
基于深度学习的简历信息实体抽取方法
2018-12-22 07:40黄胜,李伟,张剑
计算机工程与设计 2018年12期
黄 胜,李 伟,张 剑
(1.重庆邮电大学 光通信与网络重点实验室,重庆 400065;2.北京大学深圳研究院,广东 深圳 518057)
0 引 言
简历是生活中常见的文本,按结构通常可以划分为结构化文本、半结构化文本、非结构化文本。为了从财经人物中挖掘关联信息以便于监管机构维护市场,其中非常重要的一环就是从非结构化的简介文本中抽取相应的信息实体,对其进行结构化处理并建立人物信息数据库,此外企业的人力资源部门同样也需要对简历信息实体进行抽取。现有的信息实体抽取方法主要是通过规则匹配并结合相关的语言学特征定制模板来抽取,然而该方法泛化能力差,开发维护困难,难以应对大数据量且格式自由的非结构化自然语言文本。
为解决主要依赖于规则模板方法的弊端,首先可以将待解析文本处理待标注词序列,通过序列标注算法为待解析的信息实体标记上相应的标签,再通过匹配标签进行解析。在深度学习还没有渗透到各个应用领域之前,传统的最常用的序列标注算法是基于条件随机场(conditional random fields,CRF)[1]模型。CRF作为一种概率图模型虽然其求解的是全局最优序列,但其需要依赖于人工定制的特征抽取模板。深度学习则不同,其可以自主的学习到序列中的特征信息,特别是循环神经网络(recurrent neural network,RNN)[1]已经显示出其在混杂的文本数据中的信息识别能力,但其求解的是局部最优解,并未将标签之间的约束信息引入。
基于以上的论述,本文提出基于长短期记忆网络(long short term memory,LSTM)[2]与CRF联合模型的简历信息实体解析方法。该方法首先通过Word2Vec[3]训练得到词向量表对输入的词序列进行初始化,然后再由双向LSTM层融合待标注词所处的语境信息,输出所有可能标签序列的分值到CRF层,最后由其引入前后标签之间的约束求解最优标签序列,并辅以Dropout[4]方法防止过拟合。
1 简历信息抽取
为构建人物信息数据库需要从人物简介信息中抽取简历信息实体(姓名、性别、现任职位、曾任公司等)。该简介是非结构化的自然语言文本,如下段为简历示例。
北京远特科技股份有限公司,陈**,男,1973年10月出生,中国国籍,无境外永久居留权,研究生学历。1997年至2000年,负责福耀玻璃集团的生产调度和战略规划工作;2000年至2003年在美国俄克拉荷马大学就读;2003年至2007年任美国CBK控股公司营销副总;2007年至今在华瑞集团工作,现任华瑞集团副董事长;2014年4月至今任远特科技董事长。
简历信息实体的标注相较于其它序列标注问题有很大的不同与挑战。首先是简介信息文本往往涉及多领域,多行业,存在很多行业专有名词与表述,而且人物简介信息方面的训练语料也很少。该简介的抽取的另外一个更大的挑战就是需要对长序列依赖建模,有时一个人物可以在同一时间段内在多家公司任职,而且在同一个公司也可以有多个职位头衔,而为了区分相应的现任与曾任相关标签,就需要考虑到整篇简历的信息。图1展示的是利用序列标注方法抽取简历信息的整体流程。

图1 简历信息实体抽取流程
在图1中,信息实体的标注这一环节无疑是最为重要的,在以往的处理方式中,对于中文来说,一般是在分词的过程中引入相关的实体标记信息,但是一般分词工具自带的实体标记功能是通用化的,所含有的标记信息也比较的少。此前已有研究将深度学习应用于自然语言处理中,比如Yao等[5]将循环神经网络与条件随机场混合的循环条件随机场(recurrent conditional random field,RCRF)模型应用于语言理解;Chiu等[6]联合长短期记忆网络LSTM与卷积神经网络(convolutional neural network,CNN)用于命名实体识别;而Ma和Hovy等[7]则在LSTM和CNN联合的基础上又嵌套了CRF,用于英文的词性标注问题;Jagannatha等[8]将RNN应用于医疗文本的序列标注问题中。为此提出深度学习方法应用于简历信息文本的抽取中,将混合LSTM网络和CRF概率图模型的序列标注模型应用于简历信息实体的标签标注环节。
在该混合模型中由LSTM神经网络学习信息序列的特征,输出相应的备选标签概率给输出层,利用CRF层代替LSTM神经网络的Softmax输出层,将邻近标签之间的约束引入最后的标签预测,从而为每个词产生最终的预测标签,最后定制相应的标签匹配规则将信息实体抽取出来。
2 模型及优化
2.1 LSTM
利用多层神经网络的深度学习技术,已经在包括自动语音处理到图像处理中有强大的影响力,特别是近年RNN和CNN已经被应用到语音识别[9]、语言理解、机器翻译、语言模型、人脸识别等任务中。长短期记忆网络是一种特殊类型的RNN,通常也被简称为LSTM,与传统RNN相比较,比如Elman-RNN和Jordan-RNN[1],LSTM已经在序列数据上展示出更好的长距离依赖处理能力,其在本质上和RNN没有什么区别,唯一的不同之处在于LSTM用了一个具有线性激活功能的记忆单元(memory cell)去存储历史信息。这在一定的程度上避免了由于线性记忆单元在任意时间内保留未缩放的激活和误差导数而造成的梯度爆炸和梯度消失问题。图2是一个LSTM记忆单元。
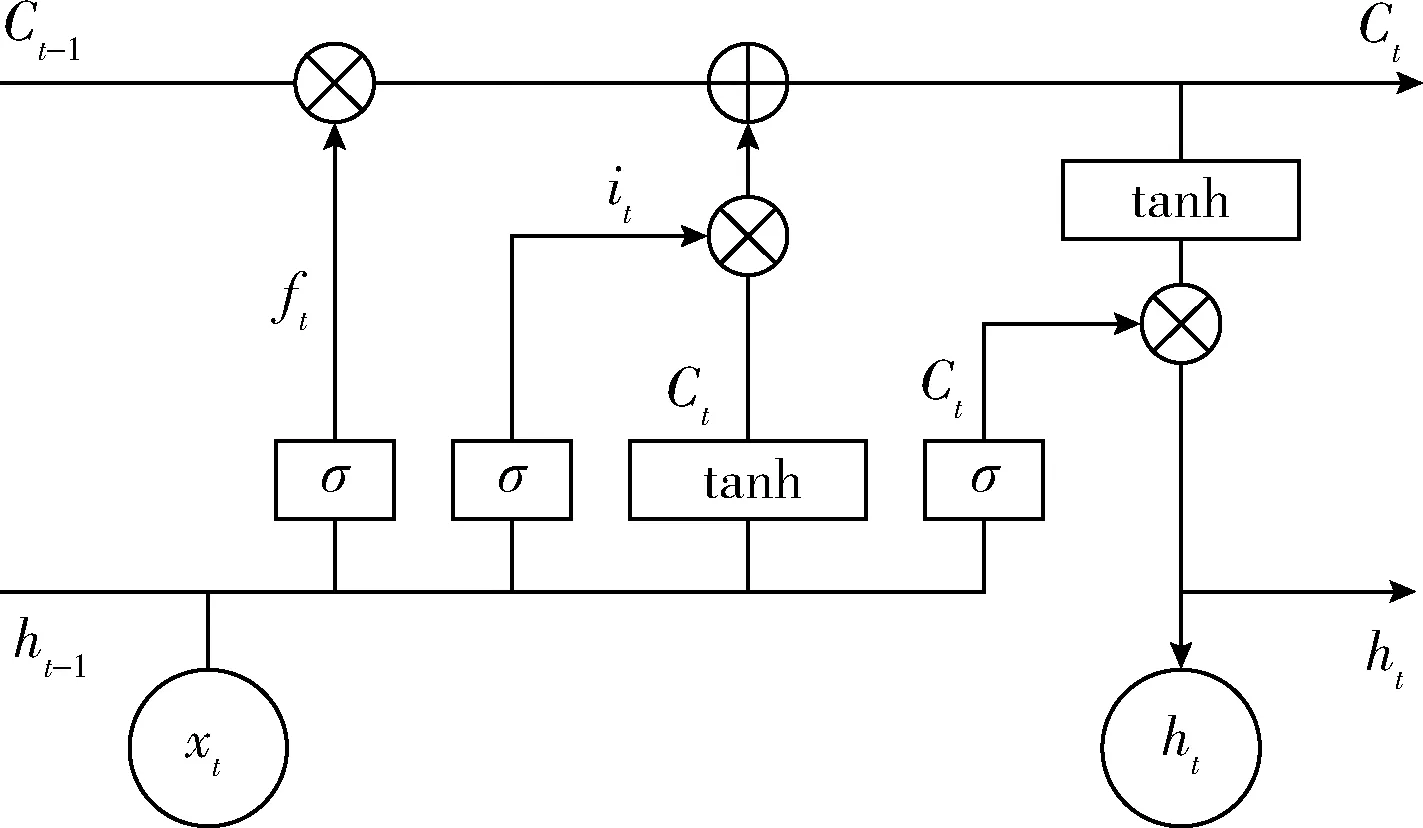
图2 LSTM cell结构
该LSTM记忆单元由式(1)实现
(1)
其中,σ是逻辑Sigmoid函数,i、f、o还有C分别是输入门(input gate)、遗忘门(forget gate)、输出门(output gate)和记忆单元向量(cell vectors),这些向量的维度都与隐藏层向量h的维度是一致。Wi、Wf、Wo分别表示连接输入门、遗忘门、输出门的权重矩阵。
虽然LSTM能更好的处理长距离依赖问题,但是LSTM相应的网络结构也更加的复杂,相应的权重参数也更多,其模型的训练将会消耗更多的时间和空间以及计算资源,同时也需要更多的训练数据支撑训练。尽管该模型在一些比较简单的序列标注问题上取得了比较良好的效果,但是当输出的标签之间存在很强的依赖关系时,其独立的分类决策就有限制了。本文的简历信息实体的标注解析就属于这一类具有强标签依赖的,例如标签B-org.company后面不能直接就是标签I-gsp.company或者I-per.name,像这种情况就不能只根据待标注序列的上下文信息孤立的判别标签,为此还应该将整个序列中标签与标签之间的约束关系引入。
2.2 CRF(Baseline)
为了在预测当前标签中利用到临近标签信息有两种不同的方法,第一种是像最大熵分类器(maximum entropy classifier)和最大熵马尔科夫模型(maximum entropy markov model,MEMM)这样的通过预测每个时间步长的标签分布,再使用相应的解码来寻找最优标签序列;第二种就是像条件随机场(CRF)这种是在整个句子层级的建模,求解全局最优解。CRF和隐马尔科夫模型(hidden markov model,HMM)作为在自然语言处理领域具有丰富应用历史的概率图模型,其经常被应用在分词,词性标记等任务中。尤其是CRF,其是一个非常简单而又非常有效的概率图模型,不同于HMM对P(x,y)联合建模,CRF模型对后验概率P(y|x)直接建模。已有研究结果表明,CRF模型通常有着更高的标注精度,在深度学习没有广泛的渗透到各个应用领域之前,其基本是最主流的方法。
2.3 BLSTM-CRF
根据以上的分析。提出将联合了双向长短期记忆神经网络(bidirectional LSTM,BLSTM)与条件随机场(CRF)的序列标注模型应用于简历信息实体中的标注,该步骤是简历信息实体抽取的关键步骤。
在BLSTM-CRF联合模型中,BLSTM不是直接的输出备选标签,而是将待标记对象与各标签序列对应的分值输出给CRF层,由CRF层引入标签之间的约束对标签序列进行综合选取,与Ling等[10]中提出的模型类似。这个分值是与每个标记对象被标记的标签相对应。该分值由BLSTM计算得到的包含待标注词上下文信息的词向量的点乘得到。该结构如图3所示。为说明这个混合模型,下面将举例。
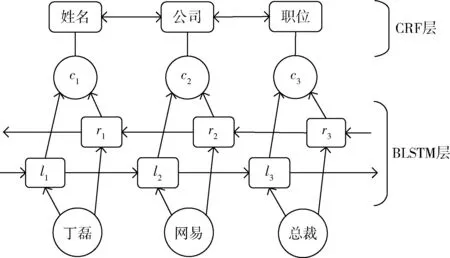
图3 BLSTM混合CRF序列标注模型
(1)假定一条输入词序列为
X=(x1,x2,…,xn)
(2)
在实际的神经网络输入中,其中xi指的是其对应的d维词向量,该向量可随机初始化也可利用训练好的词向量表初始化。
(2)再由BLSTM层中的前向LSTM将词xi及其上文信息计算表征为向量li,同理后向LSTM将反向读取该词序列,且将词xi及其下文信息计算表征为ri,然后再将ri和li两个向量再连接为向量ci,ci= [ri;li]。其中前向LSTM和后向LSTM具有不同的网络参数。该种方法有效的将词以及其上下文信息用向量表征出来,已被应用到多种自然语言处理任务。
(3)定义BLSTM层的输出分值,假定整个网络的输出目标序列(即所对应的标签序列)为
y=(y1,y2,…,yn)
(3)
则分值由以下公式确定
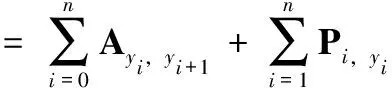
(4)
其中,A是过渡分值矩阵,Ai,j表示的是从标签i过渡到标签j的分值。而其中的P代表的是大小为n×k,双向LSTM的输出分值矩阵,其中k与目标标签分类数相同,Pi,j代表的是单词i被神经网络标注为j标签的分值。y0和yn是这个句子所对应的起始和结束标签,因此A是维度为k+2的方阵。
在所有的标签序列上Softmax生成目标序列y的概率为
(5)
在训练过程中,最大化正确标签序列的对数概率

(6)
其中,YX代表序列X对应的所有可能的标签序列,从上面的表述可以看出训练网络是为了尽量的输出有效的标签序列。在解码的时候,通过由以下公式

(7)
给出的最大分值用于预测最合适的标签序列。可以用动态规划的方法计算方程(6)中的求和以及方程(7)中的最大后验序列y*,因为是对输出之间的相互作用进行建模[11]。
从前面的叙述中,可以得出该模型的参数分别是分数矩阵A,以及双向LSTM的参数,即生成矩阵P的参数,CRF层线性特征的权重和词向量。其中xi表示的是输入序列X中每个词所对应的词向量表示,而其中的yi则是与每个词所对应的标注标签相关联的。使用之前所描述的CRF来引入相邻标签之间的约束,代替此层使用的Softmax输出层,从而得到每个词所对应的最终预测标签。模型训练最终目标使得正确标签的所对应的分值最大,为此对网络进行以训练调整权重使得似然方程(6)所对应的标签概率最大化。
2.4 预训练词向量
在未利用预训练向量初始化向量查询表时,将随机初始化向量表,然后在后续训练中调整参数的同时,得到相应的词向量表。但是在标记训练数据资源比较少的情况下,采用随机初始化的向量表,容易收敛到局部最优解,或者很难收敛。词的向量化表示为每个词提供了连续空间的表征,这些词向量一般是利用大规模的语料库,可以在包含从浅层神经网络到卷积神经网络再到循环神经网络等多种模型上训练生成。
为了训练词向量,首先是需要相应的训练语料库,不同的语料库训练出来的词向量效果是不一样的,为此在本文的实验中选取了中文维基百科(Cnwiki)的语料库和搜狗(Sogou)新闻的语料作为训练数据,经过数据清洗分别得到两个语料915 MB和1.70 GB的正文数据。其次就是训练工具的选择,主流的有Google在2013年开源的Word2Vec以及斯坦福大学开源的GloVe。Word2vec可以在百万数量级的词典和上亿的数据集上进行高效的训练,其训练得到的词向量,可以很好地度量词与词之间的相似性,且其简单高效。Word2Vec主要包含两个算法模型,即连续词袋模型(continuous bag-of-words,CBOW)和Skip-gram[3]。CBOW利用词语的上下文来预测词语,而Skip-gram利用词语来预测其上下文。
在本文的实验中将利用Gensim工具包中的Word2Vec,在中文维基百科语料库和搜狗新闻语料库上以Skip-gram模型分别得到565 MB和390 MB的100维词向量,其中前者包含619 275个词的向量,后者含425 957个词的向量。
2.5 Dropout
深层神经网络包含多个非线性隐藏层,这使得它们成为非常具有表现力的模型,可以学习到输入与输出之间非常复杂的关系。然而,使用有限的训练数据,这些复杂关系中许多都是采样噪声的结果,它们存在于训练集中但是并没有出现在实际的测试集中,这样将导致过拟合问题,使得训练出来的模型泛化能力降低。在本文的实验中,将根据Hinton等[5]提出的Dropout训练方法,即在训练过程中随机的使得双向LSTM输入之前的一些权重不更新(但依旧是连接的),这样可以防止过拟合。
3 实验与分析
3.1 数据集
本文所使用的数据集是从多家上市公司的公开招股书PDF中获取的1000条非结构化的高管简介信息文本,共包含76780个待标注项,其中一条为一个人的简介信息,每条包含150~400个汉字。并根据严格制定的标注规范由多人对其进行标注,避免由于人主观性差异带来的影响。其中标注规范中的13个基本标签见表1,加入IOB信息后则有27个标签。其中B表示的标签的开头,I表示的是实体标签非开头信息,比如“北京大学”对应的标签分别为B-org.school、I-org.school。O指的是其它,即代表非所要抽取的其它信息实体。数据集按8∶1∶1的比例分割为训练集、开发集、测试集。
3.2 评价指标
本文采用准确率(Precision)、召回率(Recall)、F1-Score3种评价指标,其值越高表示标注识别的效果越好,除此以外记录F1-score随着训练Epoch次数的变化曲线
(8)
其中,为了保证实验结果的公平客观,实验结果采取10折交叉验证。将数据集分成10等份,轮流将其中的1份作为测试集,其余9份作为训练数据,并在训练数据中拿出1份作为验证集,用于训练中的模型评估以及Early Stopping,Early Stopping可以防止过拟合和节省模型训练时间。
3.3 实验步骤
本文方法的实验基本流程如下:
(1)数据预处理:对数据集进行清洗,根据相应的xml标签信息将其数据集中的处理标注对象与其对应的标签写入两个二维List(Python数据类型)中,两条List的第一维索引对应的简历的数字ID,第二维分别对应简历对象内容和对应的标签信息,然后使用分词工具对第一个含有简历信息内容的List进行分词,并引入IOB信息。
(2)模型训练:对于上述的神经网络序列标注模型,以反向传播(BP)算法来训练网络,用随机梯度下降(SGD)算法在每个训练样本时调整权重参数,其中学习率的变动区间为0.001到0.06,学习率的选取对结果有重要的影响,如果学习率过大就会导致局部直线化严重,就会丢失很多的细节信息如果学习率过小为了尽量的拟合曲线,就需要更多的样本,学习训练的时间会更长,也容易造成过拟合。在实验过程中,通过多组实验的对比后,学习率设置为0.01为宜。

表1 标注标签以及相关说明
在本文的BLSTM与CRF混合模型中前向和后向LSTM的维度都设置为100,对其进行微调并实验对比发现隐藏层维度对性能并没有明显的影响。词向量表征的维度大小选取与语料库的大小相关,如果维度过大将会导致训练的时间加长,复杂度增加;维度过小将不能完全表征词丰富的语义信息,为此综合多方面考虑以及小组实验的对比,默认设定词向量维度为100。Dropout参数rate设定为0.5,参数设定过小将会导致更长的训练时间,而且也防止过拟合的效果也会降低;然而参数设定过高将会导致非线性拟合不够,降低性能,影响标注效果。
表3中Dr是指Dropout,Pre(S)指使用Sogou语料训练的词向量表,Pre(W)指使用Cnwiki语料训练的词向量表。
实验结果表明,联合了神经网络和条件随机场模型的简历信息实体抽取方法要明显的优于传统的简历抽取方法。首先单纯从表2的实验结果来看,其实传统RNN,比如Elman-RNN、Jordan-RNN并不见得在标注效果上要优于基于CRF的标注方法,因为CRF求解的是全局最优解,而RNN实质上求解的是局部最优解,RNN相对于CRF的优势在于无需人工定制的特征模板,而是由神经网络自动的学习序列内在的特征。而其中LSTM和BLSTM的标注效果要好于RNN,这是由于LSTM在一定程度上缓解了序列的长距离依赖问题,特别是对于简历信息元抽取,需要一次性对整篇的简历文本进行标注识别,但是BLSTM的效果仍比CRF差一些。但是BLSTM与CRF联合方法要明显优于两者单独作为标注模型的方法。

表2 各模型实验结果对比
从表3和图4中可以看出,在该联合模型中添加相关优化方法Dropout和预训练向量,由表2和表3的数据对比可以看出,加入Dropout方法后F1值提升了近2%,原因在于LSTM由于其网络的复杂性增加,权重参数也更多,表征能力也更强,也更加容易出现过拟合,Dropout的防过拟合效果明显。在表3的数据中可以看出在加入Sogou语料库训练的预向量之后,标注的效果反而比随机初始化向量的效果变差了,由于搜狗新闻语料库更加的偏重于新闻类的表述,使得训练的向量带有倾向性,进一步的导致梯度下降时的路径并非最优路径。对于中文维基百科语料训练所得向量的加入提升也比较明显。从图4中的曲线可以看出,预训练向量的加入可以使得训练的提前达到收敛,曲线更加平滑,混合的简历标注抽取模型在训练了大概20 Epoch就可得到最优模型参数,极大降低了模型训练的时间,而且本文提出的方法也比以往的模型方法得到的标注性能F1值提升了近8%的绝对百分比。表4中展现的是利用BLSTM-CRF模型结合了中文维基预训练向量初始化以及Dropout方法的各标签标注性能及占比。

表3 模型优化方法对比

图4 各方法F1值与随Epoch次数的变化曲线

标签PrecisionRecallF1-score占有比pers.name99.48%96.95%98.2011.69%pers.male96.88%96.88%96.883.90%pers.female100.00%100.00%100.001.77%pers.birth100.00%98.80%99.395.00%pers.country100.00%100.00%100.004.75%pers.edu91.03%92.21%91.614.75%pers.school71.05%84.38%77.142.31%org.time82.89%95.45%88.734.63%org.company90.30%97.72%93.8614.43%org.pos87.01%95.65%91.1210.78%gsp.time93.06%88.74%90.858.77%gsp.company82.25%81.90%82.0714.07%gsp.pos85.66%82.61%84.1014.86%
4 结束语
本文提出了一种简历信息实体标注抽取的方法,该方法利用深度学习强大的特征学习能力,特别是LSTM的序列建模能力,由机器自动的获取词序列的特征,并以融合了词所在语境信息的向量来表征词,且由CRF层引入标签之间的约束作全局最优标签预测,并辅以预训练词向量初始化词向量表。实验结果表明,该方法相较于传统的简历实体抽取方法,不仅在标注性能上得到整体的提升,而且可有效避免人工定制特征抽取规则的麻烦、降低实际开发的难度与成本。在当前的大数据环境下,将该方法与云计算平台相结合并引入基于深层神经网络的分词技术,研究出能够高速处理大数据量多领域文本的端到端系统,是下一步的研究方向。
猜你喜欢
工会博览(2022年8期)2022-06-30
医学美学美容(2021年18期)2021-10-21
中国外汇(2019年18期)2019-11-25
车迷(2018年11期)2018-08-30
中国医疗保险(2018年3期)2018-07-14
海峡姐妹(2018年3期)2018-05-09
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
Coco薇(2015年11期)2015-11-09
