
改进的协同过滤算法及其并行化实现
2018-12-22 08:06:16李书琴
计算机工程与设计 2018年12期
李 嵩,李书琴,刘 斌
(西北农林科技大学 信息工程学院,陕西 杨凌 712100)
0 引 言
为了及时准确地获取有效信息,推荐系统不断地发展。其中,协同过滤推荐算法应用最为广泛[1]。然而,随着时代发展,数据量极速膨胀,推荐系统中的数据稀疏性和可扩展性等问题在很大程度上影响着推荐的效果[2,3],因此,国内外相关学者从不同的角度出发,采用不同的方法来解决这些问题。杨兴耀等[4]提出一种基于信任模型填充的协同过滤推荐模型;Guo等[5]提出使用用户信任的邻居评分填充和代表用户偏好;针对算法的可扩展性优化,李华等[6]提出一种基于用户情景模糊聚类,并用Slope One算法填充评分的方法;Wang等[7]通过融合遗传算法改进K-均值聚类,生成推荐;许伟等[8]提出基于聚类与矩阵分解技术结合的方式进行协同过滤推荐;李淋淋等[9]提出用聚类方式生成最近邻居集,并用加权的Slope One算法进行推荐。
上述文献中提出的算法仍存在填充后信息缺失或者聚类提取的信息量不够的问题,也有的算法由于考虑因素过多,导致算法本身较为复杂,执行时间过长。且这些算法往往都忽略了用户兴趣与项目类别之间潜在的偏好关系,没有充分挖掘用户兴趣。同时,以上大部分算法都侧重于单节点实现,随着数据量的指数级增长,单节点计算已经不能满足需求。如今是大数据与云计算的时代,海量数据的多机并行化计算是一个不可避免的趋势。因此,本文提出了基于GROUSE和用户聚类的协同过滤算法,充分考虑用户与项目类别之间的潜在关系,引入类别加权度的概念改进相似度计算,并在Spark大数据计算平台上对算法进行设计与实现。
1 基于项目的协同过滤算法
传统基于项目的协同过滤算法(item-based CF)以评分相似性程度为核心,以最近邻集合为载体进行推荐。算法实现过程主要分为3个阶段,首先构建用户项目评分模型,然后计算项目之间的相似度以产生最近邻集合,最后预测评分产生推荐。具体步骤如下。
(1)建立用户项目评分模型
本文构建矩阵Rmn表示用户对项目的评分,每一个行向量表示一位用户的评分集合,共m个,每一个列向量表示一个项目的被评分集,共n个。矩阵中元素ru,i则表示用户u对项目i的评分。评分矩阵可表示为
(2)计算相似度
相似度计算是协同过滤算法最重要的一步,其目的是为了描述项目间相似程度,产生最近邻集合,其计算结果对推荐精度起着决定性作用。在常见的相似性计算模型中,皮尔逊相关系数因效果较好,最为常用[10],其描述如式(1)所示
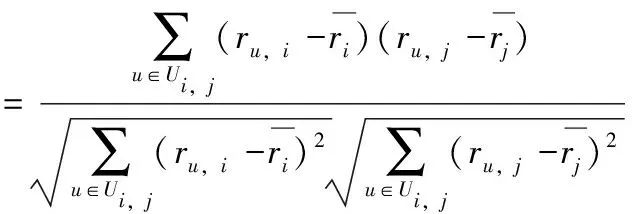
(1)

(3)预测评分
最终依据目标未评分项目与其最近邻中的项目间相似性计算用户对其的预测评分。预测评分模型可用式(2)进行计算
(2)
得到预测评分后,按照Top-N原则对用户进行推荐。
2 基于GROUSE和用户聚类的改进协同过滤算法
本文利用矩阵填充与对用户做模糊聚类的思想,解决上述提到的数据稀疏性和可扩展性问题,并结合两步的处理结果构造目标用户簇类的评分模型;同时,在算法中考虑用户对不同项目类别的偏好不同,提出类别加权度的概念,用以改进相似度计算,在减少计算规模的基础上,有效地提高了推荐精度。本文算法处理流程如图1所示。
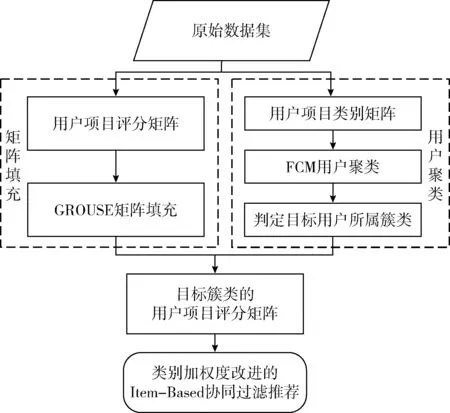
图1 基于GROUSE和用户聚类的改进协同过滤推荐
2.1 格拉斯曼秩1更新子空间估计法(GROUSE)
矩阵填充(matrix completion)是一个是通过寻找近似矩阵来逼近原缺失矩阵的技术。在强不相干条件下恢复低秩矩阵所要求的采样数目是m>Crnlogn,其中m为可观测元素数,r为矩阵的秩,n为矩阵阶数,C是正常数[11]。由于一个用户评价过的项目相比较项目总数来说极其有限,因此用户评分矩阵中可观测元素非常少,可以认为评分矩阵是一个低秩矩阵,具有用矩阵填充的方法解决数据稀疏性问题的可行性。
Balzano等[12]提出的格拉斯曼秩1更新子空间估计法(Grassmannian rank-one update subspace estimation,GROUSE)在相同的采样下,对于高维低秩的数据矩阵,性能比IALM等常用的矩阵填充算法要好[13]。GROUSE算法基于代价函数的最小化,函数定义如式(3)所示

(3)
其中,S是观测到的有缺失点的矩阵的一个子空间。由于GROUSE算法是一个追踪子空间的算法,要适用于整个缺失矩阵的填充,还需要对算法做些改变。填充具体算法流程见表1。

表1 基于格拉斯曼秩1更新子空间估计的矩阵填充算法

(4)

2.2 用户聚类
不同用户对不同项目类别喜好程度不同,为了深入挖掘用户兴趣与项目类别间潜在关系,本文构造m×l的用户项目类别矩阵,并基于该矩阵对用户进行聚类。矩阵可表示为
该矩阵由n个l维的向量ti(i=1,…,n)构成,其中n和l分别是用户和项目类别的数目,矩阵中元素ti,g表示用户i对类别g中项目的评分次数。
在此基础上,本文使用FCM(fuzzy C-Means)算法对用户聚类。该算法的基本思想是同一个用户可以以不同的隶属度属于多个类别,其价值函数表达式如式(5)所示
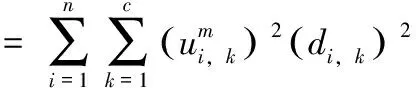
(5)
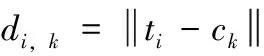

(6)
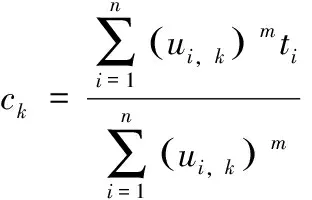
(7)
本文中用户聚类的FCM算法描述见表2。

表2 FCM算法
本文通过FCM算法做用户聚类,有两个优点:其一,通过挖掘用户兴趣与项目类别之间的模糊特性,从本质上体现出两者的潜在关系;其二,在做推荐时,只需要判定目标用户所属簇类,并在簇类内部做协同过滤推荐即可,这种方式能够大幅降低用户项目评分矩阵的维度,减少协同过滤搜索邻居用户的范围,从而减少计算复杂度,有效提高可扩展性。
2.3 类别加权度的概念
传统协同过滤算法仅仅以可观测到的评分数值为依据进行计算,并没有从其它角度挖掘用户兴趣,这种处理方式则会忽略一些有价值的潜在信息。以现实情况而言,用户的兴趣会有所偏好,对于不同的项目类别,用户的偏好程度也不一样。基于该实际情况,本文提出了类别加权度的概念,来表示用户u对项目类别g的喜爱程度。具体的计算步骤如下:
步骤1 计算用户u对项目类别g的评分权重

(8)

步骤2 计算用户u对项目类别g的评分次数权重

(9)

步骤3 计算用户u对项目类别g的类别加权度

(10)
其中,α是类别加权因子。
2.4 基于类别加权度改进的相似度计算

(11)

(12)
根据式(1)和式(12)并结合用户聚类的结果,改进后的项目间相似度计算如式(13)所示

(13)
其中,Ui,j是用户u所属的簇类中对项目i和j都评价过的用户集合。由此可见,类别加权度分别作用在原始评分与填充评分上使得用户对不同类别的电影的评分有了不同的权重,考虑了用户的兴趣偏好,符合实际意义,且将用户集合缩小为目标用户所属的簇类,大大减少了相似度计算量,提高了算法的运行效率,有效提高了算法的可扩展性。
2.5 本文算法的流程
基于上述分析,本文提出基于GROUSE和用户聚类的改进协同过滤算法CF-GUC,结合图1,算法流程如下:
(1)构建用户项目评分矩阵R和用户项目类别矩阵T。
(2)利用表1算法对原始矩阵R进行填充,得到近似矩阵R+。并用R+中元素补充R中相应位置的不可观测元素,R中已有的元素不变,形成完整的评分矩阵R*。
(3)利用表2算法基于用户项目类别矩阵T对用户进行聚类,产生目标用户所属簇类,并与R*中的所有行向量取交集,得到类内评分矩阵R′。
(4)对于矩阵R′,利用式(11)基于类别加权度加权进行计算,得到加权后的类内评分矩阵记为R″。
(5)基于矩阵R″,利用式(13)计算项目间相似性,并产生目标项目的最近邻居集Ki。
(6)根据步骤(5)的计算结果,利用式(2)做评分预测,得到项目评分预测值pu,i。
2.6 算法特性总结
综合上述对本文所提出算法的描述,该算法具有以下优秀的特性:
(1)采用GROUSE算法矩阵填充,每次迭代时更新子空间的时间复杂度极小[13],所需运行时间大大减少,有效地缓解了数据稀疏性;
(2)对用户基于类别权重矩阵进行聚类,充分考虑了用户兴趣的偏好,且在目标用户的所属簇类内进行相似度计算,避免了一些无意义的运算,极大减少了计算复杂度,提高了算法的运行时效;
(3)对于不同用户对不同类别的项目在选择时有偏好这一实际情况,本文引入了类别加权度的概念,深入挖掘用户兴趣与项目类别之间的潜在关系,并从评分高低与评分次数两个角度将权值作用于矩阵填充的结果之上,从而在一定程度上减少直接使用填充值计算所带来的计算误差。
3 基于GROUSE和类别加权度的协同过滤算法在Spark上并行实现
3.1 Spark大数据计算平台
Spark是一个处理海量数据的快速、通用的并行计算框架,其核心是弹性分布式数据集(resilient distributed datasets,RDD)。RDD的最大特点是基于内存计算,可以降低硬盘I/O的带来开销,提高执行效率。理论上利用Spark平台可以突破因为海量数据造成的存储困难与计算复杂度高等限制,是提高系统可扩展性的有效方式。基于Spark实现的推荐算法有以下优点:
(1)所有的运算都基于RDD,其基于内存计算和懒加载的特性,对于诸如相似度计算等需要大量迭代的算法,优势更加明显,能够大大减少推荐算法的执行时间。
(2)Spark支持多种分布式存储结构,如HDFS、S3等,这为推荐系统在数据存储上的无限扩展提供了理论上的可能性,使得推荐系统据可扩展性问题得到有效改善。
3.2 并行算法实现
3.2.1 矩阵填充的处理流程
GROUSE算法在进行矩阵填充时,需要依次对子空间进行迭代,尽管每次更新子空间的代价较小,但是在数据量极大的情况下依然会耗费大量的时间,由于子空间相互独立,因此算法可以在Spark平台上进行并行化的实现,以提高填充速度。本文参考吴文波等[14]关于奇异值分解的并行处理方法的研究,并结合GROUSE算法更新子空间代价函数每次只优化一列的特点,采用如下的填充过程:首先根据数据集构建转置评分矩阵RT;然后将RT按列进行分片,形成多个小的子矩阵;之后利用GROUSE算法分别对各个子矩阵进行填充;最后合并各个填充子矩阵,生成填充矩阵,并与原始矩阵按照式(4)的规则进行整合。
首先读入评分数据到RDD中,通过map操作将RDD中的每条记录转为键值对形式,其中键是用户ID,值是一个Tuple(元组),存储形式为
3.2.2 用户聚类的处理流程
首先构造用户项目类别矩阵,读入项目文件和评分文件,构建
聚类完成后还需要获得目标用户的所属簇类。按照FCM算法最大隶属度原则,找到目标用户最大可能性归属的簇类以及该簇类中的用户集合,并与output1文件生成的RDD通过join操作形成簇类内的评分RDD,命名为c_rRDD。
3.2.3 协同过滤推荐的处理流程
对目标用户进行协同过滤推荐的过程,分为两个阶段:一是对簇类内的评分数据加权;二是进行协同过滤的相关计算。这样在计算的时候就将所有用户数据集缩小为目标用户所属簇类的数据集,达到了降维的目的,避免了一些无意义的计算,处理流程如下:
第一阶段,构造类别加权度,对目标用户所属簇类中的评分数据进行加权。首先,对于评分权重w_ru,j,根据数据集构造
第二阶段,进行协同过滤相关的计算。首先,计算项目间相似度,在式(13)的基础上对c_w_rRDD进行转换操作,计算元组中每个项目的评分均值以及评分与评分均值的差值,输出为平均评分文件output2,用flatMap和aggregateByKey操作进行项目间配对与归并,并通过mapValues进行配对项目间的相似度计算,形成simRDD。然后,计算最近邻,转换simRDD格式为
4 实验与分析
4.1 实验数据集
本文实验数据集来自MovieLens推荐系统(http://movielens.org),其近似数据量描述见表3。每条评分记录包括用户ID、项目ID、评分、时间戳等4个属性,评分为1到5,评分越高表示用户对该电影的喜爱度越高[15]。
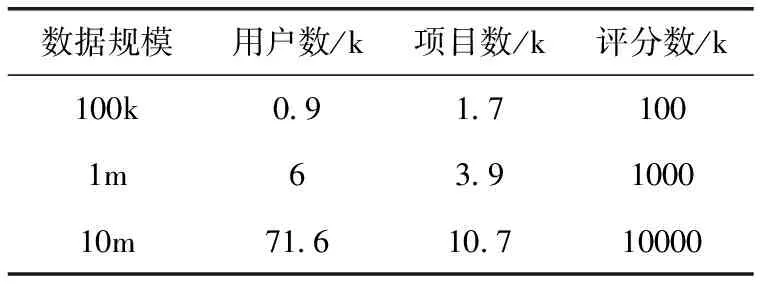
表3 MovieLens数据集描述
4.2 度量标准和实验环境
本文用统计方法中的平均绝对误差MAE(mean absolute error)度量指标来描述推荐质量,MAE值越小,则推荐精度越高。该指标的计算方法如式(14)所示
(14)
其中,pi为预测评分,ri为实际评分。
本文实验所需的Spark环境分为单节点的本地模式和多节点集群模式,Spark版本1.6.1,Linux版本Cent OS 6.5。实验环境硬件配置见表4。
4.3 实验结果及分析
实验1:选取最优类别加权因子α。本文以数据量为100 k的数据集为样本确定参数α,训练集取其中80%,测试集取其中20%。参数确定的原则是通过控制变量,来比较不同α取值时MAE值的大小。图2的实验结果是设置最近邻个数k为50时取得,可以看到,当α=0.4时,本文算法得到最小的MAE值。

表4 实验环境硬件配置
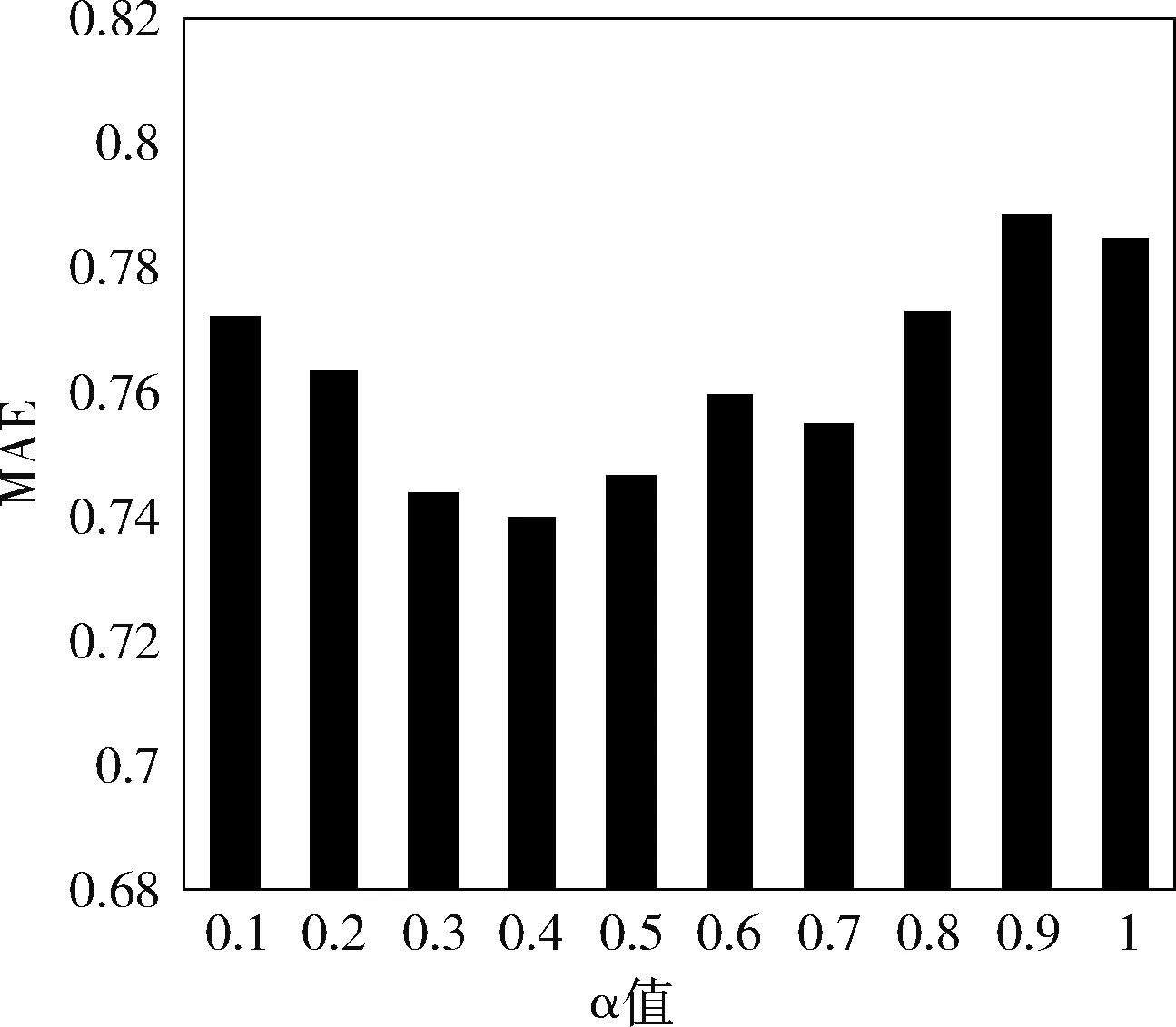
图2 不同α取值下本文算法的MAE比较
实验2:算法对比实验
为了验证本文算法的推荐效果,将本文改进算法与以下几种常见的协同过滤推荐算法进行对比实验:
(1)CF-mean:基于评分均值填充的CF算法;
(2)CF-UC:基于简单用户聚类的CF算法;
(3)Pearson-CF:基于皮尔逊相关系数的CF算法;
(4)CF-GUC:本文提出的改进算法。
按照实验1中参数选取的结果,CF-GUC算法设置类别加权因子α=0.4,图3描述了不同邻居数下以上几种算法的MAE值对比。可见在k>40时,基本所有的算法都趋于稳定。由于本文算法能够有针对性地解决数据矩阵稀疏性问题,且将用户关于电影类别的兴趣进行了更深层次的挖掘,并依照用户兴趣对相似度计算进行了改进,可以看到在实验范围内的邻居数目下,CF-GUC算法相比于其它算法推荐效果要好。当最近邻居数k取30到40时,CF-GUC算法相比于CF-mean算法、CF-UC算法、Pearson-CF算法,MAE值分别降低了约3.31%,3.02%,6.48%。

图3 不同邻居数目下各算法的MAE比较
实验3:算法执行效率测试。实验环境如表4中所描述,比较表3中不同数据集在3种实验环境下的执行时间。实验结果如图4所示。
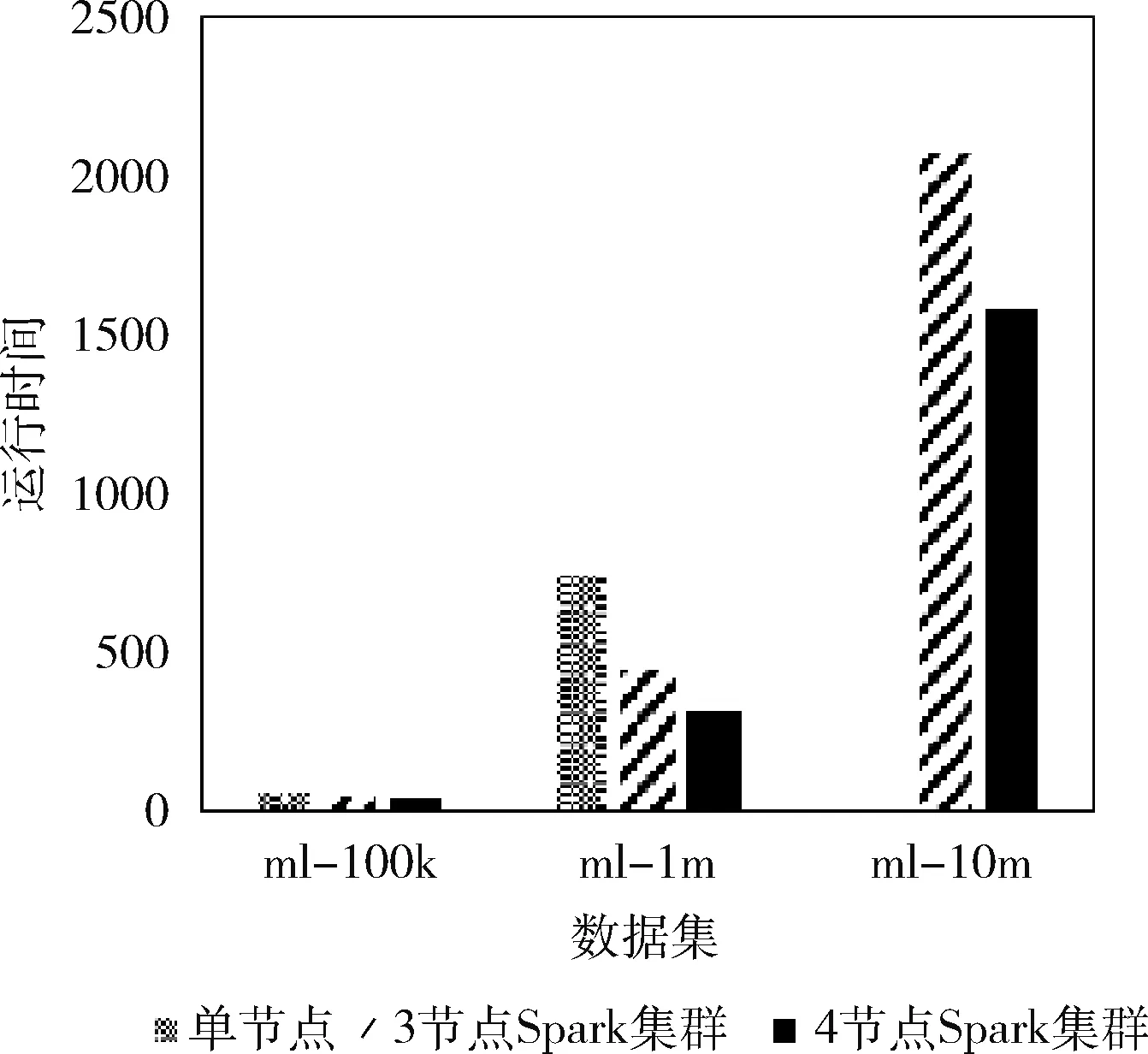
图4 不同环境下本文算法运行时间比较
图4中,纵轴表示本文算法的运行时长,单位为分钟,横轴表示3种规模不同的数据集。从图4中可以观察到,在数据量较小的时候,单节点与两种Spark集群运行时间基本差不多,这是因为Spark集群在计算的时候需要进行任务拆分与合并,这种资源调度消耗了较多的运行时间,因此在数据量较小的时候,集群的优势并不能体现出来,甚至有时候会比单节点执行效率更低。随着数据集规模的增大,集群的优势逐渐凸显出来,特别是Spark基于内存迭代计算的高效性也愈加明显。在ml-1m的数据集上,3节点的Spark集群执行效率比单节点高约40.6%,4节点的Spark集群执行效率比单节点高约58.4%。可以看到,由于ml-10m的数据集规模太大,在单机状态下已经无法进行计算,故没有数据,而Spark集群依然能高效地完成计算任务,且4节点的Spark集群相较于3节点的Spark集群,计算效率仍有提高。但是,这并不能说明集群中节点数越多越好,在数据规模一定的情况下,节点数多了,反而会因为资源调度、网络通信等过程降低执行效率。在实验过程中,笔者还发现,大规模用户聚类以及获得目标用户簇类等过程会耗费大量时间,因此从实际应用的角度出发,对于诸如矩阵填充、用户聚类等可以离线计算的过程,可以放在离线部分处理,能够进一步保证算法的执行效率。
通过上述3个实验可以看出,本文提出的CF-GUC算法在推荐质量上有很大提高,且算法在Spark集群上的并行化执行,极大地缩短了其运行时间,大大提高了系统的可扩展性。
5 结束语
本文以解决传统协同过滤推荐算法中存在的数据矩阵稀疏性问题和可扩展性问题为出发点,提出了基于GROUSE和用户聚类的改进协同过滤推荐算法。算法首先通过GROUSE算法对评分矩阵做填充,以解决数据矩阵稀疏性问题,并引入类别加权度,对评分进行加权;其次,构造用户电影类别矩阵,对用户进行聚类;再次,在协同过滤推荐阶段,在目标用户所属的簇类内进行相似度计算;最后实现了算法在Spark集群上的并行化,通过聚类技术和借助Spark计算平台解决系统的可扩展性问题。
实验结果表明,在同等条件下本文算法在推荐质量方面表现优秀,且通过聚类和算法在Spark集群上实现的手段,使得算法的执行效率也有了大幅提高。但是聚类参数是影响推荐精度的重要条件,Spark的分片以及代码分发等也是影响计算效率的重要因素,这些参数的调优与配置有待进一步实验与深入研究。
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
汽车观察(2019年2期)2019-03-15 06:00:50
电子测试(2017年15期)2017-12-18 07:19:27
中国卫生(2016年5期)2016-11-12 13:25:26
新校长(2016年8期)2016-01-10 06:43:59
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
商事法论集(2014年1期)2014-06-27 01:20:42
生物进化(2014年2期)2014-04-16 04:36:26
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
