
一种两阶段联合哈希的协同过滤算法
2019-01-02 05:27:44张辉宜侯耀祖
计算机工程 2018年12期
张辉宜,侯耀祖,陶 陶
(安徽工业大学 计算机学院,安徽 马鞍山 243032)
0 概述
个性化推荐技术由于能为用户推荐感兴趣的内容,提高用户的使用体验,进而增强用户粘性以及用户的忠诚度,已经得到很多大型互联网公司(如Amazon、Alibaba、Tencent等)的广泛关注和深入研究。
协同过滤是推荐系统中流行的技术之一,其主要思想是相似的用户会偏好相似的项目,它主要利用用户过往的行为如评分、点击等信息,无需关注项目的内容。协同过滤还具有新异推荐、对用户友好等特点,因而受到研究者的青睐,得到广泛研究。常见的协同过滤算法主要分为2类:一类是基于模型的方法,利用数据挖掘和机器学习等技术在数据集上训练出模型,然后基于模型为目标用户对未评分项目的偏好度进行预测,从而完成推荐;另一类是基于内存的方法,通过计算用户之间或项目之间的相似度,利用相似度来获取用户或项目的近邻,对近邻评分加权来预测用户对未评分项目的评分,进而实现对用户推荐,文献[1]对这2类方法进行了详细的介绍与总结。近年来,矩阵分解技术因为其在扩展性及预测准确度方面的优势得到广泛关注[2-3]。矩阵分解技术通过分解用户评分矩阵,得到低维的用户和项目的特征向量,利用用户和项目特征向量的点积来衡量用户对项目的偏好程度,使用户和项目向量的维度得到降低,且其利用特征向量的点积来取代传统的相似度计算,因此推荐效率得到较大提高。
然而,随着系统中数据量的极速增长,用户对项目的评分数据呈现海量高维的特点,这对传统的协同过滤算法提出了严峻的挑战。一方面,由于数据的体量增大、维度增加,评分数据表现出高稀疏性,这导致传统的相似度方法在计算用户或项目的相似度时不够准确,近邻检索准确度低,预测精度低;另一方面,体量和维度的增加也带来了计算和存储开销的极速增长,导致推荐系统的效率下降。
本文在分析前人工作的基础上,提出一种两阶段联合哈希(Two-stage Joint Hashing,TSH)的协同过滤算法。从用户或项目视角上应用主成分分析(Principal Component Analysis,PCA)[4]技术,采用迭代量化哈希(Iterative Quantization,ITQ)[5]的策略,得到保留该视角分布信息的二值码,然后由已得到的二值码和评分信息来约束用户与项目的海明距离,得到另一视角的二值码。
1 哈希学习相关研究
协同过滤系统为目标用户在项目集上检索偏好的项目,这个过程可以看做是一个相似性检索问题:检索用户感兴趣的项目[6]。尽管传统的相似性度量,如Jaccard相似系数、余弦相似系数和欧式距离等,已经广泛使用在推荐系统中,但是其在高维海量的数据上计算量过大且对于高稀疏度数据的相似度计算精度低。研究表明,哈希学习[7]在相似性检索方面有独特的优势,它通过机器学习机制将数据映射成二进制串的形式,能够显著减少数据的存储和通信开销,从而有效提高学习系统的效率[8]。哈希学习学到的二值码能保持原空间中的近邻关系,其在快速相似性检索领域的应用具有强大的生命力,已经被广泛应用到信息检索[9]、计算机视觉[10-11]和推荐系统[12-14]等领域。
迭代量化哈希算法是最有代表性的哈希算法之一,由于它最早考虑到不同维度信息量分布不均问题,并且提出对主成分分析后的低维特征进行迭代量化的策略,因此在检索性能和速度上都取得较大的提高。其主要思想为:
1)在原始空间上应用主成分分析技术对高维样本进行降维,将其高维特征映射到低维空间,得到低维空间的特征表示。记X为原始空间数据,降维后的维度为c,W为投影矩阵,V为应用PCA后得到的原始高维数据的低维表示,V=XW。
2)对V量化进行编码,考虑到数据方差分布不均的问题即投影后的低维数据可区分性差,直接对V进行量化无法很好地代表样本的真实分布情况,因此ITQ算法提出数据旋转的策略,若W为最优的投影矩阵,则WR也是如此,其中R为c×c的正交矩阵,基于此对PCA降维后的样本进行旋转,使旋转后的数据在各个主方向上方差尽可能的均衡,建立如下损失方程:
(1)
其中,B为期望得到的哈希编码。求解式(1)可以通过随机初始化R,固定R求解B,再固定B求解R的步骤迭代进行直至达到局部最优解。
ITQ算法具有计算复杂度低、检索性能高的优点,在解决传统的协同过滤算法应对海量高维数据时性能不足的问题上有独特的优势,但它也有一个明显的缺点,即为提升检索性能所做平衡方差的工作会造成信息量的丢失,这在推荐系统稀疏评分数据上尤其明显,因此直接从用户和项目视角上应用ITQ算法会损失大量信息,影响推荐性能。
针对上述问题,本文提出一种两阶段联合哈希的协同过滤算法,既可以利用ITQ算法的优点,又结合系统中数据的性质改善ITQ算法的缺点,使得ITQ算法能更好地应用在推荐系统中。
2 本文算法
假定系统中的用户数量为m,项目数量为n,用户对项目的评分构成的评分矩阵为S∈m×n,其中,Sij表示用户i对项目j的评分,分值越高表示用户越偏好该项目,向量ui=(Si1,Si2,…,Sin)为用户i的向量表示,向量vj=(S1j,S2j,…,Smj)为项目j的向量表示,哈希后的用户空间为U:{u1,u2,…,um}∈{-1,1}c×m,哈希后的项目空间为V:{v1,v2,…,vn}∈{-1,1}c×n。tr(.)表示矩阵的迹,‖.‖F表示矩阵的Frobenius范式,sgn()为符号函数,输入大于等于0时输出1,反之输出-1。
2.1 基于用户视角的两阶段联合哈希算法UTSH
基于用户视角的两阶段联合哈希算法的主要阶段如下:
1)在用户视角进行降维,将用户映射到低维空间,应用PCA技术得到c位用户的特征向量,对之量化即可得到c位用户的二值码。为了减少量化过程的信息损失,引用文献[10]中的迭代量化策略,具体的流程如下:
(1) 在用户空间应用PCA,得到c位用户的特征向量f1,f2,…,fn∈F。
(2) 建立量化过程的损失方程:
(2)
其中,R为正交的旋转矩阵,量化后的用户空间为U,随机初始化R后,交替执行如下2个过程直至得到局部最优解,从而得到最优的U:保持R不变,按照U=sgn(FR)来更新U;保持U不变,对UFT进行奇异值分解(Singular Value Decomposition,SVD)为PΩQT,其中,P为c×c阶酉矩阵,Q为m×m阶酉矩阵,按照R=PQT来更新R。
2)通过系统中的评分来约束用户与项目的海明距离,即以用户与项目在低维空间中的相似度来预测用户对项目的偏好程度。参照文献[6]中用户ui与项目vj的相似度定义,如式(3)所示。
(3)
其中,I()为指示函数,如果条件为真则返回1,否则返回0。由上面的定义可知,当用户与项目的海明距离越小时,相似度越接近1;海明距离越大时,相似度越接近于0。基于这个性质可以建立如下的损失方程:
s.t.V∈{-1,1}c×n
(4)
在约束条件下,直接由式(4)求解最优的V是一个NP-难问题[14],在此引入辅助集合V’={X∈Rc×n|X1=0,XTX=nI},距离d(V,V’)=minX∈V'||V-X||F,基于式(4),可得:
s.t.V∈{-1,1}c×n
(5)
通过调整足够大的参数α,使得X逼近V即d(V,V’)=0,进而将难以求解的V的离散约束转移到连续的容易求解的X上,由约束条件的性质,式(5)可化简为:
s.t.V∈{-1,1}c×n,XTX=nI,X1=0
(6)
将求解V、X的问题分解为求解V和X的2个子问题,交替优化这2个子问题直至收敛即可求得V的最优解。
在求解V的子问题中,保持X不变,对于vj∈V有:
(7)
其中,Rj为S中已知的用户对项目vj的评分集合。由于vj的值是离散的,故采用逐位更新的策略更新vj,更新规则同文献[14]如下所示:
(8)
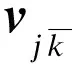
对于X的子问题,保持V不变,由式(6)可得:
argmaxXtr(VTX)
s.t.XTX=nI,X1=0
(9)
UTSH算法描述如下:
输入评分矩阵Sm×n,二值码位数c,权衡系数α
输出用户的二值码Uc×m,项目的二值码Vc×n
1)F←PCA(S)
2)随机初始化正交矩阵R
3)交替执行(1)、(2)直至收敛
(1)U←sgn(FR)
(2)(P,Q)←SVD(UFT),R←PQT
4)初始化V,X,将S放缩
5)交替执行(1)、(2)直至收敛
(1) for j=1 to n :
重复以下过程直至收敛
for k=1 to c :
(2)构造中心矩阵C
6)返回U、V
2.2 基于项目视角的两阶段联合哈希算法ITSH
基于项目视角的两阶段哈希算法先从项目视角哈希,再通过评分约束用户与项目的海明距离,进一步得到用户二值码的算法,由于其过程与上述基于用户视角的两阶段哈希算法对称,在此不再赘述。
3 仿真实验
为验证算法的有效性,对UTSH、ITSH、ITQ和二值化的矩阵分解算法BinMF[15]进行仿真实验。其中,ITQ分别在用户和项目视角上哈希来获得用户和项目的二值码;BinMF为二值化的基于交替最小二乘法的矩阵分解算法,即对矩阵分解算法生成的特征表示以中位数作为阈值进行量化,得到用户和项目的二值码。
3.1 数据集
仿真实验数据选择MovieLen-1M数据集[16]。MovieLens-1M数据集共包括6 040个用户对3 900部电影的1 000 209个评分,可以看出只有约4%的用户-电影存在评分。评分是从1到5的整数,评分越低表示用户对该电影的偏好程度越低,反之,评分越高则表示用户对该电影偏好程度较强。通常,从数据集中随机选取80%的记录作为训练数据,余下的记录作为测试数据来验证算法效果。实验选取归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)[17]来作为评估指标,这要求过滤掉数据集中记录过少的用户,以确保这一指标的有效性。本文过滤掉评分个数低于5个的电影的评分,并且选取评分个数超过20个的用户,每个用户的80%记录作为训练数据,余下的20%记录作为测试验证数据。对数据集进行5次同样比例的随机划分,并取5次实验结果的均值用来评估。
3.2 度量标准
通常的推荐算法采用均方根误差(Root Mean Square Error,RMSE)来评估算法的性能,这个指标衡量算法在训练集上生成的预测评分与验证集中真实评分的差距。然而在现实的推荐系统中,通常只为目标用户推荐预测评分较高的项目,而预测评分低的项目通常不会被推荐给用户,因此,RMSE在推荐任务上并不是一个最优的度量标准。
本文选取文献[17]中提出的NDCG作为实验的度量标准,它是一个建立在折损累计增益上的指标。具体来说,对于任意一个用户,算法为该用户返回的前K个推荐结果在验证集中的实际评分为{r1,r2,…,rK},则对应的折损累计增益为:
(10)
根据该用户在验证集中的实际评分,选取其中最大的K个评分并按照降序排列,即为理想的项目评分{R1,R2,…,RK},由此可计算此用户的理想折损累计增益为:
(11)
最终,可以得到该用户的归一化折损累计增益为:
(12)
在接下来的实验中,计算在不同算法上所有用户的NDCG值,并取均值进行比较。
3.3 实验结果及分析
实验的结果如图1、图2所示,其中,图1显示在进行top-K推荐时,K=5场景下各算法的NDCG值,图2显示在进行top-K推荐时,K=10场景下各算法的NDCG值。
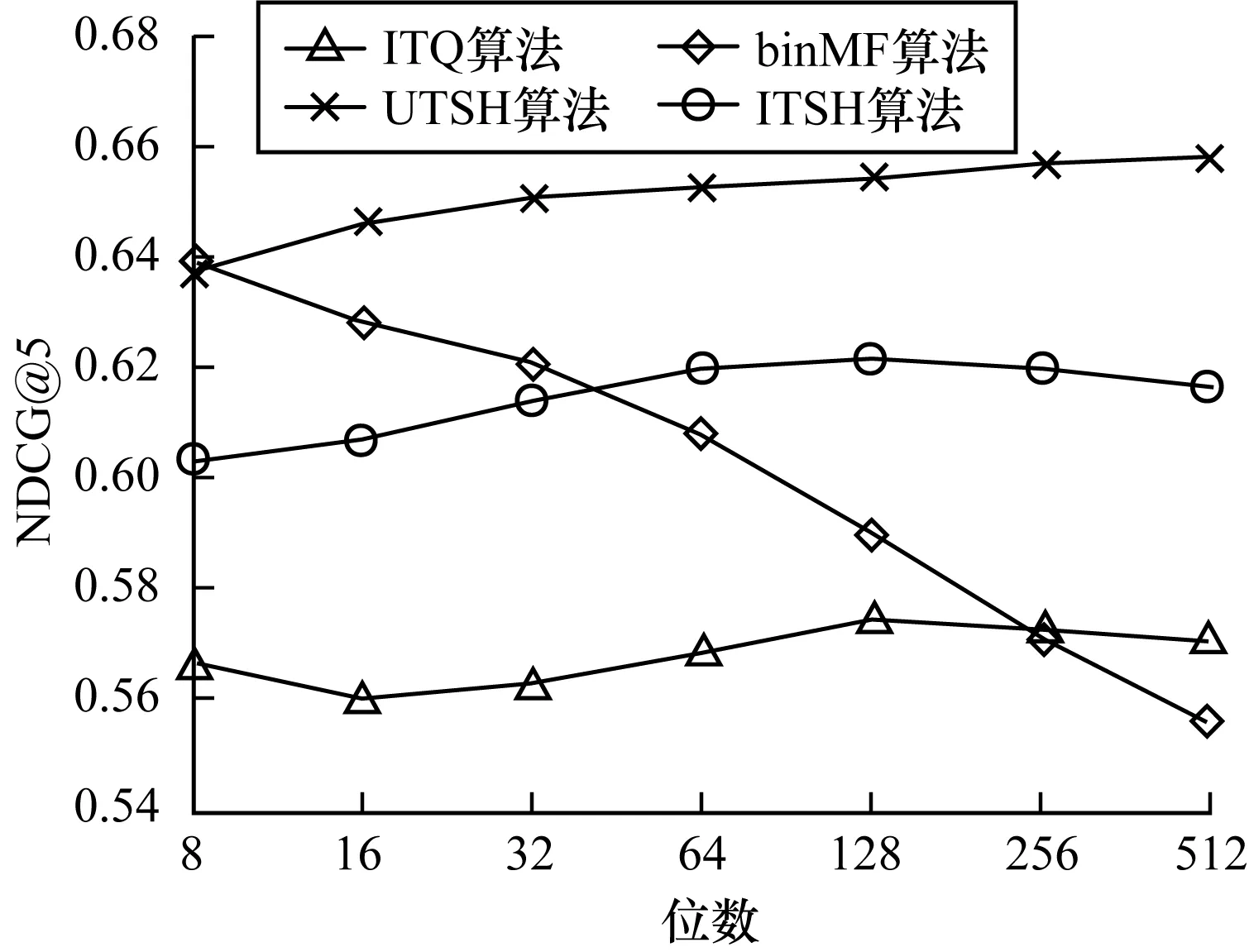
图1 top-5推荐时各算法的折损累计增益比较
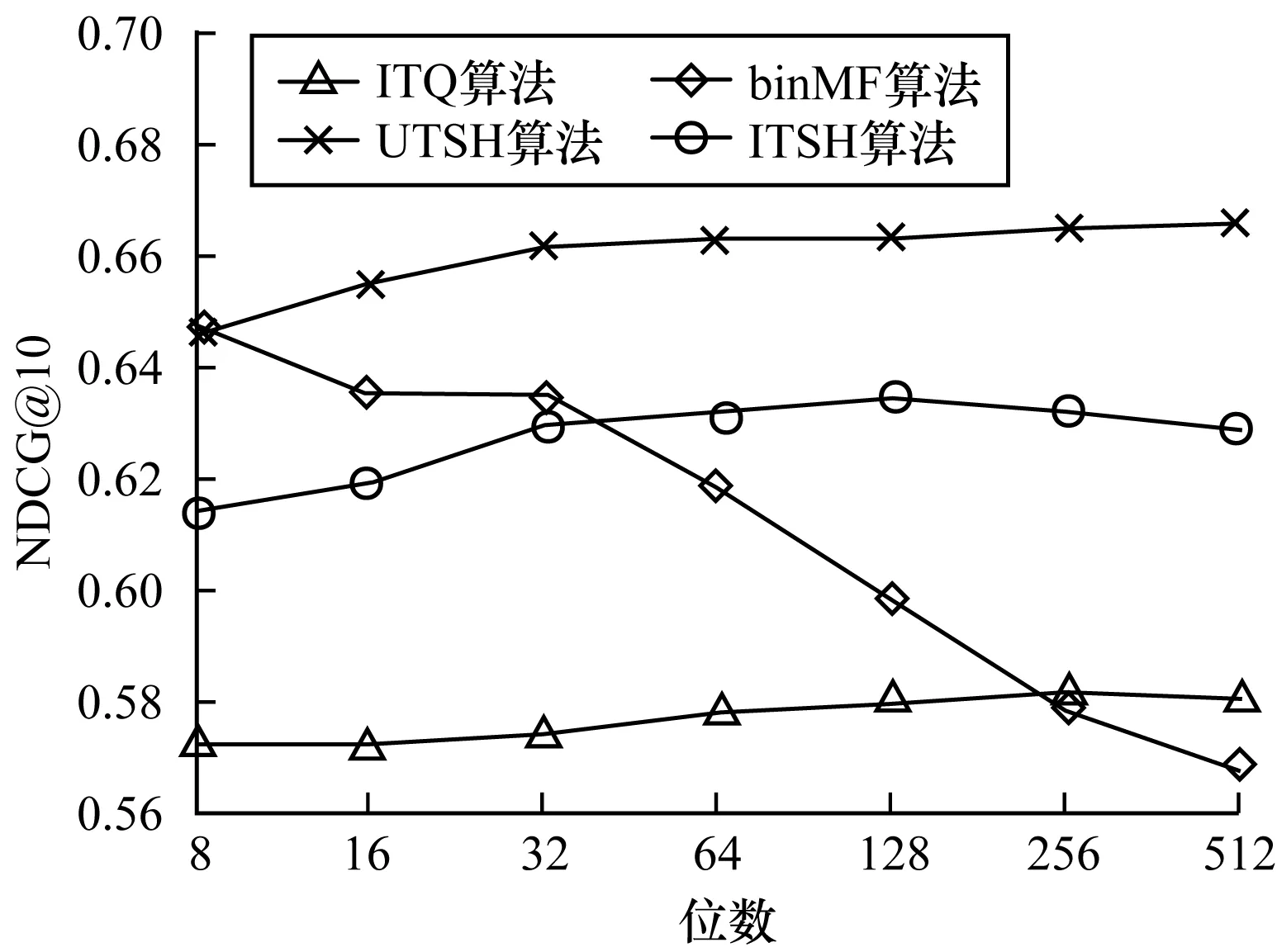
图2 top-10推荐时各算法的折损累计增益比较
从图1、图2可以看出:
1)UTSH算法的NDCG值高于其他算法,其曲线增长平缓,在小于128位时就有较高的NDCG值,反映了该算法受编码的位数影响较小,且用较少位数的编码就能取得较好的性能,表明UTSH算法的推荐性能较好而且存储代价小。
2)BinMF算法的性能随着位数增加呈现明显的下降趋势,一方面是因为训练集的稀疏性导致算法在量化阶段损失大量信息,另一方面是NDCG着重衡量top-K推荐的质量,而BinMF算法着重于对整体未知评分的预测,由此可知其在高稀疏性的数据集上进行top-K推荐任务中的表现不如本文算法。
3)对3种哈希算法,在NDCG@5情况下,ITSH算法比ITQ算法提高7.53%,UTSH算法比ITQ算法提高12.69%,实际上,ITSH算法与ITQ算法在项目视角的哈希学习过程是基本一致的,性能上的差异体现在用户视角上采用的监督式哈希方法,由于数据的稀疏性,直接在评分数据集上应用ITQ编码会损失大量的信息,为了保留更多的评分中的信息,ITSH算法在第二阶段用评分约束用户与项目的海明距离,通过监督式的哈希算法获得了高效的用户编码,同理,UTSH在项目视角采用监督式的哈希算法,也取得了更好的性能。
4)UTSH算法比ITSH算法的NDCG高出了5.58%(在NDCG@5情况下),这说明数据的稀疏性对ITQ算法的性能的影响较大,也进一步体现了两阶段哈希算法的优势,TSH算法不仅充分的利用评分数据的信息,而且针对评分数据各视角的稀疏性特点进行针对性的处理,进一步提高了推荐的质量。
4 结束语
本文提出先对用户或项目视角进行哈希,然后用评分来约束哈希后的距离,再对另一视角进行哈希编码的方法。该方法第一阶段从数据的其中一个视角挖掘其潜在特征,有利于捕捉数据的全局结构信息;第二阶段对另一视角进行逐位编码,又有效地利用了数据在该视角内的局部结构信息。两阶段联合哈希的协同过滤算法将传统的相似度计算问题转化为高效的二值码检索问题,大幅减少了计算和存储开销,能够有效降低稀疏性对推荐性能的影响,同时也为利用除评分外的信息来编码提供可能,有利于进一步提高推荐系统的性能。然而,本文所做的工作仍然是完全依赖于评分数据的,没有将评分以外的信息加入到编码过程中,对推荐性能的提升有限。因此,利用好评分以外的信息来生成二值码以解决稀疏性问题,将是下一步的工作。
猜你喜欢
黑龙江大学自然科学学报(2021年4期)2021-11-19 07:05:10
高技术通讯(2021年2期)2021-04-13 01:09:46
测控技术(2018年10期)2018-11-25 09:35:28
计算机应用(2016年10期)2017-05-12 15:22:34
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
工业设计(2016年8期)2016-04-16 02:43:34
南都周刊(2015年1期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年4期)2015-09-10 07:22:44
计算机工程(2015年8期)2015-07-03 12:20:04
