
互斥约束工作流可满足性决策的匹配剪枝模式回溯法
2019-01-08 11:35:56翟治年卢亚辉王中鹏吴茗蔚
中国机械工程 2018年24期
翟治年 卢亚辉 万 健,3 王中鹏 吴茗蔚
1.浙江科技学院信息与电子工程学院,杭州,310023 2.深圳大学计算机与软件学院,深圳,518060 3.复杂系统建模与仿真教育部重点实验室,杭州,310018
0 引言
云制造是一种面向服务的网络化制造新模式,它将分布式制造资源通过云平台集约化运营,使客户可根据需求灵活租用资源,快速组织定制化的生产。在这种模式下,资源的多源性和虚拟性给客户的业务过程带来了更严重的安全隐患。
云制造业务依赖于平台的服务注册、匹配、组合、执行等支撑功能[1]。通常,制造需求可分解为若干有序的步骤,形成一个工作流。对它进行授权规划,根据每个步骤的制造功能要求,在注册服务中进行搜索,为其匹配若干候选的服务资源。由于同一步骤的候选服务功能相同,因此须根据客户的非功能需求进行服务组合,即定义服务质量优化目标和约束条件,求解相应的资源分配问题,为每个步骤指定唯一的执行服务。服务组合是满足客户需求的关键。不过,有关研究多强调一定业务指标或系统特性的优化,例如完工时间、资源利用率、可靠性等[2-4],而忽略了业务的安全性要求。特别地,服务提供者在完成步骤时可获取相关业务数据,有非法使用的可能。然而服务由大量第三方以虚拟资源形式提供,客户很难对提供者进行有效鉴别。为了降低有关安全隐患,客户往往需要在特定步骤之间施加某种职责分离约束,例如禁止关键零件的加工步骤使用同一执行服务,以免产品设计被组合破解。附加安全约束的业务过程不一定是可行的,这就产生了所谓工作流可满足性决策(workflow satisfiability decision,*WS)问题。
*WS寻求同时满足给定约束和授权规划的任意一个资源分配,可验证授权规划的可行性,为业务的安全执行提供必要的保证。互斥是一种应用广泛的二元职责分离约束,相应的*WS问题记为*WS(≠),有非常重要的意义。该问题是NP完全的[5],对于该问题,确定性算法对中小规模实例有不错的效果,并可以保证完备性(问题无解时能够正确识别),本文将进一步研究其性能优化问题,以推动相关求解技术的进步。
*WS问题的资源分配解为每个步骤分配一个资源,也为每个资源指定一个步骤子集(可为空,但要求这些步骤子集恰为所有步骤的一个划分)。基于前者,可以建立明确的解空间(以步骤为变量,资源为值的变量分解树),通过搜索特别是回溯法搜索求任意一个可行解。基于后者,在很多约束条件下,为任一资源合法指定任一步骤子集,可递推转化为剩余资源与剩余步骤之间的*WS问题,且不同的递推路径可能产生重复子问题,从而导致动态规划的求解方法。这两条求解路线上,各有一些新的进展。在动态规划路线上,CRAMPTON等[6]基于Bjorclund求赋权集最大权划分的方法对一系列*WS问题给出了具有优化指数时间复杂度的算法。对于*WS(≠)问题,其时间复杂度为O*(2|S|(|X|+|U|2))(S、U、X分别为步骤、资源和互斥约束的集合),O*表示法用来度量算法的主要开销,设c为正常数,p(n)是关于n的多项式,则O(cnp(n))可表示为O*(cn),是目前最优的理论结果。但该方法的空间复杂度为指数级,且实际空间占用极大,严重限制了求解规模和性能表现。COHEN等[7]通过识别互斥等一大类约束的资源独立性特征,建立了资源分配的模式编码技术,以此压缩动态规划缓存,得到了一种时间复杂度为O*(3|S|wlgw)的算法,其中w是资源的分散度。2016年,他们将该方法推广到了资源独立性计数约束下的*WS[8]问题。在解空间搜索路线上,KARAPETYAN等[9]利用模式编码技术来压缩解空间,提出了资源独立约束*WS问题的模式回溯算法,其时间复杂度为O*(B|S|),其中B|S|为第|S|个贝尔数,具有目前最好的实际性能。CRAMPTON等[10]将模式回溯法推广到类别独立约束中,给出了层次组织约束*WS问题的求解算法。除文献[6]以外,上述研究均与模式编码技术有关。
事实上,WS问题是约束可满足问题(constraint satisfaction problem,CSP)的特殊情形,而模式编码是一种CSP值对称打破技术。模式回溯法不仅有前述的良好性能表现,而且推动了这一CSP问题技术领域的进步。HENTENRYCK等[11]、RONEY-DOUGAL等[12]和FLENER等[13]先后对具有全局和逐块值对称的CSP问题进行了研究,建立了以群等价树(group equivalence-tree,GE-Tree)为核心的打破对称技术。然而,上述研究对变量值域附加了相应的限制,以联合约束和值域特征,得到问题层面的对称性。早在2006年,COHEN等[14]已经从问题和约束两个层面来区分CSP的对称性概念。2014年,他们又通过WS问题对后一种对称性进行研究[7],定义了资源独立性约束的概念,并为问题的解建立了模式编码表示,证明任意解与其模式在此类约束的验证上是等价的。这一工作实际上是从约束而非问题层面来定义所谓全局值对称性,从而有可能在不限制变量值域的情况下利用这一性质。特别地,它为约束(而非问题)的对称解建立了一种简明的抽象机制,使模式解空间的定义成为可能。2015年,KARAPETYAN等[9]基于模式编码给出了模式解空间的构造方法,建立了资源独立性约束WS问题的模式回溯法。模式解空间可以利用问题约束的资源独立性快速构造,而对变量值域没有限制。模式回溯法通过授权匹配来验证模式解的真实性,连同COHEN等关于解和模式约束验证等价的结论,共同解决了在模式解空间上搜索真实可行解的问题,建立了一种新型的CSP全局值对称打破技术。2016年,CRAMPTON等[10]将资源独立性约束推广为类独立性约束,给出了组织机构约束*WS问题的求解方法,实际上是将模式回溯法推广到了多层嵌套的逐块值对称约束的可满足问题。可见,以WS问题为应用背景的模式编码的相关研究,为CSP值对称打破技术做出了重要贡献。模式回溯法集中体现了有关进展,是一种很有潜力的新型算法。
本文将以*WS(≠)问题为切入点来建立一种优化的模式回溯算法。
1 *WS(≠)问题与模式回溯法
以下S表示工作流步骤集,U表示可用资源集,T表示S的子集。
定义1资源分配函数π:T→U,为T中每个步骤指派唯一的执行资源。当T=S时,称π为完全资源分配;当T=∅时,称π为空资源分配。所有资源分配的集合记为Π。
定义2访问控制策略是一个四元组〈S,U,A,C〉,其中:
(1)授权A={UA(s)|s∈S},这里UA(s)是步骤s的授权列表,而u∈UA(s)是s的候选执行资源。由此定义资源u的授权步骤集SA(u)={s∈S|u∈UA(s)}。对于一个资源分配π:T→U,若任取s∈T,均有π(s)∈UA(s),则称π满足授权。
(2)C是约束的集合。每个约束c=〈T,Θ〉,其中T⊆S是受c约束的步骤集,而Θ⊆Π表示满足该约束的所有资源分配:任取θ∈Θ,其定义域均包含T,且其为T中各步骤分配的资源满足约束c的要求。若T={s,s′},而Θ={θ|θ(s)≠θ(s′)},则称c为互斥约束。
若一个完全资源分配满足C中所有约束和授权A,则称其是该访问控制策略的可行解。
定义3互斥约束工作流可满足决策问题*WS(≠)定义为访问控制策略〈S,U,A,X〉,目标是求任意一个可行解。其中,X是互斥约束的集合。
定义4[7]约束c=〈T,Θ〉具有资源独立性,是指任取θ∈Θ和置换φ:U→U,必有φ∘θ∈Θ。实际上,{θ-1(u)∩T|u∈U}构成了T的一个划分,φ∘θ属于Θ或满足c,这是因为其可以保持每个划分块中的步骤都分配同一资源,且不同划分块分配不同资源。这就是说,c只限制T中各步骤所分配资源的组合方式,而不限制每个步骤具体分配哪个资源。例如互斥约束c=〈{s,s′},Θ〉,Θ={θ|θ(s′)≠θ(s″)},对于φ:U→U,必有φ∘θ(s′)=φ(θ(s′))≠φ(θ(s″))=φ∘θ(s″),故也有φ∘θ∈Θ,满足资源独立性要求,因为c只要求s和s′分配的资源不同,而不限制是怎样两个不同的资源。
定义5[7,9]资源分配π:T→U的模式p定义为二元组〈T,{x1,…,x|S|}〉,它为每个步骤si分配一个编码xi,使得:
(1)
若p是π的模式,也称π符合p。xi≡0的模式称为空模式。模式的编码序列x1,…,x|S|确定了一个S→{0,1,…,min(|S|,|U|)}函数,且在该序列的非0编码中,较小编码的首次出现先于较大编码的首次出现。
直观上,将π中使用的不同资源,从1开始重新编号,就可得到π的模式p。尽管π为各步骤所分配资源之间的关系,在p中变成了相应编码之间的关系,但其组合方式没有任何改变。因此,一个很自然的结论是:π满足一个资源独立性约束,当且仅当p满足这一约束。例如U={ui|1≤i≤7},S={si|1≤i≤6},T={s1,s3,s4,s6,s7},若π:T→U使得π(s1)=u3、π(s3)=u6、π(s4)=u1、π(s6)=u6、π(s7)=u3,则其模式p为〈T,{1,0,2,3,0,2,1}〉。π满足s1和s3之间的互斥约束,当且仅当p满足这一约束。事实上,对于任意的资源独立性约束集C,在资源分配集Π上存在等价关系“≈”,使得任取π∈Π,[π]≈中所有资源分配有相同的模式,且π满足C当且仅当π的模式满足C[7]。
为求访问控制策略的一个可行解,可在解空间树上回溯搜索。每个资源分配都对应一个树节点,当搜索到该节点时,须验证其是否满足约束。在资源独立性约束下,对资源分配与模式的约束验证相互等价,而模式数量小得多,因此有可能通过构造某种模式解空间来加快搜索。文献[9]的模式回溯算法隐式给出了模式解空间的结构:它是一棵根树;每个节点对应一个(步骤,编码)对;从根到叶的每条路径都不重复地包含S中所有步骤;根节点的编码为1;每组兄弟节点的编码分别为1,2,…,mx+1,其中mx是父节点到根的路径上的最大编码。由于每个节点唯一对应于从根到该节点的路径,且在该路径上,较小编码的首次出现早于较大编码的首次出现,故每个节点都表示一个可能的模式,不妨记为p。只要所用编码数(显然不超过|S|)不超过|U|,p必然构成某组资源分配Πp的模式。通常的解空间中,每个节点代表的资源分配都必然符合授权,这是因为每个步骤的授权资源集是预先确定的,在形成解空间时即可满足授权要求。然而,模式将抽象的编码而非真实的资源赋给步骤,在形成模式解空间时无法兼顾授权要求。这就给上述回溯搜索带来了新的问题。
如前所述,对模式p=〈T,{x1,…,x|S|}〉进行约束验证即可判断任何π∈Πp是否满足约束。我们将这种约束验证记为C。但是,符合模式p的资源分配不一定满足授权。为了判断是否存在某个π0∈Πp满足授权要求,模式回溯算法给出了验证的方法:设p的非0编码集为I,首先计算I与U之间的授权二分图B(任取x∈I和u∈U,若{s∈T|p(s)=x}⊆SA(u),则(x,u)是B中的边),然后在B上用匈牙利算法[15]求I的完全匹配,即一个单射函数m:I→U。若能求得m,则m∘p∈Πp且满足授权要求,否则,Πp中没有满足授权的资源分配。我们将这种验证称为(编码集与资源集的)授权匹配验证,记为M。模式回溯算法中还使用了M的一个必要性验证:设表示模式p的节点对应(步骤,编码)对(s,x),判断是否存在u∈U,使得{s∈T|p(s)=x}⊆SA(u),即x在按前述方式计算的授权二分图中是否有邻点。若无,则p不可能通过验证M。我们将这一验证称为(单个)编码的授权真实性验证,记为A。
在回溯搜索中,如何处理剪枝能力与验证代价的关系有重要意义[16],模式回溯法也不例外。文献[9]和文献[10]均只在搜索到叶节点时执行验证M,而当搜索非叶节点时,则以其必要性验证A代替。也就是说,仅当找到一个完整的模式解,需要计算真实可行解的时候,才去执行一次耗时的匹配验证。这样做降低了单个搜索节点上的验证代价,并可以保证一定的剪枝能力。而本文将利用实例难度的分布特点表明,这种处理方法在宏观上并不是最优的。
2 *WS(≠)的匹配剪枝模式回溯算法
由于互斥约束有资源独立性,故*WS(≠)问题可用模式回溯法求解。本节首先给出一种改进的模式回溯算法,其特点是在每个搜索节点处执行匹配验证M,以充分发挥其剪枝能力,故称为匹配剪枝模式回溯(MPB)算法;然后,将对其性能与代价的关系进行分析研究。算法描述如下。
算法1MPB (s,p,v) //Match-Pruning Pattern Backtracking
输入:s表示待分配编码的当前步骤,p表示之前各步骤的编码分配模式(未分配编码的步骤,其p值为0),v将p中的编码映射为相应的步骤集
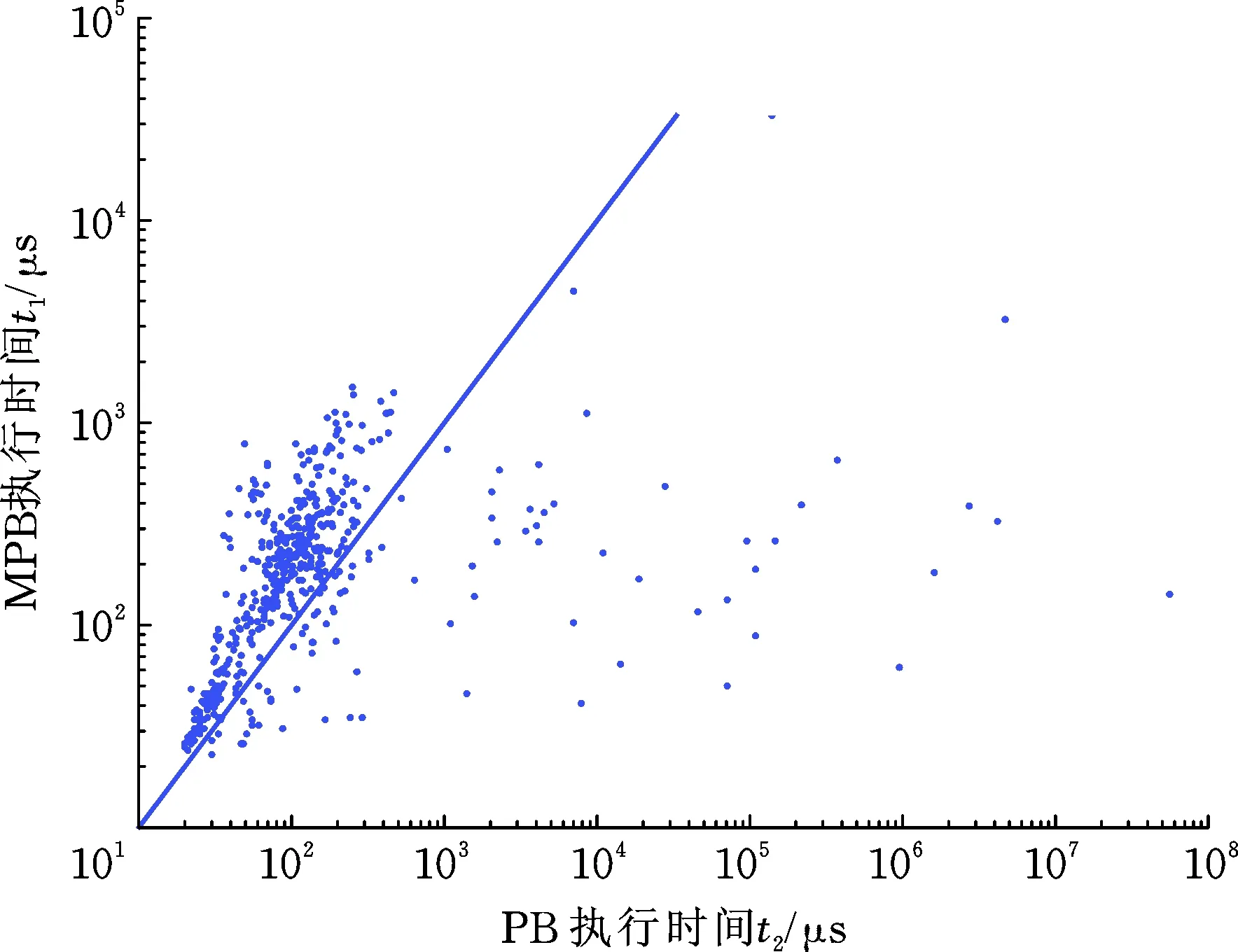
输出:S的资源分配可行解π, 或NULL(表示无解)
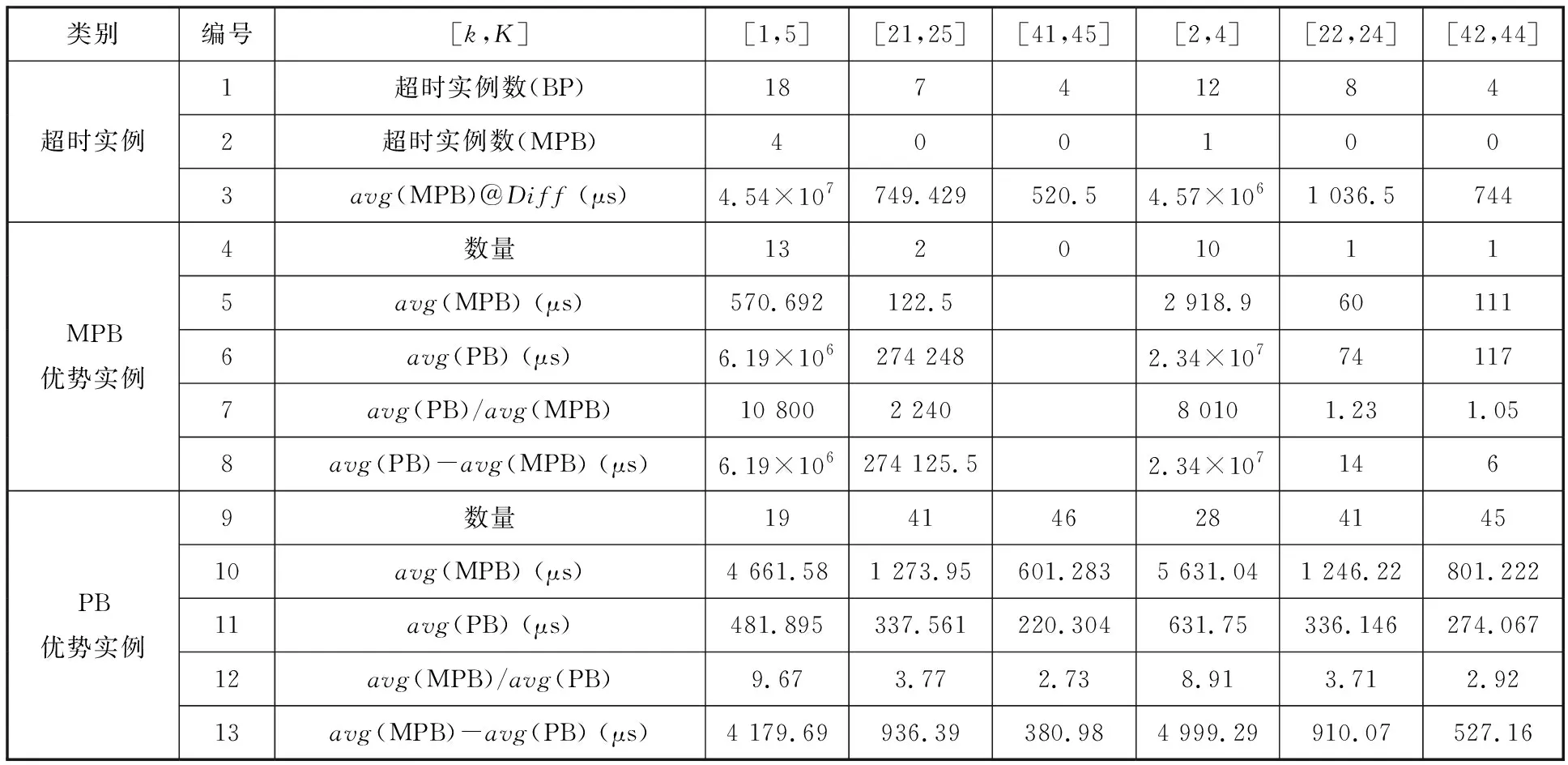
1.mx←{0,max(p(j)|1≤j 2.for (1≤x≤max(mx+1,|U|)) //尝试已使用的所有编码和下一个新编码,但编码数不能超过资源数 3.p(s)←x; 4.v′←v; //为下一级调用计算新的v 5.v′(x)←v′(x)∪{s}; 6. if (存在{s′,s″}∈X使得p(s′)=p(s″)) continue; //验证C失败,跳过当前编码,尝试下一个 7.i←s; //从当前步骤开始,对已分配编码的所有步骤循环 8. while (i≥1) //循环计算编码-资源二分图bp,bp(x)表示其授权步骤集可覆盖v′(x)的所有资源 9. if (bp(p(i))≠∅) continue; //bp(p(i))已计算,跳过当前x 10. for (u∈U∧v′(p(i))⊆SA(u))bp(p(i))←bp(i)∪{u}; //SA(u)是资源u的授权步骤集 11. if (bp(p(i))=∅) break; //编码p(i)在二分图中无邻点,验证A失败 12.i←i-1; 13. end while 14. if (i=s) continue; //为步骤s分配编码x导致验证A失败,跳过当前编码,尝试下一个 15. 求二分图bp的完全匹配m; //根据m可将编码映射为匹配资源 16. if (m不存在) continue; //无匹配,验证M失败,跳过当前编码,尝试下一个 17. if (s=|S|) returnm∘p; //p通过3种验证,且为完整模式解,其所匹配的真实解即为所求可行解 18.π′←MPB(s+1,p,v′); //p通过3种验证,但不是完整模式,继续深度优先搜索 19. if (π′≠NULL) returnπ′;//递归调用得到了可行解,将其返回即可 20.end for 21.p(s)←0; //清除尝试赋值的痕迹 22.return NULL; 令初始调用为MPB (1,p:S→{0},v:{1,…,|U|}→{∅}),即可求解*WS(≠)问题〈S,U,A,X〉,其中p:S→{0}给每个步骤赋值为0,v:{1,…,|U|}→{∅}给每个资源赋值为∅。由于在最坏情况下,算法可能遍历模式解空间,故其时间复杂度为O*(B|S|)。 相对于现有模式回溯法(记为PB),MPB算法的主要改变是在非叶节点处增加了第15~16行的授权匹配验证M,以及第7~14行的授权二分图计算,均属于验证M的内容。其中第7行从当前步骤s开始循环,将首先计算当前编码x在二分图中的邻点,这正是验证A的内容。若该验证不通过,第11行将跳出循环,不会执行剩余的二分图计算过程,紧跟着第14行会检测到这一情况,也不会执行求匹配的代码。简单来说,PB算法在每个搜索节点处进行组合验证V=C+A,而MPB算法在其后附加了验证M。上述算法设计的变化并不大,但会带来很有意义的性能提升。分析如下。 回溯法的性能由搜索节点数量和节点验证代价共同决定。MPB算法在每个搜索节点处引入匹配验证M,其目的是加强剪枝,尽量避免dead-end现象,即搜索到叶子或接近叶端的位置才发现当前解不可行,从而减少搜索节点的数量,避免相应的验证代价。然而,引入M也会增加单个节点的验证代价,这可以根据3种验证的时间复杂度进行比较。设每个节点n对应步骤-编码赋值(s,x),验证C只检查步骤s所参与的互斥约束,至多|S|个,而每一约束只需常数时间,故时间复杂度为O(|S|)。验证A判断编码x是否对应某个授权资源u,而x至多赋给|S|个步骤,需要逐一检查这些步骤和每个资源之间的授权关系。通过预先计算所有资源和步骤之间的授权关系矩阵,验证A可在O(|U||S|)时间内完成,因此,验证V=C+A的时间复杂度为O(|U||S|)。相对而言,验证M所需时间代价较大,完整计算授权二分图相当于执行O(|S|)次验证A,需要O(|U||S|2)时间,若与文献[9-10]保持一致,采用匈牙利算法求匹配,则其时间复杂度也是O(|U||S|2),故验证V+M的总代价为O(|U||S|2)。于是,MPB算法在非叶节点处的验证代价较PB算法高出一个O(|S|)因子。总体上,PB算法和MPB算法的执行代价之比可表示为 (2) 其中,#SNodes(PB)和#SNodes(MPB)分别是PB算法和MPB算法所搜索验证的节点总数,Cost(V)是PB算法在单个非叶节点上的验证代价,Cost(V+M)是MPB算法每个节点上的验证代价,#FLeaves(PB)表示PB算法因M验证失败而剪枝的叶节点数目,包含于#SNodes(PB),但需要额外的Cost(M)代价。MPB算法相对于PB算法的改进目标是使式(2)的比值尽可能大。改进前,对于#SNodes(PB)-#FLeaves(PB)中的节点,验证代价为Cost(V),而对于#FLeaves(PB)中的节点,验证代价为Cost(V+M)。改进后,对于#SNodes(MPB)中的节点,验证代价均为Cost(V+M)。Cost(V+M)>Cost(V)会减小式(2)的R值,如前述,Cost(V+M)比Cost(V)高出一个线性因子,这是其缩减作用的上限,当#FLeaves(PB)在#SNodes(PB)中所占比例较小时,会更接近这一上限。同时,V+M的剪枝能力强于V,原来的每次剪枝,改进后将发生在同样或更靠根的位置,必有#SNodes(MPB)≤#SNodes(PB),这将会增大式(2)的R值,但其作用强度很难估计,也缺乏合理的假设。本文将根据问题实例的难度分化情况,给出进一步的分析。 已有研究指出,回溯法求解CSP问题时存在相变因素,导致性能两极分化[17-18]。对于现有模式回溯法PB,我们也观察到了类似现象,即其在多数实例上表现良好,但时有性能恶化的情况出现。对于这两种情况,给出如下的分析。 PB性能恶化时将会伴随着比较严重的dead-end现象,即很多叶节点不能导致真实可行解而被剪枝,从而增大#FLeaves(PB)在#SNodes(PB)中的比例。或在更一般情况下,该比例不一定很大,但必然有大量剪枝点出现在接近叶端的位置,此时,任何新的剪枝能力对避免性能恶化都是非常重要的。特别地,大量剪枝点出现在近叶的位置,从根到剪枝点的路径很长,这就增加了新验证M在中间节点处提前剪枝的可能。而对原来比较靠近根端的剪枝点,引入M后至少可在同样位置完成剪枝。总体上,平均剪枝高度明显降低的可能性会比较大。对于正则的模式回溯解空间树(所有叶节点的高度相等),根据贝尔数的增长规律,当初始高度大于4时,树高每降低1层,所包含节点的数目减少2/3以上,且初始高度越大,降低1层后节点的减少比例越大。因此,模式回溯的搜索节点数量随剪枝高度降低,且至少按3k指数速度减少。如果M能额外提供一定剪枝能力,则可有效增大#SNodes(PB)/#SNodes(MPB),且比较容易抵消Cost(V+M)/Cost(V)的线性因子缩减作用,使式(2)取很大的R值,从而改善模式回溯法在困难实例上的性能表现。 PB性能良好时,若非问题实例的规模非常小,或者第一个真实模式解对应的叶节点恰巧出现在深度优先序列靠近开始的位置,则表明验证V的剪枝能力已经很强,剪枝高度已经较低。相应地,被剪枝的模式部分解所用编码数量也不多,为其进行完全匹配的难度较低,比较容易通过验证M。此时,M额外引入的剪枝能力有限,但却增加了搜索节点上的验证代价,容易引起整体性能下降。在最不利的情况下,M相对于V并未增加任何剪枝能力,引入M前后搜索节点的数量完全相同。此时,搜索代价完全取决于单节点验证开销,如前所述,MPB算法较PB算法高出一个O(|S|)因子。当PB性能良好时,由此导致的绝对性能差距也不大。而由于如下原因,两者的相对和绝对性能差距还会进一步减小: (1)由于PB算法有效的剪枝能力,剪枝点的高度h往往会明显小于|S|,而任意搜索节点n的高度h会更小。设n=(s,x),即在该节点处编码x被赋给步骤s,那么,验证C只需检查s与当前已赋值步骤之间的约束,其数量为O(h),验证A可在O(|U|h)时间内完成,而验证M可在O(|U|h2)时间内完成。MPB算法在非剪枝的搜索节点处需要进行V+M验证,但相对于PB算法的V=C+A验证,其代价只高出一个O(h)而非O(|S|)因子,两者的相对性能差距也会比之前的分析更小。 (2) 由于所有剪枝点构成了搜索范围的下边缘,根据模式解空间随树高的扩张速度可以判断,PB算法的剪枝点在所有搜索节点中占据了可观的比例。这些剪枝点都不能通过验证V,本文MPB算法按照先V后M的顺序进行验证,在这些节点处没有额外代价。相对于之前较为粗略的分析,这一因素进一步限制了两种算法的绝对性能差距。 由上述分析可以预期:相对于PB算法,MPB算法在容易的*WS(≠)实例上不会有多大劣势(至多高出一个O(h)因子,且两者的绝对性能差距不大),而在困难实例上会取得比较明显的优势。 现有算法中,文献[6]算法(记为Cr13)具有最低的时间复杂度,是一种基于容斥原理的动态规划算法,而文献[7]算法(记为Co14)代表了基于模式的动态规划算法,文献[9]算法(记为PB)具有最好的实测时间性能,代表了现有的模式回溯方法。本实验将MPB算法与这3种算法,特别是PB算法,进行性能对比,验证模式回溯法和增强匹配策略的优势。MPB算法和PB算法均根据步骤参与的互斥约束数量对其进行降序排列,并采用匈牙利算法计算匹配。 在二元随机CSP问题的标准模型中,采用变量个数、值域大小、约束密度和约束紧度4个参数控制实例生成,其约束类型不确定,且每个变量都取整个值域。对于仅含互斥约束且变量值域存在差异的*WS(≠)问题,约束紧度(违反约束的元组数与该约束值域中所有可能的元组数的比值)取决于两个约束变量的值域,不必单独控制,且生成模型中需要增加反映变量值域差异的参数。因此,本文通过以下几个参数控制实例生成: 步骤集规模|S|、资源比例μ=|U|/|S|(取资源集规模|U|=|S|μ)、约束密度ω=2|X|/[|S|(|S|-1)](以概率ω决定在每一对步骤之间是否生成约束)、每个步骤s的授权比例ks=UA(s)/|U|(从U中随机取|U|ks个资源作为s的授权资源集UA(s))。 每个实例的参数取值规则如下: (1)在[s,S](此处S和s只是大小两个整数,不表示步骤集和步骤)范围内随机生成|S|。步骤数反映了WS问题的基础规模。通常,取S=100即可覆盖大多数工作流的规模,且该范围的变化已经可以导致模式解空间的膨胀,为生成难实例提供了必要条件。 (2)在[u,U]范围内随机生成资源比例分子μ,取[u,U]=[50,200]以反映资源供应从相对短缺到比较充分之间的各种情况。 (3)在[w,W]范围内随机生成约束密度分子ω,由于互斥约束用于表达安全攸关的业务规则,故其密度通常不会太高。在本文实验中,将统一取[w,W]=[10,25]。 (4) 对于每个步骤s,在[k,K]范围内随机生成ks。当所有步骤的ks均为100%时,每个资源都可以执行每个步骤,只要模式部分解所用编码数不超过|U|,就一定对应某个真实部分解。特别地,当μ≥1时,任何模式部分解所用编码数都不超过|U|,故其一定具有真实性,不需要进行授权相关验证。以上是一种简化的理想情况。在实际应用中,不同的步骤需要不同的业务技能,其授权资源集通常存在差别。对于同一个编码赋给的若干步骤来说,其授权资源存在交集的可能性被降低了,这就为匹配验证的剪枝作用提供了基础。我们将根据随后实验的目的对[k,K]进行设置。 按上述规则随机生成500个实例,未确定参数的取值为[s,S]=[5,35],由于各对比算法的性能水平不尽相同,故首先取较小规模的工作流进行实验,对于表现突出的算法再扩大规模进行测试;随机取[k,K]= [1,4]、 [10,35]、[40,65]、[70,95]或[5,100],分别反映授权比例很低、较低、中等、偏高或大范围波动的情况。 设置时间上限为6 min,在500个实例上执行4种对比算法,结果如下。 两个动态规划算法中,Cr13和Co14分别解出了133和122个实例,最大求解规模分别是15和17个步骤,大体相当。在解出实例上的平均执行时间方面,Cr13为14.95 s,Co14为23.80 s,前者有一定的优势。在解出实例上的平均占用空间方面,Cr13为541 MB,Co14为14 MB。在失败实例当中,Cr13除22个超时外,其余均为内存超限,而Co14均为超时失败。这表明前者的空间占用处于劣势。从理论最坏情况来说,Cr13和Co14的空间复杂度分别为O*(|U|2|S|)和O*(B|S|),前者低于后者。但两者的空间利用方式显著不同,Cr13有保存权函数和计算快速zeta变换两个环节,均需一次性分配O*(2|S|)空间,而Co14随着自底向上动态规划,逐渐缓存新出现的模式部分解,这就使其空间代价的增长实际上比Cr13慢得多。 两个模式回溯算法中,PB解出了493个实例,而MPB解出了全部实例,略有优势。两者可求解的最大规模均为35个步骤。在解出实例上的平均执行时间上, PB为0.83 s,MPB为0.33 ms,有明显优势。在解出实例上的平均占用空间上,PB和MPB均为13 MB。较之两种动态规划算法,PB和MPB在求解率、最大求解规模、平均时间和空间占用上都有极大优势,验证了模式回溯算法的优越性。为了解平均时间性能差异背后的具体分布,将PB和MPB在493个共同解出实例上的执行时间逐对成点,得到图1所示的散点图。由图1可知,PB对大部分实例的处理都在300 μs以内,但其余实例的执行时间发生了数倍到成百万倍的跳跃,这就导致平均执行时间大大增加。而MPB的执行时间基本上在2 ms以内,且以相当连续的方式变化,因此平均时间也在同一量级。 图1 实验1中MPB与PB执行时间的逐点对比Fig.1 Pointwise comparison between the running time of MPB and PB in experiment 1 逐点对比两种算法。y=x斜线上方是PB较MPB优势的实例,其数量很多(404个),但是纵横坐标之比(MPB/PB)不大,平均为1.96,纵横坐标之差(MPB-PB)的平均值仅为159.49 μs,说明PB的相对优势不大,而绝对优势非常小;斜线及其下方是MPB较PB有更大或同等优势的实例,其数量相当少(89个),但是横纵坐标之比(PB/MPB)很大,平均为28 585.89。这表明PB在大量实例上有较小的优势,而MPB在少数实例上取得了很大的优势。此外,还有7个实例PB的执行时间超过360 s,而MPB处理它们仅需0.149~0.455 ms,平均为0.29 ms,甚至低于MPB在所有实例上的平均时间。综合上述结果可知,在PB性能相对恶化的实例上,MPB均取得了显著的优化效果。而在那些PB表现良好的实例上,MPB同样有不错的表现,与PB的绝对和相对性能差距都不大,这与之前的分析结果一致。 以上对少量步骤的情形进行实验,表明MPB性能的提高主要发生在PB性能恶化的实例上。接下来,我们将通过更大范围的实验来确定此类实例的出现条件,进一步验证本文算法的优势,并通过剪枝能力相关指标的测量,进一步揭示其原因。如前所述,问题实例的约束密度处于较低的范围内,我们将通过改变授权比例来寻找现有模式回溯法的难解实例。 将步骤数的范围扩大到[s,S]=[10,100],在不同波动幅度(100/3,100/5)下,令(k+K)/2等距(17±1)变化,分别生成一组实例。其中第1组[k,K]=[1,33]、 [17,49]、[34,66]、[50,82]和[68,100],第2组[k,K]=[8,27]、[24,43]、[41,60]、[57,76]和[75,94]。每个[k,K]为1个单元,按前述单实例规则生成50个实例,每组包含5单元共250个实例。在两组实例上以6 min为限运行PB和MPB,统计结果见表1和表2。其中,avg(G)表示算法G在若干实例(通常是一单元中某一类别的实例)上的平均执行时间,剪枝高度均值(G)表示算法G在若干实例上产生的所有剪枝点(到实例结束或超时为止)的平均高度(剪枝点到根的距离称为其高度),搜索节点数均值(G)表示算法G在若干实例上的搜索节点数(一个实例执行结束或到其超时为止,执行过搜索验证的节点总数)的平均值,Diff表示PB超时而MPB未超时的实例集。 表1 实验2第1组实例结果统计 表2 实验2第2组实例结果统计 (续表) 类别编号[k,K][8,27][24,43][41,60][57,76][75,94]MPB优势的共同解出实例8数量110319avg(PB)(μs)2603.58×1069.41×10610810avg(MPB) (μs)19714424210611avg(PB)/avg(MPB)1.3224 90038 9001.0212avg(PB)-avg(MPB) (μs)633.58×1069.41×106213剪枝高度均值(PB)19.6920.8735.0815.7714剪枝高度均值比(MPB)15.0112.3624.4215.7715搜索节点数均值(PB)1781.55×1062.96×1065416搜索节点数均值(MPB)915499.3354PB优势的共同解出实例17数量444648444918avg(MPB)(μs)1 384.86887.239651.396637.386430.26519avg(PB)(μs)361.477285.739238.333248.023197.18420avg(MPB)/avg(PB)3.833.112.732.572.1821avg(MPB)-avg(PB) (μs)1 175.77601.5413.063389.363233.08122剪枝高度均值(MPB)34.1434.0830.3332.9929.7123剪枝高度均值(PB)34.1434.0830.3332.9929.7124搜索节点数均值(MPB)318.75226.18164.5158.36146.0625搜索节点数均值(PB)318.75226.18164.5158.36146.06 由表1、表2的1~3行可以看出,PB出现了数量不等的超时实例,而MPB大部分没有超时。在PB超时而自身未超时的实例上,MPB平均执行时间均未超过2 ms,性能优势非常显著。由4~7行可知,MPB通过额外的匹配验证,将剪枝高度平均降低了27.95,这导致其搜索节点数大幅度减少,降低了5~6个数量级。MPB的搜索节点数平均仅有几百个,远低于其剪枝高度(40左右)相应的贝尔数部分和,这主要是因为采用了剪枝点高度均值这一指标,而不是严格意义上的平均剪枝高度(对于每个实例,将其搜索节点数从根开始以宽度优先方式排列在解空间树中,计算下边缘的高度)。在形态上,前者可能导致从根开始的一丛分散的枝条,其平均长度较大,但枝条上的节点相对较少,而后者得到从根开始排列紧密的三角形,其高度不大,但包含了大量节点。若固定搜索节点的数量,则前者以后者为下界。事实上,PB在这些实例上的剪枝高度均值都已接近解空间树的高度,两个指标区别不大。若对MPB也采用后一指标,则相对于PB的降低程度会更大。另外,PB在大量叶节点处发生匹配失败,统计其MatchFailedLeafCount(V)达到SearchNodeCount(V)的同等或1/10量级,这种情况属于典型的“dead-end”。两种算法对比可知,仅仅采用V=C+A验证,在此类实例上远不能实现有效剪枝,而增加M验证可明显增强模式回溯法的剪枝能力。就PB超时实例的分布而言,当(k+K)/2从较小的值开始增加时,大体呈减少的趋势,这是因为授权比例增加对模式解空间大小没有影响,但却可以导致真实模式解数量的增加,使得第一个解在搜索序列中的出现位置提前,从而更容易被搜索到。随着授权比例的增加,MPB的超时实例数量变化不太明显,但其仅有的2个超时实例也出现在授权比例最低的区间。从表1、表2的第3行来看,在授权比例较低的解出实例上,MPB消耗的时间也较多。总的来说,PB在较低的授权比例下更容易出现超时,而MPB可以有效改善这种情况,但其性能在较低的授权比例下也较差。 由表1、表2的8~12行可以看出,MPB优势的共同解出实例很少,平均每单元(50个实例)不到2个,但MPB的优势很大。除2个执行时间极为接近的实例(此时算法优势有一定偶然性)外,至少将性能提高到26.5倍,最多达到45万倍,绝对性能差距则在2.5 ms~700 s之间,优化效果也比较明显。从13~16行的回溯剪枝指标来看,MPB将剪枝高度平均降低了5.97(除去执行时间几乎相等的情况),相应将搜索节点数降低了1~5个数量级。由此可见,剪枝高度平均值的较少降低,已经可以引起搜索节点数的大幅度减少。在PB性能相对恶化的实例上,MPB已经可以取得很大优势。 观察表1、表2第17~25行的数据可知,PB优势的共同解出实例很多,平均每单元45个左右。有些意外的是,在绝大部分情况下,MPB和PB的剪枝高度和搜索节点数平均值都相同。这说明对较为容易的实例,PB所使用的V=C+A验证与V+M验证往往是等效的。对本文算法来说,相当于最不利的情况普遍发生了。即便如此,PB的性能优势最多只达到步骤集规模(10~100,中位值55)的1/10,而非线性比例,且绝对性能优势均在1.2 ms以内,均与我们之前的分析一致。 上述两组实例的[k,K]波动幅度较大,导致其中位值起点较高。为了考查更小的授权比例,取小的波动幅度(5,3),令(k+K)/2等距(20)变化,生成3、4两组实例进行扩展测试。每组实例包含3个单元,其中第3组[k,K]=[1,5]、 [21,25]、[41,45],第4组[k,K]=[2,4]、[22,24]、[42,44],其他参数与之前的设置相同。在两组实例上以6 min为限运行PB和MPB,统计结果见表3。 表3 实验2第3、4组实例结果统计 由表3的1~3行可见,PB的超时实例数随着(k+K)/2的减小而增多,MPB的超时实例数明显小于PB,且在PB超时而MPB未超时的实例上,MPB的平均执行时间不超过45.4 s。由4~8行可见,MPB占优势的共同解出实例仍然不多,且MPB取得的性能优势是相当显著的(忽略2个执行时间几乎相等的实例),至少为81.5倍,最高可达10 800倍。由9~13行可见,PB占优势的共同解出实例很多,但PB的性能优势不超过MPB的9.67倍,而其绝对性能优势不超过5 ms,同样是非常微弱的。上述结果的变化规律与前两组实例基本一致。值得注意之处在于,对于[k,K]=[1,5]、[2,4]两个单元,PB的超时实例数和MPB优势的共同解出实例出现了明显提升,表明在低约束密度下足够小的授权比例可以导致真实模式解的数量急剧减小,使PB难解实例的数量显著增加。 本文从互斥约束工作流可满足决策问题(即*WS(≠)问题)出发,针对现有模式回溯算法的缺陷进行改进,通过扩大授权匹配验证的作用范围来增强其剪枝能力,并对其验证代价的负面影响进行考查。分析和实验表明,现有模式回溯法的实例性能存在比较明显的两极分化现象:在性能恶化实例上,匹配验证可以显著增强剪枝能力,极大提高搜索性能;而在性能良好的实例上,尽管验证代价的负作用更为突出,但造成的绝对性能下降几乎可以忽略。在工作流环境约束密度较低的前提下,实验还表明:当授权比例较低时,更容易发挥本文方法的优势。 下一步将对特定约束的*WS随机实例生成模型和解的分布规律进行研究,用以改进其求解效率。2.1 PB性能恶化
2.2 PB性能良好
3 实验研究

3.1 4种*WS(≠)算法的性能对比实验(实验1)
3.2 MPB与PB的进一步对比实验(实验2)



4 结语
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
加油站服务指南(2021年4期)2021-07-21 02:29:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
数学年刊A辑(中文版)(2020年1期)2020-05-19 00:30:30
天津诗人(2017年2期)2017-03-16 03:09:39
人生十六七(2015年6期)2015-02-28 13:08:38
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
计算机工程(2014年6期)2014-02-28 01:26:33
上海理工大学学报(2012年3期)2012-03-20 13:54:43
