
基于卷积神经网络的RGB-D图片分类
2018-12-20 07:55:00徐小杰
电子设计工程 2018年24期
柳 畅 ,徐小杰
(1.中国科学院上海微系统与信息技术研究所,上海200050;2.上海科技大学信息学院,上海201210;3.中国科学院大学北京100049)
近年来,深度感知设备发展迅速,传统照相机和深度感知设备的结合广泛应用于各个领域。为获得同一场景的彩色(RGB)图片和深度(D)图片,常用的方法是使用一种同时具备相机镜头和深度传感器的设备,比如已经广泛商用的Kinect。RGB-D图片比传统的RGB图片多出的深度信息带来了更多三维空间的立体感。因此,学术界特别是机器人和计算机视觉领域,对RGB-D图片的应用研究日益广泛。网上大量公开的RGB-D数据集[1-3]也方便了不具备人力物力条件自己制作数据集的学术研究者们使用。
深度学习[4]作为一种近几年提出的方法,在高级信息感知方面的成就远远超越了传统的机器学习方法。在图像处理的相关应用中,一个非常重要的网络结构是卷积神经网络(CNNs)。这种网络结构可以有效地提取二维图像中某一点邻域内的信息。因此,对于图片这种相邻像素点间具有很强相关性的数据,CNNs是非常合适的网络结果。就目前来说,CNNs已经在图像分类[5-8]、分割[9-11],目标识别与检测[12-14]等方向得到了成功的应用。
在图像分类问题上,基于CNNs的方法[5]已经超越了传统的机器学习方法,但是它们往往是以彩色(RGB)图像作为输入数据。如果增加一维深度(D)信息,是否能再次提高分类准确率?针对该问题,本文提出了一种将深度信息和彩色信息结合的方法,探索并发现了它们的最佳组合方式,最后设计实验证明了深度信息能够将图片分类准确率提升至少5%。
1 RGB-D数据预处理
1.1 建立训练数据集
由华盛顿大学(University of Washington,UW)维护的RGB-D物体数据集(RGB-D Object Dataset)[1]是目前学术研究领域应用最为广泛的数据集之一。它包括了51类常见物品,包括水果、蔬菜和各种日用品,每一类包括5到10种颜色形状不同的个体。整体算来,共有约300种独立的个体(instance)。对于每个个体,该数据集提供了分别从 30°、45°、60°俯视角下,用Kinect环拍的视频。为方便图像处理领域的研究工作,该数据集也提供了由环拍视频转换来的图像数据:每个个体约600对RGB-D图片和对图片中物体的掩码图(mask)。
由于该数据集包含的图片总量达到了207,920对,为减少实验时间同时得到合理可靠的实验结果,我们在每个大类中随机抽取687对图片,组成数据子集用来训练。由于每个大类中包括不同外形的个体和拍摄角度,我们从30°和60°俯视角的图片集中抽取训练集和验证集,从45°俯视角中抽取测试集。以“苹果”为例,该大类中共包括5种不同外形的个体,那么就需要均匀地从每个个体的两个俯视角度的图像集中分别随机选择687/5/2≈69对RGB-D图。最后,保留35 000对并打乱顺序。它们将作为本文实验的训练集和验证集。在45°俯视角的图片集中,用同样的方式选出5 000对图片作为测试集。本文中所有实验结果均为测试集上的实验结果。
1.2 RGB-D数据预处理
本文使用的RGB-D数据如图1,2所示,分别是彩色图像和深度图像。图2中的黑色部分表示此处的深度信息缺失。为降低其对于网络训练的影响,我们采用NYU Depth V2数据集提供的补洞脚本来填补这些缺失的深度数据(然后将灰度值缩放到[0,1]),结果如图3所示。

图1 RGB图

图2 D图

图3 填充D图
为避免复杂背景对算法效果的影响,该数据集的制作者已经严格控制了环境颜色。在此基础上,我们使用提供的掩码图对目标物体抠像,最后我们的训练数据如图4,5所示。

图4 RGB图去背景
由于数字图像在不同的色彩空间内有不同的表达形式,我们将本属于RGB色彩空间的数据分别转化到HSI、Lab、YUV等空间,或转为灰度图像(Grayscale)共训练使用。

图5 D图去背景
2 CNNs网络设计
2.1 CNNs网络结构
本文的CNNs结构如表1所示。输入数据是36×36×n的图像,n取1、3、4,分别表示深度图像、彩色图像和RGB-D图像。卷积层#1_1包括48个5×5卷积核,移动步长(stride)为1,池化层#1_2对每个2×2的格子做max-pooling,格子移动步长为2(即格子间互不重叠)。在每个卷积和全连接层后使用线性整流函数(Rectified Linear Unit,ReLu)作为激活函数。最后使用Softmax分类器做51分类。

表1 CNNs结构
2.2 概率累加
多个CNNs的连接方法通常是从每个网络取出某个激活函数的输出,串联成一个更长的列向量,送入后面的网络层,以此合并成一个树形网络。这种网络往往需要较复杂的调参技巧才能收敛到较好的结果。本文将n个Softmax分类器的输出结果进行叠加,并再次归一化,得到最终用来分类的概率向量(如图6)。这种设计参考了Boosting算法的思想,希望色彩信息和深度信息能够互相取长补短,以达到更好的分类效果。
图6中算子f进行逐元素计算,公式如下:
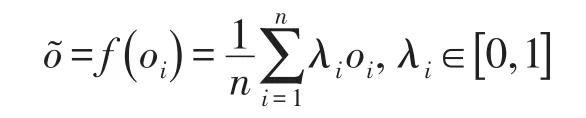
其中,oi表示第i个网络输出的概率向量。权重λi体现了不同网络对最终结果的影响程度。本文中固定λi=1。
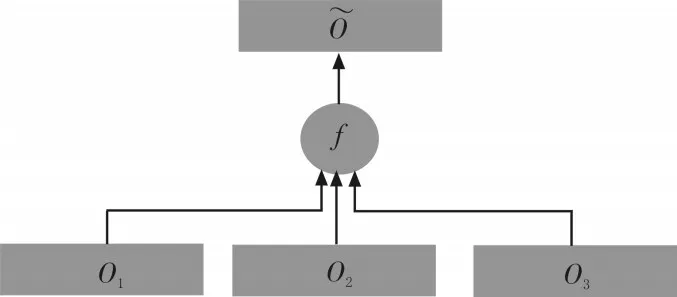
图6 概率累加示意图
3 实验分析
本文使用MatConvNet作为CNNs网络搭建和训练的框架。硬件设备是配有Intel Core i7 3.60 GHz的CPU和8GB内存的计算机。
CNNs训练时,我们用正态分布于[0,0.01]的随机数初始化卷积层和全连接层的权值矩阵W,偏置b统一设为0。为加快收敛速度,使用批梯度下降法(Batch Gradient Descent)来优化网络参数,batch大小为200。经初步测验,对整个训练集反复使用16次,即16个epoch后,目标函数收敛到较低值,因此我们在前8个epoch中,设学习率为0.01,后8个epoch降至0.001,使得训练损失(loss)能够平缓地下降。
3.1 CNNs预训练结果
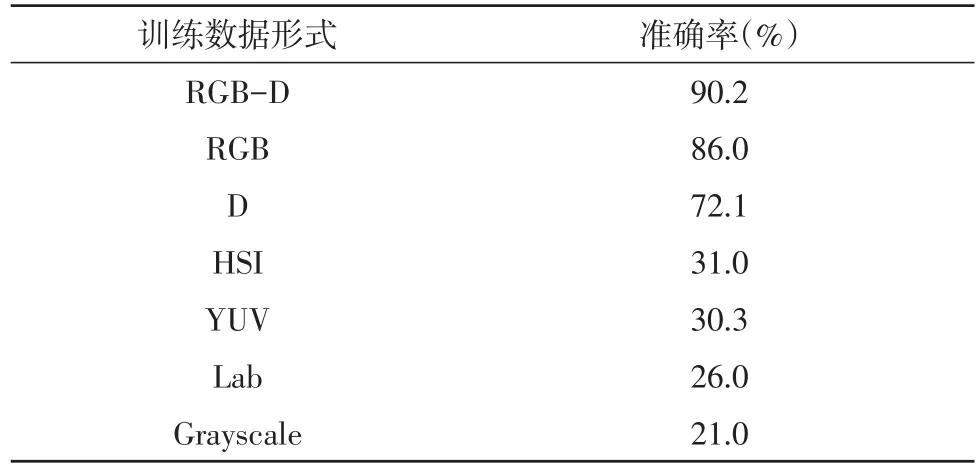
表2 预训练准确率
表2展示了将同一个物体的不同表达形式作为网络输入,得到的预测准确率。其中RGB-D的准确率远高于其他的如入形式,但数值上也不尽如人意。用HSI、YUV、Lab和Grayscale训练分类网络是失败的。原因在于训练出的网络泛化性能较差。在训练集上,它们的loss普遍下降很快最终收敛,但是在验证集和测试集,loss达到某个值(0.05)左右便不再下降。
概率累加的思想需要选择分类效果相对较好的弱分类器来实现由弱到强。下一节中我们将RGBD、RGB、D 3个网络自由组合,找出分类效果最好的一组。
3.2 概率累加结果

表3 组合准确率
实验证明,由RGB-D、RGB和D三者的组合表现最佳,达到了95.0%的准确率。RGB和D的组合也达到了94.6%,非常接近最高值。从本质上来看,RGB-D在三者组合中其实是冗余的,对RGB和D的组合,通过增加epoch和适当调参能够达到95%以上的效果。比较RGB+RGB-D和D+RGB-D的组合可以看出,色彩信息在分类任务中的作用大于深度信息。

表4 与其他算法结果对比
表4将本文实验的最佳结果与目前发表的两个成熟算法进行比较。本文使用了相对简单的网络结构,结合Boosting的思想,在本文的数据集上达到了比文献[15-16]更高的准确率。对于每个大类的分类结果如图7,X轴表示正确的标签(label),Y轴表示网络预测的标签,灰色方格表示将标签X预测为标签Y的概率。整体看来,预测结果准确。
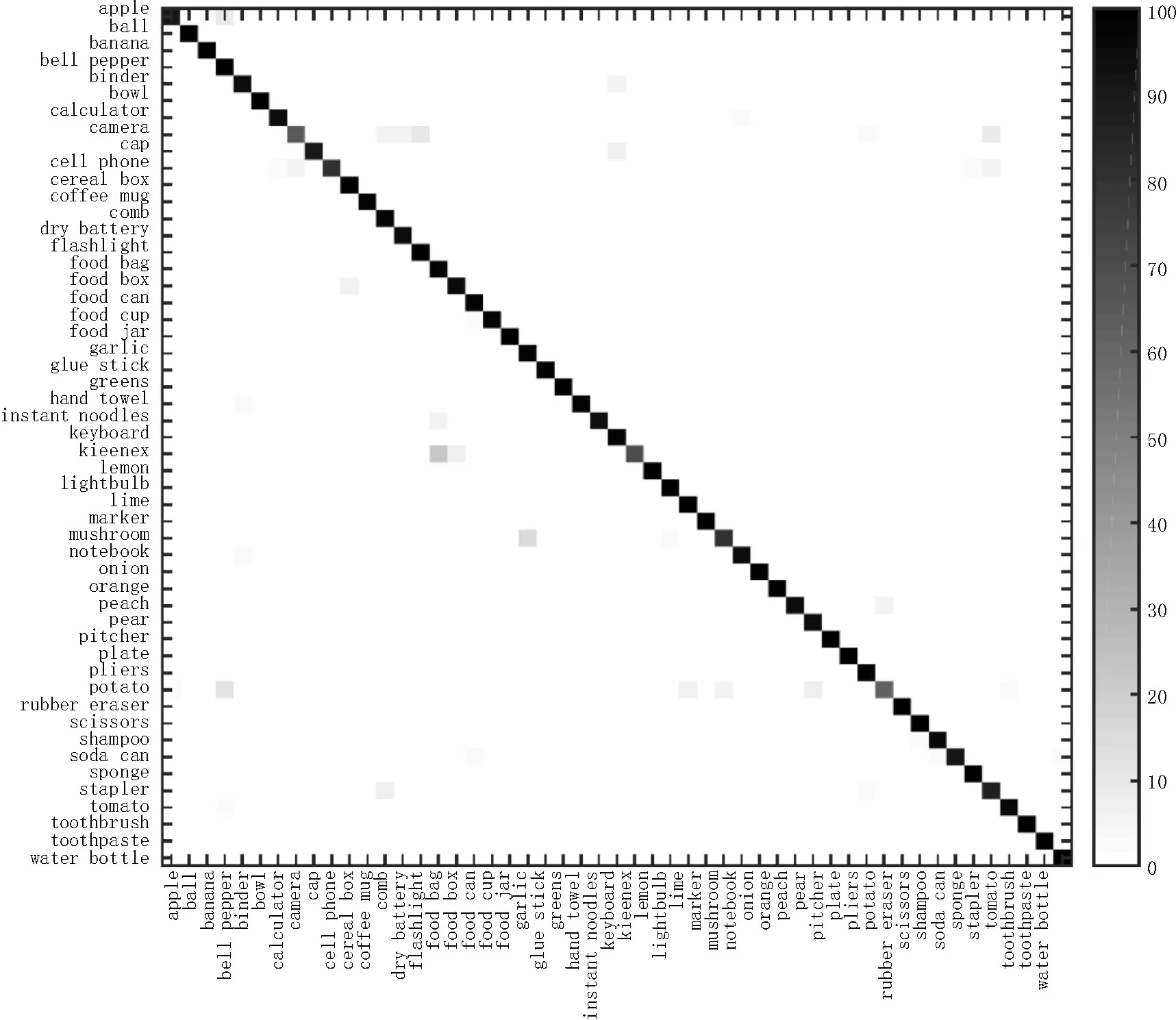
图7 每一类的分类准确率
4 结束语
本文针对基于图像的物体分类问题,借鉴了Boosting算法的思想,提出了将若干CNNs网络结合以实现更好的分类结果。本文将图像[17]的色彩信息和深度信息利用CNNs进行结合,发现RGB-D、RGB和D三者的组合能够使分类效果达到最高值95.0%,比单独使用其中任何一种信息提高了至少5%。另外,实验发现HSI、YUV、Lab等颜色空间下训练的网络泛化性能较差,侧面印证了机器人[18]及计算机视觉领域广泛基于RGB图像进行算法设计的合理性。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
中国交通信息化(2018年5期)2018-08-21 03:37:40
