序列模型的输入变量,得到符合目标的输出变量,这可以帮助决策者及时调整变量,进行有效控制。
聚类和关联规则本质上属于描述型模型,主要是需要通过对数据之间隐含的模式或者关系进行挖掘识别,从而发现所需要的知识。这类方法要求的数据类型较多,获取程度上也较复杂。分类和时间序列分析属于预测型模型,是以时间为关键属性开展的,分析历史或当前的数据,从而推导出未来的趋势。这类模型对数据的时间连续性要求较强,同时由于使用的数据类型相对单一,在数据的获取上较容易实现。
3 结语
通过对数据挖掘相关知识的总结梳理和分类,对数据挖掘应用的领域有了深刻的认识,为今后相关的研究奠定了一定的理论基础,给同仁在此方面的研究提供借鉴参考价值。
参考文献
[1] 刘健.基于数据挖掘的软件系统优化与重构的研究[D].河北工业大学,2013.
[2] 武书彦,李咚.数据挖掘的探索性研究[J].制造业自动化,2011,33(2):98-100.
[3] 张莹.基于SVR的案例挖掘的应用研究[D].合肥工业大学,2011.
[4] 王旺.数据挖掘在零售行业的应用[D].云南大学,2016.
猜你喜欢
电力与能源(2017年6期)2017-05-14
科学与财富(2016年28期)2016-10-14
科学与财富(2016年28期)2016-10-14
考试周刊(2016年79期)2016-10-13
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
