
基于盲源分离和噪声抑制的语音信号识别
2019-01-07 12:04
计算机测量与控制 2018年12期
(南京理工大学 计算机科学与工程学院,南京 210094)
0 引言
在多个发声者的普适环境中,正确地调整语音识别模型以提高语音识别精度一直是一项挑战。从噪声环境中恢复干净的语音对于语音增强、语音识别和许多其它语音相关应用具有重要意义。在现实生活中,有许多噪声源,如环境、信道失真和扬声器可变性[1]。因此,已经有许多算法用于消除语音中的噪声[2-4]。这些算法大多需要额外的噪声估计,并且只适用于听觉效果而不适用于自动语音识别(ASR)。
本文介绍了一种自优化语音活动检测(VAD)算法,以及信号分离后简单但有效的噪声消除过程,以提高语音识别率。所提出的VAD算法的关键是不需要对干净的语音变化进行先验估计。此外,用于语音/非语音判决的阈值是由噪声本身所产生,即自优化过程。对于噪声去除过程是基于广泛已知的频谱减法(SS)[5],而不需要任何额外的模型或训练过程。最后利用NOIZEUS数据库将VAD算法与SS方法、零交叉能量法(ZCE)[6]、熵权法[7]进行了性能比较。
1 基于SSTFT的盲源分离(BSS)
假设Sn(t),n=1,...,N是未知的语音源,其中N是发声者的数目。M-传感器麦克风阵列的布置是线性的。输出向量xm(t),m=1,...,M可以建模为:
x(t)=As(t)+n(t)
(1)
其中:A表示混合矩阵,x(t)=[x1(t),...,xM(t)]T是接收混合的向量,s(t)包含多个语音源,n(t)是加性高斯白噪声向量,T是转置运算符。
基于上述信号模型的空间短时傅立叶变换(SSTFT)BSS算法的过程如下:
1)计算公式(1)中混合x(t)的STFT,得到每个时频(TF)点(t,f)的M×1向量Sx(t,f):
Sx(t,f)=ASs(t,f)+Sn(t,f)
(2)
其中:下标S表示STFT运算符。
2)基于每个时刻的标准来检测自动源TF点,即TF域中语音源的自动定位:
(3)

3)基于SSTFT的算法的前提是估计源N的数量以及混合矩阵A。本文应用文献[8]中提出的方法,尝试检测一些主导的TF点,即具有主要能量的源点与其他源和噪声能量的点相比较。应用均值漂移聚类方法[9]在不知道源的数量的情况下对主导TF点进行分类。通过对同一簇中的所有TF点的空间矢量求平均来估计混合矩阵A,并且通过计算得到合成簇的数量来估计N。
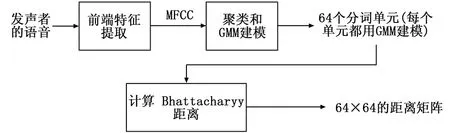
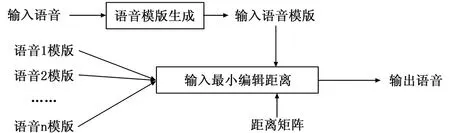
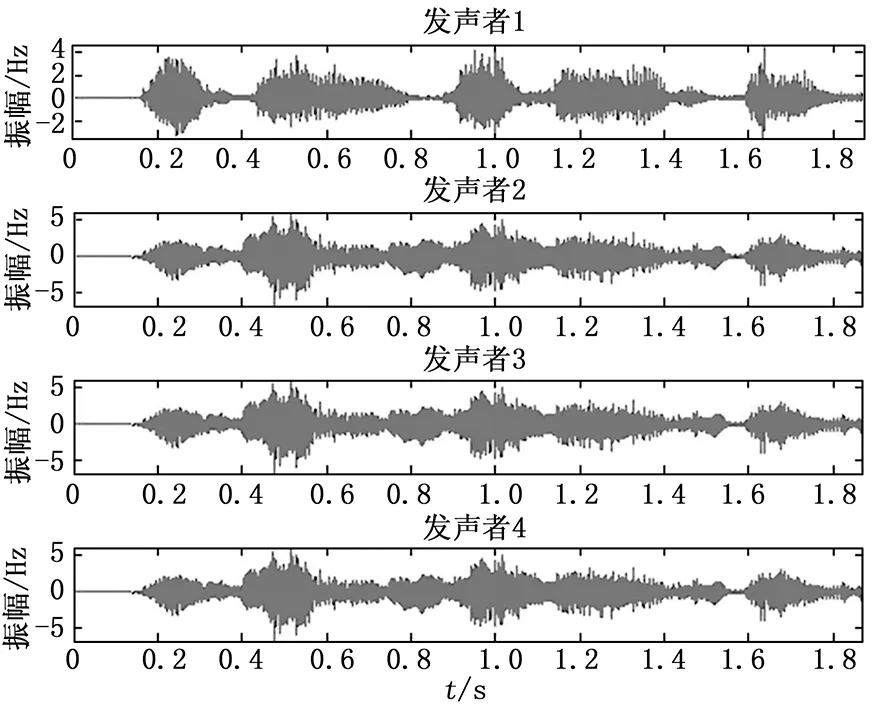
4)基于检测到的自动源TF点集Ω和估计混合矩阵A,应用基于子空间的方法来估计每个源的STFT值[10]。假设在每个自动源TF点属于点集Ω处最多存在K (4) (5) (6) 其中:+表示摩尔-彭罗斯的伪逆运算符。Ω中的每个自动源TF点处的能量分配给相应源的K个STFT值。 6)每个源通过逆STFT[11]利用公式(6)估计的STFT值进行恢复。 噪声和语音通常在统计学上是相互独立并且具有不同的统计特性[12]。噪声更为对称分布且始终呈现,而语音由于其有效/无效周期,通常呈现出非平稳性。语音的主动/非主动转换使语音能量更集中在语音活动期。 噪声和语音的不同行为使得基于语音频谱的最小/最大值来跟踪语音或噪声成为可能。具有高能量的部分更可能是语音,而低能部分更可能是噪声,语音幅度大于噪声幅度,这使得可以通过分析有噪语音的最大值来检测语音。与噪声相比,清晰语音幅度的概率分布函数在“尾部”部分更平坦,这意味着清晰语音幅度更可能远离其平均值。即使对于信噪比SNR=0 dB,也可以证明信号的峰值部分更可能来自语音。 假设语音被不相关的加性高斯噪声所扭曲,VAD的两个假设是: H0:语音缺失:Y=N+R; H1:语音呈现:Y=S+N+R。 其中:Y,N,S和R分别表示来自盲源分离过程的频域噪声话音,噪声,干净话音和残余话音。H0和H1的概率密度函数由下式给出: (7) (8) 本文还需要假设两个条件PN(Y)/P(Y)<ε和PSPN,其中ε是0.01和0.2之间的启发式参数。定义则第一个条件可以简化为: (9) 因此,可以定义: (10) 其中:Yε可以作为更直接的阈值。频率等级VAD标志可以表示如下: (11) 计算语音概率密度函数,可以得到|Yε|2。使用公式(11)实现二进制VAD标志。VAD算法适用于抑制噪声,并且可以有效区分噪声和浊音。为了提高自动语音识别率,本文仍然需要跟踪噪声能量的变化,并更新包括语音帧在内的所有帧的噪声能量。 在VAD算法的设计中,由于语音信号是高度非平稳,软判决算法优于二进制判决。没有明确的边界标记发音的开始或结束,因此,判别信息被用作软判决阈值。 能量计算在逐帧的基础上进行,每个帧乘以适当的窗口以减少来自快速傅立叶变换(FFT)的频率混叠。其中,50%重叠意味着产生帧长度一半的初始延迟,应仔细选择框架尺寸。假设采样率为FS,帧大小为N=2m,时间分辨率为N/FS,频率分辨率为FS/N。显然,较大的帧尺寸可以提供更好的频率分辨率,但时间分辨率较差。通常,对于FS为8 000和16 000 Hz,对应合适的帧大小N分别为256和512。 信号被分为16个子频带。当帧的大小为256时,第i个子频带的能量为: (12) (13) 利用帧能量和子带能量计算基于当前帧和噪声帧的子带能量分布概率来计算识别信息。假设随机变量Y可能是a1,...,ak的值。Y的概率分布与假设H0和H1有关。设P0(ak)=P(ak|H0),P1(ak)=P(ak|H1),判别信息定义如下: (14) 可以利用子带能量分布来计算当前帧和噪声帧的相似性: (15) (16) 阈值通过以下方式更新: 1)选择前5帧为噪声/非语音帧。 2)语音信号周期的前一帧认为是噪声帧。 3)当前一帧确定为是噪声帧时,如果当前帧满足|Y|2≤|Yε|2,则当前帧将视为噪声帧。如果当前帧满足|Y|2>|Yε|2和d>Tr,则当前帧将视为起始位置帧,并与接下来的6帧进行比较。如果6帧也满足|Y|2>|Yε|2和d>Tr,则可以将起始位置帧作为语音周期的起始位置。否则,当前帧仍然认为是噪声帧。 4)当前一帧是语音帧时,如果当前帧满足|Y|2>|Yε|2,则仍然是语音帧。如果当前帧满足|Y|2≤|Yε|2和d 5)在上述确定的每个步骤中,噪声阈值将进行更新: THn=THn-1(1-λ)+|Y|2λ (17) 其中:THn表示第n帧的更新后的噪声阈值,|Y|2为当前语音的概率分布函数值,λ为噪声更新因子,该噪声更新因子由判别信息计算。 6)如果所有数据都已处理完毕,则自适应调整结束。 语音信号Y(w)通常被加性高斯噪声N(w)所破坏。理论上,可以通过估计其功率并使用以下滤波器对噪声信号进行滤波来实现最佳地消除噪声: H(w)=(|Y(w)|-|N(w)|)/Y(w) (19) 本文所提出的VAD将检测噪声帧,并从语音信号中减去噪声谱,试图在ASR的特征提取过程中保留更多的信息,并消除在特征提取和模板匹配期间提供错误信息的噪声。由于语音信号总是非平稳的,所以作出语音或噪声的二元决策变得相当困难。因此,本文通过计算语音活动评分(VAS)来估计语音,当导出的VAS表示语音和噪声的混合时,可以实现平滑的处理转换。 框架下的VAS是由两个方面决定:第一个涉及语音的可理解性,通过计数语音频带中的Bark频带的数量来近似量化,该频带的功率超过估计噪声的相应Bark频带的数量。语音频带范围从第4到第14个Bark频带。第二个是当前帧相对于估计噪声功率的相对功率,帧的相对功率越高,其包含语音的可能性就越大。最后的VAS仅仅是这两个方面的分数之和。将参数ε设置为VAS的倒数并对每个帧进行更新。连续VAS比固定参数提供更大的灵活性。即使需要对帧是否为纯噪声帧进行二元判决,仍然可以在一定的值上处理改变和收敛。 本文将从前端特征提取,由词单元和词模板组成的训练过程以及最终识别过程阐述了整个系统。在VAD和噪声抑制之后,将在ASR系统中对处理后的语音信号进行评估。 用于此识别任务的特征向量是24 MFCC。帧窗口大小为20 ms,语音在16 kHz下采样并具有16 bit分辨率。 训练过程的第一部分要求用户记录他们大约两分钟的演讲。建议阅读语音丰富的句子,以获得更全面的分词单元。在这个实验中,用户被要求阅读一系列哈佛大学经典语录。通过使用C均值算法得到的MFCC聚类为64个不同的单元,大致对应于分词的集合。然后使用4种高斯混合模型对这些聚类中的每一个进行建模。在这个实验中,重新聚类不会在分词模板生成过程中完成。为了简化模型,进一步计算生成64×64的Bhattacharyya距离矩阵。这个过程如图1所示。 图1 分词单元生成 在这一步中,要识别的单词被记录。如图2所示,要求用户对单词进行发音,并且基于最大似然估计方式,模板生成将这些单词转换为子单词单元索引序列。为了避免对单词进行过分割,只有当与相邻状态存在显着的似然差异余量时才允许改变子单词索引,从而采用过渡启发式。用户想要向系统录入每个单词都必须重复该过程。 图2 语言模板生成 假设系统中有M个词模板,识别过程计算由模板生成的用户输入特征向量X输入的概率,则选择的词是最大似然的词: m*=argmaxpm(Xinput) (20) 模板可以看作是高斯混合模型(GMM)序列,这使得随着词表模板数目的增加,pm(Xinput)计算越来越复杂,并且很难观察所提出的VAD算法[13]的效果。本文使用Bhattacharyya距离矩阵[14]将输入特征转换为分词单元索引序列。两个概率分布p1和p2之间的Bhattacharyya距离矩阵为: (21) 测试实验中的每个分词单元使用4个混合GMM建模,因此它们之间的距离为: (22) 使用Levenshtein距离法计算所有64个分词单元的距离。通过原始模式匹配算法的识别任务的平均运行时间与模板的数目成比例地增加。对于Bhattacharyya编辑距离方法,当模板数量增加时,运行时间非常稳定,特别适用于实时识别系统,图3给出了其匹配过程。 图3 识别匹配过程 发声者识别过程与匹配过程相似,有两个主要的区别:(1)只有在发声者识别过程中才加载所选择的说话者配置文件,由于发声者的身份已知。在发声者识别中,对发声者配置文件进行轮询,并将输入与每个发声者的相应激活关键字注册进行比较。(2)不考虑编辑距离,发声者识别过程在给定模板中的GMM分布序列的情况下使用输入的后验概率。这种方法使在设定接受阈值时具有更大的灵活性。 在本文的案例中,使用2个麦克风接收来自4个发声者的混合声音。在分离的信号中,通过使用自动发声者识别选择一个发声者的声音,然后进行隔离单词识别测试。 图4给出了使用上述过程从2个麦克风接收到的信号中分离出4个发声者声音的结果,两个麦克风的噪声混合如图5所示。 图4 从4个发声者中分离出来的声音 图5 由2个麦克风接收的混合语音信号 由图4可见,4个发声者的振幅随时间的变化趋势相似,仅在振幅的数值上有微小差异,说明4个发声者在信号分离过程中有语言重叠部分,但通过分词单元匹配识别,仍然能够分辨出不同发声者的语音信号。图5可见,2个麦克风接收的混合语音信号随时间的变化趋势也相似,也仅在振幅的数值上有微小差异,说明2个麦克风接收混合语音信号过程中可以有效地对噪声进行抑制,更好的接收不同发声者的语音信号。因此,图4和图5分别从盲源分离和噪声抑制两个方面验证了所提出的语音信号识别方法的有效性。 本文将给出ASR系统的结果和客观评价。首先定义信噪比: (24) 其中:S(k)是语音信号能量,N(k)是噪声能量。在这个ASR实验中,车辆和餐厅的噪声来自NOIZEUS噪声数据库。 使用ASR系统进行语音识别测试,提出的盲盲源分离算法是在VAD算法之前实现。文献[15]指出,与麦克风相比,语音源更少的系统可以获得更好的分离效果。将SS方法、ZCE方法和基于熵的方法的性能与在车辆和餐馆噪声环境中提出的VAD噪声抑制方法进行了比较。对于信噪比SNR为0,5和10 dB的情况,在表1中给出了车辆噪声与餐厅噪声内的语音识别精度实验结果,其中,括号内为餐厅噪声环境下的识别率。 表1 车辆噪声与餐厅噪声内的语音识别精度 与在VAD算法中实现精度最高的(基于熵的方法)相比,信噪比SNR=0 dB的情况下的相对改善达到2.5%(1.2%),而在信噪比为5 dB的情况下,改善率为1.4%(0.33%)。整个ASR系统以逐帧的方式工作,满足大多数嵌入式电子应用的实时操作。除了在实验中使用的噪声,使用NOIZEUS的街道噪音也可以获得相似的结果。 本文提出并实现了一种用于普适语音环境的完整语音恢复算法。它能有效地从多个发声者的混合语音中恢复个体发声者的声音。所提出的算法的关键特征是不需要先验信息的来源数量和干净语音方差的估计。用于抑制噪声的阈值是从语音本身生成,从而导致适应变化环境的理想能力。此外,所提出的盲源分离和噪声抑制方法不需要任何额外的计算过程,有效地减少了计算负担。最后,所提出的系统可以容易地在普适语音环境中实现。

2 噪声评估
2.1 噪声描述
2.2 算法推导

3 噪声抑制
3.1 子带能量计算

3.2 阈值更新
3.3 改进的VAD和噪声抑制
4 发声者和语音识别
4.1 前端特征提取
4.2 分词单元生成
4.3 语言模板生成

4.4 匹配过程识别
5 实验研究
5.1 算法应用与分析

5.2 算法评价

6 结论
猜你喜欢
建材发展导向(2022年20期)2022-11-03建材发展导向(2022年12期)2022-08-19建材发展导向(2021年19期)2021-12-06建材发展导向(2021年20期)2021-11-20计算机仿真(2021年6期)2021-11-17校园英语·月末(2021年13期)2021-03-15临床骨科杂志(2020年1期)2020-12-12考试与评价·高二版(2020年2期)2020-09-10智富时代(2019年6期)2019-07-24智富时代(2019年6期)2019-07-24
