
A New Method to Construct Education Knowledge Graph
2019-01-04 09:31ZhiyunZhengJianpingWuZhenfeiWangZhongyongWangLimingWangDunLi
计算机教育 2018年12期
Zhiyun Zheng, Jianping Wu, Zhenfei Wang, Zhongyong Wang, Liming Wang, Dun Li*
Abstract: Learning from the Internet is becoming more and more convenient and attracting more and more people. How to obtain knowledge from massive data and construct high quality knowledge graph has become a research hot topic. This paper proposes a new method of knowledge graph construction based on crowd-sourcing. Firstly, learners build the subgraphs to acquire knowledge through the crowd-sourcing task; secondly, we put forward the fusion strategy of knowledge subgraph, in which knowledge graph is converted into the adjacency matrix, and the weight of the knowledge relation is calculated by matrix operations, thus knowledge graph is constructed. Finally, experiments conducted on an open platform show that the accuracy and integrity of proposed method of constructing knowledge graph are higher and our new method exists potential value for online learning and self-regulated learning.
Key words: knowledge graph; crowd-sourcing; fusion; adjacency matrix
1 Introduction
Internet and education are hailed as two wheels to promote social progress in the 21st century. By taking full advantage of the existing information technology and providing abundant learning resources, E-learning has been integrated into many educational ideas.Hence, various learning patterns, such as MOOC,CSCL (computer supported collaborative learning),knowledge graph, are formed.
This paper introduces the crowd-sourcing technology, and proposes the construction method of educational knowledge graph based on crowd-sourcing.It is mainly to divide the construction of knowledge graph into 2 stages including knowledge acquisition based on crowd-sourcing and knowledge fusion based on crowd-sourcing. Besides, the evaluation methods of knowledge graph under crowd-sourcing mode are offered to make a contrastive analysis.
2 Relevant Work
2.1 Study on knowledge graph
In essence, the knowledge graph is a semantic net and a graphic set of association knowledge, which refers to a large-scale knowledge base in general. In April.2012, Google launched the knowledge graph project realizing a new round of technological change in the search engine. Soon, a series of famous knowledge graphs were constructed, such as Google Knowledge Graph, DBpedia, NELL, Zhishi.me and SSCO, Baidu Zhixin, Sogou Zhilifang and so on. The knowledge graph can display information like knowledge context and development history of the discipline intuitively and vividly, the knowledge graph was mainly applied to scientific research in the early days.
With the continuous development of network information, the knowledge graph has been applied to various fields. This paper mainly aims at the educational field.
Paper[1] full-fledged tutorial videos of math concepts from ordinary people on a Crowd-sourcing website. Paper[2] brought the Concept maps method into the teaching and learning process. Paper[3] learned the conceptual graph via educational data, established the directed conceptual graph with the given relevancy between curricula, and explored the implicit relevancy between curricula by using the induced graph. Paper[4]explored students' conceptions of science learning via drawing analysis, using Activity and Emotions and attitudes categories in students’ drawings to predict students’ learning status. Paper[5] presented a new method, CQUAL, for automatically predicting the quality of contributions submitted to a knowledge base. Paper[6] presented a framework for constructing a specific type of knowledge graph, a concept map from textbooks and outperformed supervised learning baselines to help with concept map extraction. Paper[7]presented booc.io, which was designed from a detailed characterization of domain questions and tasks for educational tools in conjunction with experts. Paper[8]generalized the big data model, learning analysis, data mining, and knowledge graph technology in the field of online education.
2.2 Study on crowd-sourcing
Crowd-sourcing technology has attracted more and more attention since it was proposed in 2006. The crowd-sourcing was defined by its presenter JeffHowe[9]as “the practice of outsourcing the work tasks of a company or institution that were executed by employees in the past to an unspecified public network in a free and voluntary form”.
Crowd-sourcing is that the knowledge and ability owned by every person are valuable for others, and it tries to extract collective intelligence from the masses and to return the masses with this[10]. The crowdsourcing flow covers three stages: task preparation, task execution and answer integration. The task preparation stage includes the following steps: the publisher designs and distributes the crowd-sourcing task; the worker chooses the task. The task execution stage covers the following steps: the worker receives and completes the task, and submits the answer. The answer integration stage involves the following steps: the task publisher receives and integrates the crowd-sourcing answers.
3 Theoretical Study
3.1 Knowledge acquisition based on cr owdsourcing
Knowledge acquisition is the first step to construct the knowledge graph. In this paper, knowledge acquisition is designed as the crowd-sourcing task, involving three steps.
(1) Setting of crowd-sourcing task.|O|metaknowledge points are selected from the field language materials and distributed on the crowd-sourcing platform as original crowd-sourcing task. The metaknowledge point is denoted by O={o1,o2,…,o|O|}, and the difficulty degree D={do1,do2,…,d|o|}of every metaknowledge point is defined.
(2) Execution of crowd-sourcing task. During knowledge association at each time, learner l selects meta-knowledge point oifrom O, and adds knowledge point v which is the most closely linked to oi. Then,by replacing oiwith v, the learner enters the next step of association, and the rest can be done in the same procedure. At last, a knowledge subgraphbelonging to learner l and containing knowledge point oiis formed.
(3) Updating of crowd-sourcing task. The initial crowd-sourcing task includes a part of the knowledge points only, and more knowledge points should be supplemented and updated continuously to provide more choices and help follow-up learners.
When several learners iterate the above processes,we can get the knowledge points set after updating(denoted by V0={v1,v2,…,vm}) and multiple knowledge subgraphs (denoted by. That is,the task of knowledge subgraph acquisition based on crowd-sourcing is completed.
3.2 Knowledge subgraph fusion strategy based on crowd-sourcing
Knowledge fusion is the process to produce a relatively complete and standard group knowledge graph after effectively fusing the knowledge subgraphs constructed by the learners, which are not necessarily comprehensive and accurate. The knowledge subgraph fusion strategy includes four steps: data preprocessing,weight calculation of knowledge points, weight calculation of knowledge association, and knowledge subgraph fusion.
3.2.1 Data preprocessing
In the original knowledge resources gained through crowd-sourcing, nonstandard expressions and colloquial phrases might appear, which affect the construction effect of knowledge graph. Hence, data preprocessing is needed.
We remove the low-frequency knowledge points and filter the noise words, and gain the set of effective knowledge points V={v1,v2, ,vn} and the filtered knowledge points set V -, V - =V0-V={v1,v2, ,vm-n}.
3.2.2 Weight calculation of knowledge points
The weight of knowledge points means the importance degree of a certain knowledge point in the knowledge system. In this paper, the following two parameters are chosen to quantify the weight of knowledge points(in formula 1): the difficulty coefficient of knowledge point and the score of knowledge point given by learners.

Where WVi,tis the weight of knowledge point viat time t, diis the corresponding difficulty coefficient,λ is a default value; α is the time decay factor, and this parameter is introduced to eliminate the weight difference of knowledge points simply caused by different distributing times; β means the score weight coefficient of knowledge point;represents the score of knowledge point vigiven by learner k;indicates the weighted average of learners’score for knowledge point vi; Rksignifies the assessed value for the learning ability of grader k, and its value is shown in formula 2.

Where Ri,tis the value of learning ability of learner i at time t ; every learner’s learning level at the initial time is μ=0; H represents the number of all knowledge subgraphs for the learner to be “bookmarked”; V indicates the number of all knowledge subgraphs for the learner to gain“high opinion”;signifies the average quality score of all knowledge subgraphs established by learner i; x,y and z are corresponding weight coefficients.
3.2.3 Weight calculation of knowledge association
The knowledge linkage represents learners’ cognitive process, and the weight of knowledge association indicates the importance of relevancy between two knowledge points, reflecting their correlation in the knowledge system. In the paper, the weight of association between two knowledge points is calculated through analyzing whether the two knowledge points are related in different knowledge subgraphs and combining with the quality of knowledge subgraph, as shown in formula 3.

Where WE(Gk,vi,vj) means whether knowledge points viand vjinvolve edge connection in a certain knowledge subgraph Gk. If there is an edge, the value would be 1; else, it would be 0. WE(vi,vj) represents the weight on edge after knowledge subgraph fusion; it is the scores sum of all knowledge subgraphs containing ei,jin S, where WGkis the learner’s score of subgraph k,defined as following.
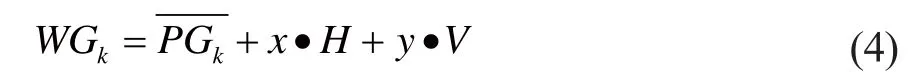
3.2.4 Knowledge subgraph fusion strategy
The knowledge subgraph fusion strategy is established via adjacent matrix operation of graphs.
(1) The knowledge subgraph is transformed into adjacent matrix form of subgraph, and is defined in formula 5.

If graph Gkcontains edge ei,j, the value of Ek[i][ j],in its adjacent matrix Ekis 1; otherwise, the value is 0.
(2) The set of ineffective knowledge points V -generated after preprocessing is subtracted from the adjacent matrix of subgraph, and the learner’s score WG is a set as the subgraph weight. Weighted summation is conducted for the adjacent matrix of subgraph, to gain adjacent matrix WE,and the element is defined in formula 6.

In essence, adjacent matrix WE is the matrix of knowledge graph after fusion, and WE[i][ j] is the weight of relation between viand vj. If WE[i][ j]>0, then edge connection exists between knowledge points viand vj.
(3) Weight calculation is conducted for effective knowledge points contained in the knowledge graph according to formula 1, to gain the weight matrix w of knowledge points, and it is defined as following.

Through the above matrix operation, the knowledge subgraph constructed by the learner can be fused, to generate the logical structure of group knowledge graph, denoted by G=(V, E,WV,WE)in which V means the set of effective knowledge points, E indicates the set of undirected edges, WV represents the set of weights in knowledge points, and WE signifies the set of weights in edge.
Now, the construction process of a knowledge graph based on crowd-sourcing is almost completed. First,it distributes meta-knowledge points to the crowdsourcing platform as keywords in the form of crowdsourcing. Then numerous learners will participate in this crowd-sourcing task, fully express the powerful“human” ability of semantic comprehension and knowledge summarization, and conduct knowledge association by starting from keywords to construct their own knowledge subgraphs. Besides, these knowledge subgraphs will be processed in 4 steps covering data preprocessing, weight calculation of knowledge points,weight calculation of edges, and knowledge fusion.The formation of a knowledge system is promoted via“collective” intelligence, and a complete knowledge graph G = (V, E, WV, WE) is gained.
Finally, using an algorithm diagram to summarize the procedure so as to deepen comprehension. The main scientific problem of this paper lies in two aspects: subgraph acquisition and subgraph fusion. The specific algorithm is as follows.

4 Experiment and Analysis
In this paper, the field of software development in IT industry is chosen as the target field of experimental study. According to the statistics, till May 2013,there had been nearly 3,000 IT training institutions which include about 40,000 courses. At present,IMOOC has more than 15 million users. Numerous online learners have provided a strong manpower support and rich data source for knowledge resource acquisition of this experiment. This paper aims to help students reinforce learning better and teachers teach contrapuntally in the field of online education,and uses the computer science as an example to demonstrate its application value. Figure 1 shows major contents of the knowledge graph in software development field.

Fig. 1 Knowledge graph exhibition on software development domain.
4.1 Rating evaluation on the ability of learners
The learning levels of 84 learners in this experiment are quantified according to the quality of knowledge subgraphs submitted by the learners. They are divided into 4 levels covering 0—40%, 40%—60%, 60%—80%, and 80%—100%, as shown in Fig. 2.

Fig.2 Rating evaluation on the ability of learners.
As shown in the figure above, if the rank level is under 2, students need to continue to study and through comparing and analyzing the self-knowledge maps and the group knowledge maps, which is better to locate and make up the deficiencies. At the same time, the teacher can adjust the course progress according to the number of students whose learning quality percentage was less than 60%. If the number of unqualified people accounts for more than 50% of the total, the teacher may take a certain period of time to review the weak points of failed learners and provide targeted explanations.
4.2 Comparison between the r esults of knowledge graph construction
There is no uniform knowledge structure and evaluation criterion in this field, so the knowledge graph constructed is evaluated by the following method. Our knowledge association is compared w i t h t h e s e m a n t i c dictionary Hownet Knowledge Database and artificial construction results respectively.
(1) Comparison between knowledge graph and Hownet Knowledge Database (keenage.com).
Founded by Mr. Dong Zhen-dong, Hownet[11]is a Chinese commonsense knowledge base describing the relation between concepts and between the attributes of concepts. The weights of knowledge association in the knowledge graph shown in Fig.3 are compared with semantic similarities in Hownet, as shown in Table 1.
Knowledge linkage weight can be semantically understood as the relevancy between knowledge points. According to Table 1, the knowledge relevancy gained via our method can match human intuition and professional characteristics in most cases.
(2) Comparison between knowledge graph and Words-240 (manually annotated data set).

Fig.3 Comparison knowledge relationship's importance with Words-240.
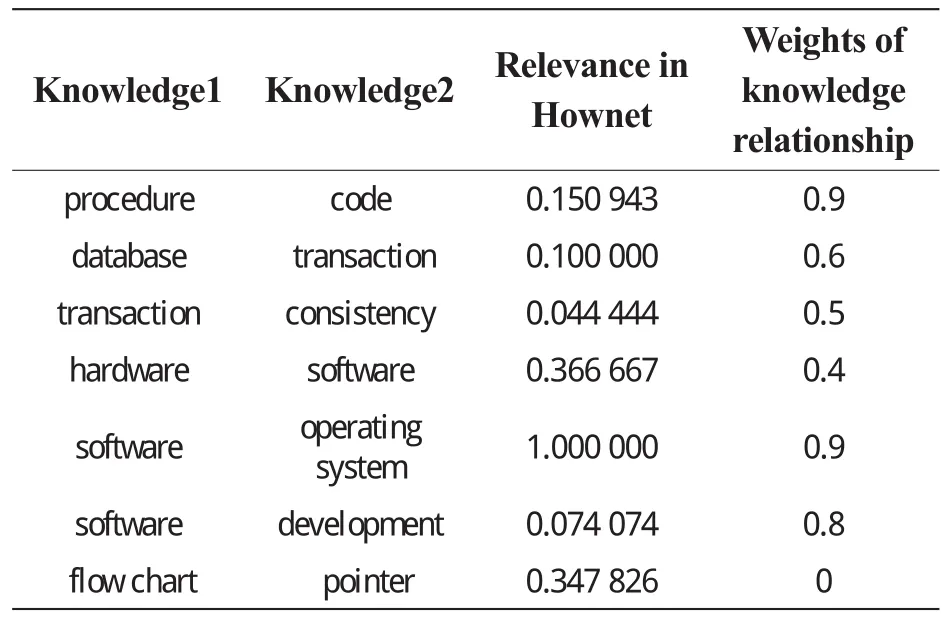
Table 1 Comparison of knowledge relationship's importance with Hownet.
Words-240 is a test set of Chinese semantic relevancy released by scholars like Wang Xiang in 2011. It is completed by entirely relying on manual annotation, and contains the largest vocabulary in the existing test sets of semantic relevancy. We compare it with our paper shown in Table 2.

Table2 Comparison of knowledge relationship's importance with Words-240.
According to the contrast data in Table 2, knowledge relevancy gained on the basis of knowledge graph technology is almost the same as the manually annotated vocabulary and semantic relevancy, showing that the knowledge graph of software development field based on crowd-sourcing almost accords with manually annotated results, so its reliability is comparatively high.
Since Words-240 contains much knowledge of other fields, an additional experiment in the Words-240 data set was conducted to verify the universality of our method. The comparison of construction results of this paper and Words-240 is shown in Fig. 3.
After calculation, if the knowledge point relevancy is defined in [0,1], the standard deviation of our results and Words-240 results is S=0.148, and Spearman’s correlation coefficient of the two results is 0.835. In Fig. 3, the relevancy is accurate to 0.001 in Words-240. Owing to the calculation and graph aesthetics, the weight of knowledge association is accurate to 0.1 in this paper. If the in fluence of accuracy on the experiments is ignored, it can be seen in Fig.3 that knowledge relevancy obtained by our method shows the same overall trend with manually annotated results of Words-240, and their results are similar, which meets the expected goal of low standard deviation and high correlation coefficient.It shows that the efficiency of our method is as good as that of manual annotation method, but our method needs much lower human cost than manual annotation method,so its extendibility is high.
5 Conclusion
In the reform trend of “internet + education” industry,under the guiding ideology of connectivity learning concept of e-learning (“learning is equal to knowledge linking”) , the learner’s initiative and participation degree in the learning process are emphasized, and the individual intelligence is extensively mined via crowdsourcing in this paper. Besides, the knowledge graph,a new knowledge representation mode, is adopted,and an in-depth study is made on the construction of knowledge graph in educational field based on crowdsourcing technology. The evaluation mechanism for learner’s ability and learning outcomes based on knowledge graph is formulated, and the graphical database is brought into the visualization process of knowledge graph, providing a new idea for online learning and autonomous learning.
The platform in the paper is currently in the initial stage. It analyzes students’ behavior data, aiming to allow learners to perform subjective initiative, integrate the learned knowledge, and form a knowledge context system to help learners understand their own learning situation and locate and make up the deficiencies. At the same time, it can help teachers understand the students'mastery and track the course progress. The student behavior data also includes the number of login, online duration, video browsing, job submission, interactive question answering, etc. In the future work, classroom interactions will be gradually added, and the weak knowledge points of the curriculum will be statistically assessed, to make the online education more humanized.
Acknowledgment
The authors are grateful to the editors and reviewers for their suggestions and comments. This work was supported by National Social Science Foundation project (17BXW065), Science and Technology Research project of Henan (14430051007), Reform Research Project of Higher Education of Henan(2014SJGLX007) and Science and Technology Research project of Zhengzhou(141PPTGG368).

- 计算机教育的其它文章
- Iterative Case-Driven Method and Practice of Java Language Teaching
- The Reform Scheme of Practice-Courses Cooperation Training Pattern of Software Engineering Major of Overseas Chinese Universities
- Evaluating students’ learning situations using“Four-quadrant law”
- The MOOC/SPOC Based “1+M+N”Multi-University Collaborative Teaching and Learning Mode: Practice and Experience
- Practice and Study of Training Model for Professional Master Degree in Software Engineering
- Construction and Practice of Cloud-based Experiment and Innovation Project Supporting Platform for Computer Science Education