
基于Spark的飞机试验数据预处理技术研究
2019-01-07 11:57,,,,
计算机测量与控制 2018年12期
, , ,,
(1.上海民用飞机健康监控工程技术研究中心,上海 200241; 2.北京航天测控技术有限公司,北京 100041; 3.北京市高速交通工具智能诊断与健康管理重点实验室,北京 100041;4.轨道交通装备全寿命周期状态监测与智能管理技术与应用北京市工程实验室,北京 100041)
0 引言
随着计算机和测控技术的发展,试飞试验数据呈现出参数多(上万个)、数据量大(上百TB)、参数类型多样化等特点[1]。飞行试验数据是完成新机定型、鉴定的主要依据,同时也是支撑航空科技发展的宝贵资料。能否将大量飞行试验数据有效管理并使用起来,这对我国航空事业的发展具有重要的现实意义。
飞行试验是在真实飞行条件下进行的科学研究和产品试验。它是航空科技发展的重要手段,是航空产品研制和鉴定的必须环节,是为用户摸索和积累经验的有效途径。试飞任务中的数据信息管理是一个庞大而复杂的系统工程,目前国内传统的试飞数据处理模式是:一型飞机、一个团队、一套数据格式及处理程序,即由专业人员使用自行开发的软件,对测试数据进行处理,中间结果及最终报告数据以操作系统文件的形式保存;有关数据处理的文档人工处理。这种处理模式的缺点是:1)数据和程序的继承性差,共享困难;2)低水平重复,不利于积累以往的经验;3)处理效率低,容易出错;4)处理周期长,不利于快速做出下一步的试飞决策。
本文研究基于Spark的飞机试验数据处理技术,将改变原有的“特定飞机,专用软件”的研制模式,将复杂、繁琐的数据管理工作抽象出来,使工程师能够将更多的精力集中到数据的处理和分析工作中去。一方面,提炼共同要求,统一飞行试验信息化标准,完成系统的统一规划与部署,避免试飞信息化工作出现效率低下和资源浪费等问题。另一方面,通过建立健全和完善型号信息系统、数据与信息以及数据处理软件的标准和规范,提高信息系统和软件的可重复性,避免低水平的重复开发。
1 SPARK内存计算框架
目前,应用最为广泛的大数据技术是hadoop以及其分布式架构map-reduce。Hadoop MapReduce采用Master/slave 结构。只要按照其编程规范,只需要编写少量的业务逻辑代码即可实现一个强大的海量数据并发处理程序。其核心思想是分而治之。Mapper负责把一个复杂的业务,任务分成若干个简单的任务分发到网络上的每个节点并行执行,产生的结果由Reduce进行汇总,输出到HDFS中,大大缩短了数据处理的时间开销。MapReduce以一种可靠且容错的方式对大规模集群海量数据进行数据处理,数据挖掘,机器学习等方面的操作[2-7]。
尽管该架构具备开源分布式的特点且应用范围广泛,但在大量数据离线计算过程中,map-reduce存在着大量的硬盘读写,这造成计算效率很低。Spark是用于大数据处理快速而通用的引擎,其采用分布式内存计算方式,将过程数据保存在内存中,减少了由于磁盘交互产生的I/O,从而提高数据计算效率[8-10]。
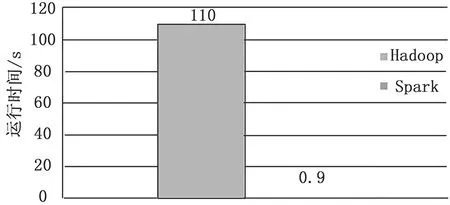
图1 Hadoop和Spark的逻辑回归
Spark拥有Hadoop MapReduce所具有的优点,但和MapReduce的最大不同之处在于Spark是基于内存的迭代式计算[11]。Spark的Job处理的中间输出结果可以保存在内存中,从而不再需要读写HDFS,除此之外,Map-Reduce在计算中只有两个阶段,即map和reduce。而在Spark的计算模型中,可以分为n阶段,因为它内存迭代式的,我们在处理完一个阶段以后,可以继续往下处理很多个阶段,而不只是两个阶段。因此,Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。不仅实现了MapReduce的算子map函数和reduce函数及计算模型,还提供更为丰富的算子,如filter、join、groupByKey等,是一个用来实现快速而同用的集群计算的平台。
此外,Spark应用程序还离不开SparkContext和Executor。Executor负责执行任务,运行Executor的机器称为Worker节点,SparkContext由用户程序启动,通过资源调度模块实现与Executor通信。图2为Spark的操作机制。

图2 Spark操作机制
集群管理器主要控制整个集群,监控各工作节点。工作节点负责控制计算节点,启动执行器和驱动程序。执行器是应用程序运行在工作节点上的一个进程。
RDD(Resilient Distributed Datasets)[1],弹性分布式数据集,是分布式内存的一个抽象概念,RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,只能通过在其他RDD执行确定的转换操作(如map、join和group by)而创建,然而这些限制使得实现容错的开销很低。对开发者而言,RDD可以看作是Spark的一个对象,它本身运行于内存中,如读文件是一个RDD,对文件计算是一个RDD,结果集也是一个RDD,不同的分片、数据之间的依赖、key-value类型的map数据都可以看做RDD。图3显示Spark计算的RDD模型。

图3 Spark计算过程不同阶段的RDD模型
2 海量飞行数据预处理方法
飞机试验数据解析效率是影响大数据分析,挖掘额外信息资源的重要影响因素。随着飞机集成度的提高,传感器数据的增多,飞机试验数据的参数种类与数据量剧增。传统的飞机数据解析方法主要是针对源码数据量小的情况,无法满足当前大型飞机试验任务的需求。而针对大规模源码数据,目前一般都是工程师对任务进行分工,每个人负责任务的一部分,在各自的机器上运行,最后将结果进行汇总,这不仅会增加人力成本,也会增加解析的复杂度,降低解析效率,影响下一步试飞决策。因此,需要建立一种针对大规模飞行试验数据的预处理方法。
本文一方面采用Spark处理框架,通过分布式计算方式,减少磁盘交互产生的I/O,提高计算效率;另一方面,利用飞机数据采集特点,减少不必要的解析,节省集群内存计算空间,提高解析效率。从数据解析过程优化与并行处理的角度,提出了基于Spark的海量飞行试验数据的预处理方法。
2.1 飞行数据解析优化
飞机运行过程中,机载采集器根据规定的采样率对机载数据进行采集,当次试飞结束后下载原始数据。由于数据参数格式固定,在数据采集过程,根据实际情况解析前段数据,直到获取所有需要的参数初始信息位置,包括参数的采样初始时间,整个数据文件采样的初始时间以及数据文件出现的参数名全集等。
确定数据文件中存在的参数集合,预先剔除参数组中不存在于当前数据文件中的参数群,只提取存在于数据文件中的参数属性,有效地跳过不必要的解析过程。同时减少广播变量(Broadcast)占用的内存,为集群内存计算节省空间,显著提高解析的效率。
进而,切割并行数据,生成若干个原始数据包。切包的规则是只能在两个单包之间切,而不能跨包,否则会丢失数据,通过不断计算单包的长度来用指针偏移的方法来切包。
在此基础上,对飞行测试数据进行预处理。预处理过程分为两个阶段,配置阶段和应用阶段。图4显示了两个阶段的过程,包括控制流程和数据流程。

图4 图解码阶段的数据预处理步骤
在配置阶段,主要是在试飞数据处理设备正式投入运行之前和运行过程中,进行系统基础信息的配置与扩展开发,并且进行系统数据库的管理,为系统提供原始数据的解码、分析逻辑、算法功能等方面的配置和扩展开发能力,使系统具备持续的完善能力。
1)首先进行的是用户配置、试验信息配置与基础信息配置的工作。
2)其次是完成对配置文件的解析和试验数据的预处理。
3)再次是存储原始二进制数据和解析后工程值数据。
4)最后针对解析后数据为用户提供数据服务,包括数据的查询、下载、导出、分析、二次计算等。
在准备阶段,从配置文件中读取帧格式的配置信息,包括帧参数的位置,采样率,通道数等。然后读取参数数据表中所有帧参数的数据类型、分辨率、数据长度等。最后,根据参数的位置信息设置参数索引表。
在解码阶段,当接收到源代码时,根据429、232、664协议规定的帧格式对帧头进行解析,获取当前帧的索引表唯一标识,通过标识确定当前帧采集的参数索引表,进而根据参数信息将源码数据解析为工程值数据。

图5 解码阶段的数据预处理步骤
2.2 基于SPARK的数据处理技术
在使用SPARK技术来解决大规模数据预处理问题的过程中,如何在每个预处理步骤中构建测试数据RDD模型以及如何使用SPARK算子至关重要,直接影响数据预处理的效率。图6为基于SPARK的数据处理流程图。
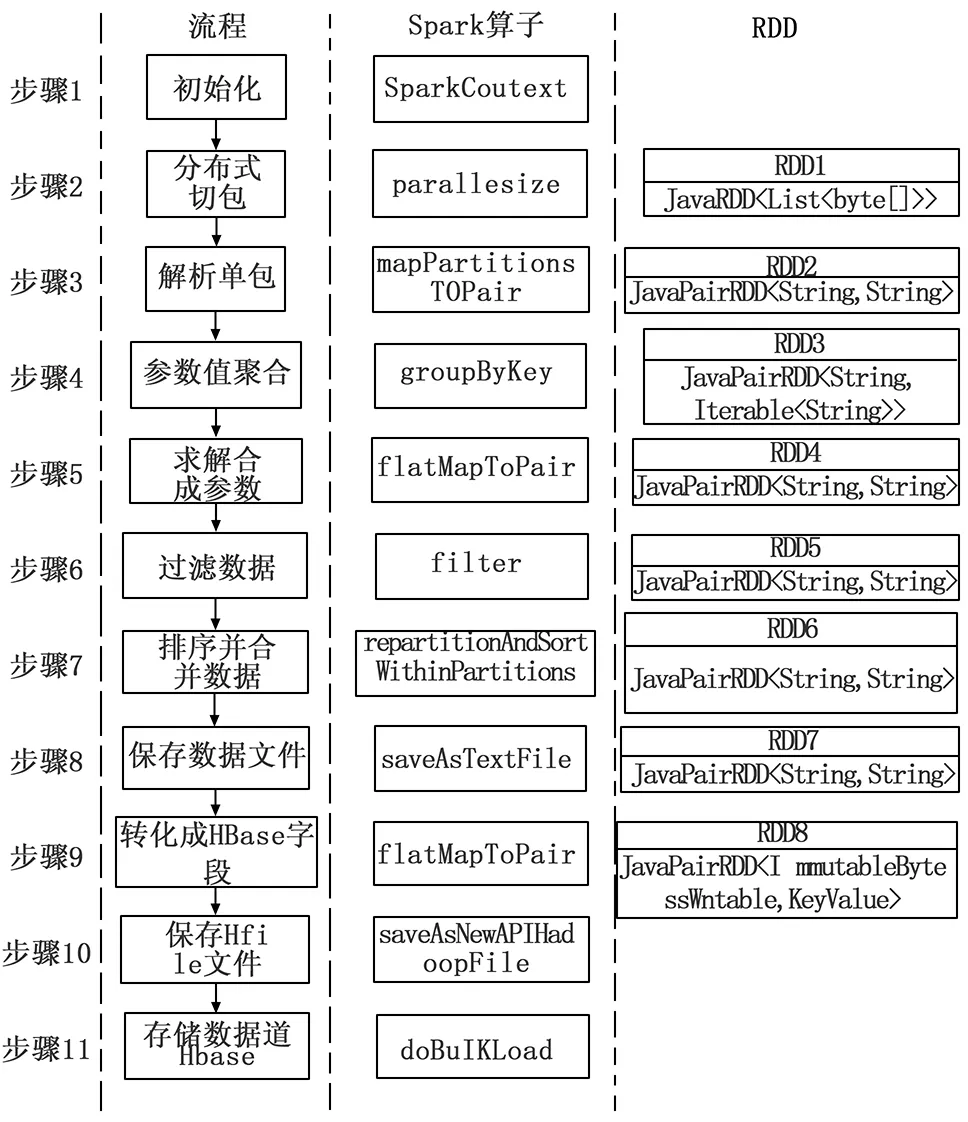
图6 基于SPARK的数据处理流程图
基于SPARK的数据处理具体步骤如下:
步骤1:初始化。包括共享变量初始化,通过解析配置文件,获取参数信息和协议解析规则,并打包成广播变量作为集群共享信息,同时初始化累加器,作为分布式运算过程中不同线程之间数据通信的媒介;以及待解析数据初始化,将源码数据文件的上传到HDFS,并按照1 GB一个单元进行预先切包。最后还对spark环境进行初始化,指定基本的参数配置,保证spark的高效运行。
步骤2:分布式切包。将上传到HDFS上的数据加载到分布式内存中,在加载的过程中,同时将数据每隔N(一般可以设定为1000)个帧切一次包,并将所有切后的包重组为K(一般可以设定为2000)份,设定为每份启动一个线程,进行分布式处理。将加载到分布式算子中。一部分数据将打开一个线程。创建数据结构为JavaRDD
步骤3:解析单包。根据步骤一中初始化的广播变量信息,解析帧头,获取帧头的标识信息,根据标识以及解析的配置文件获取当前帧采集的参数以及参数属性,进而将源码帧数据解析成工程值数据。期间,待解析的参数组范围之外的参数直接跳过,保证解析速度的最大化;此外,整个解析过程通过mapPartitionsToPair算子执行并行处理,各个线程共享广播变量,尽可能的避免不同线程在运算过程中的shuffle操作,减少线程之间由于通信导致的延迟。该步骤获取的数据格式为JavaPairRDD
步骤4: 参数值聚合。对步骤三得到的结果进行聚合操作,执行groupBykey算子,将key(参数组+时间)相同的value(参数位置+参数值)聚合在一起,得到当前参数组当前帧时间的所有参数数据集,并将数据集根据参数组规定的顺序组成长字符串,以便获取同一采样时间点的参数值,便于进行事后试验数据的关联分析。最终获取到的数据结构为JavaPairRDD

图7 主机配置
步骤5:求解合成参数。有一些参数需要一些基本参数经过一定的运算法则转换才能获取,如两个参数的加减乘除运算、位权重运算、EU转换、多项式计算等。所以在将基础参数工程值解析出来后,需要找到合成参数需要的基本参数相同时间点的数据集,然后经过算法运行,得到合成参数的值。其结果形式与步骤5产生的结果一致。
步骤6:过滤数据。针对不同的参数组,需要分别导出到不同的文件中,以保证不同试验科目的独立性,便于不同专业的专家对数据进行分析。然后以参数组+时间字符串中的参数组为过滤条件,使用filter算子,筛选出所需的参数组数据集,由于执行的是filter算子,得到的RDD数据集数据结构没有变化,结果形式与步骤5一致。
步骤7:首先需要对整体数据进行全局排序,以保证所有数据能够以时间顺序进行排列。此时数据是分布式的散播在内存中,为了将参数组数据以规定的数据格式导出,需要将内存中所有的相关数据合并在一起,使用repartitionAndSortWithinPartitions算子,将partitioner参数设置为1,即得到合并后的数据。由于只是数据的合并,所以RDD结构仍然不变,为JavaPairRDD
步骤8:保存数据文件。 使用saveAsTextFile算子,将步骤7得到的合并结果保存到HDFS的文件系统中,每个参数组都分别形成独立的文件系统,通过服务的形式分发给不同试验科目的专业人员,进行进一步的数据分析。
步骤9:转化为HBase字段。预处理的数据需要进行卸载,一方面以系统文件的形式分发给专业人员,另一方面需要持久化存储到分布式数据库HBase中,以便时候的随时查询和进一步的分析,通过flatMapToPair算子将步骤6的RDD数据集转化为满足HBase特定形式的JavaPairRDD
步骤10:保存HFile文件。由于实际产生的数据量过大,直接存储到HBase容易出现内存溢出问题,并且消耗时间较长。故而采取先转存为HFile文件的形式进行HBase存储,使用saveAsNewAPIHadoopFile算子将数据集转化为HFile文件。
步骤11:存储到HBase。通过doBulkLoad方法将HFile文件转化为HBase数据,进而完成送源码数据到工程值数据的处理工作。
3 实验验证
3.1 实验环境
实验环境部署在有3个物理服务器的集群中,其中一个服务器既作为主管理节点,又作为计算节点;另一个服务器作为备管理节点和计算节点;最后一个服务器作为计算节点,具体环境配置如表1所示。

表1 实验环境配置
试验数据来源于某型号飞机试飞过程产生的数据,数据量为30 GB。将试验数据分成三份,分别在三台主机上进行预处理。
3.2 实验结果分析
基于Spark的飞机试验数据预处理结果,如图8所示。数据切包、单包解析、参数聚合、参数合成、数据存储所需时间约为30分钟。传统数据处理平台数据预处理时间则需要9小时。相较于传统数据处理方法,本文提出的数据预处理方法大大提高了解析效率,克服了传统数据处理方式效率低下,单个机器内存和CPU等硬件条件不足的问题。

图8 各阶段处理时间
主机一运行线程333个,各线程累积执行时间2.3 h,解析工程数据文件9.5 GB;主机二运行线程331个,各线程累积执行时间2.3 h,解析工程数据文件9.5 GB;主机三运行线程336个,各线程累积执行时间2.3 h,解析工程数据文件9.7 GB。各线程执行时间最小为5 s,最大为55 s。数据垃圾回收时间最小为0 ms,最大为32 s。各线程处理原始数据最小为3.6 MB,最大为11.3 MB,解析数据输出大小最小为17.2 MB,最大为42.2 MB,如图9所示。尽管本文提出的方法相较于传统方法,大大提高了数据解析效率。但各线程负载不均衡,未充分利用系统资源,影响系统运行性能,对数据解析时间产生一定的负面影响,这也是后续需要进一步改进的地方。

图9 飞行测试数据预处理记录
4 结论
本文针对海量飞行数据预处理方法处理效率低、处理周期长等问题,提出了基于Spark的飞机试验数据预处理方法,并以某型飞机30 GB的试飞数据为例进行实验验证,结果显示本文提出的数据预处理方法相较于传统的大规模数据预处理方法可有效地缩短数据预处理时间,提高处理效率,帮助用户快速做出下一步试飞决策。未来将重点研究数据倾斜调优与Shuffle调优的问题,优化Spark的性能,进一步提高数据解析效率。
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
材料与冶金学报(2022年2期)2022-08-10
温州大学学报(自然科学版)(2022年2期)2022-05-30
现代电子技术(2022年8期)2022-04-13
心理学报(2022年4期)2022-04-12
体育科技文献通报(2022年1期)2022-01-15
能源工程(2021年6期)2022-01-06
建材发展导向(2021年12期)2021-07-22
建材发展导向(2021年23期)2021-03-08
智富时代(2019年4期)2019-06-01
