
基于特征权值的缺失数据修复方法
2018-12-27 11:35郑洁
无线互联科技 2018年20期
郑 洁
(贵阳职业技术学院,贵州 贵阳 550081)
近年来,数据挖掘技术得到了蓬勃的发展,人们能够从海量的数据信息中提取或“挖掘”出有用的知识,这些知识可提供给相关领域使用,因此,将数据挖掘技术看作是信息技术自然演化的结果[1]。在现实生活中,我们面临着各种各样的数据问题,通常,我们将数据预处理作为进行数据挖掘的一个前期工作。缺失数据的处理问题作为数据预处理领域的一个研究热点[2],为了能够更加充分地利用已经搜集到的数据,对缺失数据的处理是非常必要的。
1 特征权值计算
Relief算法以类内和类间的距离作为基础来评判该特征属性的重要性,作为一种重要的机器学习方法,广泛应用于数据的特征选择、分类等方面[3],本文的研究工作是在基于Relief算法的思想上来求解属性特征权值。
对于一个含有决策属性的数据集,假设x是数据集合中的任一个样本,如果x'是与同类距离最近的样本,y是与x异类距离最近的样本,考虑x与x',y的距离在各个特征上的投影,记为pin(a,x,x')与pout(a,x,y),其中a是属性特征集合中的一个特征。对于连续型的数值变量,Relief算法给出了计算特征权值的规则:
其中:pin(a, x, x ')=| x -x′|, pout(a, x, y) =|x -y|,初始化特征权值wk= 1/m;对于数据集中每一个样本数据按照公式(1)更新每一维属性权值,即可输出属性集的特征权值

2 基于属性权值的数据修复
在壳近邻计算方法(Shell Neighbors Imputation,SNI)中[4],我们把每一个选择出来的左、右近邻对数据修复的结果影响程度看作是相同的,但实际上,由于每一维属性的重要程度是不同的,因此,我们将特征权值引入数据填充计算,采取如下公式:

3 实验与结果分析
3.1 预测准确率和数据缺失率
为了说明本文提出的修复方法的有效性,我们引入一个衡量预测准备率的参数:均方根误差(Root Mean Square Error,RMSE),它的定义如下:

其中:ei是原来的属性值,是填充值,n是数据集中缺失值的个数,对数据进行填充后,通过计算得出RMSE的值可以验证数据的修复效果,RMSE的值越大,表示预测准确率就越低,即数据的修复效果越不好,相反则说明修复效果越好。
3.2 实验方法与数据集
本章的实验数据来源是UCI标准数据集[5]中的两个真实数据集,为了测试预测的准确率,我们选择完整的数据集,每次随机地将其中部分的数据设为缺失,对其进行填充后,再与原本的值一起计算RMSE的值来比较修复效果。每一个数据集上进行500次实验,表1是实验数据集的基本信息。

表1 数据集基本信息
3.3 实验结果与分析
将本文提出的修复方法与壳近邻计算方法分别在表1描述的两个真实的UCI数据集上进行模拟实验,结果如图1—2所示。
根据上述实验结果,我们可以得到以下结论:
(1)随着数据集中数据缺失程度不断提高,两种填充算法计算所得的RMSE的值会逐渐增大,即数据填充准确率随着数据缺失率的增加会逐渐降低。尤其是当数据缺失率超过20%以后,两种算法数据修复的准确率明显下降。

图1 Iris数据集上的填充效果对比
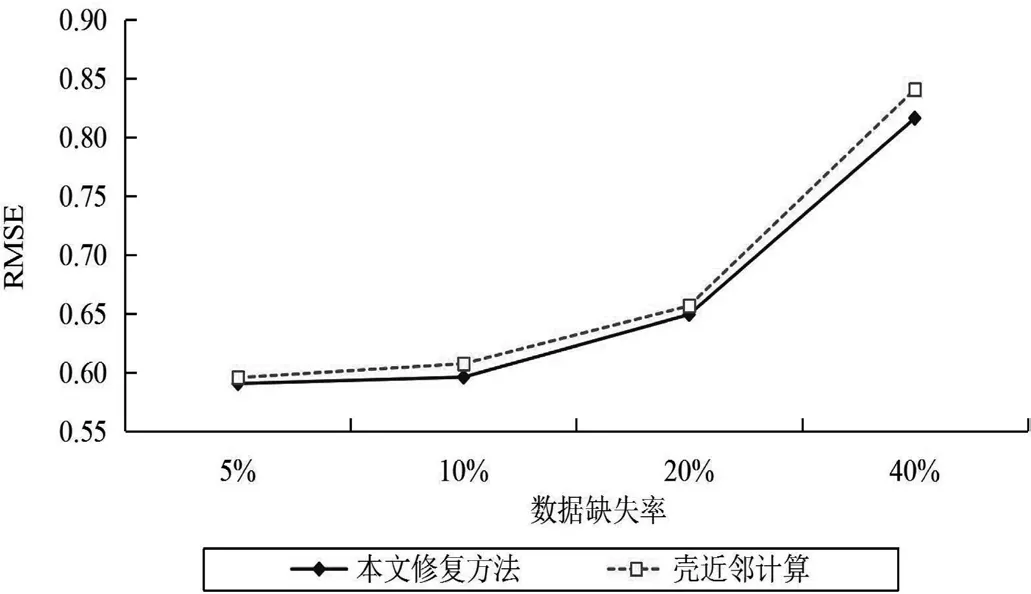
图2 Pen-Based数据集上的效果对比
(2)在大数据集Pen-Based的RMSE值明显小于小数据集Iris的RMSE值,也就是说,我们可以认为在数据缺失率相同的情况下,数据集越大,计算过程中可以利用的已知信息会越多,由此可能会使得缺失数据的修复准确率更高。
(3)在两个数据集上,本文提出的方法对缺失数据修复的效果都优于SNI,由此我们可知:如果对属性的特征权值计算合理,将其引入数据填充计算中,可以提升数据修复的效果。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2017年5期)2017-11-23
电力与能源(2017年6期)2017-05-14
自动化学报(2017年7期)2017-04-18
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
