
Storm集群下基于性能感知的负载均衡策略①
2019-01-07 02:41冯馨锐
计算机系统应用 2018年12期
冯馨锐,谢 彬,唐 鹏,秦 健
(中国电子科技集团公司第三十二研究所 信息服务平台室,上海 201808)
随着互联网和大数据技术的快速发展,全球的数据正在以惊人的速度增长,因此数据的高时效性,可操作性需求已经成为研究热点[1].Storm作为Twitter开源的分布式实时流计算系统,具有编程接口简单[2],可拓展性良好和容错机制可靠[3]的优点,因此在实时推荐,金融分析和在线机器学习[4]等方面发挥着重要作用.
实时流计算系统及负载均衡、调度技术的研究向来是大数据处理领域不可回避的研究热点.面对企业生产对流式数据实时处理快速增长的需求,如何根据运行时环境动态调度流算子任务,满足低处理时延并最有效利用计算资源具有巨大的研究价值.
本文阐述了Storm自带的调度器调度策略,并对其现存的负载均衡问题进行了分析.同时,本文针对流处理系统数据输入率和数据处理延迟等不足,以集群的视角提出了一种基于性能感知的负载均衡策略并对其算法进行了实验验证.结果表明,该算法能够有效的提高集群资源的利用率,进而达到动态的负载均衡.
1 Storm现有调度机制在负载均衡问题分析
Storm通常应用在计算密集型场景中,负载均衡技术则是保证实时计算高性能和高吞吐量的有效手段,而任务调度策略又会直接影响负载均衡的性能.
在Storm集群中,用户提交的作业是一个topology,其表现为有向无环图,会被调度器进行任务的划分.Storm默认调度策略采用sort-slot将任务(Task)轮流分配给节点,如图1所示.

图1 Storm 默认任务调度示意图
每次新提交的topology均会从第一个节点开始分配所划分的任务.但因每个topology的业务逻辑不同,其任务划分数量也是不定的.如果仅根据节点剩余slot数量进行简单负载均衡会存在以下三点问题:
(1)这种sort-slots会导致整个集群资源分配不均衡,排序靠前的supervisor分配出去的 slot数量多,而后面某些很少.
(2)在集群中添加、删除节点或worker进程后,集群的计算资源会发生变化,现有调度策略无法根据改变后的可用资源做出有效的调整策略.
(3)Storm默认的调度机制未充分考虑节点负载情况,计算容器的固定配置使其不能根据数据输入率实现有效的负载均衡.
针对Storm默认调度算法进行改进的相关研究吸引了越来越多研究者的关注.Ding[5]等采用了改变worker内部并行度方式应对负载的波动,Navalho[6]等提出了依据数据输入率动态变化调整worker等方法.这些技术仍然是基于计算资源分配量固定的情况下进行的改进,并未考虑worker本身的资源需求和分配不匹配的问题,不一定适用于Storm集群运行时环境.Xiong[7]等以Task之间的Tuple传输速率作为判定条件,提出热边调度算法,将高频热边关联的Task作为整体来调度,以最大程度减轻节点之间通过网络传输Tuple的数量.这种算法能够在降低通信量和负载均衡之间有一个很好的权衡.然而在真实的生产环境中,往往是高速的局域网连接的计算机集群,并不会将带宽视为一种限制资源.此外,Zhang[8]等采用权值分配策略为每个slot定义并且计算优先级,优化了Slot排序的问题,实现了节点之间的负载均衡.但是该策略并未考虑负载波动对计算资源的影响以及集群中不同节点之间的性能差异,只适合应用于某些需要区分任务紧急度的领域中.
2 基于性能感知的负载均衡策略
本文提出了一种基于性能感知的负载均衡策略.该策略可及时感知节点负载波动,并可根据节点负载能力分配任务,在充分利用系统的资源同时,达到负载均衡的目的.
2.1 算法改进分析及思想
在storm集群中,一个topology的任务是分布到多个节点上执行的,且负载会随着数据输入率的波动而波动.因各个节点的资源可用性和数据输入率存在一定的差异[9],会导致任务的处理速度不一.其实,对于一个流应用来说,计算资源供给的不稳定性,数据输入率不确定性等情况,终将反应到节点对于任务的处理性能上[10].如果将数据输入率,平均处理延迟等参数结合应用在改进的算法中,能够更好地反映节点的具体负载情况,以此为依据来评估节点的处理能力,量化的重新分配任务,则可以达到改进负载均衡的目的.
算法思想如下:首先对Storm的监控模块进行重用,使其可以采集任务部署后的运行信息.接着工作节点(supervisor)每隔一个周期向监控模块发送一个信息采集请求,监控模块会及时反馈当前拓扑中各个任务的流输入率和平均处理时延.任务调度器会根据每个节点采集的信息来定义该节点的优先级,以达到及时的性能感知.最后,调度器以集群的视角将任务的计算量与节点处理能力相匹配,产生新的任务映射方案,达到负载均衡的目的.
2.2 性能感知方法
在过去的研究中,系统负载的评价标准一般是CPU利用率,但是对于一个任务来说,该任务的CPU利用率仅仅表示了其占用了节点计算时间的比重,并不能体现节点的处理性能[11].如表一 所示,两个负载相同的任务,一个任务输入率为 1000 tuples/s,在平均处理延迟为2 ms的node1上执行,另一个任务输入率为2000 tuples/s,在平均处理延迟为 1 ms的 node2 上执行.虽然两个任务的负载相同,但其所对应的节点处理数据效率是明显不同的.

表1 负载与 PAV 的对比
基于上述发现,本文将r(t)/τ(t)的值称为性能感知值(PAV).PAV与任务在某段时间内的输入率成正比,与相应时间段内的节点平均处理延迟成反比.
性能的计算首先要获取监控拓扑任务的运行数据,这个方法通过监控模块来完成.为了避免监控的偶然因素,调度器将采用最近连续三次监控的平均值.单个节点的PAV可以是其上各任务的PAV之和,也可是节点总数据输入率和与平均处理延迟的商.本文从集群的视角来考虑,采用后者来计算,并对结果降序排列,为之后的负载均衡做准备.具体的PAV计算方法如下,流程图如图2所示.

算法1.计算节点PAV输入:任务运行时信息输出:PAV_node[N]Step1:receive task runtime information Step2:FOR node belongs to cluster DO get the total rate:sum all task rate on node get the average latency END FOR Step3:PAV_ node[i] total rate/average latency Step4:Sort_down(PAV_node)
合理配置采样周期对于调度性能的提高具有重要意义.如果采样周期过短,集群信息的采集会带来很大开销,对任务实时性会有一定的影响,而如果周期过长,对于波动较大的数据流,会影响其性能感知准确性.根据以往经验,数据平均到达率为3000 tuples/s且服从泊松概率分布时,采样周期设置在 10 s~15 s 为佳[12].本文实验环境设置的采样周期为10 s.

图2 节点 PAV 计算流程图
我们可以根据PAV来评估一个节点当前的处理性能,PAV高的节点应该被分配更多任务.一般而言,每个节点的计算资源是固定的,随着提交任务的增多,节点处理性能会变差,即PAV会降低,此时需将某些任务提交给PAV高的节点去处理,可减小性能差节点的计算量.
2.3 基于PAV的负载均衡算法实现
结对交换算法是解决负载均衡的常用算法,如图3所示,其基本思路是将N个节点分为N/2组,负载最小的节点与负载最大的在一组,负载次小的与负载次大的在一组,依此类推,若还剩中间节点,则忽略处理.在组内通过任务的迁移,来减少节点之间的负载不平衡.
结对交换算法对性能有差异的节点任务交换,在一定程度上缓解了性能差节点上的处理压力,但是不能以集群视角来分配任务,且对有些情形不起作用.因此,本文以结对交换算法为启发式优化算法,提出了基于PAV的负载均衡算法.
负载均衡问题本质上是一个NP完全问题[13],到目前为止还没有完全有效的解法.对于这类问题,用贪心选择策略有时候会设计出一个比较好的近似算法.本


表3 实验环境配置
实验的目的在于对性能感知的改进方法做相关性测试,并且以典型的大数据应用WordCount进行了4组实验.4组实验分别针对Storm优化的处理时延测试、系统吞吐量测试、固定数据输入率下CPU负载均衡性测试以及满足泊松概率分布的动态数据流下CPU资源利用率测试.
3.1 不同数据输入率下平均处理时延
流处理系统最主要的是保证应用的低处理时延,处理时延是衡量一个调度系统是否有效的重要指标.实验一包括了4组对比实验,分别以1000条/s、2000条/s、3000条/s、4000条/s的速率向Redis中写入数据,然后Spout从其中读取数据.图4表示的是默认调度和本文调度在对应数据输入率下的平均处理时延的比较.由实验结果可知,默认调度算法的处理时延会随着发送端数据量的累积而增大,当速率达到4000条/s时,时延增长约40%,而基于性能感知的调度算法可及时感知任务的计算量,并将其分配到性能最优的节点上,因此整体平均时延并不会有显著增大.

图4 处理时延对比
3.2 系统吞吐量测试
实验二通过改变topology中的task数量,对系统吞吐量进行测试.从图5可以看出,在task数量小于6时,默认的算法效率略高于改进算法,这主要是由于task数量较少时,集群负载很低,而默认算法的实现较为简单,因此性能好于改进算法.随着task数量的增加,改进算法优势就体现出来了.这是因为基于PAV的调度能有效感知集群中每个节点的负载情况,将任务和节点处理能力相匹配,从而避免个别节点的过载.随着task数量的继续增加而超过10个时,两种算法的吞吐量均出现了不同程度的下降.这是由于这些task通信所需的频繁的序列化与反序列化操作及task所对应的executor间的切换,均会消耗很多的计算资源,最终导致吞吐量下降.
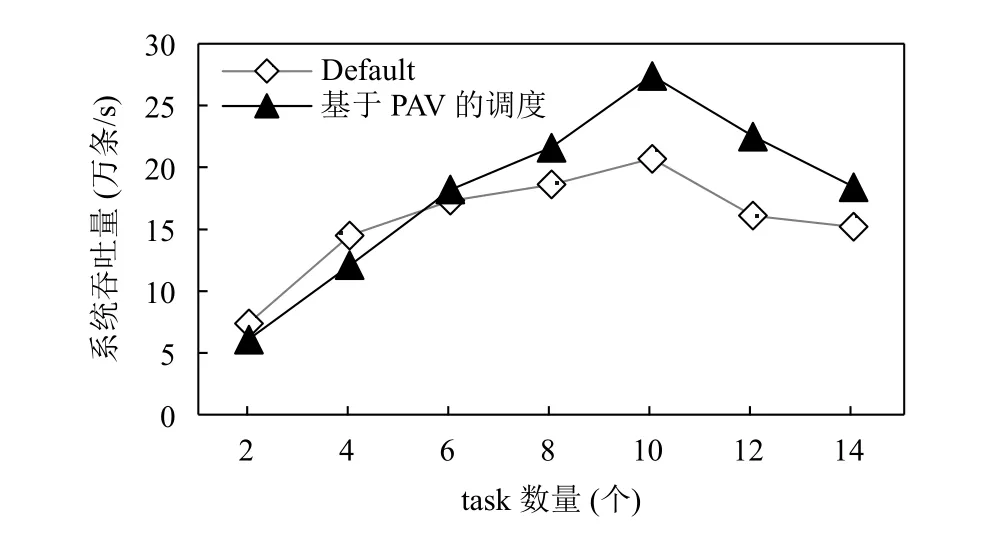
图5 系统吞吐量比较
3.3 固定数据输入率下CPU负载均衡性测试
实验三采集了在固定数据输入率(2000条/s)下流处理过程中集群CPU资源在异构节点上的负载分布,进而考察基于性能感知负载均衡策略效果.如图6所示,当系统稳定后,计算能力较好的节点(Slave2和Slave3)因其使用基于PAV的负载均衡调度,CPU使用率相较默认调度有了显著上升,而Slave5由于计算能力略低,调度器在感知性能后会将其上任务根据结对交换算法进行迁移,因此与默认调度策略相比,其CPU使用率会有显著下降,约50%左右.

图6 集群节点 CPU 负载分布
3.4 动态数据流下CPU资源利用率测试
为了能够满足在真实的生产环境下系统随着数据到达率的变化而处理数据,实验四在实验三的基础上,通过Python数据发生器作为数据源产生数据流,且到达的时间遵循泊松分布.公式如下:

测试数据泊松分布参数λ从1000开始,分别增至2000、3000,统计不同性能节点的CPU资源使用率.
表4给出了各节点在λ参数递增的动态数据流下,CPU资源平均利用率在默认调度和基于性能感知的负载均衡调度下的对比.重点考察Slave2和Slave5.随着λ的增大,性能较好的Slave2其PAV调度CPU利用率相较默认调度会有显著增加,当λ=4000时,两者相差近20%,而Slave5性能较差(见表3),其PAV会随着λ增加而下降,依据本文贪心调度策略,上面的任务会被调度到别的节点.所以尽管输入率动态增加,CPU资源利用率反而有所下降.这是改进算法对节点性能感知后动态迁移任务的结果,进一步体现了真实环境下动态的负载均衡.

表4 动态数据流下集群CPU资源平均利用率(%)
综合以上4组实验结果可以看出,通过对时延和流输入率的感知,结合负载均衡迁移机制,使任务可以在集群间依据处理的需要调度到适合的节点,是提高Storm集群资源利用率和处理效率的有效途径.
4 结束语
本文基于Storm实时流处理调度机制,针对默认调度策略资源分配不均衡和无法动态感知数据的输入率等问题,提出了基于性能感知的负载均衡策略.通过实验验证,结果表明基于性能感知的负载均衡策略可有效促进Storm集群负载均衡,提高吞吐量,并降低处理时延.本文的局限性在于,对于性能感知的调度策略方面未考虑设置阈值和动态调整阈值以达到更好的调度性能,这也是下一步的研究方向.
猜你喜欢
电脑知识与技术(2021年22期)2021-09-14
北京航空航天大学学报(2021年6期)2021-07-20
纺织科学研究(2021年6期)2021-07-15
铁道通信信号(2020年10期)2020-02-07
北京航空航天大学学报(2019年9期)2019-10-26
军事运筹与系统工程(2019年4期)2019-09-11
计算机测量与控制(2019年6期)2019-06-27
花火B(2019年3期)2019-04-27
信息化建设(2019年2期)2019-03-27
电子制作(2019年23期)2019-02-23
